Cloud Composer 3 | Cloud Composer 2 | Cloud Composer�
本頁面說明如何使用 DataflowTemplateOperator 從 Cloud Composer 啟動 Dataflow 管道。Cloud Storage Text 到 BigQuery 管道是一種批次管道,可讓您上傳儲存在 Cloud Storage 的文字檔案,並使用您提供的 JavaScript 使用者定義函式 (UDF) 轉換文字檔案,然後將結果輸出到 BigQuery。

總覽
開始工作流程前,請先建立下列實體:
來自空白資料集的空白 BigQuery 資料表,將包含下列資訊欄:
location、average_temperature、month,以及 (選用)inches_of_rain、is_current和latest_measurement。JSON 檔案,可將
.txt檔案中的資料正規化為 BigQuery 資料表結構定義的正確格式。JSON 物件會包含BigQuery Schema陣列,其中每個物件都會包含欄名、輸入類型,以及是否為必填欄位。輸入
.txt檔案,其中包含要批次上傳至 BigQuery 資料表的資料。以 JavaScript 編寫的使用者定義函式,可將
.txt檔案的每一行轉換為資料表的相關變數。指向這些檔案位置的 Airflow DAG 檔案。
接著,您會將
.txt檔案、.jsUDF 檔案和.json結構定義檔案上傳至 Cloud Storage bucket。您也會將 DAG 上傳至 Cloud Composer 環境。上傳 DAG 後,Airflow 會執行其中的工作。這項工作會啟動 Dataflow 管道,將使用者定義函式套用至
.txt檔案,並根據 JSON 結構定義設定格式。最後,資料會上傳至您先前建立的 BigQuery 資料表。
事前準備
- 如要撰寫使用者定義函式,您必須熟悉 JavaScript。
- 本指南假設您已擁有 Cloud Composer 環境。如要建立環境,請參閱「建立環境」。您可以使用任何版本的 Cloud Composer 搭配本指南。
Enable the Cloud Composer, Dataflow, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.請確認您具備下列權限:
- Cloud Composer 角色:建立環境 (如果沒有的話)、管理環境值區中的物件、執行 DAG,以及存取 Airflow UI。
- Cloud Storage 角色:建立值區並管理其中的物件。
- BigQuery 角色:建立資料集和資料表、修改資料表中的資料、修改資料表結構定義和中繼資料。
- Dataflow 角色:查看 Dataflow 工作。
請確認環境的服務帳戶有權建立 Dataflow 工作、存取 Cloud Storage 值區,以及讀取和更新 BigQuery 資料表中的資料。
建立含結構定義的空白 BigQuery 資料表
建立具有結構定義的 BigQuery 資料表。本指南稍後會使用這個結構定義。這個 BigQuery 資料表會保留批次上傳的結果。
如何建立含結構定義的空白資料表:
主控台
前往 Google Cloud 控制台的「BigQuery」頁面:
在導覽面板的「Resources」(資源) 區段,展開專案。
在詳細資料面板中,按一下「建立資料集」。
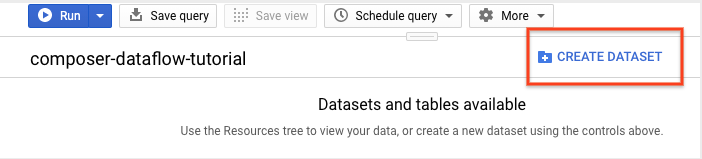
在「建立資料集」頁面的「資料集 ID」部分,為資料集命名
average_weather。其他欄位則一概保留預設值。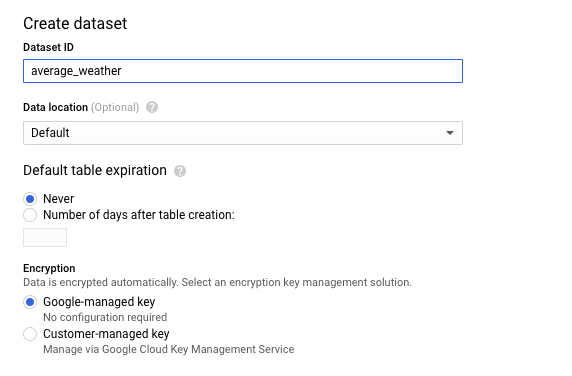
點選「建立資料集」。
