Am 15. September 2026erreichen alle Cloud Composer 1- und Cloud Composer 2-Umgebungen der Version 2.0.x das geplante Ende des Lebenszyklus und können nicht mehr verwendet werden. Wir empfehlen, die Migration zu Cloud Composer 3 zu planen.
Auf dieser Seite wird beschrieben, wie Sie mit den Google Kubernetes Engine-Operatoren Cluster in Google Kubernetes Engine erstellen und Kubernetes-Pods in diesen Clustern starten.
Mit Google Kubernetes Engine-Operatoren werden Kubernetes-Pods in einem bestimmten Cluster ausgeführt. Dabei kann es sich um einen separaten Cluster handeln, der nicht mit Ihrer Umgebung in Verbindung steht.
Im Vergleich dazu führt KubernetesPodOperatorKubernetes-Pods im Cluster Ihrer Umgebung aus.
Auf dieser Seite werden Sie Schritt für Schritt durch einen Beispiel-DAG geführt, mit dem ein Google Kubernetes Engine-Cluster mit dem GKECreateClusterOperator erstellt wird, der verwendet den GKEStartPodOperator mit den folgenden Konfigurationen und löscht den Cluster dann mit GKEDeleteClusterOperator danach:
Wir empfehlen die Verwendung der neuesten Version von Cloud Composer. Diese Version muss mindestens im Rahmen der Einstellungs- und Supportrichtlinie unterstützt werden.
GKE-Operatorkonfiguration
Zum Ausführen dieses Beispiels legen Sie die gesamte gke_operator.py-Datei in den Ordner dags/ Ihrer Umgebung. Alternativ können Sie den entsprechenden Code einem DAG hinzufügen.
Cluster erstellen
Der hier gezeigte Code erstellt einen Google Kubernetes Engine-Cluster mit zwei Knotenpools, pool-0 und pool-1, die jeweils einen Knoten haben. Bei Bedarf können Sie weitere Parameter aus der Google Kubernetes Engine API als Teil von body festlegen.
Wir empfehlen die Verwendung regionaler Cluster in Airflow 2. Zonale Cluster sind anfälliger für zonale Fehler. Sie können beispielsweise die Region us-central1 für Ihren Cluster anstelle der Zone us-central1-a verwenden.
Weitere Informationen zu regionsspezifischen Aspekten finden Sie unter Geografie und Regionen.
Vor dem Release von apache-airflow-providers-google Version 5.1.0 konnte das node_pools-Objekt nicht im GKECreateClusterOperator übergeben werden. Wenn Sie Airflow 2 verwenden, achten Sie darauf, dass Ihre Umgebung apache-airflow-providers-google Version 5.1.0 oder höher verwendet. Sie können eine neuere Version dieses PyPI-Pakets installieren, indem Sie apache-airflow-providers-google und >=5.1.0 als erforderliche Version angeben.
Als Behelfslösung für Airflow-1-Nutzer verwenden wir die BashOperator und gcloud, um diese Knotenpools zu erstellen.
Airflow 2
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"CLUSTER={"name":CLUSTER_NAME,"node_pools":[{"name":"pool-0","initial_node_count":1},{"name":"pool-1","initial_node_count":1},],}create_cluster=GKECreateClusterOperator(task_id="create_cluster",project_id=PROJECT_ID,location=CLUSTER_REGION,body=CLUSTER,)
Airflow 1
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"CLUSTER_ZONE="us-west1-a"CLUSTER_NAME="example-cluster"CLUSTER={"name":CLUSTER_NAME,"initial_node_count":1}create_cluster=GKECreateClusterOperator(task_id="create_cluster",project_id=PROJECT_ID,location=CLUSTER_ZONE,body=CLUSTER,)# Using the BashOperator to create node pools is a workaround# In Airflow 2, because of https://github.com/apache/airflow/pull/17820# Node pool creation can be done using the GKECreateClusterOperatorcreate_node_pools=BashOperator(task_id="create_node_pools",bash_command=f"gcloud container node-pools create pool-0 \ --cluster {CLUSTER_NAME}\ --num-nodes 1 \ --zone {CLUSTER_ZONE}\ && gcloud container node-pools create pool-1 \ --cluster {CLUSTER_NAME}\ --num-nodes 1 \ --zone {CLUSTER_ZONE}",)
Arbeitslasten im Cluster starten
In den folgenden Abschnitten wird jede GKEStartPodOperator-Konfiguration im Beispiel erläutert. Informationen zu den einzelnen Konfigurationsvariablen finden Sie in der Airflow-Referenz für GKE-Operatoren.
