Integración con SAP
En esta página se describen los pasos para integrar cargas de trabajo operativas de SAP (SAP ECC y SAP S/4 HANA) en Cortex Framework Data Foundation. Cortex Framework puede acelerar la integración de datos de SAP con BigQuery mediante plantillas de procesamiento de datos predefinidas con flujos de procesamiento de Dataflow a BigQuery, mientras que Cloud Composer programa y monitoriza estos flujos de procesamiento de Dataflow para obtener estadísticas a partir de tus datos operativos de SAP.
El archivo config.json del repositorio de la infraestructura de datos de Cortex Framework configura los ajustes necesarios para transferir datos desde cualquier fuente de datos, incluido SAP. Este archivo contiene los siguientes parámetros para cargas de trabajo operativas de SAP:
"SAP": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING"
},
"SQLFlavor": "ecc",
"mandt": "100"
}
En la siguiente tabla se describe el valor de cada parámetro operativo de SAP:
| Parámetro | Significado | Valor predeterminado | Descripción |
SAP.deployCDC
|
Implementar CDC | true
|
Genera secuencias de comandos de procesamiento de CDC para ejecutarlas como DAGs en Cloud Composer. |
SAP.datasets.raw
|
Conjunto de datos de landing sin procesar | - | El proceso de CDC lo usa para donde la herramienta de replicación coloca los datos de SAP. Si usas datos de prueba, crea un conjunto de datos vacío. |
SAP.datasets.cdc
|
Conjunto de datos procesados por el CDC | - | Conjunto de datos que funciona como fuente de las vistas de informes y como destino de los DAGs procesados. Si utilizas datos de prueba, crea un conjunto de datos vacío. |
SAP.datasets.reporting
|
Conjunto de datos de informes de SAP | "REPORTING"
|
Nombre del conjunto de datos al que pueden acceder los usuarios finales para generar informes, donde se implementan las vistas y las tablas visibles para los usuarios. |
SAP.SQLFlavor
|
Tipo de SQL del sistema de origen | "ecc"
|
s4 o ecc.
Para probar los datos, mantenga el valor predeterminado (ecc).
|
SAP.mandt
|
Mandante o cliente | "100"
|
Mandante o cliente predeterminado de SAP.
Para probar los datos, mantenga el valor predeterminado (100).
|
SAP.languages
|
Filtro de idioma | ["E","S"]
|
Códigos de idioma de SAP (SPRAS) que se van a usar en los campos pertinentes (como los nombres). |
SAP.currencies
|
Filtro de moneda | ["USD"]
|
Códigos de moneda de destino de SAP (TCURR) para la conversión de moneda. |
Aunque no se requiere una versión mínima de SAP, los modelos de ECC se han desarrollado en la versión más antigua compatible de SAP ECC. Es normal que haya diferencias en los campos entre nuestro sistema y otros sistemas, independientemente de la versión.
Modelo de datos
En esta sección se describen los modelos de datos de SAP (ECC y S/4 HANA) mediante diagramas de relaciones entre entidades (DRE).