返回導覽面板,在「Resources」(資源) 區段中展開專案。然後點選
average_weather資料集。在詳細資料面板中,按一下「建立資料表」。
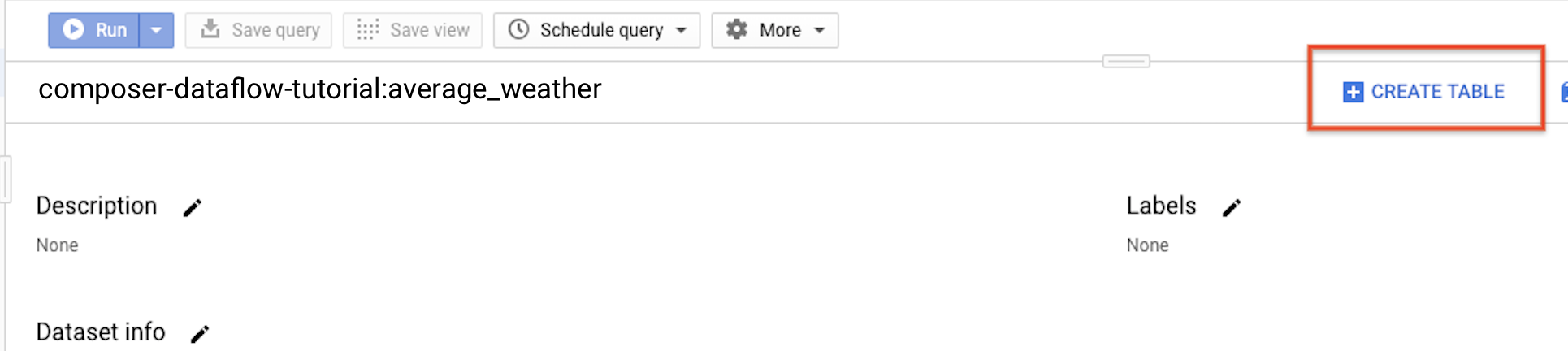
在「Create table」(建立資料表) 頁面的「Source」(來源) 區段中,選取「Empty table」(空白資料表)。
在「Create table」(建立資料表) 頁面的「Destination」(目的地) 區段中:
在「Dataset name」(資料集名稱) 部分,選擇
average_weather資料集。
在「Table name」(資料表名稱) 欄位中輸入名稱
average_weather。確認「Table type」(資料表類型) 設為「Native table」(原生資料表)。
在「Schema」(結構定義) 區段中,輸入結構定義。您可以採用下列其中一種做法:
啟用「以文字形式編輯」,然後以 JSON 陣列的形式輸入資料表結構定義,即可手動輸入結構定義資訊。在下列欄位中輸入資訊:
[ { "name": "location", "type": "GEOGRAPHY", "mode": "REQUIRED" }, { "name": "average_temperature", "type": "INTEGER", "mode": "REQUIRED" }, { "name": "month", "type": "STRING", "mode": "REQUIRED" }, { "name": "inches_of_rain", "type": "NUMERIC" }, { "name": "is_current", "type": "BOOLEAN" }, { "name": "latest_measurement", "type": "DATE" } ]使用「新增欄位」手動輸入結構定義:
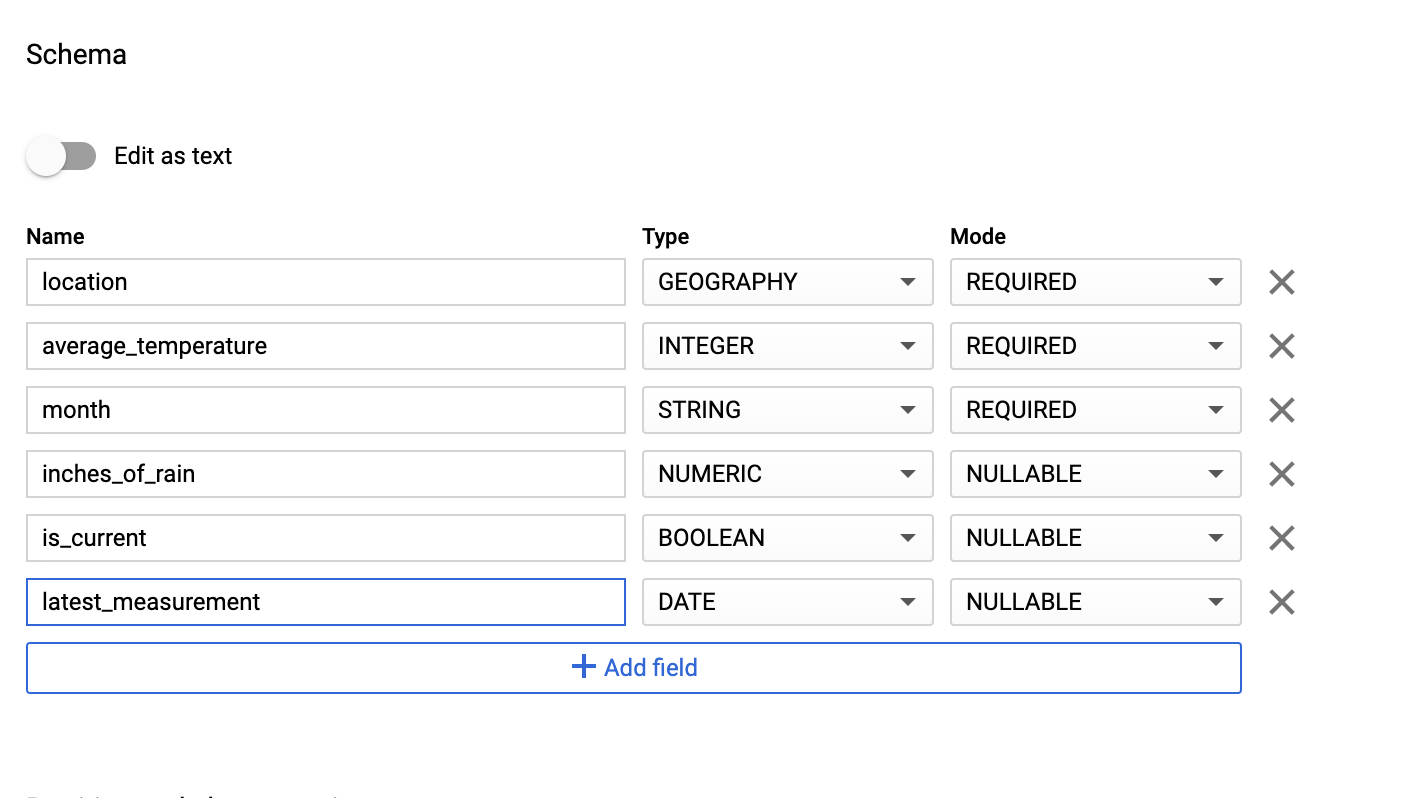
保留「Partition and cluster settings」(分區與叢集設定) 中的預設值:
No partitioning。在「Advanced options」(進階選項) 區段的「Encryption」(加密) 項目中,請保留預設值:
Google-owned and managed key。點選「建立資料表」。
bq
使用 bq mk 指令,在這個資料集中建立空白資料集和資料表。
執行下列指令,建立全球平均天氣資料集:
bq --location=LOCATION mk \
--dataset PROJECT_ID:average_weather
更改下列內容:
LOCATION:環境所在的區域。PROJECT_ID:專案 ID。
執行下列指令,在這個資料集中建立含有結構定義的空白資料表:
bq mk --table \
PROJECT_ID:average_weather.average_weather \
location:GEOGRAPHY,average_temperature:INTEGER,month:STRING,inches_of_rain:NUMERIC,is_current:BOOLEAN,latest_measurement:DATE
Python
將這段程式碼儲存為 dataflowtemplateoperator_create_dataset_and_table_helper.py,並更新其中的變數,以反映您的專案和位置,然後執行下列指令:
python dataflowtemplateoperator_create_dataset_and_table_helper.py
Python
如要向 Cloud Composer 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
