Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
En esta página, se describe cómo supervisar el estado general y el rendimiento del entorno de Cloud Composer con métricas clave en el panel de Monitoring.
Introducción
En este instructivo, se abordan las métricas clave de supervisión de Cloud Composer que pueden proporcionar una buena descripción general del estado y el rendimiento a nivel del entorno.
Cloud Composer ofrece varias métricas que describen el estado general del entorno. Los lineamientos de supervisión de este instructivo se basan en las métricas expuestas en el panel de Monitoring de tu entorno de Cloud Composer.
En este instructivo, aprenderás sobre las métricas clave que sirven como indicadores principales de problemas con el rendimiento y el estado de tu entorno, así como los lineamientos para interpretar cada métrica en acciones correctivas para mantener el entorno en buen estado. También configurarás reglas de alertas para cada métrica, ejecutarás el DAG de ejemplo y usarás estas métricas y alertas para optimizar el rendimiento de tu entorno.
Objetivos
Costos
En este instructivo, se usan los siguientes componentes facturables de Google Cloud:
- Cloud Composer (consulta los costos adicionales)
- Cloud Monitoring
Cuando finalices este instructivo, puedes borrar los recursos creados para evitar que se te siga facturando. Para obtener más información, consulta Realiza una limpieza.
Antes de comenzar
En esta sección, se describen las acciones que debes realizar antes de comenzar el instructivo.
Crea y configura un proyecto
Para este instructivo, necesitas un Google Cloud proyecto. Configura el proyecto de la siguiente manera:
En la Google Cloud consola, selecciona o crea un proyecto:
Asegúrate de tener habilitada la facturación para tu proyecto. Obtén información para verificar si la facturación está habilitada en un proyecto.
Asegúrate de que el usuario del proyecto Google Cloud tenga los siguientes roles para crear los recursos necesarios:
- Administrador de objetos de almacenamiento y entorno
(
roles/composer.environmentAndStorageObjectAdmin) - Administrador de Compute (
roles/compute.admin) - Editor de Monitoring (
roles/monitoring.editor)
- Administrador de objetos de almacenamiento y entorno
(
Habilita las API para tu proyecto.
Enable the Cloud Composer API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Crea tu entorno de Cloud Composer
Crea un entorno de Cloud Composer 2.
Como parte de este procedimiento, otorgas el rol de Extensión del agente de servicio de la API de Cloud Composer v2 (roles/composer.ServiceAgentV2Ext) a la cuenta del agente de servicio de Composer. Cloud Composer usa esta cuenta para realizar operaciones en tu proyecto Google Cloud .
Explora las métricas clave del estado y el rendimiento a nivel del entorno
En este instructivo, se explican las métricas clave que pueden brindarte una buena descripción general del estado y el rendimiento generales de tu entorno.
El panel de supervisión de la consola deGoogle Cloud contiene una variedad de métricas y gráficos que permiten supervisar las tendencias en tu entorno y, además, identificar los problemas con los componentes de Airflow y los recursos de Cloud Composer.