SAP ECC

SAP S/4 HANA
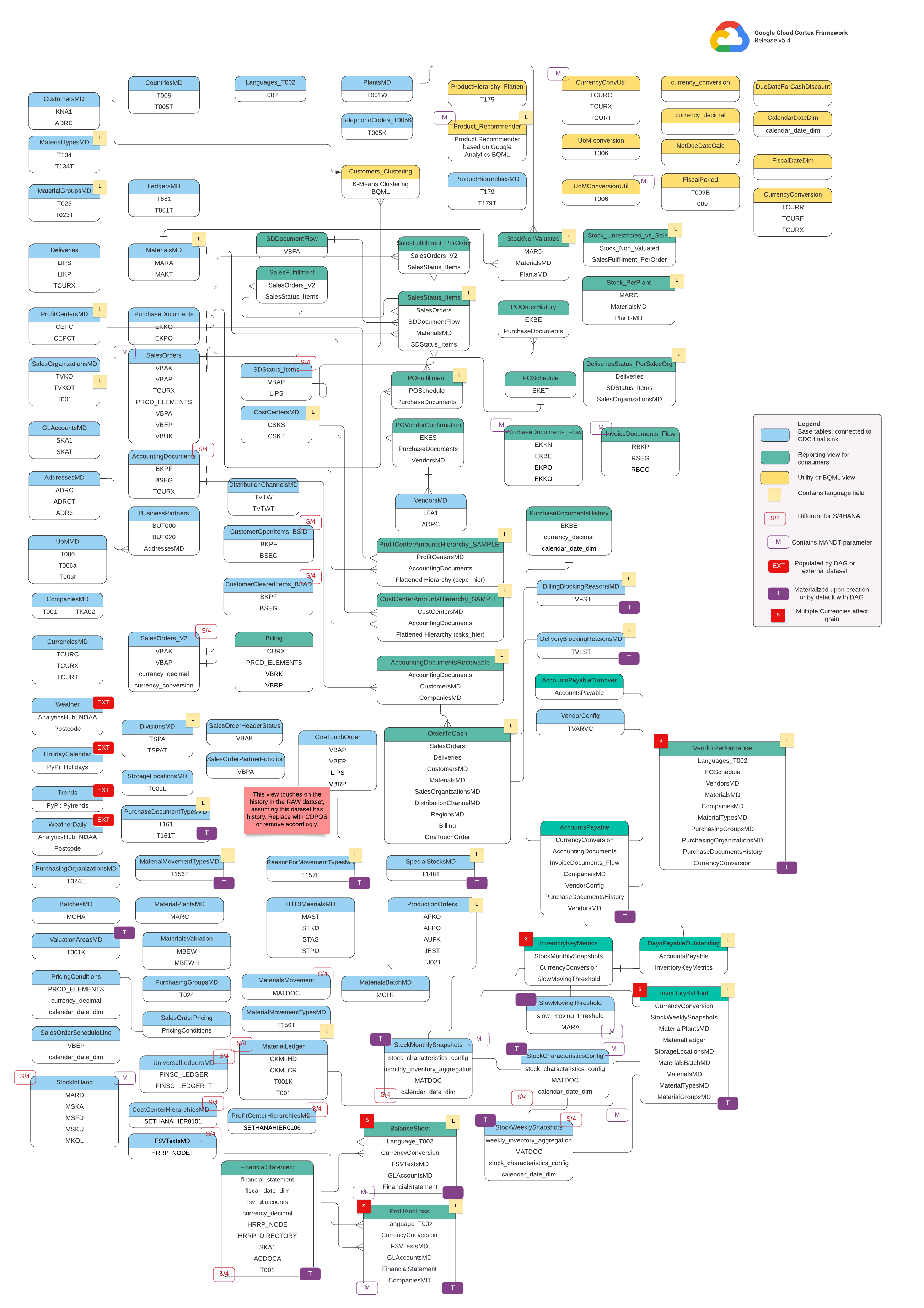
Vistas básicas
Son los objetos azules del diagrama ER y son vistas de tablas de CDC sin transformaciones, salvo algunos alias de nombres de columna. Consulta las secuencias de comandos en src/SAP/SAP_REPORTING.
Vistas de informes
Son los objetos verdes del diagrama ER y contienen los atributos dimensionales relevantes que usan las tablas de informes. Consulta las secuencias de comandos en src/SAP/SAP_REPORTING.
Vista de utilidad o de BQML
Son los objetos amarillos del diagrama ER y contienen los hechos y las dimensiones combinados. Se trata de un tipo específico de vista que se usa para el análisis de datos y la creación de informes. Consulta las secuencias de comandos en src/SAP/SAP_REPORTING.
