Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Cette page explique comment accéder au tableau de bord de surveillance d'un environnement Cloud Composer et l'utiliser.
Pour en savoir plus sur des métriques spécifiques, consultez Surveiller les environnements avec Cloud Monitoring.
Accéder au tableau de bord de surveillance
Le tableau de bord de surveillance contient des métriques et des graphiques permettant de surveiller les tendances dans les exécutions de DAG dans votre environnement et d'identifier les problèmes liés aux composants Airflow et aux ressources Cloud Composer.
Pour accéder au tableau de bord de surveillance de votre environnement :
Dans la console Google Cloud , accédez à la page Environnements.
Dans la liste des environnements, cliquez sur le nom de votre environnement. La page Détails de l'environnement s'ouvre.
Accédez à l'onglet Surveillance.
Configurer des alertes pour les métriques
Vous pouvez configurer des alertes pour une métrique. Pour ce faire, cliquez sur l'icône en forme de cloche située dans l'angle de la carte de surveillance.
Afficher une métrique dans Monitoring
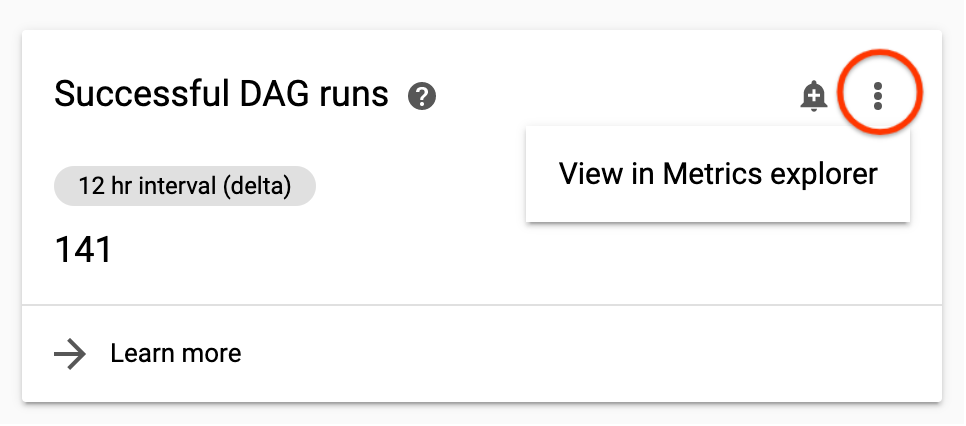
Vous pouvez examiner une métrique plus en détail dans Monitoring.
Pour y accéder à partir du tableau de bord de surveillance de Cloud Composer, cliquez sur les trois points en haut à droite d'une carte de métriques, puis sélectionnez Afficher dans l'explorateur de métriques.
Description des métriques
Chaque environnement Cloud Composer possède son propre tableau de bord de surveillance. Les métriques affichées sur un tableau de bord de surveillance pour un environnement spécifique ne suivent que les exécutions de DAG, les composants Airflow et les détails de l'environnement pour cet environnement. Par exemple, si vous avez deux environnements, le tableau de bord n'agrège pas les métriques des deux environnements.