Cada entorno de Cloud Composer tiene su propio panel de supervisión.
Familiarízate con las siguientes métricas clave y ubica cada una en el panel de Monitoring:
En la consola de Google Cloud , ve a la página Entornos.
En la lista de entornos, haz clic en el nombre de tu entorno. Se abrirá la página Detalles del entorno.
Ve a la pestaña Monitoring.
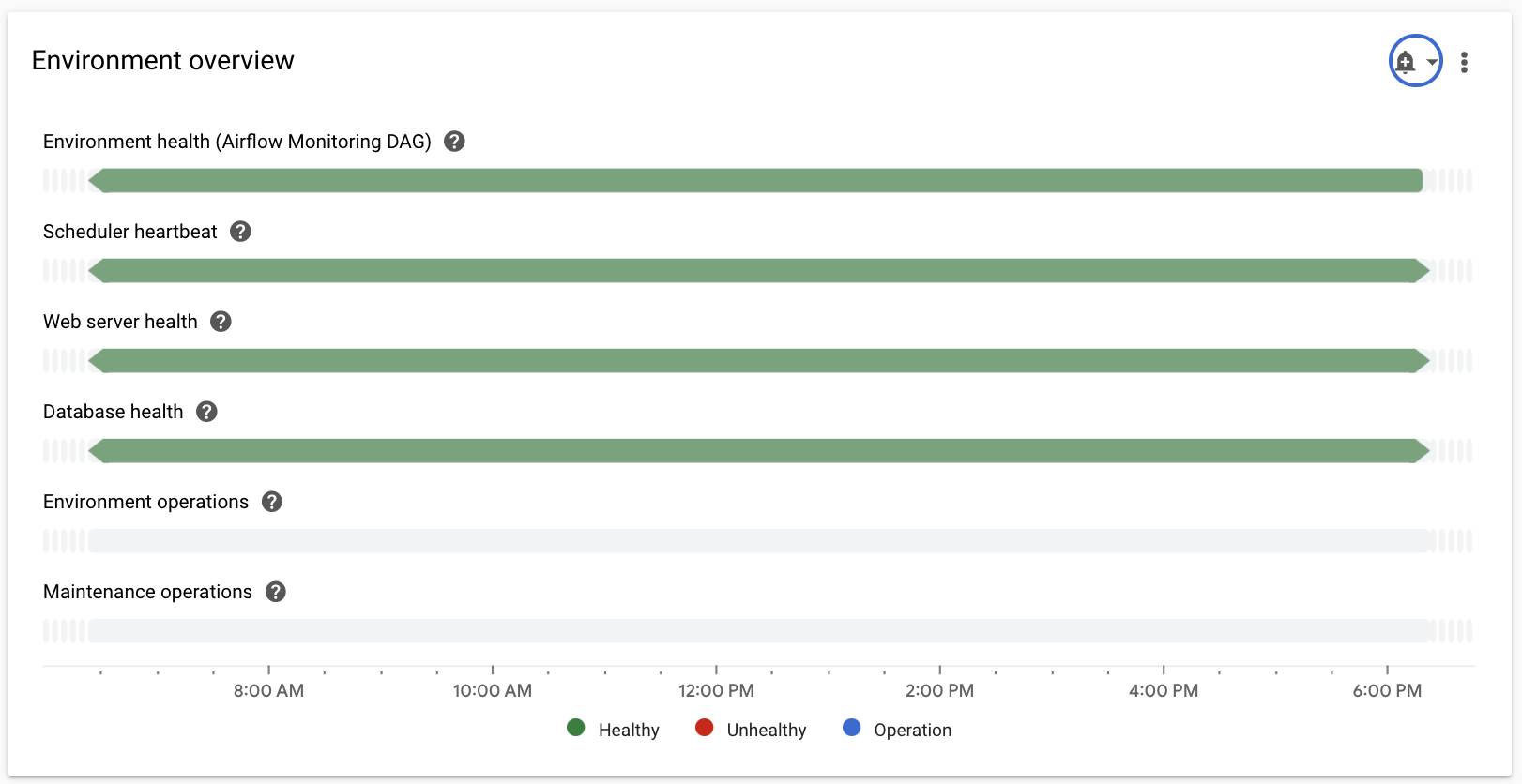
Selecciona la sección Descripción general, busca el elemento Descripción general del entorno en el panel y observa la métrica Estado del entorno (DAG de supervisión de Airflow).
En este cronograma, se muestra el estado del entorno de Cloud Composer. El color verde de la barra de estado del entorno indica que el entorno está en buen estado, mientras que el estado de entorno no saludable se indica con el color rojo.
Cada pocos minutos, Cloud Composer ejecuta un DAG de actividad llamado
airflow_monitoring. Si la ejecución del DAG de actividad finaliza correctamente, el estado esTrue. Si falla la ejecución del DAG de actividad (por ejemplo, debido a la expulsión del Pod, la finalización del proceso externo o el mantenimiento), el estado esFalse.
Selecciona la sección Base de datos SQL, busca el elemento Estado de la base de datos en el panel y observa la métrica Estado de la base de datos.
En este cronograma, se muestra el estado de la conexión a la instancia de Cloud SQL de tu entorno. La barra de estado verde de la base de datos indica conectividad, mientras que los errores de conexión se indican con el color rojo.
El pod de supervisión de Airflow hace ping a la base de datos de forma periódica y muestra el estado como
Truesi se puede establecer una conexión o comoFalsesi no se puede.
En el elemento Estado de la base de datos, observa las métricas Uso de CPU de la base de datos y Uso de memoria de la base de datos.
El gráfico Uso de CPU de la base de datos indica el uso de núcleos de CPU por parte de las instancias de base de datos de Cloud SQL de tu entorno en comparación con el límite total disponible de CPU de la base de datos.
El gráfico Uso de memoria de la base de datos indica el uso de memoria de las instancias de bases de datos de Cloud SQL de tu entorno en comparación con el límite total de memoria disponible de la base de datos.
Selecciona la sección Schedulers, busca el elemento Latido del programador en el panel y observa la métrica Latido del programador.
En este cronograma, se muestra el estado del programador de Airflow. Verifica las áreas rojas para identificar los problemas del programador de Airflow. Si tu entorno tiene más de un programador, el estado de latido será correcto siempre y cuando responda al menos uno de los programadores.
El programador se considera en mal estado si el último latido se recibió más de 30 segundos (valor predeterminado) antes de la hora actual.
Selecciona la sección Estadísticas del DAG, busca el elemento Procesos zombi eliminados en el panel y observa la métrica Procesos zombi eliminados.