Etiquetas adicionales
Las etiquetas con colores de este diagrama ER representan las siguientes características de las tablas de informes:
| Etiqueta | Color | Descripción |
L
|
Amarillo | Esta etiqueta hace referencia a un elemento o atributo de datos que especifica el idioma en el que se almacenan o se muestran los datos. |
S/4
|
Rojo | Esta etiqueta indica que determinados atributos son específicos de SAP S/4 HANA (puede que este objeto no esté en SAP ECC). |
MANDT
|
Morado | Esta etiqueta indica que determinados atributos contienen el parámetro MANDT (representa el cliente o el ID de cliente) para determinar a qué cliente o instancia de empresa pertenece un registro de datos específico. |
EXT
|
Rojo | Esta etiqueta indica que los DAGs o los conjuntos de datos externos rellenan objetos específicos. Esto significa que la entidad o tabla marcada no se almacena directamente en el sistema SAP, pero se puede extraer y cargar en SAP mediante un DAG u otro mecanismo. |
T
|
Morado | Esta etiqueta indica que determinados atributos se materializarán automáticamente mediante el DAG configurado. |
S
|
Rojo | Esta etiqueta indica que los datos de una entidad o de las tablas se ven influenciados o afectados por varias monedas. |
Requisitos previos para la replicación de SAP
Ten en cuenta los siguientes requisitos previos para replicar datos de SAP con Cortex Framework Data Foundation:
- Integridad de los datos: Cortex Framework Data Foundation espera que las tablas de SAP se repliquen con los mismos nombres de campo, tipos y estructuras de datos que tienen en SAP. Siempre que las tablas se repliquen con el mismo formato, los mismos nombres de campos y la misma granularidad que en la fuente, no es necesario usar una herramienta de replicación específica.
- Nombres de tablas: los nombres de las tablas de BigQuery deben crearse en minúsculas.
- Configuración de la tabla: la lista de tablas que usan los modelos de SAP está disponible y se puede configurar en el archivo
cdc_settings.yamlde CDC (captura de datos de cambios). Si una tabla no aparece en la lista durante la implementación, los modelos que dependan de ella fallarán, aunque otros modelos no dependientes se implementarán correctamente. - Consideraciones específicas sobre el conector de BigQuery para SAP:
- Asignación de tablas: para obtener información sobre la opción de conversión, consulta la documentación sobre la asignación de tablas predeterminada.
- Inhabilitar la compresión de registros: recomendamos inhabilitar la compresión de registros porque podría afectar tanto a la capa CDC de Cortex como al conjunto de datos de informes de Cortex.
- Replicación de metadatos: si no vas a implementar datos de prueba ni generar secuencias de comandos de DAG de CDC durante la implementación, asegúrate de que la tabla
DD03Lde metadatos de SAP se replique desde SAP en el proyecto de origen. Esta tabla contiene metadatos sobre las tablas, como la lista de claves, y es necesaria para que funcionen el generador de CDC y el gestor de dependencias. Esta tabla también te permite añadir tablas no incluidas en el modelo, como tablas personalizadas o Z, para que se puedan generar secuencias de comandos de CDC. Gestión de variaciones menores en los nombres de las tablas: si hay pequeñas diferencias en el nombre de una tabla, es posible que algunas vistas no encuentren los campos necesarios, ya que los sistemas SAP pueden tener pequeñas variaciones debido a las versiones o a los complementos, o bien porque algunas herramientas de replicación pueden gestionar los caracteres especiales de forma ligeramente diferente. Te recomendamos que ejecutes la implementación con
turboMode : falsepara detectar el mayor número de errores en un solo intento. Estos son algunos de los problemas habituales:- Se elimina el prefijo
_de los campos que lo tienen (por ejemplo,_DATAAGING)._ - Los campos no pueden empezar por
/en BigQuery.
En esta situación, puedes ajustar la vista que falla para seleccionar el campo tal como lo ha colocado la herramienta de replicación que elijas.