建立 Cloud Storage 值區
建立 bucket,存放工作流程所需的所有檔案。您在本指南稍後建立的 DAG 會參照您上傳至這個儲存空間值區的檔案。如要建立新的儲存空間值區:
主控台
在 Google Cloud 控制台中開啟 Cloud Storage。
按一下「建立值區」,開啟值區建立表單。
輸入 bucket 資訊,並點選「繼續」來完成各個步驟:
為 bucket 指定全域不重複的名稱。本指南以
bucketName為例。選取「區域」這個位置類型,接下來,選取要儲存 bucket 資料的位置。
選取「Standard」做為資料的預設儲存空間級別。
選取「統一」存取權控管機制,即可存取物件。
按一下 [完成]。
gcloud
使用 gcloud storage buckets create 指令:
gcloud storage buckets create gs://bucketName/
更改下列內容:
bucketName:您在本指南稍早建立的值區名稱。
程式碼範例
C#
如要向 Cloud Composer 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
Go
如要向 Cloud Composer 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
Java
如要向 Cloud Composer 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
Python
如要向 Cloud Composer 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
Ruby
如要向 Cloud Composer 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
為輸出資料表建立 JSON 格式的 BigQuery 結構定義
建立 JSON 格式的 BigQuery 結構定義檔案,與您先前建立的輸出資料表相符。請注意,欄位名稱、類型和模式必須與先前在 BigQuery 資料表結構定義中定義的項目相符。這個檔案會將 .txt 檔案中的資料正規化為與 BigQuery 結構定義相容的格式。將這個檔案命名為 jsonSchema.json。
{
"BigQuery Schema": [
{
"name": "location",
"type": "GEOGRAPHY",
"mode": "REQUIRED"
},
{
"name": "average_temperature",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "month",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "inches_of_rain",
"type": "NUMERIC"
},
{
"name": "is_current",
"type": "BOOLEAN"
},
{
"name": "latest_measurement",
"type": "DATE"
}]
}
建立 JavaScript 檔案來格式化資料
您將在這個檔案中定義 UDF (使用者定義函式),提供邏輯來轉換輸入檔案中的文字行。請注意,這項函式會將輸入檔案中的每一行文字視為個別引數,因此函式會針對輸入檔案中的每一行執行一次。將這個檔案命名為 transformCSVtoJSON.js。
建立輸入檔案
這個檔案會包含您要上傳至 BigQuery 資料表的資訊。將這個檔案複製到本機,並命名為 inputFile.txt。