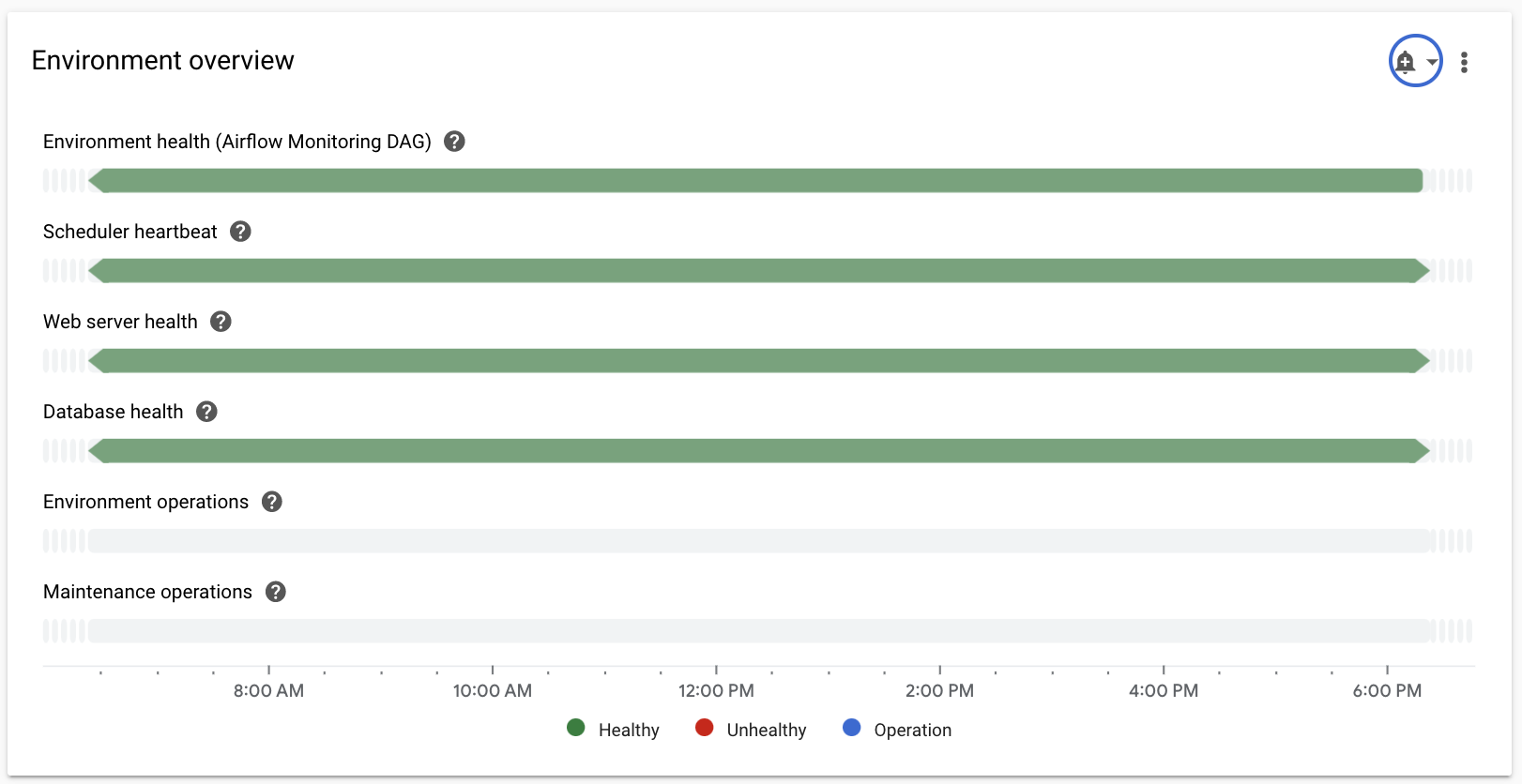
Vue d'ensemble de l'environnement
| Métrique d'environnement | Description |
|---|---|
| État de l'environnement (DAG de surveillance Airflow) | Chronologie indiquant l'état du déploiement de Composer. L'état vert ne reflète que l'état du déploiement de Composer. Cela ne signifie pas que tous les composants Airflow sont opérationnels et que les DAG peuvent être exécutés. |
| Pulsation du programmeur | Chronologie indiquant la pulsation du programmateur Airflow. Recherchez des zones rouges pour identifier les problèmes liés au planificateur Airflow. Si votre environnement comporte plusieurs planificateurs, l'état de pulsation est "OK" tant qu'au moins l'un d'eux répond. |
| État du serveur Web | Chronologie indiquant l'état du serveur Web Airflow. Cet état est généré en fonction des codes d'état HTTP renvoyés par le serveur Web Airflow. |
| État de la base de données | Chronologie indiquant l'état de la connexion à l'instance Cloud SQL qui héberge la base de données Airflow. |
| Opérations liées à l'environnement | Chronologie des opérations qui modifient l'environnement, telles que les mises à jour de configuration ou le chargement d'instantanés de l'environnement. |
| Opérations de maintenance | Timeline indiquant les périodes pendant lesquelles des opérations de maintenance sont effectuées sur le cluster de l'environnement. |
| Dépendances de l'environnement | Chronologie indiquant l'état des vérifications de l'accessibilité et des autorisations pour l'opération de l'environnement. |
Statistiques des DAG
| Métrique d'environnement | Description |
|---|---|
| Exécutions DAG ayant réussi | Nombre total d'exécutions réussies pour tous les DAG de l'environnement au cours de la période sélectionnée. Si le nombre d'exécutions DAG réussies est inférieur aux niveaux attendus, cela peut signifier des échecs (voir Échecs d'exécution DAG) ou un problème de programmation. |
| Exécutions de DAG ayant échoué Tâches ayant échoué | Nombre total d'exécutions ayant échoué pour tous les DAG de l'environnement au cours de la période sélectionnée. Nombre total de tâches ayant échoué dans l'environnement au cours de la période sélectionnée. Les tâches ayant échoué n'entraînent pas toujours l'échec de l'exécution d'un DAG, mais elles peuvent s'avérer utiles pour résoudre les erreurs de DAG. |
| Exécutions DAG terminées | Nombre de succès et d'échecs du DAG pour des intervalles dans la période sélectionnée. Cela peut aider à identifier les problèmes temporaires liés aux exécutions DAG et à les mettre en corrélation avec d'autres événements, tels que les évictions de pods de nœuds de calcul. |
| Tâches terminées | Nombre de tâches effectuées dans l'environnement avec une répartition des tâches réussies et ayant échoué. |
| Durée médiane d'une exécution DAG | Durée moyenne des exécutions DAG. Ce graphique permet d'identifier les problèmes de performances et d'identifier les tendances de la durée du DAG. |
| Tâches Airflow | Nombre de tâches en cours d'exécution, en file d'attente ou différées à un moment donné. Les tâches Airflow sont des tâches en file d'attente dans Airflow. Elles peuvent être placées dans la file d'attente de l'agent Celery ou de l'exécuteur Kubernetes. Les tâches en file d'attente Celery sont des instances de tâches placées dans la file d'attente de l'agent Celery. |