Airflow 2
fromairflowimportmodelsfromairflow.providers.google.cloud.operators.kubernetes_engineimport(GKECreateClusterOperator,GKEDeleteClusterOperator,GKEStartPodOperator,)fromairflow.utils.datesimportdays_agofromkubernetes.clientimportmodelsask8s_modelswithmodels.DAG("example_gcp_gke",schedule_interval=None,# Override to match your needsstart_date=days_ago(1),tags=["example"],)asdag:# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"CLUSTER={"name":CLUSTER_NAME,"node_pools":[{"name":"pool-0","initial_node_count":1},{"name":"pool-1","initial_node_count":1},],}create_cluster=GKECreateClusterOperator(task_id="create_cluster",project_id=PROJECT_ID,location=CLUSTER_REGION,body=CLUSTER,)kubernetes_min_pod=GKEStartPodOperator(# The ID specified for the task.task_id="pod-ex-minimum",# Name of task you want to run, used to generate Pod ID.name="pod-ex-minimum",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# The namespace to run within Kubernetes, default namespace is# `default`.namespace="default",# Docker image specified. Defaults to hub.docker.com, but any fully# qualified URLs will point to a custom repository. Supports private# gcr.io images if the Composer Environment is under the same# project-id as the gcr.io images and the service account that Composer# uses has permission to access the Google Container Registry# (the default service account has permission)image="gcr.io/gcp-runtimes/ubuntu_18_0_4",)kubenetes_template_ex=GKEStartPodOperator(task_id="ex-kube-templates",name="ex-kube-templates",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="bash",# All parameters below are able to be templated with jinja -- cmds,# arguments, env_vars, and config_file. For more information visit:# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# DS in jinja is the execution date as YYYY-MM-DD, this docker image# will echo the execution date. Arguments to the entrypoint. The docker# image's CMD is used if this is not provided. The arguments parameter# is templated.arguments=["{{ ds }}"],# The var template variable allows you to access variables defined in# Airflow UI. In this case we are getting the value of my_value and# setting the environment variable `MY_VALUE`. The pod will fail if# `my_value` is not set in the Airflow UI.env_vars={"MY_VALUE":"{{ var.value.my_value }}"},)kubernetes_affinity_ex=GKEStartPodOperator(task_id="ex-pod-affinity",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,name="ex-pod-affinity",namespace="default",image="perl",cmds=["perl"],arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# affinity allows you to constrain which nodes your pod is eligible to# be scheduled on, based on labels on the node. In this case, if the# label 'cloud.google.com/gke-nodepool' with value# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any# nodes, it will fail to schedule.affinity={"nodeAffinity":{# requiredDuringSchedulingIgnoredDuringExecution means in order# for a pod to be scheduled on a node, the node must have the# specified labels. However, if labels on a node change at# runtime such that the affinity rules on a pod are no longer# met, the pod will still continue to run on the node."requiredDuringSchedulingIgnoredDuringExecution":{"nodeSelectorTerms":[{"matchExpressions":[{# When nodepools are created in Google Kubernetes# Engine, the nodes inside of that nodepool are# automatically assigned the label# 'cloud.google.com/gke-nodepool' with the value of# the nodepool's name."key":"cloud.google.com/gke-nodepool","operator":"In",# The label key's value that pods can be scheduled# on."values":["pool-1",],}]}]}}},)kubernetes_full_pod=GKEStartPodOperator(task_id="ex-all-configs",name="full",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="perl:5.34.0",# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["perl"],# Arguments to the entrypoint. The docker image's CMD is used if this# is not provided. The arguments parameter is templated.arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# The