Paso 1: Establece las cargas de trabajo
En esta página se explica el primer paso para configurar tu infraestructura de datos, que es el núcleo de Cortex Framework. La base de datos, que se basa en el almacenamiento de BigQuery, organiza los datos entrantes de varias fuentes. Estos datos organizados simplifican el análisis y su aplicación en el desarrollo de la IA.
Configurar la integración de datos
Empieza definiendo algunos parámetros clave que sirvan de guía para organizar y usar tus datos de forma eficiente en Cortex Framework. Recuerda que estos parámetros pueden variar en función de la carga de trabajo específica, el flujo de datos que elijas y el mecanismo de integración. En el siguiente diagrama se muestra una descripción general de la integración de datos en la base de datos de Cortex Framework:

Define los siguientes parámetros antes de la implementación para que el uso de los datos en Cortex Framework sea eficiente y eficaz.
Proyectos
- Proyecto de origen: proyecto en el que se encuentran los datos sin procesar. Necesitas al menos un Google Cloud proyecto para almacenar datos y ejecutar el proceso de implementación.
- Proyecto de destino (opcional): proyecto en el que Cortex Framework Data Foundation almacena sus modelos de datos procesados. Puede ser el mismo que el proyecto de origen o uno diferente, según tus necesidades.
Si quieres tener conjuntos de proyectos y conjuntos de datos independientes para cada carga de trabajo (por ejemplo, un conjunto de proyectos de origen y de destino para SAP y otro conjunto de proyectos de origen y de destino para Salesforce), ejecuta implementaciones independientes para cada carga de trabajo. Para obtener más información, consulta la sección Usar diferentes proyectos para segregar el acceso de los pasos opcionales.
Modelo de datos
- Desplegar modelos: elige si necesitas desplegar modelos para todas las cargas de trabajo o solo para un conjunto de modelos (por ejemplo, SAP, Salesforce y Meta). Para obtener más información, consulta las fuentes de datos y las cargas de trabajo disponibles.
Conjuntos de datos de BigQuery
- Conjunto de datos de origen (sin procesar): conjunto de datos de BigQuery en el que se replica el origen de los datos o en el que se crean los datos de prueba. Le recomendamos que tenga conjuntos de datos independientes, uno por cada fuente de datos. Por ejemplo, un conjunto de datos sin procesar para SAP y otro para Google Ads. Este conjunto de datos pertenece al proyecto de origen.
- Conjunto de datos de CDC: conjunto de datos de BigQuery en el que se almacenan los registros más recientes disponibles de los datos procesados de CDC. Algunas cargas de trabajo permiten asignar nombres de campos. Recomendamos tener un conjunto de datos de CDC independiente para cada fuente. Por ejemplo, un conjunto de datos de CDC para SAP y otro para Salesforce. Este conjunto de datos pertenece al proyecto de origen.
- Conjunto de datos de informes de destino: conjunto de datos de BigQuery en el que se implementan los modelos de datos predefinidos de Data Foundation. Te recomendamos que tengas un conjunto de datos de informes independiente para cada fuente. Por ejemplo, un conjunto de datos de informes para SAP y otro para Salesforce. Este conjunto de datos se crea automáticamente durante la implementación si no existe. Este conjunto de datos pertenece al proyecto de destino.
- Preprocesamiento del conjunto de datos K9: conjunto de datos de BigQuery en el que se pueden desplegar componentes de DAG reutilizables y entre cargas de trabajo, como las dimensiones
time. Las cargas de trabajo dependen de este conjunto de datos, a menos que se modifiquen. Este conjunto de datos se crea automáticamente durante la implementación si no existe. Este conjunto de datos pertenece al proyecto de origen. - Conjunto de datos K9 de posprocesamiento: conjunto de datos de BigQuery en el que se pueden implementar informes entre cargas de trabajo y DAGs de fuentes externas adicionales (por ejemplo, la ingestión de Google Trends). Este conjunto de datos se crea automáticamente durante la implementación si no existe. Este conjunto de datos pertenece al proyecto de destino.
Opcional: Generar datos de muestra
Cortex Framework puede generar datos y tablas de ejemplo si no tienes acceso a tus propios datos, a herramientas de replicación para configurar datos o si solo quieres ver cómo funciona Cortex Framework. Sin embargo, debes crear e identificar los conjuntos de datos de CDC y sin procesar con antelación.
Crea conjuntos de datos de BigQuery para los datos sin procesar y los datos de CDC por fuente de datos siguiendo estas instrucciones.
Consola
Abre la página de BigQuery en la Google Cloud consola.
En el panel Explorador, selecciona el proyecto en el que quieras crear el conjunto de datos.