| Tâches zombie supprimées | Nombre de tâches zombies supprimées pendant une courte période. Les tâches zombies sont souvent provoquées par l'arrêt externe des processus Airflow. Le planificateur Airflow supprime régulièrement les tâches zombies, ce qui apparaît dans ce graphique. |
| Taille de sac du DAG | Nombre de DAG déployés dans le bucket de votre environnement et traités par Airflow à un moment donné. Cela peut être utile lors de l'analyse des goulots d'étranglement des performances. Par exemple, une augmentation du nombre de déploiements de DAG peut nuire aux performances en raison d'une charge excessive. |
| Erreurs du processeur DAG | Nombre d'erreurs et d'expirations de délai par seconde lors du traitement des fichiers DAG. La valeur indique la fréquence des erreurs signalées par le processeur DAG. Elle ne correspond pas au nombre de DAG ayant échoué. |
| Temps d'analyse total pour tous les DAG | Graphique indiquant le temps total nécessaire à Airflow pour traiter tous les DAG dans l'environnement. L'augmentation du temps d'analyse peut affecter l'efficacité de la programmation. Pour en savoir plus, consultez Différence entre le temps d'analyse du DAG et le temps d'exécution du DAG. |
Statistiques du planificateur
| Métrique d'environnement | Description |
|---|---|
| Pulsation du programmeur | Consultez Vue d'ensemble de l'environnement. |
| Utilisation totale du processeur par le planificateur | Utilisation totale des cœurs de vCPU par les conteneurs s'exécutant dans tous les pods de programmeurs Airflow, et limite combinée de vCPU pour tous les programmeurs. |
| Utilisation totale de la mémoire du planificateur | Utilisation totale de la mémoire par les conteneurs s'exécutant dans tous les pods de programmeurs Airflow et limite combinée de vCPU pour tous les programmeurs. |
| Utilisation totale du disque par le planificateur | Utilisation totale de l'espace disque par les conteneurs s'exécutant dans tous les pods de programmeurs Airflow, et limite combinée de l'espace disque pour tous les programmeurs. |
| Redémarrages des conteneurs du programmeur | Nombre total de redémarrages pour les conteneurs de programmateur individuels. |
| Évictions de pods du programmeur | Nombre d'évictions de pods du programmeur Airflow. L'éviction de pods peut se produire lorsqu'un pod spécifique du cluster de votre environnement atteint ses limites de ressources. |
Statistiques des nœuds de calcul
| Métrique d'environnement | Description |
|---|---|
| Utilisation totale du processeur par les nœuds de calcul | Utilisation totale des cœurs de processeur virtuel par les conteneurs s'exécutant dans tous les pods de nœuds de calcul Airflow et limite combinée des processeurs virtuels pour tous les nœuds de calcul. |
| Utilisation totale de la mémoire des nœuds de calcul | Utilisation totale de la mémoire par les conteneurs s'exécutant dans tous les pods de nœuds de calcul Airflow et limite combinée de processeurs virtuels pour tous les nœuds de calcul. |
| Utilisation totale du disque par les nœuds de calcul | Utilisation totale de l'espace disque par les conteneurs s'exécutant dans tous les pods de nœuds de calcul Airflow et limite combinée de l'espace disque pour tous les nœuds de calcul. |
| Nœuds de calcul actifs | Nombre actuel de nœuds de calcul dans votre environnement. Dans Cloud Composer 2, votre environnement ajuste automatiquement le nombre de nœuds de calcul actifs. |