secrets to pass to Pod, the Pod will fail to create if the# secrets you specify in a Secret object do not exist in Kubernetes.secrets=[],# Labels to apply to the Pod.labels={"pod-label":"label-name"},# Timeout to start up the Pod, default is 120.startup_timeout_seconds=120,# The environment variables to be initialized in the container# env_vars are templated.env_vars={"EXAMPLE_VAR":"/example/value"},# If true, logs stdout output of container. Defaults to True.get_logs=True,# Determines when to pull a fresh image, if 'IfNotPresent' will cause# the Kubelet to skip pulling an image if it already exists. If you# want to always pull a new image, set it to 'Always'.image_pull_policy="Always",# Annotations are non-identifying metadata you can attach to the Pod.# Can be a large range of data, and can include characters that are not# permitted by labels.annotations={"key1":"value1"},# Optional resource specifications for Pod, this will allow you to# set both cpu and memory limits and requirements.# Prior to Airflow 2.3 and the cncf providers package 5.0.0# resources were passed as a dictionary. This change was made in# https://github.com/apache/airflow/pull/27197# Additionally, "memory" and "cpu" were previously named# "limit_memory" and "limit_cpu"# resources={'limit_memory': "250M", 'limit_cpu': "100m"},container_resources=k8s_models.V1ResourceRequirements(limits={"memory":"250M","cpu":"100m"},),# If true, the content of /airflow/xcom/return.json from container will# also be pushed to an XCom when the container ends.do_xcom_push=False,# List of Volume objects to pass to the Pod.volumes=[],# List of VolumeMount objects to pass to the Pod.volume_mounts=[],# Affinity determines which nodes the Pod can run on based on the# config. For more information see:# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/affinity={},)delete_cluster=GKEDeleteClusterOperator(task_id="delete_cluster",name=CLUSTER_NAME,project_id=PROJECT_ID,location=CLUSTER_REGION,)create_cluster >> kubernetes_min_pod >> delete_clustercreate_cluster >> kubernetes_full_pod >> delete_clustercreate_cluster >> kubernetes_affinity_ex >> delete_clustercreate_cluster >> kubenetes_template_ex >> delete_cluster
Airflow 1
fromairflowimportmodelsfromairflow.operators.bash_operatorimportBashOperatorfromairflow.providers.google.cloud.operators.kubernetes_engineimport(GKECreateClusterOperator,GKEDeleteClusterOperator,GKEStartPodOperator,)fromairflow.utils.datesimportdays_agowithmodels.DAG("example_gcp_gke",schedule_interval=None,# Override to match your needsstart_date=days_ago(1),tags=["example"],)asdag:# TODO(developer): update with your valuesPROJECT_ID="my-project-id"CLUSTER_ZONE="us-west1-a"CLUSTER_NAME="example-cluster"CLUSTER={"name":CLUSTER_NAME,"initial_node_count":1}create_cluster=GKECreateClusterOperator(task_id="create_cluster",project_id=PROJECT_ID,location=CLUSTER_ZONE,body=CLUSTER,)# Using the BashOperator to create node pools is a workaround# In Airflow 2, because of https://github.com/apache/airflow/pull/17820# Node pool creation can be done using the GKECreateClusterOperatorcreate_node_pools=BashOperator(task_id="create_node_pools",bash_command=f"gcloud container node-pools create pool-0 \ --cluster {CLUSTER_NAME}\ --num-nodes 1 \ --zone {CLUSTER_ZONE}\ && gcloud container node-pools create pool-1 \ --cluster {CLUSTER_NAME}\ --num-nodes 1 \ --zone {CLUSTER_ZONE}",)kubernetes_min_pod=GKEStartPodOperator(# The ID specified for the task.task_id="pod-ex-minimum",# Name of task you want to run, used to generate Pod ID.name="pod-ex-minimum",project_id=PROJECT_ID,location=CLUSTER_ZONE,cluster_name=CLUSTER_NAME,# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# The namespace to run within Kubernetes, default namespace is# `default`.namespace="default",# Docker image specified. Defaults to hub.docker.com, but any fully# qualified URLs will point to a custom repository. Supports private# gcr.io images if the Composer Environment is