Halaman ini menguraikan praktik terbaik yang harus digunakan saat mengembangkan pipeline Dataflow Anda. Penggunaan praktik terbaik ini memiliki manfaat berikut:
- Meningkatkan kemampuan observasi dan performa pipeline
- Peningkatan produktivitas developer
- Meningkatkan kemudahan pengujian pipeline
Contoh kode Apache Beam di halaman ini menggunakan Java, tetapi kontennya berlaku untuk Apache Beam SDK Java, Python, dan Go.
Pertanyaan yang perlu dipertimbangkan
Saat mendesain pipeline, pertimbangkan pertanyaan berikut:
- Di mana data input pipeline Anda disimpan? Berapa banyak set data input yang Anda miliki?
- Seperti apa data Anda?
- Apa yang ingin Anda lakukan dengan data Anda?
- Ke mana data output pipeline Anda harus dikirim?
- Apakah tugas Dataflow Anda menggunakan Assured Workloads?
Menggunakan template
Untuk mempercepat pengembangan pipeline, alih-alih membuat pipeline dengan menulis kode Apache Beam, gunakan template Dataflow jika memungkinkan. Template memiliki manfaat berikut:
- Template dapat digunakan kembali.
- Template memungkinkan Anda menyesuaikan setiap tugas dengan mengubah parameter pipeline tertentu.
- Siapa pun yang Anda beri izin dapat menggunakan template untuk men-deploy pipeline. Misalnya, developer dapat membuat tugas dari template, dan ilmuwan data di organisasi dapat men-deploy template tersebut di lain waktu.
Anda dapat menggunakan template yang disediakan Google, atau membuat template Anda sendiri. Beberapa template yang disediakan Google memungkinkan Anda menambahkan logika kustom sebagai langkah pipeline. Misalnya, template Pub/Sub ke BigQuery menyediakan parameter untuk menjalankan fungsi yang ditentukan pengguna (UDF) JavaScript yang disimpan di Cloud Storage.
Karena template yang disediakan Google bersifat open source berdasarkan Lisensi Apache 2.0, Anda dapat menggunakannya sebagai dasar untuk pipeline baru. Template ini juga berguna sebagai contoh kode. Lihat kode template di repositori GitHub.
Assured Workloads
Assured Workloads membantu menerapkan persyaratan keamanan dan kepatuhan untuk pelangganGoogle Cloud . Misalnya, Region Uni Eropa dan Dukungan dengan Sovereignty Controls membantu menerapkan jaminan residensi data dan kedaulatan data untuk pelanggan yang berbasis di Uni Eropa. Untuk menyediakan fitur ini, beberapa fitur Dataflow dibatasi atau dilimitasi. Jika Anda menggunakan Assured Workloads dengan Dataflow, semua resource yang diakses pipeline Anda harus berada di project atau folder Assured Workloads organisasi Anda. Referensi ini mencakup:
- Bucket Cloud Storage
- Set data BigQuery
- Topik dan langganan Pub/Sub
- Set data Firestore
- Konektor I/O
Di Dataflow, untuk tugas streaming yang dibuat setelah 7 Maret 2024, semua data pengguna dienkripsi dengan CMEK.
Untuk tugas streaming yang dibuat sebelum 7 Maret 2024, kunci data yang digunakan dalam operasi berbasis kunci, seperti windowing, pengelompokan, dan penggabungan, tidak dilindungi oleh enkripsi CMEK. Untuk mengaktifkan enkripsi ini bagi tugas Anda, hentikan atau batalkan tugas, lalu mulai ulang tugas. Untuk mengetahui informasi selengkapnya, lihat Enkripsi artefak status pipeline.
Membagikan data di seluruh pipeline
Tidak ada mekanisme komunikasi antar-pipeline khusus Dataflow untuk berbagi data atau konteks pemrosesan antar-pipeline. Anda dapat menggunakan penyimpanan yang andal seperti Cloud Storage atau cache dalam memori seperti App Engine untuk membagikan data antar-instance pipeline.