- Se elimina el prefijo
Replicar datos sin procesar de SAP
El objetivo de Data Foundation es exponer modelos de datos y analíticas para informes y aplicaciones. Los modelos consumen los datos replicados de un sistema SAP mediante una herramienta de replicación preferida, como las que se indican en las guías de integración de datos de SAP.
Los datos del sistema SAP (ECC o S/4 HANA) se replican en formato sin procesar.
Los datos se copian directamente de SAP a BigQuery sin que se modifique su estructura. Es básicamente una imagen reflejada de las tablas de tu sistema SAP. BigQuery usa nombres de tabla en minúsculas para su modelo de datos. Por lo tanto, aunque tus tablas de SAP tengan nombres en mayúsculas (como MANDT), se convertirán a minúsculas (como mandt) en BigQuery.
Procesamiento de captura de datos de cambios (CDC)
Elige uno de los siguientes modos de procesamiento de CDC que ofrece Cortex Framework para que las herramientas de replicación carguen registros de SAP:
- Añadir siempre: inserta cada cambio en un registro con una marca de tiempo y una marca de operación (Insertar, Actualizar o Eliminar) para que se pueda identificar la última versión.
- Actualizar al llegar (combinar o insertar): crea una versión actualizada de un registro al llegar a
change data capture processed. Realiza la operación de CDC en BigQuery.
Cortex Framework Data Foundation admite ambos modos, aunque, en el caso de la opción de añadir siempre, proporciona plantillas de procesamiento de CDC. Algunas funciones deben comentarse para que se actualicen en la página de destino. Por ejemplo, OneTouchOrder.sql y todas sus consultas dependientes. Esta función se puede sustituir por tablas como CDPOS.

Configurar plantillas de CDC para herramientas que replican en modo de añadir siempre
Te recomendamos que configures el cdc_settings.yaml según tus necesidades.
Algunas frecuencias predeterminadas pueden generar costes innecesarios si la empresa no requiere ese nivel de actualización de los datos. Si usas una herramienta que se ejecuta en modo de añadir siempre, Cortex Framework Data Foundation proporciona plantillas de CDC para automatizar las actualizaciones y crear la versión más reciente de la verdad o del gemelo digital en el conjunto de datos procesado de CDC.
Puedes usar la configuración del archivo cdc_settings.yaml si necesitas generar secuencias de comandos de procesamiento de CDC. Consulta las opciones en Configurar el procesamiento de CDC. En el caso de los datos de prueba, puede dejar este archivo como predeterminado.
Haz todos los cambios necesarios en las plantillas de DAG según tu instancia de Airflow o Cloud Composer. Para obtener más información, consulta Recoger la configuración de Cloud Composer.
Opcional: Si quieres añadir y procesar tablas individualmente después de la implementación, puedes modificar el archivo cdc_settings.yaml para procesar solo las tablas que necesites y volver a ejecutar el módulo especificado llamando directamente a src/SAP_CDC/cloudbuild.cdc.yaml.
Configurar el procesamiento de CDC
Durante la implementación, puedes combinar los cambios en tiempo real mediante una vista de BigQuery o programar una operación de combinación en Cloud Composer (o en cualquier otra instancia de Apache Airflow). Cloud Composer puede programar las secuencias de comandos para que procesen las operaciones de combinación periódicamente. Los datos se actualizan a su versión más reciente cada vez que se ejecutan las operaciones de combinación. Sin embargo, cuanto más frecuentes sean estas operaciones, mayores serán los costes. Personaliza la frecuencia programada según las necesidades de tu empresa. Para obtener más información, consulta la programación compatible con Apache Airflow.
En el siguiente ejemplo de secuencia de comandos se muestra un extracto del archivo de configuración:
data_to_replicate:
- base_table: adrc
load_frequency: "@hourly"
- base_table: adr6
target_table: adr6_cdc
load_frequency: "@daily"
Este archivo de configuración de ejemplo hace lo siguiente:
- Crea una copia de
SOURCE_PROJECT_ID.REPLICATED_DATASET.adrcenTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrc, si esta última no existe. - Crea un script de CDC en el segmento especificado.
