Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Esta página descreve como aceder e usar o painel de controlo de monitorização de um ambiente do Cloud Composer.
Para mais informações sobre métricas específicas, consulte o artigo Monitorize ambientes com o Cloud Monitoring.
Aceda ao painel de controlo de monitorização
O painel de controlo de monitorização contém métricas e gráficos para monitorizar tendências nas execuções de DAGs no seu ambiente e identificar problemas com componentes do Airflow e recursos do Cloud Composer.
Para aceder ao painel de controlo de monitorização do seu ambiente:
Na Google Cloud consola, aceda à página Ambientes.
Na lista de ambientes, clique no nome do seu ambiente. É apresentada a página Detalhes do ambiente.
Aceda ao separador Monitorização.
Configure alertas para métricas
Pode configurar alertas para uma métrica clicando no ícone de sino no canto do cartão de monitorização.
Veja uma métrica na monitorização
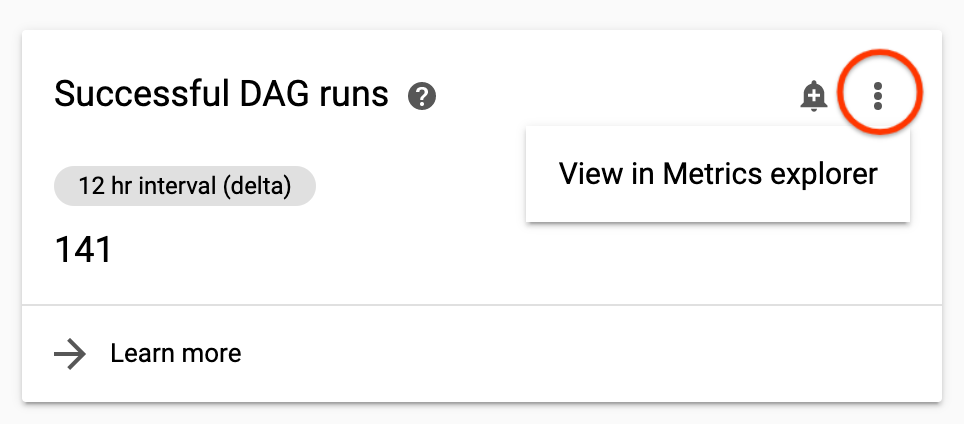
Pode analisar uma métrica mais detalhadamente ao vê-la em Monitorização.
Para navegar até aí a partir do painel de controlo de monitorização do Cloud Composer, clique nos três pontos no canto superior direito de um cartão de métricas e selecione Ver no explorador de métricas.
Descrições das métricas
Cada ambiente do Cloud Composer tem o seu próprio painel de controlo de monitorização. As métricas apresentadas num painel de controlo de monitorização para um ambiente específico apenas monitorizam as execuções de DAG, os componentes do Airflow e os detalhes do ambiente para este ambiente específico. Por exemplo, se tiver dois ambientes, o painel de controlo não agrega métricas de ambos os ambientes.
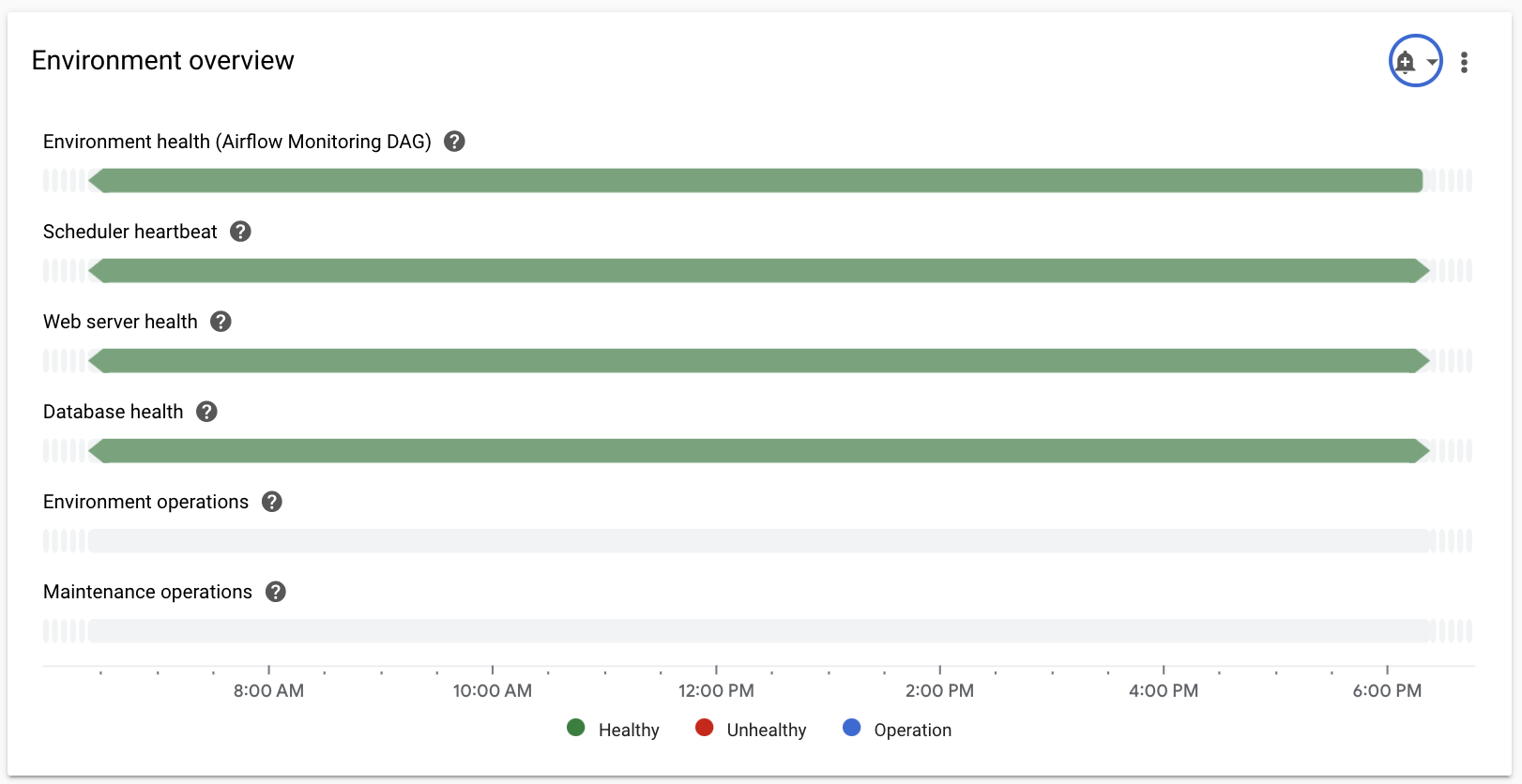
Vista geral do ambiente
| Métrica de ambiente | Descrição |
|---|---|
| Estado de funcionamento do ambiente (DAG de monitorização do fluxo de ar) | Uma cronologia que mostra o estado da implementação do Composer. O estado verde reflete apenas o estado da implementação do Composer. Não significa que todos os componentes do Airflow estejam operacionais e que os DAGs possam ser executados. |
| Ritmo do programador | Uma cronologia que mostra o sinal de pulsação do agendador do Airflow. Verifique se existem áreas vermelhas para identificar problemas do programador do Airflow. Se o seu ambiente tiver mais do que um programador, o estado de sinal de pulsação é saudável desde que, pelo menos, um dos programadores esteja a responder. |
| Estado do servidor Web | Uma cronologia que mostra o estado do servidor Web do Airflow. Este estado é gerado com base nos códigos de estado HTTP devolvidos pelo servidor Web do Airflow. |
| Estado da base de dados | Uma cronologia que mostra o estado da ligação à instância do Cloud SQL que aloja a base de dados do Airflow. |
| Operações de ambiente | Uma cronologia que mostra as operações que modificam o ambiente, como a realização de atualizações de configuração ou o carregamento de instantâneos do ambiente. |
| Operações de manutenção | Uma cronologia que mostra os períodos em que são realizadas operações de manutenção no cluster do ambiente. |
| Dependências do ambiente | Uma cronologia que mostra o estado das verificações de acessibilidade e autorizações para o funcionamento do ambiente. |