Abre la opción Acciones y haz clic en Crear conjunto de datos:
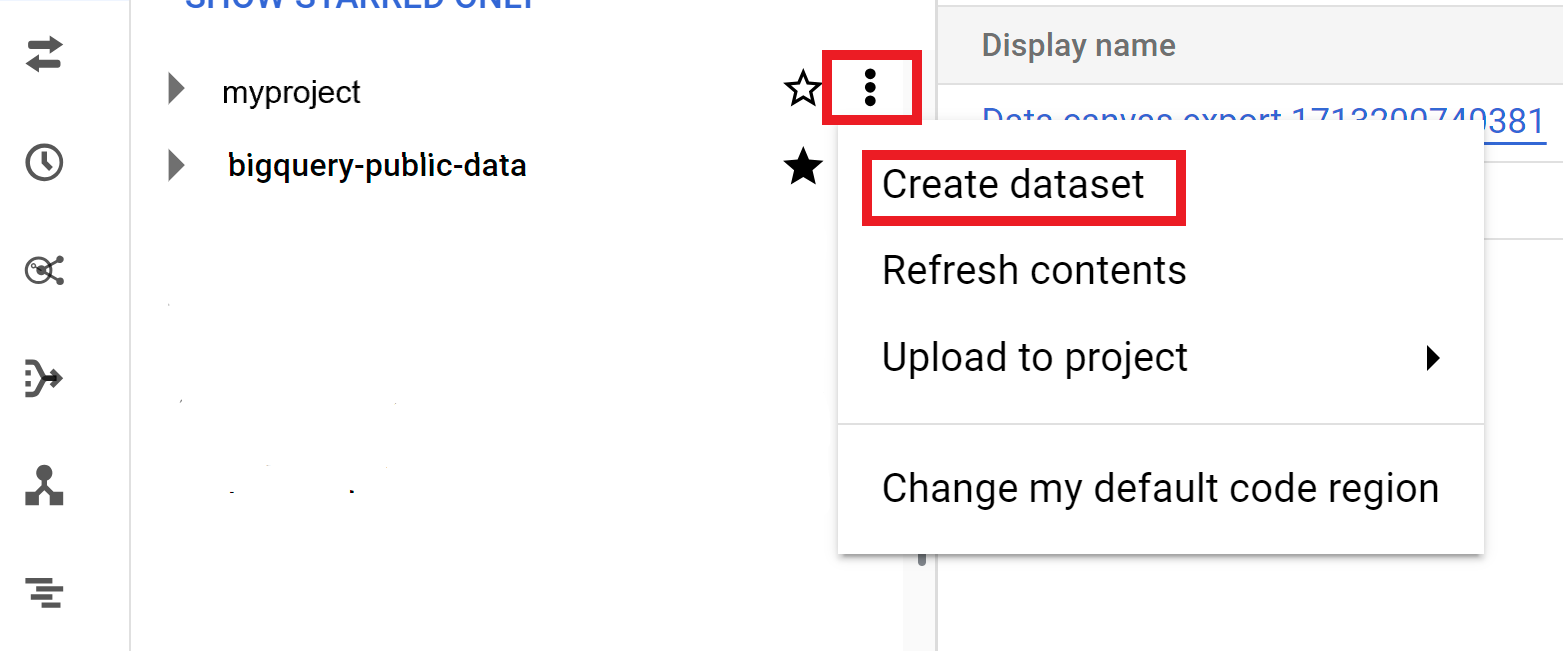
En la página Crear conjunto de datos, haz lo siguiente:
- En ID del conjunto de datos, introduce un nombre único para el conjunto de datos.
En Tipo de ubicación, elija una ubicación geográfica del conjunto de datos. Una vez creado un conjunto de datos, no se puede cambiar su ubicación.
Opcional. Para obtener más información sobre cómo personalizar un conjunto de datos, consulta el artículo Crear conjuntos de datos: consola.
Haz clic en Crear conjunto de datos.
BigQuery
Crea un conjunto de datos para los datos sin procesar copiando el siguiente comando:
bq --location= LOCATION mk -d SOURCE_PROJECT: DATASET_RAWHaz los cambios siguientes:
LOCATIONcon la ubicación del conjunto de datos.SOURCE_PROJECTpor el ID de tu proyecto de origen.DATASET_RAWcon el nombre del conjunto de datos de datos sin procesar. Por ejemplo,CORTEX_SFDC_RAW.
Crea un conjunto de datos para los datos de CDC copiando el siguiente comando:
bq --location=LOCATION mk -d SOURCE_PROJECT: DATASET_CDCHaz los cambios siguientes:
LOCATIONcon la ubicación del conjunto de datos.SOURCE_PROJECTpor el ID de tu proyecto de origen.DATASET_CDCcon el nombre del conjunto de datos de datos de CDC. Por ejemplo,CORTEX_SFDC_CDC.
Confirma que los conjuntos de datos se han creado con el siguiente comando:
bq lsOpcional. Para obtener más información sobre cómo crear conjuntos de datos, consulta el artículo Crear conjuntos de datos.
Pasos siguientes
Cuando haya completado este paso, siga los pasos de implementación que se indican a continuación:
- Establecer cargas de trabajo (esta página).
- Clonar repositorio.
- Determina el mecanismo de integración.
- Configura los componentes.
- Configurar la implementación.
- Ejecuta la implementación.