- Crea una copia de
SOURCE_PROJECT_ID.REPLICATED_DATASET.adr6enTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdcsi esta última no existe. - Crea un script de CDC en el segmento especificado.
Si quieres crear DAGs o vistas de tiempo de ejecución para procesar los cambios de las tablas que existen en SAP y no aparecen en el archivo, añádelas a este archivo antes de la implementación. Esto funciona siempre que la tabla DD03L se replique en el conjunto de datos de origen y el esquema de la tabla personalizada esté presente en esa tabla.
Por ejemplo, la siguiente configuración crea una secuencia de comandos de CDC para la tabla personalizada zztable_customer y una vista de tiempo de ejecución para detectar cambios en tiempo real en otra tabla personalizada llamada zzspecial_table:
- base_table: zztable_customer
load_frequency: "@daily"
- base_table: zzspecial_table
load_frequency: "RUNTIME"
Plantilla generada de ejemplo
La siguiente plantilla genera el procesamiento de los cambios. En este punto, se pueden modificar los campos, como el nombre del campo de marca de tiempo, o añadir operaciones:
MERGE `${target_table}` T
USING (
SELECT *
FROM `${base_table}`
WHERE
recordstamp > (
SELECT IF(
MAX(recordstamp) IS NOT NULL,
MAX(recordstamp),
TIMESTAMP("1940-12-25 05:30:00+00"))
FROM `${target_table}` )
) S
ON ${p_key}
WHEN MATCHED AND S.operation_flag='D' AND S.is_deleted = true THEN
DELETE
WHEN NOT MATCHED AND S.operation_flag='I' THEN
INSERT (${fields})
VALUES
(${fields})
WHEN MATCHED AND S.operation_flag='U' THEN
UPDATE SET
${update_fields}
Si tu empresa necesita estadísticas casi en tiempo real y la herramienta de replicación lo admite, la herramienta de implementación acepta la opción RUNTIME.
Esto significa que no se generará una secuencia de comandos de CDC. En su lugar, una vista analizaría y obtendría el registro más reciente disponible en el tiempo de ejecución para ofrecer una coherencia inmediata.
Estructura de directorios de los DAGs y las secuencias de comandos de CDC
La estructura del bucket de Cloud Storage para los DAGs de CDC de SAP espera que los archivos SQL se generen en /data/bq_data_replication, como en el siguiente ejemplo.
Puedes modificar esta ruta antes de la implementación. Si aún no tienes un entorno de Cloud Composer, puedes crear uno más adelante y mover los archivos al bucket de DAGs.
with airflow.DAG("CDC_BigQuery_${base table}",
template_searchpath=['/home/airflow/gcs/data/bq_data_replication/'], ##example
default_args=default_dag_args,
schedule_interval="${load_frequency}") as dag:
start_task = DummyOperator(task_id="start")
copy_records = BigQueryOperator(
task_id='merge_query_records',
sql="${query_file}",
create_disposition='CREATE_IF_NEEDED',
bigquery_conn_id="sap_cdc_bq", ## example
use_legacy_sql=False)
stop_task = DummyOperator (task_id="stop")
start_task >> copy_records >> stop_task
Las secuencias de comandos que procesan datos en Airflow o Cloud Composer se generan específicamente por separado de las secuencias de comandos específicas de Airflow. Esto te permite portar esas secuencias de comandos a otra herramienta que elijas.
Campos de CDC obligatorios para las operaciones MERGE
Especifique los siguientes parámetros para la generación automática de procesos por lotes de CDC:
- Proyecto y conjunto de datos de origen: conjunto de datos en el que se replican o se transmiten los datos de SAP. Para que las secuencias de comandos de CDC funcionen de forma predeterminada, las tablas deben tener un campo de marca de tiempo (llamado "recordstamp") y un campo de operación con los siguientes valores, todos ellos definidos durante la replicación:
- I: para insertar.