Este gráfico indica la cantidad de tareas zombi que se finalizaron en un período breve. Las tareas zombi, a menudo, son producto de la terminación externa de los procesos de Airflow (por ejemplo, cuando se bloquea el proceso de una tarea).
El programador de Airflow finaliza las tareas zombi de forma periódica, lo que se refleja en este gráfico.
Selecciona la sección Trabajadores, busca el elemento Reinicios del contenedor de trabajadores en el panel y observa la métrica Reinicios del contenedor de trabajadores.
- Un gráfico indica la cantidad total de reinicios de los contenedores de trabajadores individuales. Demasiados reinicios de contenedores pueden afectar la disponibilidad de tu servicio o de otros servicios descendentes que lo usan como dependencia.
Conoce las comparativas y las posibles acciones correctivas para las métricas clave
En la siguiente lista, se describen los valores de referencia que pueden indicar problemas y se proporcionan las medidas correctivas que puedes tomar para solucionarlos.
Estado del entorno (DAG de supervisión de Airflow)
Porcentaje de éxito inferior al 90% durante un período de 4 horas
Las fallas pueden significar expulsiones de Pods o finalizaciones de trabajadores porque el entorno está sobrecargado o funciona mal. Las áreas rojas en la línea de tiempo del estado del entorno suelen correlacionarse con las áreas rojas en las otras barras de estado de los componentes individuales del entorno. Identifica la causa raíz revisando otras métricas en el panel de Monitoring.
Estado de la base de datos
Porcentaje de éxito inferior al 95% durante un período de 4 horas
Los errores significan que hay problemas de conectividad con la base de datos de Airflow, lo que podría deberse a una falla o un tiempo de inactividad de la base de datos porque está sobrecargada (por ejemplo, debido a un alto uso de la CPU o la memoria, o a una mayor latencia al conectarse a la base de datos). Estos síntomas suelen deberse a DAGs no óptimos, por ejemplo, cuando los DAGs usan muchas variables de entorno o de Airflow definidas de forma global. Identifica la causa raíz revisando las métricas de uso de recursos de la base de datos SQL. También puedes inspeccionar los registros del programador para detectar errores relacionados con la conectividad de la base de datos.
Uso de CPU y memoria de la base de datos
Más del 80% de uso promedio de CPU o memoria en un período de 12 horas
Es posible que la base de datos esté sobrecargada. Analiza la correlación entre las ejecuciones de tu DAG y los picos en el uso de CPU o memoria de la base de datos.
Puedes reducir la carga de la base de datos con DAG más eficientes con conexiones y consultas en ejecución optimizadas, o bien distribuyendo la carga de manera más uniforme con el tiempo.
Como alternativa, puedes asignar más CPU o memoria a la base de datos. Los recursos de la base de datos se controlan con la propiedad de tamaño del entorno, y este debe ajustarse a un tamaño mayor.
Señal de monitoreo de funcionamiento del programador
Porcentaje de éxito inferior al 90% durante un período de 4 horas
Asigna más recursos al programador o aumenta la cantidad de programadores de 1 a 2 (recomendado).
Procesos zombi eliminados
Más de una tarea zombie por cada 24 horas
El motivo más común de las tareas zombie es la escasez de recursos de CPU o memoria en el clúster de tu entorno. Revisa los gráficos de uso de recursos de los trabajadores y asígnale más recursos a tus trabajadores, o bien aumenta el tiempo de espera de las tareas zombie para que el programador espere más tiempo antes de considerar que una tarea es zombie.
Reinicios del contenedor de trabajadores
Más de un reinicio cada 24 horas
El motivo más común es la falta de memoria o almacenamiento del trabajador. Analiza el consumo de recursos de los trabajadores y asígnales más memoria o almacenamiento. Si la falta de recursos no es el motivo, investiga los incidentes de reinicio del trabajador y usa las consultas de registro para descubrir los motivos de los reinicios.
Crea canales de notificaciones
Sigue las instrucciones que se describen en Crea un canal de notificaciones para crear un canal de notificaciones por correo electrónico.
Para obtener más información sobre los canales de notificaciones, consulta Administra canales de notificaciones.
Crea políticas de alertas
Crea políticas de alertas basadas en las comparativas proporcionadas en las secciones anteriores de este instructivo para supervisar de forma continua los valores de las métricas y recibir notificaciones cuando estas infrinjan una condición.
Console
Para configurar alertas para cada métrica que se presenta en el panel de Monitoring, haz clic en el ícono de campana que se encuentra en la esquina del elemento correspondiente:
Busca cada métrica que quieras supervisar en el panel de Monitoring y haz clic en el ícono de campana que se encuentra en la esquina del elemento de la métrica. Se abrirá la página Crear política de alertas.
En la sección Transformar datos, haz lo siguiente:
Configura la sección Dentro de cada serie temporal como se describe en la configuración de las políticas de alertas para la métrica.