under the same# project-id as the gcr.io images and the service account that Composer# uses has permission to access the Google Container Registry# (the default service account has permission)image="gcr.io/gcp-runtimes/ubuntu_18_0_4",)kubenetes_template_ex=GKEStartPodOperator(task_id="ex-kube-templates",name="ex-kube-templates",project_id=PROJECT_ID,location=CLUSTER_ZONE,cluster_name=CLUSTER_NAME,namespace="default",image="bash",# All parameters below are able to be templated with jinja -- cmds,# arguments, env_vars, and config_file. For more information visit:# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# DS in jinja is the execution date as YYYY-MM-DD, this docker image# will echo the execution date. Arguments to the entrypoint. The docker# image's CMD is used if this is not provided. The arguments parameter# is templated.arguments=["{{ ds }}"],# The var template variable allows you to access variables defined in# Airflow UI. In this case we are getting the value of my_value and# setting the environment variable `MY_VALUE`. The pod will fail if# `my_value` is not set in the Airflow UI.env_vars={"MY_VALUE":"{{ var.value.my_value }}"},)kubernetes_affinity_ex=GKEStartPodOperator(task_id="ex-pod-affinity",project_id=PROJECT_ID,location=CLUSTER_ZONE,cluster_name=CLUSTER_NAME,name="ex-pod-affinity",namespace="default",image="perl",cmds=["perl"],arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# affinity allows you to constrain which nodes your pod is eligible to# be scheduled on, based on labels on the node. In this case, if the# label 'cloud.google.com/gke-nodepool' with value# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any# nodes, it will fail to schedule.affinity={"nodeAffinity":{# requiredDuringSchedulingIgnoredDuringExecution means in order# for a pod to be scheduled on a node, the node must have the# specified labels. However, if labels on a node change at# runtime such that the affinity rules on a pod are no longer# met, the pod will still continue to run on the node."requiredDuringSchedulingIgnoredDuringExecution":{"nodeSelectorTerms":[{"matchExpressions":[{# When nodepools are created in Google Kubernetes# Engine, the nodes inside of that nodepool are# automatically assigned the label# 'cloud.google.com/gke-nodepool' with the value of# the nodepool's name."key":"cloud.google.com/gke-nodepool","operator":"In",# The label key's value that pods can be scheduled# on."values":["pool-1",],}]}]}}},)kubernetes_full_pod=GKEStartPodOperator(task_id="ex-all-configs",name="full",project_id=PROJECT_ID,location=CLUSTER_ZONE,cluster_name=CLUSTER_NAME,namespace="default",image="perl",# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["perl"],# Arguments to the entrypoint. The docker image's CMD is used if this# is not provided. The arguments parameter is templated.arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# The secrets to pass to Pod, the Pod will fail to create if the# secrets you specify in a Secret object do not exist in Kubernetes.secrets=[],# Labels to apply to the Pod.labels={"pod-label":"label-name"},# Timeout to start up the Pod, default is 120.startup_timeout_seconds=120,# The environment variables to be initialized in the container# env_vars are templated.env_vars={"EXAMPLE_VAR":"/example/value"},# If true, logs stdout output of container. Defaults to True.get_logs=True,# Determines when to pull a fresh image, if 'IfNotPresent' will cause# the Kubelet to skip pulling an image if it already exists. If you# want to always pull a new image, set it to 'Always'.image_pull_policy="Always",# Annotations are non-identifying metadata you can attach to the Pod.# Can be a large range of data, and can include characters that are not# permitted by labels.annotations={"key1":"value1"},# Resource specifications for Pod, this will allow you to set both cpu# and memory limits and requirements.