- A: para actualizar.
- D: para eliminar.
- Proyecto y conjunto de datos de destino para el procesamiento de CDC: el script generado crea de forma predeterminada las tablas a partir de una copia del conjunto de datos de origen si no existen.
- Tablas replicadas: tablas para las que se deben generar las secuencias de comandos.
- Frecuencia de procesamiento: siguiendo la notación Cron, indica la frecuencia con la que se espera que se ejecuten los DAGs.
- Segmento de Cloud Storage de destino en el que se copian los archivos de salida de CDC.
- Nombre de la conexión: el nombre de la conexión que usa Cloud Composer.
- (Opcional) Nombre de la tabla de destino: disponible si el resultado del procesamiento de CDC permanece en el mismo conjunto de datos que el destino.
Optimización del rendimiento de las tablas de CDC
En el caso de determinados conjuntos de datos de CDC, puede que te interese aprovechar las particiones de tablas, el clustering de tablas o ambos de BigQuery. Esta elección depende de los siguientes factores:
- Tamaño y datos de la tabla.
- Columnas disponibles en la tabla.
- Necesidad de datos en tiempo real con vistas.
- Datos materializados como tablas.
De forma predeterminada, los ajustes de CDC no aplican particiones ni agrupaciones de tablas.
Puedes configurarlo como quieras. Para crear tablas con particiones o clústeres, actualiza el archivo cdc_settings.yaml con las configuraciones pertinentes. Para obtener más información, consulta Partición de tablas y Configuración de clústeres.
- Esta función solo se aplica cuando un conjunto de datos de
cdc_settings.yamlse configura para la replicación como tabla (por ejemplo,load_frequency = "@daily") y no como vista (load_frequency = "RUNTIME"). - Una tabla puede ser tanto una tabla con particiones como una tabla agrupada en clústeres.
Si usas una herramienta de replicación que permite particiones en el conjunto de datos sin procesar, como el conector de BigQuery para SAP, te recomendamos que configures particiones basadas en el tiempo en las tablas sin procesar. El tipo de partición funciona mejor si coincide con la frecuencia de los DAGs de CDC en la configuración cdc_settings.yaml. Para obtener más información, consulta Consideraciones sobre el diseño para la modelización de datos de SAP en BigQuery.
Opcional: Configurar el módulo de inventario de SAP
El módulo de inventario de SAP de Cortex Framework incluye las vistas InventoryKeyMetrics
y InventoryByPlant, que proporcionan información valiosa sobre tu inventario.
Estas vistas se basan en tablas de instantáneas mensuales y semanales que usan DAGs especializados. Ambos se pueden ejecutar al mismo tiempo y no interferirán entre sí.
Para actualizar una o ambas tablas de la vista de resumen, sigue estos pasos:
Actualiza
SlowMovingThreshold.sqlyStockCharacteristicsConfig.sqlpara definir el umbral de movimiento lento y las características de las existencias de los diferentes tipos de material en función de tus requisitos.Para la carga inicial o la actualización completa, ejecuta los DAGs
Stock_Monthly_Snapshots_InitialyStock_Weekly_Snapshots_Initial.Para las actualizaciones posteriores, programa o ejecuta los siguientes DAGs:
- Novedades mensuales y semanales:
Stock_Monthly_Snapshots_Periodical_UpdateStock_Weekly_Snapshots_periodical_Update
- Actualización diaria:
Stock_Monthly_Snapshots_Daily_UpdateStock_Weekly_Snapshots_Update_Daily
- Novedades mensuales y semanales:
Actualiza las vistas intermedias
StockMonthlySnapshotsyStockWeeklySnapshots, seguidas de las vistasInventoryKeyMetricsyInventoryByPlants, respectivamente, para mostrar los datos actualizados.