Menjadwalkan tugas
Anda dapat mengotomatiskan eksekusi pipeline dengan cara berikut:
- Gunakan Cloud Scheduler.
- Gunakan Operator Dataflow Apache Airflow, salah satu dari beberapa OperatorGoogle Cloud dalam alur kerja Cloud Composer.
- Jalankan proses tugas kustom (cron) di Compute Engine.
Praktik terbaik untuk menulis kode pipeline
Bagian berikut memberikan praktik terbaik yang dapat digunakan saat Anda membuat pipeline dengan menulis kode Apache Beam.
Menyusun kode Apache Beam
Untuk membuat pipeline, biasanya digunakan transformasi Apache Beam pemrosesan paralel
ParDo
generik.
Saat menerapkan transformasi ParDo, Anda memberikan kode dalam bentuk objek DoFn. DoFn adalah class Apache Beam SDK yang menentukan fungsi pemrosesan terdistribusi.
Anda dapat menganggap kode DoFn sebagai entitas kecil dan independen: berpotensi ada banyak instance yang berjalan di mesin yang berbeda, yang masing-masing tidak mengetahui instance lainnya. Oleh karena itu, sebaiknya buat fungsi murni, yang
ideal untuk sifat paralel dan terdistribusi dari elemen DoFn.
Fungsi murni memiliki karakteristik berikut:
- Fungsi murni tidak bergantung pada status tersembunyi atau eksternal.
- Tidak ada efek samping yang dapat diamati.
- Mereka bersifat deterministik.
Model fungsi murni tidak sepenuhnya kaku. Jika kode Anda tidak bergantung pada
hal-hal yang tidak dijamin oleh layanan Dataflow, informasi
status atau data inisialisasi eksternal dapat valid untuk DoFn dan objek
fungsi lainnya.
Saat menyusun transformasi ParDo dan membuat elemen DoFn,
pertimbangkan panduan berikut:
- Saat Anda menggunakan pemrosesan tepat satu kali,
layanan Dataflow menjamin bahwa setiap elemen dalam
input
PCollectiondiproses oleh instanceDoFntepat satu kali. - Layanan Dataflow tidak menjamin berapa kali
DoFndipanggil. - Layanan Dataflow tidak menjamin secara pasti bagaimana elemen yang didistribusikan dikelompokkan. Hal ini tidak menjamin elemen mana, jika ada, yang diproses bersama.
- Layanan Dataflow tidak menjamin jumlah pasti instance
DoFnyang dibuat selama pipeline. - Layanan Dataflow bersifat fault-tolerant dan dapat mencoba ulang kode Anda beberapa kali jika worker mengalami masalah.
- Layanan Dataflow dapat membuat salinan cadangan kode Anda. Masalah dapat terjadi pada efek samping manual, seperti jika kode Anda mengandalkan atau membuat file sementara dengan nama yang tidak unik.
- Layanan Dataflow melakukan serialisasi pemrosesan elemen per
DoFninstance. Kode Anda tidak harus benar-benar aman untuk thread, tetapi setiap status yang dibagikan di antara beberapa instanceDoFnharus aman untuk thread.
Membuat library transformasi yang dapat digunakan kembali
Model pemrograman Apache Beam memungkinkan Anda menggunakan kembali transformasi. Dengan membuat library bersama untuk transformasi umum, Anda dapat meningkatkan kegunaan kembali, kemampuan pengujian, dan kepemilikan kode oleh tim yang berbeda.
Pertimbangkan dua contoh kode Java berikut, yang keduanya membaca peristiwa pembayaran. Dengan asumsi bahwa kedua pipeline melakukan pemrosesan yang sama, keduanya dapat menggunakan transformasi yang sama melalui library bersama untuk langkah pemrosesan yang tersisa.