# Prior to Airflow 1.10.4, resource specifications were# passed as a Pod Resources Class object,# If using this example on a version of Airflow prior to 1.10.4,# import the "pod" package from airflow.contrib.kubernetes and use# resources = pod.Resources() instead passing a dict# For more info see:# https://github.com/apache/airflow/pull/4551resources={"limit_memory":"250M","limit_cpu":"100m"},# If true, the content of /airflow/xcom/return.json from container will# also be pushed to an XCom when the container ends.do_xcom_push=False,# List of Volume objects to pass to the Pod.volumes=[],# List of VolumeMount objects to pass to the Pod.volume_mounts=[],# Affinity determines which nodes the Pod can run on based on the# config. For more information see:# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/affinity={},)delete_cluster=GKEDeleteClusterOperator(task_id="delete_cluster",name=CLUSTER_NAME,project_id=PROJECT_ID,location=CLUSTER_ZONE,)create_cluster >> create_node_pools >> kubernetes_min_pod >> delete_clustercreate_cluster >> create_node_pools >> kubernetes_full_pod >> delete_clustercreate_cluster >> create_node_pools >> kubernetes_affinity_ex >> delete_clustercreate_cluster >> create_node_pools >> kubenetes_template_ex >> delete_cluster
Minimalkonfiguration
Zum Starten eines Pods in Ihrem GKE-Cluster mit GKEStartPodOperator sind nur project_id, location, cluster_name, name, namespace und image und task_id erforderlich.
Wenn Sie das folgende Code-Snippet in einen DAG einfügen, ist die Aufgabe pod-ex-minimum erfolgreich, solange die zuvor aufgeführten Parameter definiert und gültig sind.
Airflow 2
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubernetes_min_pod=GKEStartPodOperator(# The ID specified for the task.task_id="pod-ex-minimum",# Name of task you want to run, used to generate Pod ID.name="pod-ex-minimum",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# The namespace to run within Kubernetes, default namespace is# `default`.namespace="default",# Docker image specified. Defaults to hub.docker.com, but any fully# qualified URLs will point to a custom repository. Supports private# gcr.io images if the Composer Environment is under the same# project-id as the gcr.io images and the service account that Composer# uses has permission to access the Google Container Registry# (the default service account has permission)image="gcr.io/gcp-runtimes/ubuntu_18_0_4",)
Airflow 1
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"CLUSTER_ZONE="us-west1-a"CLUSTER_NAME="example-cluster"kubernetes_min_pod=GKEStartPodOperator(# The ID specified for the task.task_id="pod-ex-minimum",# Name of task you want to run, used to generate Pod ID.name="pod-ex-minimum",project_id=PROJECT_ID,location=CLUSTER_ZONE,cluster_name=CLUSTER_NAME,# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# The namespace to run within Kubernetes, default namespace is# `default`.namespace="default",# Docker image specified. Defaults to hub.docker.com, but any fully# qualified URLs will point to a custom repository. Supports private# gcr.io images if the Composer Environment is under the same# project-id as the gcr.io images and the service account that Composer# uses has permission to access the Google Container Registry# (the default service account has permission)image="gcr.io/gcp-runtimes/ubuntu_18_0_4",)
Vorlagenkonfiguration
Airflow unterstützt die Verwendung von Jinja-Vorlagen.
Sie müssen die erforderlichen Variablen (task_id, name, namespace, image) mit dem Operator deklarieren. Wie im folgenden Beispiel gezeigt, können Sie alle anderen Parameter mit Jinja als Vorlage verwenden, einschließlich cmds, arguments, env_vars.
Wenn der DAG oder die Umgebung nicht geändert wird, schlägt die Aufgabe ex-kube-templates fehl. Legen Sie eine Airflow-Variable mit dem Namen my_value fest, damit dieser DAG erfolgreich ist.
So legen Sie my_value mit gcloud oder der Airflow-UI fest:
LOCATION durch die Region, in der sich die Umgebung befindet.
Airflow-UI
In der Airflow 2-UI:
Klicken Sie in der Symbolleiste auf Admin > Variables.