Haz clic en Siguiente y, luego, configura la sección Configurar activador de alertas como se describe en la configuración de las políticas de alertas para la métrica.
Haz clic en Siguiente.
Configura las notificaciones. Expande el menú Canales de notificaciones y selecciona los canales de notificaciones que creaste en el paso anterior.
Haz clic en Aceptar.
En la sección Asigna un nombre a la política de alertas, completa el campo Nombre de la política de alertas. Usa un nombre descriptivo para cada una de las métricas. Usa el valor "Name the alert policy" como se describe en la configuración de las políticas de alertas para la métrica.
Haz clic en Siguiente.
Revisa la política de alertas y haz clic en Crear política.
Métrica de estado del entorno (DAG de supervisión de Airflow): Configuraciones de políticas de alertas
- Nombre de la métrica: Cloud Composer Environment - Healthy
- API: composer.googleapis.com/environment/healthy
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar datos > Dentro de cada serie temporal:
- Ventana progresiva: Personalizada
- Valor personalizado: 4
- Unidades personalizadas: horas
- Función analítica progresiva: fracción verdadero
Configura el activador de alertas:
- Tipos de condiciones: Umbral
- Activador de alertas: Cualquier serie temporal es una infracción
- Posición del umbral: Por debajo del umbral
- Valor del umbral: 90
- Nombre de la condición: Estado del entorno
Configura las notificaciones y finaliza la alerta:
- Asigna el nombre Airflow Environment Health a la política de alertas.
Métrica de estado de la base de datos: parámetros de configuración de la política de alertas
- Nombre de la métrica: Cloud Composer Environment - Database Healthy
- API: composer.googleapis.com/environment/database_health
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar datos > Dentro de cada serie temporal:
- Ventana progresiva: Personalizada
- Valor personalizado: 4
- Unidades personalizadas: horas
- Función analítica progresiva: fracción verdadero
Configura el activador de alertas:
- Tipos de condiciones: Umbral
- Activador de alertas: Cualquier serie temporal es una infracción
- Posición del umbral: Por debajo del umbral
- Valor del umbral: 95
- Nombre de la condición: Estado de la base de datos
Configura las notificaciones y finaliza la alerta:
- Asigna el nombre Airflow Database Health a la política de alertas.
Métrica de uso de CPU de la base de datos: parámetros de configuración de la política de alertas
- Nombre de la métrica: Entorno de Cloud Composer: Uso de CPU de la base de datos
- API: composer.googleapis.com/environment/database/cpu/utilization
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar datos > Dentro de cada serie temporal:
- Ventana progresiva: Personalizada
- Valor personalizado: 12
- Unidades personalizadas: horas
- Función analítica progresiva: media
Configura el activador de alertas:
- Tipos de condiciones: Umbral
- Activador de alertas: Cualquier serie temporal es una infracción
- Posición del umbral: Por encima del umbral
- Valor del umbral: 80
- Nombre de la condición: Condición de uso de CPU de la base de datos
Configura las notificaciones y finaliza la alerta:
- Asigna el nombre Airflow Database CPU Usage a la política de alertas.
Métrica de uso de memoria de la base de datos: parámetros de configuración de la política de alertas
- Nombre de la métrica: Entorno de Cloud Composer: Uso de memoria de la base de datos
- API: composer.googleapis.com/environment/database/memory/utilization
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar datos > Dentro de cada serie temporal:
- Ventana progresiva: Personalizada
- Valor personalizado: 12
- Unidades personalizadas: horas
- Función analítica progresiva: media
Configura el activador de alertas:
- Tipos de condiciones: Umbral
- Activador de alertas: Cualquier serie temporal es una infracción
- Posición del umbral: Por encima del umbral
- Valor del umbral: 80
- Nombre de la condición: Condición de uso de memoria de la base de datos
Configura las notificaciones y finaliza la alerta:
- Asigna el nombre Airflow Database Memory Usage a la política de alertas.
Métrica de señal de monitoreo de funcionamiento del programador: configuraciones de políticas de alertas
- Nombre de la métrica: Cloud Composer Environment - Scheduler Heartbeats
- API: composer.googleapis.com/environment/scheduler_heartbeat_count
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar datos > Dentro de cada serie temporal:
- Ventana progresiva: Personalizada
- Valor personalizado: 4
- Unidades personalizadas: horas
- Función analítica progresiva: recuento
Configura el activador de alertas:
- Tipos de condiciones: Umbral
- Activador de alertas: Cualquier serie temporal es una infracción
- Posición del umbral: Por debajo del umbral
Valor del umbral: 216
- Puedes obtener este número ejecutando una consulta que agregue el valor
_scheduler_heartbeat_count_meanen el Editor de consultas del Explorador de métricas.