Estatísticas do DAG
| Métrica de ambiente | Descrição |
|---|---|
| Execuções de DAG bem-sucedidas | O número total de execuções bem-sucedidas para todos os DAGs no ambiente durante o intervalo de tempo selecionado. Se o número de execuções de DAG bem-sucedidas descer abaixo dos níveis esperados, isto pode indicar falhas (consulte Execuções de DAG com falhas) ou um problema de agendamento. |
| Execuções de DAG com falha Tarefas com falha | O número total de execuções com falhas para todos os DAGs no ambiente durante o intervalo de tempo selecionado. O número total de tarefas que falharam no ambiente durante o intervalo de tempo selecionado. As tarefas com falhas nem sempre fazem com que a execução de um DAG falhe, mas podem ser um sinal útil para resolver problemas de erros de DAG. |
| Execuções de DAG concluídas | O número de êxitos e falhas de DAG para intervalos no intervalo de tempo selecionado. Isto pode ajudar a identificar problemas transitórios com execuções de DAGs e correlacioná-los com outros eventos, como despejos de pods de trabalhadores. |
| Tarefas concluídas | O número de tarefas concluídas no ambiente com uma discriminação das tarefas bem-sucedidas e das tarefas com falhas. |
| Duração mediana da execução do DAG | A duração mediana das execuções de DAG. Este gráfico pode ajudar a identificar problemas de desempenho e a detetar tendências na duração do DAG. |
| Tarefas do Airflow | O número de tarefas em estado de execução, em fila ou adiado num determinado momento. As tarefas do Airflow são tarefas que se encontram num estado de fila no Airflow e podem ser encaminhadas para a fila do agente do Celery ou do Kubernetes Executor. As tarefas em fila do Celery são instâncias de tarefas que são colocadas na fila do agente do Celery. |
| Tarefas zombie terminadas | O número de tarefas zombie terminadas num curto período. As tarefas zombie são frequentemente causadas pela terminação externa de processos do Airflow. O programador do Airflow termina as tarefas zombie periodicamente, o que se reflete neste gráfico. |
| Tamanho do saco DAG | O número de DAGs implementados no contentor do seu ambiente e processados pelo Airflow num determinado momento. Isto pode ser útil ao analisar gargalos de desempenho. Por exemplo, um número aumentado de implementações de DAG pode degradar o desempenho devido a uma carga excessiva. |
| Erros do processador DAG | O número de erros e limites de tempo por segundo encontrados durante o processamento de ficheiros DAG. O valor indica a frequência de erros comunicados pelo processador de DAGs (é um valor diferente do número de DAGs com falhas). |
| Tempo de análise total para todos os DAGs | Um gráfico que mostra o tempo total necessário para o Airflow processar todos os DAGs no ambiente. O aumento do tempo de análise pode afetar a eficiência do agendamento. Consulte o artigo Diferença entre o tempo de análise do DAG e o tempo de execução do DAG para mais informações. |
Estatísticas do programador
| Métrica de ambiente | Descrição |
|---|---|
| Scheduler hearbeat | Consulte o Resumo do ambiente. |
| Utilização total da CPU do programador | A utilização total de núcleos de CPU virtual por contentores em execução em todos os pods do programador do Airflow e o limite de CPU virtual combinado para todos os programadores. |