| Redémarrages de conteneurs de nœuds de calcul | Nombre total de redémarrages pour les conteneurs de nœuds de calcul individuels. |
| Évictions de pods de nœuds de calcul | Nombre d'évictions de pods de nœuds de calcul Airflow. L'éviction de pods peut se produire lorsqu'un pod spécifique du cluster de votre environnement atteint ses limites de ressources. Si un pod de nœud de calcul Airflow est évincé, toutes les instances de tâche qui y sont exécutées sont interrompues, puis marquées comme ayant échoué par Airflow. |
| Tâches Airflow | Consultez Vue d'ensemble de l'environnement. |
| Tâches Celery non confirmées |
Nombre de tâches non confirmées dans la file d'attente de l'agent Celery. Les tâches non confirmées incluent les instances de tâches Airflow dans les états de tâches queued et running. Ces deux états sont normaux pour l'exécution des tâches Airflow. Le graphique "Tâches Celery non confirmées" affichera les tâches dans ces états comme non confirmées pendant qu'elles sont traitées par Airflow. Si une instance de tâche Airflow est interrompue de manière anormale (par exemple, détectée comme zombie), elle restera également non reconnue jusqu'à ce que le visibility_timeout soit atteint. Dans ce cas, le graphique affichera une tâche qui reste systématiquement non confirmée pendant une longue période. La valeur du délai de visibilité est définie sur sept jours dans Cloud Composer. Passé ce délai, la tâche sera renvoyée et pourra être confirmée. Si l'opération échoue à nouveau, il est possible que le problème reste non résolu pendant sept jours supplémentaires. |
| Expirations de délais lors d'une publication vers l'agent Celery |
Nombre total d'erreurs AirflowTaskTimeout relevées lors de la publication de tâches vers les agents Celery. Cette métrique correspond à la métrique Airflow celery.task_timeout_error. |
| Échecs de commande d'exécution Celery |
Nombre total de codes de sortie non nuls pour les tâches Celery. Cette métrique correspond à la métrique Airflow celery.execute_command.failure. |
| Tâches arrêtées par le système | Nombre de tâches de workflow pour lesquelles l'exécuteur de tâches a été arrêté par un SIGKILL (par exemple, en raison de problèmes de mémoire ou de pulsation des nœuds). |
Statistiques du déclencheur
| Métrique d'environnement | Description |
|---|---|
| Tâches différées | Nombre de tâches à l'état "différée" à un moment donné. Pour en savoir plus sur les tâches différées, consultez Utiliser des opérateurs différables. |
| Déclencheurs terminés | Nombre de déclencheurs exécutés dans tous les pods de déclencheur. |
| Déclencheurs en cours d'exécution | Nombre de déclencheurs en cours d'exécution par instance de déclencheur. Ce graphique affiche une ligne distincte pour chaque déclencheur. |
| Déclencheurs de blocage | Nombre de déclencheurs ayant bloqué le thread principal (probablement parce qu'ils n'étaient pas entièrement asynchrones). |
| Utilisation totale du CPU par les déclencheurs | Utilisation totale des cœurs de vCPU par les conteneurs s'exécutant dans tous les pods de déclencheurs Airflow, et limite combinée de vCPU pour tous les déclencheurs. |
| Utilisation totale de la mémoire par les déclencheurs | Utilisation totale de la mémoire par les conteneurs s'exécutant dans tous les pods de déclencheurs Airflow, et limite combinée des vCPU pour tous les déclencheurs. |