Klicken Sie auf der Seite Listenvariable auf Neuen Eintrag hinzufügen.
Geben Sie auf der Seite Add Variable (Variable hinzufügen) die folgenden Informationen ein:
Key: my_value
Val: example_value
Klicken Sie auf Speichern.
In der Airflow 1-UI:
Klicken Sie in der Symbolleiste auf Admin > Variables.
Klicken Sie auf der Seite Variablen auf den Tab Erstellen.
Geben Sie auf der Seite Variable die folgenden Informationen ein:
Key: my_value
Val: example_value
Klicken Sie auf Speichern.
Vorlagenkonfiguration
Airflow 2
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubenetes_template_ex=GKEStartPodOperator(task_id="ex-kube-templates",name="ex-kube-templates",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="bash",# All parameters below are able to be templated with jinja -- cmds,# arguments, env_vars, and config_file. For more information visit:# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# DS in jinja is the execution date as YYYY-MM-DD, this docker image# will echo the execution date. Arguments to the entrypoint. The docker# image's CMD is used if this is not provided. The arguments parameter# is templated.arguments=["{{ ds }}"],# The var template variable allows you to access variables defined in# Airflow UI. In this case we are getting the value of my_value and# setting the environment variable `MY_VALUE`. The pod will fail if# `my_value` is not set in the Airflow UI.env_vars={"MY_VALUE":"{{ var.value.my_value }}"},)
Airflow 1
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"CLUSTER_ZONE="us-west1-a"CLUSTER_NAME="example-cluster"kubenetes_template_ex=GKEStartPodOperator(task_id="ex-kube-templates",name="ex-kube-templates",project_id=PROJECT_ID,location=CLUSTER_ZONE,cluster_name=CLUSTER_NAME,namespace="default",image="bash",# All parameters below are able to be templated with jinja -- cmds,# arguments, env_vars, and config_file. For more information visit:# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# DS in jinja is the execution date as YYYY-MM-DD, this docker image# will echo the execution date. Arguments to the entrypoint. The docker# image's CMD is used if this is not provided. The arguments parameter# is templated.arguments=["{{ ds }}"],# The var template variable allows you to access variables defined in# Airflow UI. In this case we are getting the value of my_value and# setting the environment variable `MY_VALUE`. The pod will fail if# `my_value` is not set in the Airflow UI.env_vars={"MY_VALUE":"{{ var.value.my_value }}"},)
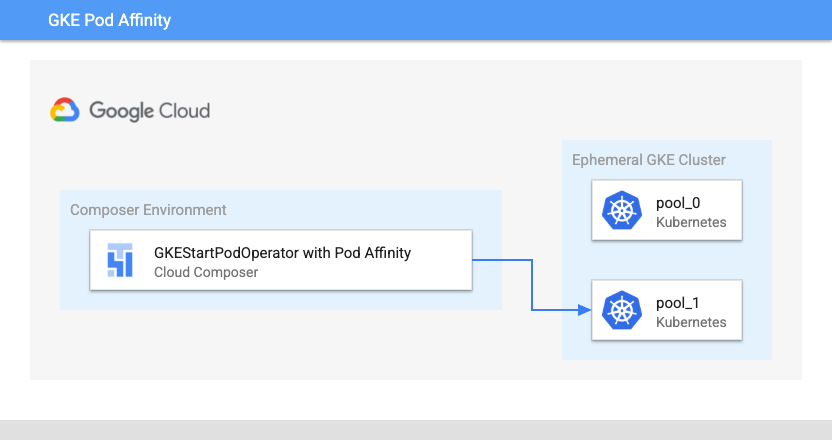
Pod-Affinitätskonfiguration
Mit der Konfiguration des Parameters affinity in GKEStartPodOperator können Sie steuern, auf welchen Knoten Pods geplant werden sollen, beispielsweise nur auf Knoten in einem bestimmten Knotenpool. Beim Erstellen des Clusters haben Sie zwei Knotenpools mit den Namen pool-0 und pool-1 erstellt. Dieser Operator legt fest, dass Pods nur in pool-1 ausgeführt werden dürfen.