| Utilização total de memória do programador | A utilização total de memória pelos contentores em execução em todos os pods do programador do Airflow e o limite de vCPU combinado para todos os programadores. |
| Utilização total do disco do programador | A utilização total do espaço em disco pelos contentores em execução em todos os pods do programador do Airflow e o limite de espaço em disco combinado para todos os programadores. |
| Reinícios do contentor do agendador | O número total de reinícios para contentores do programador individuais. |
| Despejos de pods do programador | Número de despejos de agrupamentos do programador do Airflow. A remoção de pods pode ocorrer quando um pod específico no cluster do seu ambiente atinge os limites de recursos. |
Estatísticas dos trabalhadores
| Métrica de ambiente | Descrição |
|---|---|
| Utilização total da CPU do trabalhador | A utilização total de núcleos de CPU virtual por contentores em execução em todos os pods de trabalho do Airflow e o limite de CPU virtual combinado para todos os trabalhadores. |
| Utilização total de memória do trabalhador | A utilização total de memória por contentores em execução em todos os pods de trabalho do Airflow e o limite de vCPU combinado para todos os trabalhadores. |
| Utilização total do disco do trabalhador | A utilização total do espaço em disco pelos contentores em execução em todos os pods de trabalho do Airflow e o limite de espaço em disco combinado para todos os trabalhadores. |
| Trabalhadores ativos | O número atual de trabalhadores no seu ambiente. No Cloud Composer 2, o seu ambiente dimensiona automaticamente o número de trabalhadores ativos. |
| Reinícios do contentor de trabalho | O número total de reinícios de contentores de trabalhadores individuais. |
| Despejos de agrupamentos de trabalhadores | Número de despejos de pods de trabalhadores do Airflow. A remoção de pods pode ocorrer quando um pod específico no cluster do seu ambiente atinge os limites de recursos. Se um pod de trabalho do Airflow for removido, todas as instâncias de tarefas em execução nesse pod são interrompidas e, posteriormente, marcadas como falhadas pelo Airflow. |
| Tarefas do Airflow | Consulte o Resumo do ambiente. |
| Tarefas do Celery não reconhecidas |
O número de tarefas não reconhecidas na fila do agente Celery. As tarefas não reconhecidas incluem instâncias de tarefas do Airflow nos queued e running estados das tarefas. Ambos os estados são normais para a execução da tarefa do Airflow. O gráfico de tarefas do Celery não reconhecidas produz tarefas nestes estados como não reconhecidas enquanto são processadas pelo Airflow. Se uma instância de tarefa do Airflow for interrompida de forma anormal (por exemplo, detetada como um zombie), também permanece não reconhecida até atingir o visibility_timeout. Neste caso, o gráfico apresenta uma tarefa que permanece consistentemente não reconhecida durante muito tempo. O valor do limite de tempo de visibilidade está definido como 7 dias no Cloud Composer. Após este período, a tarefa é reenviada e tem a possibilidade de ser confirmada. Se falhar novamente, pode permanecer não reconhecido durante mais 7 dias. |
| Limites de tempo de publicação do agente Celery |