- Puedes obtener este número ejecutando una consulta que agregue el valor
Nombre de la condición: Condición de señal de monitoreo de funcionamiento del programador
Configura las notificaciones y finaliza la alerta:
- Asigna el nombre Airflow Scheduler Heartbeat a la política de alertas.
Métrica de tareas zombi eliminadas: Configuraciones de políticas de alertas
- Nombre de la métrica: Entorno de Cloud Composer: Procesos zombi eliminados
- API: composer.googleapis.com/environment/zombie_task_killed_count
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar datos > Dentro de cada serie temporal:
- Ventana progresiva: 1 día
- Función analítica progresiva: suma
Configura el activador de alertas:
- Tipos de condiciones: Umbral
- Activador de alertas: Cualquier serie temporal es una infracción
- Posición del umbral: Por encima del umbral
- Valor del umbral: 1
- Nombre de la condición: Condición de tareas zombi
Configura las notificaciones y finaliza la alerta:
- Asigna el nombre Airflow Zombie Tasks a la política de alertas.
Métrica de reinicios del contenedor de trabajadores: Configuraciones de políticas de alertas
- Nombre de la métrica: Contenedor de Kubernetes: Recuento de reinicios
- API: kubernetes.io/container/restart_count
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION] pod_name =~ airflow-worker-.*|airflow-k8s-worker-.* container_name =~ airflow-worker|base cluster_name = [CLUSTER_NAME]CLUSTER_NAMEes el nombre del clúster de tu entorno, que se puede encontrar en Configuración del entorno > Recursos > Clúster de GKE en la consola de Google Cloud .Transformar datos > Dentro de cada serie temporal:
- Ventana progresiva: 1 día
- Función analítica progresiva: tasa
Configura el activador de alertas:
- Tipos de condiciones: Umbral
- Activador de alertas: Cualquier serie temporal es una infracción
- Posición del umbral: Por encima del umbral
- Valor del umbral: 1
- Nombre de la condición: Condición de reinicios del contenedor de trabajadores
Configura las notificaciones y finaliza la alerta:
- Asigna el nombre Airflow Worker Restarts a la política de alertas.
Terraform
Ejecuta una secuencia de comandos de Terraform que cree un canal de notificación por correo electrónico y suba políticas de alertas para las métricas clave que se proporcionan en este instructivo según sus comparativas respectivas:
- Guarda el archivo de ejemplo de Terraform en tu computadora local.
Reemplaza lo siguiente:
PROJECT_ID: Es el ID del proyecto de tu proyecto. Por ejemplo,example-project.EMAIL_ADDRESS: Es la dirección de correo electrónico a la que se debe enviar una notificación en caso de que se active una alerta.ENVIRONMENT_NAME: Es el nombre de tu entorno de Cloud Composer. Por ejemplo,example-composer-environmentCLUSTER_NAME: Es el nombre del clúster de tu entorno, que se encuentra en Configuración del entorno > Recursos > Clúster de GKE en la consola de Google Cloud .
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
Prueba las políticas de alertas
En esta sección, se describe cómo probar las políticas de alertas creadas y cómo interpretar los resultados.
Sube un DAG de muestra
El DAG de muestra memory_consumption_dag.py que se proporciona en este instructivo imita el uso intensivo de la memoria del trabajador. El DAG contiene 4 tareas, y cada una de ellas escribe datos en una cadena de muestra, lo que consume 380 MB de memoria. El DAG de ejemplo está programado para ejecutarse cada 2 minutos y comenzará a ejecutarse automáticamente una vez que lo subas a tu entorno de Composer.
Sube el siguiente DAG de ejemplo al entorno que creaste en los pasos anteriores:
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
Interpreta las alertas y las métricas en Monitoring
Espera unos 10 minutos después de que comience a ejecutarse el DAG de muestra y evalúa los resultados de la prueba:
Revisa tu buzón de correo electrónico para verificar que recibiste una notificación deGoogle Cloud Alerting con la línea de asunto que comienza con
[ALERT]. El contenido de este mensaje incluye los detalles del incidente de la política de alertas.Haz clic en el botón Ver incidente en la notificación por correo electrónico. Se te redireccionará al Explorador de métricas. Revisa los detalles del incidente de alerta:

Figura 2. Detalles del incidente de alerta (haz clic para ampliar) El gráfico de métricas de incidentes indica que las métricas que creaste superaron el umbral de 1, lo que significa que Airflow detectó y finalizó más de 1 tarea zombie.