Opcional: Configurar la vista Textos de jerarquía de productos
La vista Textos de jerarquía de productos aplana los materiales y sus jerarquías de productos. La tabla resultante se puede usar para proporcionar al complemento Trends una lista de términos para obtener Interés a lo largo del tiempo. Configura esta vista siguiendo estos pasos:
- Ajusta los niveles de la jerarquía y el idioma en el archivo
prod_hierarchy_texts.sql, en los marcadores de## CORTEX-CUSTOMER. Si su jerarquía de productos contiene más niveles, puede que tenga que añadir una instrucción SELECT adicional similar a la expresión de tabla común
h1_h2_h3.Puede haber personalizaciones adicionales en función de los sistemas de origen. Te recomendamos que los usuarios empresariales o los analistas participen en las primeras fases del proceso para detectar estos problemas.
Opcional: Configurar vistas de acoplamiento de jerarquía
A partir de la versión v6.0, Cortex Framework admite el acoplamiento de jerarquías como vistas de informes. Se trata de una mejora importante con respecto al aplanador de jerarquía antiguo, ya que ahora aplana toda la jerarquía, optimiza mejor S/4 al utilizar tablas específicas de S/4 en lugar de tablas ECC antiguas y también mejora significativamente el rendimiento.
Resumen de las vistas de informes
Busca las siguientes vistas relacionadas con el acoplamiento de jerarquía:
| Tipo de jerarquía | Tabla que solo contiene la jerarquía acoplada | Vistas para visualizar la jerarquía aplanada | Lógica de integración de pérdidas y ganancias con esta jerarquía |
| Versión de la información financiera (VIF) | fsv_glaccounts
|
FSVHierarchyFlattened
|
ProfitAndLossOverview
|
| Centro de beneficios | profit_centers
|
ProfitCenterHierarchyFlattened
|
ProfitAndLossOverview_ProfitCenterHierarchy
|
| Centro de costes | cost_centers
|
CostCenterHierarchyFlattened
|
ProfitAndLossOverview_CostCenterHierarchy
|
Ten en cuenta lo siguiente al usar vistas de aplanamiento de jerarquía:
- Las vistas de jerarquía combinada son funcionalmente equivalentes a las tablas generadas por la solución antigua de combinación de jerarquías.
- Las vistas generales no se implementan de forma predeterminada, ya que solo sirven para mostrar la lógica de la inteligencia empresarial. Busca su código fuente en el directorio
src/SAP/SAP_REPORTING.
Configurar el acoplamiento de jerarquías
En función de la jerarquía con la que estés trabajando, se requieren los siguientes parámetros de entrada:
| Tipo de jerarquía | Parámetro obligatorio | Campo de origen (ECC) | Campo de origen (S4) |
| Versión de la información financiera (VIF) | Gráfico de cuentas | ktopl
|
nodecls
|
| Nombre de la jerarquía | versn
|
hryid
|
|
| Centro de beneficios | Clase del conjunto | setclass
|
setclass
|
| Unidad organizativa: área de control o clave adicional del conjunto. | subclass
|
subclass
|
|
| Centro de costes | Clase del conjunto | setclass
|
setclass
|
| Unidad organizativa: área de control o clave adicional del conjunto. | subclass
|
subclass
|
Si no sabes con seguridad cuáles son los parámetros exactos, pregunta a un consultor de SAP de Finanzas o de Control.
Una vez que se hayan recogido los parámetros, actualice los comentarios ## CORTEX-CUSTOMER
de cada uno de los directorios correspondientes según sus requisitos:
| Tipo de jerarquía | Ubicación del código |
| Versión de la información financiera (VIF) | src/SAP/SAP_REPORTING/local_k9/fsv_hierarchy
|
| Centro de beneficios | src/SAP/SAP_REPORTING/local_k9/profitcenter_hierarchy
|
| Centro de costes | src/SAP/SAP_REPORTING/local_k9/costcenter_hierarchy
|
Si procede, asegúrate de actualizar los ## CORTEX-CUSTOMER comentarios de los informes correspondientes del directorio src/SAP/SAP_REPORTING.