O número total de erros AirflowTaskTimeout gerados quando as tarefas são publicadas em agentes Celery. Esta métrica corresponde à celery.task_timeout_error métrica de fluxo de ar. |
| Falhas de comando de execução do Celery |
O número total de códigos de saída diferentes de zero de tarefas do Celery. Esta métrica corresponde à celery.execute_command.failure métrica de fluxo de ar. |
| Tarefas terminadas pelo sistema | O número de tarefas de fluxo de trabalho em que o executor de tarefas foi terminado com um SIGKILL (por exemplo, devido a problemas de memória ou de sinal de pulsação do trabalhador). |
Estatísticas do servidor Web
| Métrica de ambiente | Descrição |
|---|---|
| Estado do servidor Web | Consulte o Resumo do ambiente. |
| Utilização da CPU do servidor Web | A utilização total de núcleos de CPU virtual por contentores em execução em todas as instâncias do servidor Web do Airflow e o limite de CPU virtual combinado para todos os servidores Web. |
| Utilização de memória do servidor Web | A utilização total de memória por contentores em execução em todas as instâncias do servidor Web do Airflow e o limite de vCPU combinado para todos os servidores Web. |
| Utilização total do disco do servidor Web | A utilização total do espaço em disco pelos contentores em execução em todas as instâncias do servidor Web do Airflow e o limite de espaço em disco combinado para todos os servidores Web. |
Estatísticas da base de dados SQL
| Métrica de ambiente | Descrição |
|---|---|
| Estado da base de dados | Consulte o Resumo do ambiente. |
| Utilização da CPU da base de dados | A utilização de núcleos da CPU pelas instâncias de base de dados do Cloud SQL do seu ambiente. |
| Utilização de memória da base de dados | A utilização total de memória pelas instâncias de base de dados do Cloud SQL do seu ambiente. |
| Utilização do disco da base de dados | A utilização total do espaço em disco pelas instâncias de base de dados do Cloud SQL do seu ambiente. Esta métrica aplica-se à própria instância da base de dados do Cloud SQL, pelo que a métrica não diminui quando o tamanho da base de dados do Airflow é reduzido. Para uma métrica que mostra o tamanho dos conteúdos da base de dados do Airflow, consulte Tamanho da base de dados de metadados do Airflow. |
| Tamanho da base de dados de metadados do Airflow | Tamanho da base de dados de metadados do Airflow. Esta métrica aplica-se ao componente Airflow do seu ambiente e mostra a quantidade de espaço em disco ocupado pela base de dados de metadados do Airflow na instância da base de dados do Cloud SQL. Esta métrica diminui quando o tamanho da base de dados de metadados do Airflow é reduzido (por exemplo, após a manutenção da base de dados do Airflow) e determina se é possível criar instantâneos e atualizar ambientes. Esta métrica é diferente da métrica Utilização do disco da base de dados, que mostra a quantidade de espaço em disco usado pelas instâncias da base de dados do Cloud SQL. |
| Ligações da base de dados | O número total de ligações ativas à base de dados e o limite total de ligações. |
Diferença entre o tempo de análise do DAG e o tempo de execução do DAG
O painel de controlo de monitorização de um ambiente apresenta o tempo total necessário para analisar todos os DAGs no seu ambiente do Cloud Composer e o tempo médio necessário para executar um DAG.