En tu entorno de Cloud Composer, ve a la pestaña Monitoring, abre la sección DAG statistics y busca el gráfico Zombie tasks killed:
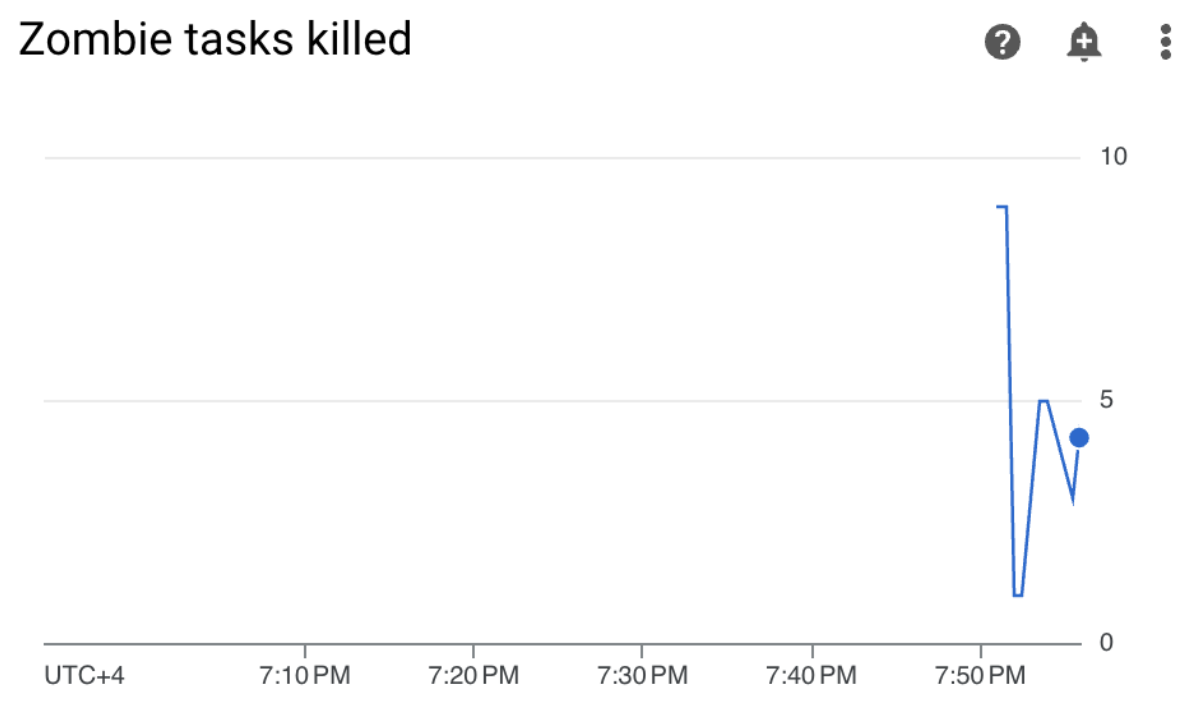
Figura 3. Gráfico de tareas zombi (haz clic para agrandar) El gráfico indica que Airflow finalizó alrededor de 20 tareas zombi en los primeros 10 minutos de ejecución del DAG de muestra.
Según las comparativas y las acciones correctivas, el motivo más común de las tareas zombi es la falta de memoria o CPU del trabajador. Identifica la causa raíz de las tareas zombi analizando el uso de los recursos de los trabajadores.
Abre la sección Workers en tu panel de Supervisión y revisa las métricas de uso de CPU y memoria del trabajador:
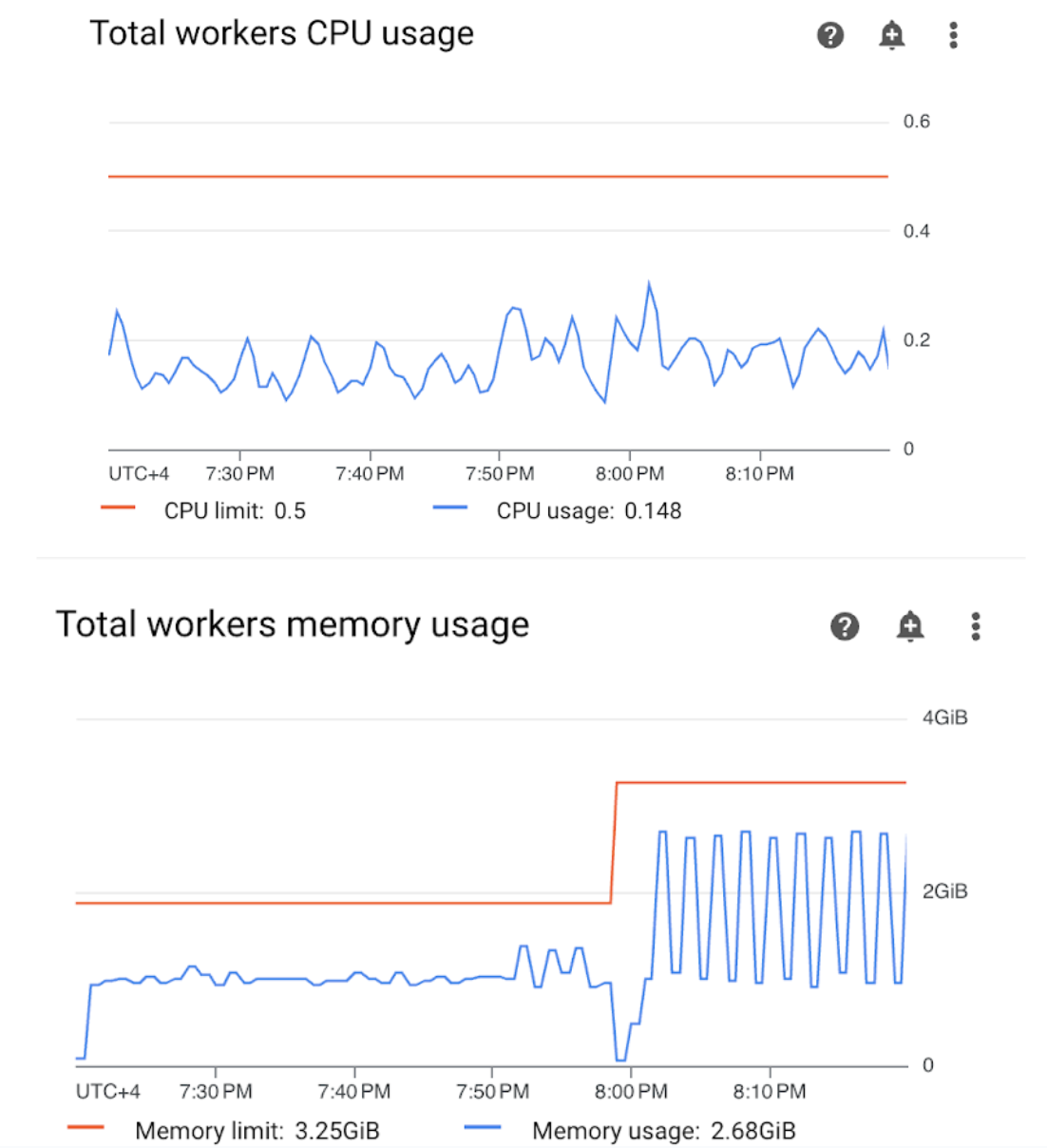
Figura 4: Métricas de uso de CPU y memoria del trabajador (haz clic para ampliar) El gráfico Uso total de CPU de trabajadores indica que el uso de CPU de los trabajadores siempre estuvo por debajo del 50% del límite total disponible, por lo que la CPU disponible es suficiente. El gráfico Uso total de memoria de los trabajadores muestra que la ejecución del DAG de muestra provocó que se alcanzara el límite de memoria asignable, que equivale a casi el 75% del límite de memoria total que se muestra en el gráfico (GKE reserva el 25% de los primeros 4 GiB de memoria y 100 MiB adicionales de memoria en cada nodo para controlar la expulsión de Pods).
Puedes concluir que los trabajadores no tienen los recursos de memoria necesarios para ejecutar el DAG de muestra correctamente.
Optimiza tu entorno y evalúa su rendimiento
Según el análisis del uso de recursos de los trabajadores, debes asignar más memoria a tus trabajadores para que todas las tareas de tu DAG se completen correctamente.
En tu entorno de Composer, abre la pestaña DAGs, haz clic en el nombre del DAG de ejemplo (
memory_consumption_dag) y, luego, en Pause DAG.Asigna memoria adicional al trabajador:
En la pestaña Configuración del entorno, busca la configuración de Recursos > Cargas de trabajo y haz clic en Editar.
En el elemento Trabajador, aumenta el límite de Memoria. En este instructivo, usa 3.25 GB.
Guarda los cambios y espera varios minutos para que se reinicie el trabajador.
Abre la pestaña DAGs, haz clic en el nombre del DAG de ejemplo (
memory_consumption_dag) y, luego, en Unpause DAG.