Contoh pertama berasal dari sumber Pub/Sub tanpa batas:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
Contoh kedua berasal dari sumber database relasional yang terikat:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
Cara Anda menerapkan praktik terbaik penggunaan ulang kode bervariasi menurut bahasa pemrograman dan alat build. Misalnya, jika Anda menggunakan Maven, Anda dapat memisahkan kode transformasi ke dalam modulnya sendiri. Anda kemudian dapat menyertakan modul sebagai submodul dalam project multi-modul yang lebih besar untuk pipeline yang berbeda, seperti yang ditunjukkan dalam contoh kode berikut:
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
Untuk mengetahui informasi selengkapnya, lihat halaman dokumentasi Apache Beam berikut:
- Persyaratan untuk menulis kode pengguna untuk transformasi Apache Beam
- Panduan gaya
PTransform: panduan gaya untuk penulis koleksiPTransformbaru yang dapat digunakan kembali
Menggunakan antrean pesan yang tidak terkirim untuk penanganan error
Terkadang, pipeline Anda tidak dapat memproses elemen. Masalah data adalah penyebab umum. Misalnya, elemen yang berisi JSON dengan format yang salah dapat menyebabkan kegagalan penguraian.
Meskipun Anda dapat menangkap pengecualian dalam metode
DoFn.ProcessElement, mencatat error, dan menghapus elemen, pendekatan ini akan menghilangkan data
dan mencegah data diperiksa nanti untuk penanganan atau pemecahan masalah secara manual.
Sebagai gantinya, gunakan pola yang disebut antrean pesan yang tidak terproses (antrean pesan yang tidak diproses).
Tangkap pengecualian dalam metode DoFn.ProcessElement dan catat
kesalahan. Daripada melepaskan elemen yang gagal, gunakan output percabangan untuk menulis elemen yang gagal ke dalam objek PCollection terpisah. Elemen ini kemudian ditulis ke tujuan data untuk diperiksa dan ditangani nanti dengan transformasi terpisah.
Contoh kode Java berikut menunjukkan cara menerapkan pola antrean pesan yang tidak terproses.
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
Gunakan Cloud Monitoring untuk menerapkan kebijakan pemantauan dan pemberitahuan yang berbeda untuk antrean surat yang tidak terkirim di pipeline Anda. Misalnya, Anda dapat memvisualisasikan jumlah dan ukuran elemen yang diproses oleh transformasi pesan yang tidak terkirim dan mengonfigurasi pemberitahuan untuk dipicu jika kondisi batas tertentu terpenuhi.
Menangani mutasi skema
Anda dapat menangani data yang memiliki skema yang tidak terduga tetapi valid menggunakan pola pesan yang tidak terkirim, yang menulis elemen yang gagal ke objek PCollection terpisah.
Dalam beberapa kasus, Anda ingin menangani elemen yang mencerminkan skema yang diubah secara otomatis sebagai elemen yang valid. Misalnya, jika skema elemen mencerminkan mutasi seperti penambahan kolom baru, Anda dapat menyesuaikan skema sink data untuk mengakomodasi mutasi.
Mutasi skema otomatis mengandalkan pendekatan output percabangan yang digunakan oleh pola pesan yang tidak terkirim. Namun, dalam kasus ini, akan memicu transformasi yang memutasi skema tujuan setiap kali skema aditif ditemukan. Untuk contoh pendekatan ini, lihat Cara menangani skema JSON yang berubah dalam pipeline streaming, dengan Square Enix di blog Google Cloud .
Memutuskan cara menggabungkan set data
Menggabungkan set data adalah kasus penggunaan umum untuk pipeline data. Anda dapat menggunakan
input samping atau transformasi CoGroupByKey untuk melakukan penggabungan dalam pipeline.
Masing-masing memiliki kelebihan dan kekurangan.