Startort des Cloud Composer-Kubernetes-Pods mit Pod-Affinität (zum Vergrößern klicken)
Airflow 2
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubernetes_affinity_ex=GKEStartPodOperator(task_id="ex-pod-affinity",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,name="ex-pod-affinity",namespace="default",image="perl",cmds=["perl"],arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# affinity allows you to constrain which nodes your pod is eligible to# be scheduled on, based on labels on the node. In this case, if the# label 'cloud.google.com/gke-nodepool' with value# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any# nodes, it will fail to schedule.affinity={"nodeAffinity":{# requiredDuringSchedulingIgnoredDuringExecution means in order# for a pod to be scheduled on a node, the node must have the# specified labels. However, if labels on a node change at# runtime such that the affinity rules on a pod are no longer# met, the pod will still continue to run on the node."requiredDuringSchedulingIgnoredDuringExecution":{"nodeSelectorTerms":[{"matchExpressions":[{# When nodepools are created in Google Kubernetes# Engine, the nodes inside of that nodepool are# automatically assigned the label# 'cloud.google.com/gke-nodepool' with the value of# the nodepool's name."key":"cloud.google.com/gke-nodepool","operator":"In",# The label key's value that pods can be scheduled# on."values":["pool-1",],}]}]}}},)
Airflow 1
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"CLUSTER_ZONE="us-west1-a"CLUSTER_NAME="example-cluster"kubernetes_affinity_ex=GKEStartPodOperator(task_id="ex-pod-affinity",project_id=PROJECT_ID,location=CLUSTER_ZONE,cluster_name=CLUSTER_NAME,name="ex-pod-affinity",namespace="default",image="perl",cmds=["perl"],arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# affinity allows you to constrain which nodes your pod is eligible to# be scheduled on, based on labels on the node. In this case, if the# label 'cloud.google.com/gke-nodepool' with value# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any# nodes, it will fail to schedule.affinity={"nodeAffinity":{# requiredDuringSchedulingIgnoredDuringExecution means in order# for a pod to be scheduled on a node, the node must have the# specified labels. However, if labels on a node change at# runtime such that the affinity rules on a pod are no longer# met, the pod will still continue to run on the node."requiredDuringSchedulingIgnoredDuringExecution":{"nodeSelectorTerms":[{"matchExpressions":[{# When nodepools are created in Google Kubernetes# Engine, the nodes inside of that nodepool are# automatically assigned the label# 'cloud.google.com/gke-nodepool' with the value of# the nodepool's name."key":"cloud.google.com/gke-nodepool","operator":"In",# The label key's value that pods can be scheduled# on."values":["pool-1",],}]}]}}},)
Vollständige Konfiguration
In diesem Beispiel werden alle Variablen gezeigt, die Sie in GKEStartPodOperator konfigurieren können. Sie müssen den Code nicht ändern, damit die Aufgabe ex-all-configs erfolgreich ausgeführt wird.