| Utilisation totale du disque par les déclencheurs | Utilisation totale de l'espace disque par les conteneurs s'exécutant dans tous les pods de déclencheurs Airflow et limite combinée de l'espace disque pour tous les déclencheurs. |
| Déclencheurs actifs | Nombre d'instances de déclencheur actives. |
| Redémarrages des conteneurs de déclencheur | Nombre de redémarrages des conteneurs de déclencheur. |
Statistiques du serveur Web
| Métrique d'environnement | Description |
|---|---|
| État du serveur Web | Consultez Vue d'ensemble de l'environnement. |
| Utilisation du processeur du serveur Web | Utilisation totale des cœurs de vCPU par les conteneurs s'exécutant dans tous les pods de serveurs Web Airflow et limite combinée de vCPU pour tous les serveurs Web. |
| Utilisation de la mémoire du serveur Web | Utilisation totale de la mémoire par les conteneurs s'exécutant dans tous les pods de serveurs Web Airflow et limite combinée de vCPU pour tous les serveurs Web. |
| Utilisation totale du disque du serveur Web | Utilisation totale de l'espace disque par les conteneurs s'exécutant dans tous les pods de serveurs Web Airflow et limite combinée de l'espace disque pour tous les serveurs Web. |
Statistiques de base de données SQL
| Métrique d'environnement | Description |
|---|---|
| État de la base de données | Consultez Vue d'ensemble de l'environnement. |
| Utilisation du processeur de la base de données | Utilisation des cœurs de processeur par les instances de base de données Cloud SQL de votre environnement. |
| Utilisation de la mémoire de la base de données | Utilisation totale de la mémoire par les instances de base de données Cloud SQL de votre environnement. |
| Utilisation du disque de la base de données | Utilisation totale de l'espace disque par les instances de base de données Cloud SQL de votre environnement. Cette métrique s'applique à l'instance de base de données Cloud SQL elle-même. Elle ne diminue donc pas lorsque la taille de la base de données Airflow est réduite. Pour obtenir une métrique indiquant la taille du contenu de la base de données Airflow, consultez "Taille de la base de données de métadonnées Airflow". |
| Taille de la base de données de métadonnées Airflow | Taille de la base de données de métadonnées Airflow. Cette métrique s'applique au composant Airflow de votre environnement et indique la quantité d'espace disque occupée par la base de données de métadonnées Airflow sur l'instance de base de données Cloud SQL. Cette métrique diminue lorsque la taille de la base de données de métadonnées Airflow est réduite (par exemple, après la maintenance de la base de données Airflow). Elle détermine s'il est possible de créer des instantanés et de mettre à niveau des environnements. Cette métrique est différente de la métrique "Utilisation de l'espace disque de la base de données", qui indique la quantité d'espace disque utilisée par les instances de base de données Cloud SQL. |
| Connexions à la base de données | Nombre total de connexions actives à la base de données et limite totale de connexions. |
Différence entre le temps d'analyse du DAG et le temps d'exécution du DAG
Le tableau de bord de surveillance d'un environnement affiche le temps total requis pour analyser tous les DAG de votre environnement Cloud Composer, ainsi que le temps moyen d'exécution d'un DAG.