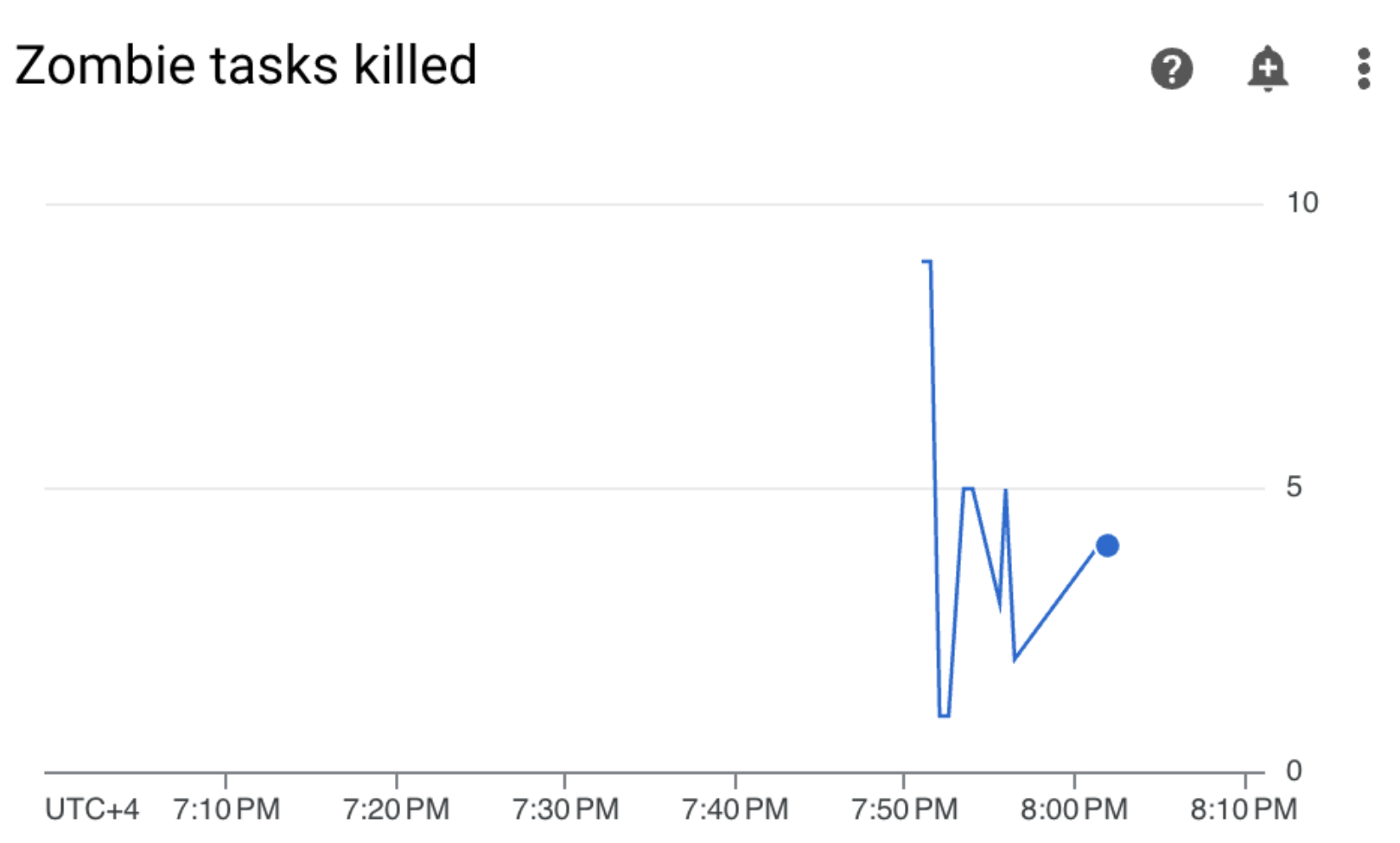
Ve a Monitoring y verifica que no hayan aparecido tareas zombi nuevas después de que actualizaste los límites de recursos del trabajador:
Resumen
En este instructivo, aprendiste sobre las métricas clave de rendimiento y estado a nivel del entorno, cómo configurar políticas de alertas para cada métrica y cómo interpretar cada métrica para tomar medidas correctivas. Luego, ejecutaste un DAG de muestra, identificaste la causa raíz de los problemas de estado del entorno con la ayuda de alertas y gráficos de supervisión, y optimizaste tu entorno asignando más memoria a tus trabajadores. Sin embargo, se recomienda optimizar tus DAGs para reducir el consumo de recursos de los trabajadores en primer lugar, ya que no es posible aumentar los recursos más allá de un cierto umbral.
Limpia
Para evitar que se apliquen cargos a tu Google Cloud cuenta por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Borra los recursos individuales
Si planeas explorar varios instructivos y guías de inicio rápido, la reutilización de proyectos puede ayudarte a evitar exceder los límites de las cuotas del proyecto.
Console
- Borra el entorno de Cloud Composer. También borrarás el bucket del entorno durante este procedimiento.
- Borra cada una de las políticas de alertas que creaste en Cloud Monitoring.
Terraform
- Asegúrate de que tu secuencia de comandos de Terraform no contenga entradas para los recursos que tu proyecto aún necesita. Por ejemplo, es posible que desees mantener habilitadas algunas APIs y los permisos de IAM aún asignados (si agregaste esas definiciones a tu secuencia de comandos de Terraform).
- Ejecuta
terraform destroy. - Borra manualmente el bucket del entorno. Cloud Composer no lo borra automáticamente. Puedes hacerlo desde la consola de Google Cloud o Google Cloud CLI.
¿Qué sigue?
- Optimiza entornos
- Escalar entornos
- Administrar las etiquetas del entorno y desglosar los costos del entorno