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubernetes_full_pod=GKEStartPodOperator(task_id="ex-all-configs",name="full",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="perl:5.34.0",# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["perl"],# Arguments to the entrypoint. The docker image's CMD is used if this# is not provided. The arguments parameter is templated.arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# The secrets to pass to Pod, the Pod will fail to create if the# secrets you specify in a Secret object do not exist in Kubernetes.secrets=[],# Labels to apply to the Pod.labels={"pod-label":"label-name"},# Timeout to start up the Pod, default is 120.startup_timeout_seconds=120,# The environment variables to be initialized in the container# env_vars are templated.env_vars={"EXAMPLE_VAR":"/example/value"},# If true, logs stdout output of container. Defaults to True.get_logs=True,# Determines when to pull a fresh image, if 'IfNotPresent' will cause# the Kubelet to skip pulling an image if it already exists. If you# want to always pull a new image, set it to 'Always'.image_pull_policy="Always",# Annotations are non-identifying metadata you can attach to the Pod.# Can be a large range of data, and can include characters that are not# permitted by labels.annotations={"key1":"value1"},# Optional resource specifications for Pod, this will allow you to# set both cpu and memory limits and requirements.# Prior to Airflow 2.3 and the cncf providers package 5.0.0# resources were passed as a dictionary. This change was made in# https://github.com/apache/airflow/pull/27197# Additionally, "memory" and "cpu" were previously named# "limit_memory" and "limit_cpu"# resources={'limit_memory': "250M", 'limit_cpu': "100m"},container_resources=k8s_models.V1ResourceRequirements(limits={"memory":"250M","cpu":"100m"},),# If true, the content of /airflow/xcom/return.json from container will# also be pushed to an XCom when the container ends.do_xcom_push=False,# List of Volume objects to pass to the Pod.volumes=[],# List of VolumeMount objects to pass to the Pod.volume_mounts=[],# Affinity determines which nodes the Pod can run on based on the# config. For more information see:# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/affinity={},)
Airflow 1
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"CLUSTER_ZONE="us-west1-a"CLUSTER_NAME="example-cluster"kubernetes_full_pod=GKEStartPodOperator(task_id="ex-all-configs",name="full",project_id=PROJECT_ID,location=CLUSTER_ZONE,cluster_name=CLUSTER_NAME,namespace="default",image="perl",# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["perl"],# Arguments to the entrypoint. The docker image's CMD is used if this# is not provided. The arguments parameter is templated.arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# The secrets to pass to Pod, the Pod will fail to create if the# secrets you specify in a Secret object do not exist in Kubernetes.secrets=[],# Labels to apply to the Pod.labels={"pod-label":"label-name"},# Timeout to start up the Pod, default is 120.startup_timeout_seconds=120,# The environment variables to be initialized in the container# env_vars are templated.env_vars={"EXAMPLE_VAR":"/example/value"},# If true, logs stdout output of container. Defaults to True.get_logs=True,# Determines when to pull a fresh image, if 'IfNotPresent' will cause# the Kubelet to skip pulling an image if it already exists. If you# want to always pull a new image, set it to 'Always'.image_pull_policy="Always",# Annotations are non-identifying metadata you can attach to the Pod.# Can be a large range of data, and can include characters that are not# permitted by labels.annotations={"key1":"value1"},# Resource specifications for Pod, this will allow you to set both cpu# and memory limits and requirements.# Prior to Airflow 1.10.4, resource specifications were# passed as a Pod Resources Class object,# If using this example on a version of Airflow prior to 1.10.4,# import the "pod" package from airflow.contrib.kubernetes and use# resources = pod.Resources() instead passing a dict# For more info see:# https://github.com/apache/airflow/pull/4551resources={"limit_memory":"250M","limit_cpu":"100m"},# If true, the content of /airflow/xcom/return.json from container will# also be pushed to an XCom when the container ends.do_xcom_push=False,# List of Volume objects to pass to the Pod.volumes=[],# List of VolumeMount objects to pass to the Pod.volume_mounts=[],# Affinity determines which nodes the Pod can run on based on the# config. For more information see:# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/affinity={},)
Cluster löschen
Der hier gezeigte Code löscht den Cluster, der zu Beginn der Anleitung erstellt wurde.
[[["Leicht verständlich","easyToUnderstand","thumb-up"],["Mein Problem wurde gelöst","solvedMyProblem","thumb-up"],["Sonstiges","otherUp","thumb-up"]],[["Schwer verständlich","hardToUnderstand","thumb-down"],["Informationen oder Beispielcode falsch","incorrectInformationOrSampleCode","thumb-down"],["Benötigte Informationen/Beispiele nicht gefunden","missingTheInformationSamplesINeed","thumb-down"],["Problem mit der Übersetzung","translationIssue","thumb-down"],["Sonstiges","otherDown","thumb-down"]],["Zuletzt aktualisiert: 2025-03-18 (UTC)."],[],[]]