Input samping
memberikan cara yang fleksibel untuk memecahkan masalah pemrosesan data umum, seperti pengayaan data dan pencarian dengan kunci. Tidak seperti objek PCollection, input samping dapat
berubah dan dapat ditentukan saat runtime. Misalnya, nilai dalam input samping dapat dihitung oleh cabang lain dalam pipeline Anda atau ditentukan dengan memanggil layanan jarak jauh.
Dataflow mendukung input sampingan dengan menyimpan data ke penyimpanan persisten, mirip dengan disk bersama. Konfigurasi ini membuat input samping lengkap tersedia untuk semua pekerja.
Namun, ukuran input samping bisa sangat besar dan mungkin tidak sesuai dengan memori pekerja. Membaca dari input samping yang besar dapat menyebabkan masalah performa jika pekerja perlu terus-menerus membaca dari penyimpanan persisten.
Transformasi CoGroupByKey
adalah
transformasi Apache Beam inti
yang menggabungkan (meratakan) beberapa objek PCollection dan mengelompokkan elemen yang
memiliki kunci yang sama. Tidak seperti input sampingan, yang membuat seluruh data input sampingan tersedia untuk setiap pekerja, CoGroupByKey melakukan operasi pengacakan (pengelompokan) untuk mendistribusikan data di seluruh pekerja. Oleh karena itu, CoGroupByKey sangat ideal jika objek
PCollection yang ingin Anda gabungkan sangat besar dan tidak sesuai dengan memori
pekerja.
Ikuti panduan berikut untuk membantu memutuskan apakah akan menggunakan input samping atau
CoGroupByKey:
- Gunakan input samping saat salah satu objek
PCollectionyang Anda gabungkan jauh lebih kecil daripada yang lain, dan objekPCollectionyang lebih kecil sesuai dengan memori pekerja. Meng-cache seluruh input samping ke dalam memori akan membuat pengambilan elemen menjadi cepat dan efisien. - Gunakan input samping saat Anda memiliki objek
PCollectionyang harus digabungkan beberapa kali dalam pipeline. Daripada menggunakan beberapa transformasiCoGroupByKey, buat satu input samping yang dapat digunakan kembali oleh beberapa transformasiParDo. - Gunakan
CoGroupByKeyjika Anda perlu mengambil sebagian besar objekPCollectionyang secara signifikan melebihi memori pekerja.
Untuk mengetahui informasi selengkapnya, lihat Memecahkan masalah error kehabisan memori Dataflow.
Meminimalkan operasi per elemen yang mahal
Instance DoFn memproses batch elemen yang disebut
bundle,
yang merupakan unit kerja atomik yang terdiri dari nol atau lebih
elemen. Setiap elemen kemudian diproses oleh metode
DoFn.ProcessElement, yang berjalan untuk setiap elemen. Karena metode DoFn.ProcessElement
dipanggil untuk setiap elemen, setiap operasi yang memakan waktu atau mahal secara komputasi yang dipanggil oleh metode tersebut akan berjalan untuk setiap elemen yang diproses oleh metode.
Jika Anda perlu melakukan operasi yang mahal hanya sekali untuk sekumpulan elemen,
sertakan operasi tersebut dalam metode DoFn.Setup atau metode DoFn.StartBundle,
bukan dalam elemen DoFn.ProcessElement. Contohnya mencakup operasi berikut:
Mem-parsing file konfigurasi yang mengontrol beberapa aspek perilaku instance
DoFn. Panggil tindakan ini hanya satu kali, saat instanceDoFndiinisialisasi, dengan menggunakan metodeDoFn.Setup.Membuat instance klien dengan durasi aktif pendek yang digunakan kembali di semua elemen dalam paket, seperti saat semua elemen dalam paket dikirim melalui satu koneksi jaringan. Panggil tindakan ini satu kali per paket menggunakan metode
DoFn.StartBundle.