A análise de um DAG e o agendamento de tarefas de um DAG para execução são duas operações separadas realizadas pelo agendador do Airflow.
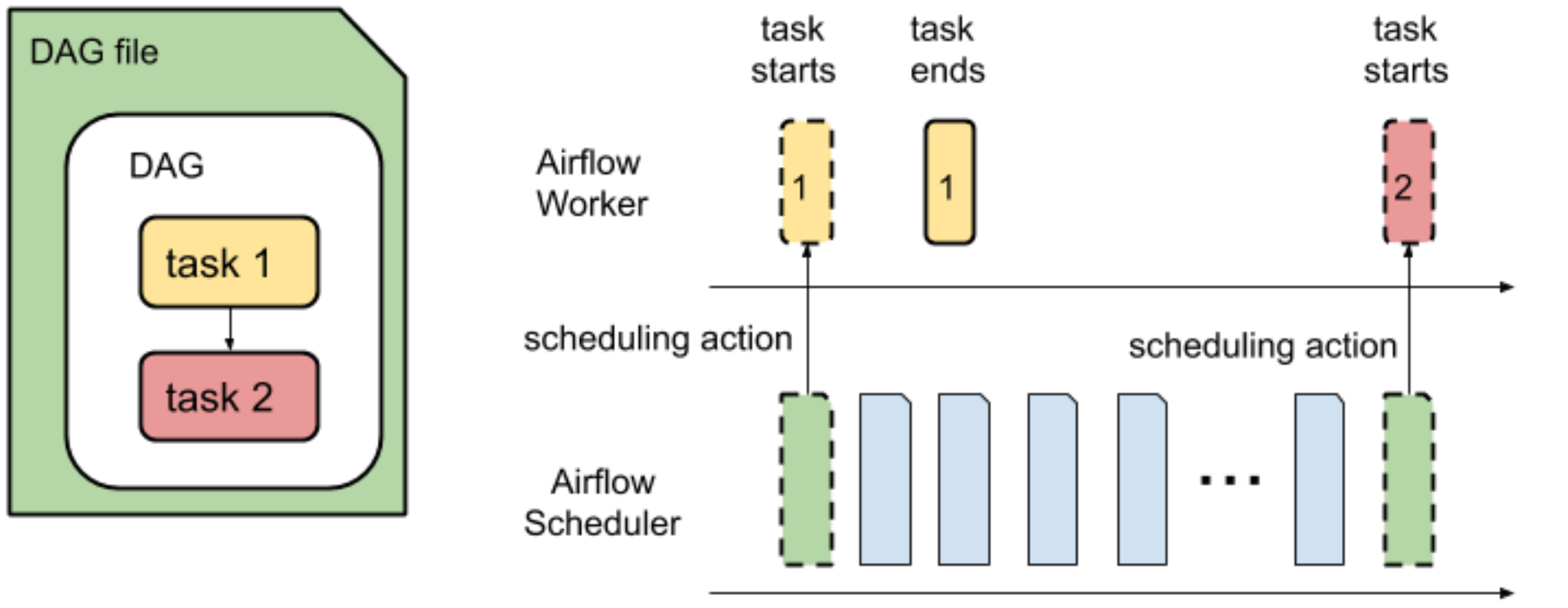
O tempo de análise de DAG é o tempo que o programador do Airflow demora a ler um ficheiro DAG e a analisá-lo.
Antes de o programador do Airflow poder agendar qualquer tarefa a partir de um DAG, o programador tem de analisar o ficheiro DAG para descobrir a estrutura do DAG e as tarefas definidas. Depois de o ficheiro DAG ser analisado, o programador pode começar a programar tarefas a partir do DAG.
O tempo de execução do DAG é a soma de todos os tempos de execução de tarefas de um DAG.
Para ver quanto tempo demora a executar uma tarefa específica do Airflow a partir de um DAG, na interface Web do Airflow, selecione um DAG e abra o separador Duração da tarefa. Este separador apresenta os tempos de execução das tarefas para o número especificado de últimas execuções de DAG.