Detalles de la solución
Las siguientes tablas de origen se usan para acoplar la jerarquía:
| Tipo de jerarquía | Source Tables (ECC) | Tablas de origen (S4) |
| Versión de la información financiera (VIF) |
|
|
| Centro de beneficios |
|
|
| Centro de costes |
|
|
Visualizar las jerarquías
La solución de aplanamiento de la jerarquía de SAP de Cortex aplana toda la jerarquía. Si quieres crear una representación visual de la jerarquía cargada que sea comparable a lo que muestra SAP en la interfaz de usuario, consulta una de las vistas para visualizar jerarquías acopladas con la condición IsLeafNode=True.
Migrar de la solución antigua de acoplamiento de jerarquías
Para migrar de la solución de acoplamiento de jerarquía antigua anterior a Cortex v6.0, sustituya las tablas tal como se muestra en la siguiente tabla. Asegúrate de que los nombres de los campos sean correctos, ya que algunos se han modificado ligeramente. Por ejemplo, prctr en cepc_hier
ahora es profitcenter en la tabla profit_centers.
| Tipo de jerarquía | Sustituir esta tabla: | Con: |
| Versión de la información financiera (VIF) | ska1_hier
|
fsv_glaccounts
|
| Centro de beneficios | cepc_hier
|
profit_centers
|
| Centro de costes | csks_hier
|
cost_centers
|
Opcional: Configurar el módulo de finanzas de SAP
El módulo de finanzas de SAP de Cortex Framework incluye las vistas FinancialStatement,
BalanceSheet y ProfitAndLoss, que proporcionan estadísticas financieras clave.
Para actualizar estas tablas de Finanzas, sigue estos pasos:
Para la carga inicial
- Después de la implementación, asegúrate de que el conjunto de datos de CDC se rellena correctamente (ejecuta los DAGs de CDC que sean necesarios).
- Asegúrese de que las vistas de acoplamiento de jerarquía estén configuradas correctamente para los tipos de jerarquías que utilice (FSV, centro de costes y centro de beneficios).
Ejecuta el DAG
financial_statement_initial_load.Si se implementan como tablas (opción recomendada), actualiza los siguientes elementos en orden ejecutando sus DAGs correspondientes:
Financial_StatementsBalanceSheetsProfitAndLoss
Para la actualización periódica
- Asegúrese de que las vistas de acoplamiento de jerarquía estén configuradas correctamente y actualizadas para los tipos de jerarquías que utilice (FSV, centro de costes y centro de beneficios).
Programar o ejecutar un
financial_statement_periodical_loadDAG.Si se implementan como tablas (opción recomendada), actualiza los siguientes elementos en orden ejecutando sus DAGs correspondientes:
Financial_StatementsBalanceSheetsProfitAndLoss
Para visualizar los datos de estas tablas, consulta las siguientes vistas de resumen:
ProfitAndLossOverview.sqlsi usas la jerarquía de la variante de balance.ProfitAndLossOverview_CostCenter.sqlsi utiliza la jerarquía de centros de costes.ProfitAndLossOverview_ProfitCenter.sqlsi usa la jerarquía de Profit Center.
Opcional: Habilitar DAGs dependientes de tareas
Cortex Framework ofrece de forma opcional ajustes de dependencia recomendados para la mayoría de las tablas SQL de SAP (ECC y S/4 HANA), donde todas las tablas dependientes se pueden actualizar con un solo DAG. Puedes personalizarlos aún más. Para obtener más información, consulta DAGs dependientes de tareas.
Siguientes pasos
- Para obtener más información sobre otras fuentes de datos y cargas de trabajo, consulta el artículo Fuentes de datos y cargas de trabajo.
- Para obtener más información sobre los pasos para la implementación en entornos de producción, consulta los requisitos previos para la implementación de Data Foundation de Cortex Framework.