Membatasi ukuran batch dan panggilan serentak ke layanan eksternal
Saat memanggil layanan eksternal, Anda dapat mengurangi biaya per panggilan dengan menggunakan transformasi
GroupIntoBatches. Transformasi ini membuat batch elemen dengan ukuran yang ditentukan.
Pengelompokan mengirimkan elemen ke layanan eksternal sebagai satu payload, bukan
satu per satu.
Bersama dengan batching, batasi jumlah maksimum panggilan paralel (serentak) ke layanan eksternal dengan memilih kunci yang sesuai untuk mempartisi data yang masuk. Jumlah partisi menentukan paralelisasi maksimum. Misalnya, jika setiap elemen diberi kunci yang sama, transformasi hilir untuk memanggil layanan eksternal tidak berjalan secara paralel.
Pertimbangkan salah satu pendekatan berikut untuk menghasilkan kunci elemen:
- Pilih atribut set data yang akan digunakan sebagai kunci data, seperti ID pengguna.
- Buat kunci data untuk memisahkan elemen secara acak di sejumlah partisi tetap, dengan jumlah kemungkinan nilai kunci menentukan jumlah partisi. Anda perlu membuat partisi yang cukup untuk paralelisme.
Setiap partisi harus memiliki elemen yang cukup agar transformasi
GroupIntoBatchesdapat berguna.
Contoh kode Java berikut menunjukkan cara membagi elemen secara acak ke dalam sepuluh partisi:
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
Mengidentifikasi masalah performa yang disebabkan oleh langkah-langkah gabungan
Dataflow membuat grafik langkah-langkah yang merepresentasikan pipeline Anda berdasarkan transformasi dan data yang Anda gunakan untuk menyusunnya. Grafik ini disebut grafik eksekusi pipeline.
Saat Anda men-deploy pipeline, Dataflow dapat mengubah grafik eksekusi pipeline untuk meningkatkan performa. Misalnya, Dataflow dapat menggabungkan beberapa operasi, sebuah proses yang dikenal sebagai pengoptimalan penggabungan, untuk menghindari dampak performa dan biaya dari penulisan setiap objek PCollection perantara dalam pipeline Anda.
Dalam beberapa kasus, Dataflow mungkin salah menentukan cara optimal untuk menggabungkan operasi dalam pipeline, yang dapat membatasi kemampuan tugas Anda untuk memanfaatkan semua pekerja yang tersedia. Dalam kasus tersebut, Anda dapat mencegah operasi digabungkan.
Perhatikan contoh kode Apache Beam berikut. Transformasi
GenerateSequence
membuat objek PCollection kecil yang terikat, yang kemudian diproses lebih lanjut
oleh dua transformasi ParDo hilir.
Transformasi Find Primes Less-than-N mungkin memerlukan biaya komputasi yang tinggi dan cenderung berjalan lambat untuk angka dalam jumlah besar. Sebaliknya, transformasi
Increment Number mungkin selesai dengan cepat.
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
Diagram berikut menunjukkan representasi grafis pipeline di antarmuka pemantauan Dataflow.
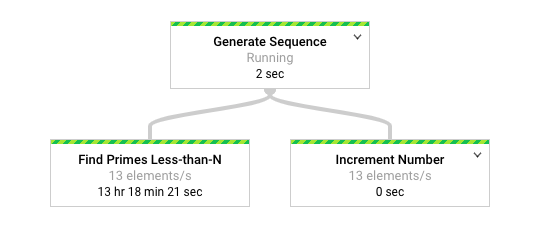
Antarmuka pemantauan Dataflow menunjukkan bahwa kecepatan pemrosesan yang sama lambatnya terjadi untuk kedua transformasi, khususnya 13 elemen per detik. Anda mungkin berharap transformasi Increment Number memproses elemen dengan cepat, tetapi tampaknya terikat pada kecepatan pemrosesan yang sama dengan Find Primes Less-than-N.