L'analyse d'un DAG et la planification des tâches d'un DAG pour exécution sont deux opérations distinctes effectuées par le programmeur Airflow.
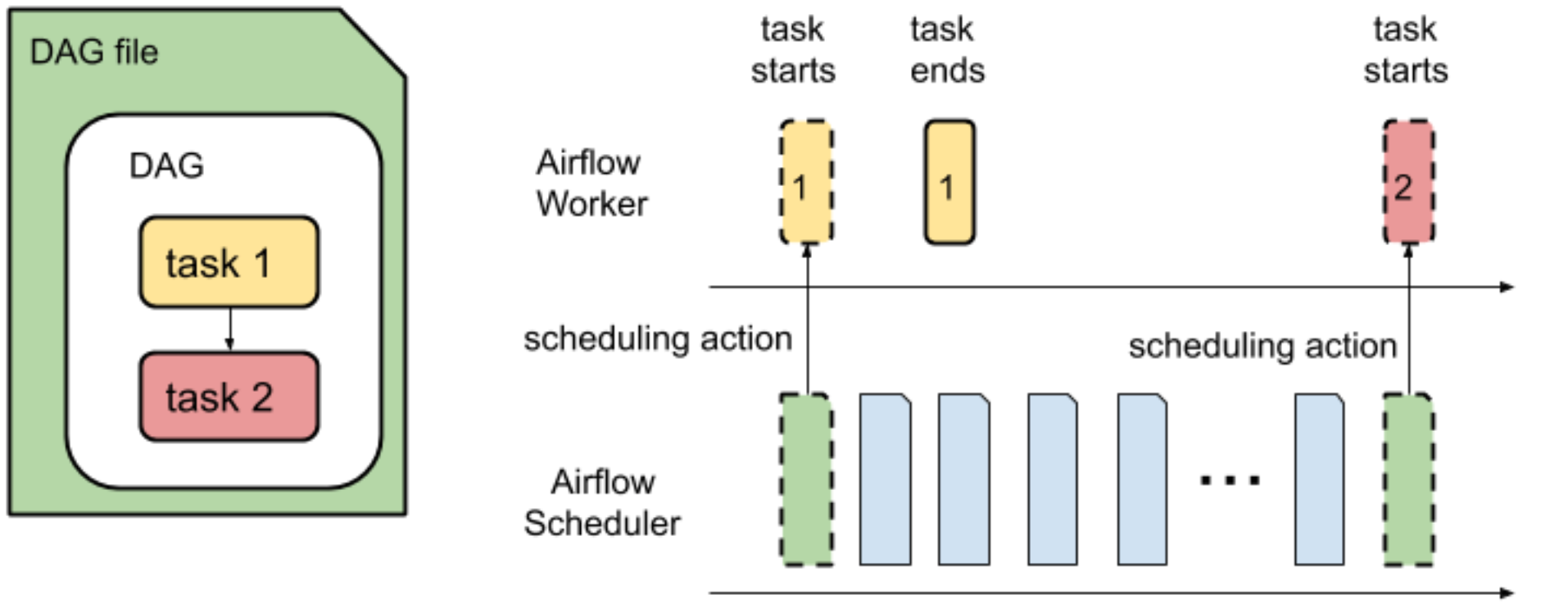
Le temps d'analyse du DAG correspond au temps nécessaire au planificateur Airflow pour lire et analyser un fichier DAG.
Avant de pouvoir planifier une tâche d'un DAG, le programmeur Airflow doit analyser le fichier DAG pour découvrir la structure du DAG et les tâches définies. Une fois le fichier de DAG analysé, le programmeur peut commencer à planifier des tâches du DAG.
Le temps d'exécution du DAG correspond à la somme de tous les temps d'exécution de tâche pour un DAG.
Pour connaître la durée d'exécution d'une tâche Airflow spécifique d'un DAG, sélectionnez un DAG dans l'interface Web Airflow et ouvrez l'onglet Durée des tâches. Cet onglet affiche les temps d'exécution des tâches pour le nombre spécifié de dernières exécutions de DAG.