Alasannya adalah Dataflow menggabungkan langkah-langkah tersebut menjadi satu
tahap, yang mencegahnya berjalan secara independen. Anda dapat menggunakan perintah
gcloud dataflow jobs describe
untuk menemukan informasi selengkapnya:
gcloud dataflow jobs describe --full job-id --format json
Dalam output yang dihasilkan, langkah-langkah gabungan dijelaskan dalam objek
ExecutionStageSummary
dalam array
ComponentTransform:
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
Dalam skenario ini, karena transformasi Find Primes Less-than-N adalah langkah yang lambat,
memecah fusi sebelum langkah tersebut adalah strategi yang tepat. Salah satu metode untuk memisahkan langkah-langkah adalah dengan menyisipkan transformasi GroupByKey dan membatalkan pengelompokan sebelum langkah, seperti yang ditunjukkan dalam contoh kode Java berikut.
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
Anda juga dapat menggabungkan langkah-langkah penghapusan penggabungan ini menjadi transformasi gabungan yang dapat digunakan kembali.
Setelah Anda membatalkan penggabungan langkah-langkah, saat Anda menjalankan pipeline, Increment Number
akan selesai dalam hitungan detik, dan transformasi Find Primes Less-than-N yang berjalan lebih lama
akan berjalan di tahap terpisah.
Contoh ini menerapkan operasi pengelompokan dan penguraian kelompok ke langkah-langkah yang tidak digabungkan.
Anda dapat menggunakan pendekatan lain untuk situasi lainnya. Dalam hal ini, penanganan output duplikat tidak menjadi masalah, mengingat output berurutan dari transformasi GenerateSequence.
Objek KV dengan kunci duplikat akan di-deduplikasi menjadi satu kunci dalam transformasi grup
(GroupByKey) dan transformasi
batal pengelompokan (Keys). Untuk mempertahankan duplikat setelah operasi pengelompokan dan penguraian kelompok,
buat pasangan nilai kunci menggunakan langkah-langkah berikut:
- Gunakan kunci acak dan input asli sebagai nilai.
- Kelompokkan menggunakan kunci acak.
- Keluarkan nilai untuk setiap kunci sebagai output.
Anda juga dapat menggunakan
transformasi Reshuffle
untuk mencegah penggabungan transformasi di sekitarnya. Namun, efek samping transformasi
Reshuffle tidak dapat dipindahkan di berbagai
pelaksana Apache Beam.
Untuk mengetahui informasi selengkapnya tentang paralelisme dan pengoptimalan gabungan, lihat Siklus proses pipeline.
Menggunakan metrik Apache Beam untuk mengumpulkan insight pipeline
Metrik Apache Beam adalah class utilitas yang menghasilkan metrik untuk melaporkan properti pipeline yang sedang berjalan. Saat Anda menggunakan Cloud Monitoring, metrik Apache Beam tersedia sebagai metrik kustom Cloud Monitoring.
Contoh berikut menunjukkan metrik Apache Beam
Counter
yang digunakan dalam subkelas DoFn.
Kode contoh menggunakan dua penghitung. Satu penghitung melacak kegagalan penguraian JSON (malformedCounter), dan penghitung lainnya melacak apakah pesan JSON valid, tetapi berisi payload kosong (emptyCounter). Di Cloud Monitoring, nama metrik kustomnya adalah custom.googleapis.com/dataflow/malformedJson dan custom.googleapis.com/dataflow/emptyPayload. Anda dapat menggunakan metrik kustom
untuk membuat visualisasi dan kebijakan pemberitahuan di Cloud Monitoring.
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
Pelajari lebih lanjut
Halaman berikut memberikan informasi selengkapnya tentang cara menyusun pipeline, cara memilih transformasi yang akan diterapkan pada data, dan hal yang perlu dipertimbangkan saat memilih metode input dan output pipeline.
Untuk mengetahui informasi selengkapnya tentang cara membuat kode pengguna, lihat persyaratan untuk fungsi yang disediakan pengguna.