POINT(40.7128 74.006),45,'July',null,true,2020-02-16
POINT(41.8781 87.6298),23,'October',13,false,2015-02-13
POINT(48.8566 2.3522),80,'December',null,true,null
POINT(6.5244 3.3792),15,'March',14,true,null
將檔案上傳至 bucket
將下列檔案上傳至您先前建立的 Cloud Storage bucket:
- JSON 格式的 BigQuery 結構定義 (
.json) - JavaScript 使用者定義函式 (
transformCSVtoJSON.js) 要處理的文字輸入檔案 (
.txt)
主控台
- 在 Google Cloud 控制台,前往「Cloud Storage bucket」頁面。
在 bucket 清單中,按一下你的 bucket。
在值區的「物件」分頁中,從下列兩個方式擇一操作:
將需要的檔案從桌面或檔案管理員拖曳到 Google Cloud 主控台的主要窗格。
按一下「上傳檔案」按鈕,在出現的對話方塊中選取要上傳的檔案,然後按一下「開啟」。
gcloud
執行 gcloud storage cp 指令:
gcloud storage cp OBJECT_LOCATION gs://bucketName
更改下列內容:
bucketName:您在本指南中稍早建立的 bucket 名稱。OBJECT_LOCATION:物件的本機路徑。例如:Desktop/transformCSVtoJSON.js。
程式碼範例
Python
如要向 Cloud Composer 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
Ruby
如要向 Cloud Composer 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
設定 DataflowTemplateOperator
執行 DAG 前,請設定下列 Airflow 變數。
| Airflow 變數 | 值 |
|---|---|
project_id
|
專案 ID。範例:example-project。 |
gce_zone
|
必須建立 Dataflow 叢集的 Compute Engine 區域。例如:us-central1-a。如要進一步瞭解有效區域,請參閱地區和區域。 |
bucket_path
|
您稍早建立的 Cloud Storage bucket 位置。範例:gs://example-bucket |
現在,您將參照先前建立的檔案,建立啟動 Dataflow 工作流程的 DAG。複製這個 DAG,並以 composer-dataflow-dag.py 儲存至本機。
Airflow 2
Airflow 1
將 DAG 上傳至 Cloud Storage
上傳 DAG 至環境 bucket 中的 /dags 資料夾。上傳成功後,您可以在 Cloud Composer 環境頁面中,按一下「DAGs Folder」(DAG 資料夾) 連結查看。
查看工作狀態
- 前往 Airflow 網頁介面。
- 在 DAG 頁面中,按一下 DAG 名稱 (例如
composerDataflowDAG)。 - 在 DAG 詳細資料頁面中,按一下「Graph View」。
查看狀態:
Failed:工作周圍有紅框。 你也可以將指標懸停在工作上,然後尋找「狀態:失敗」。Success:工作周圍有綠框。 您也可以將指標懸停在工作上,檢查是否顯示「State: Success」。
幾分鐘後,您可以在 Dataflow 和 BigQuery 中查看結果。
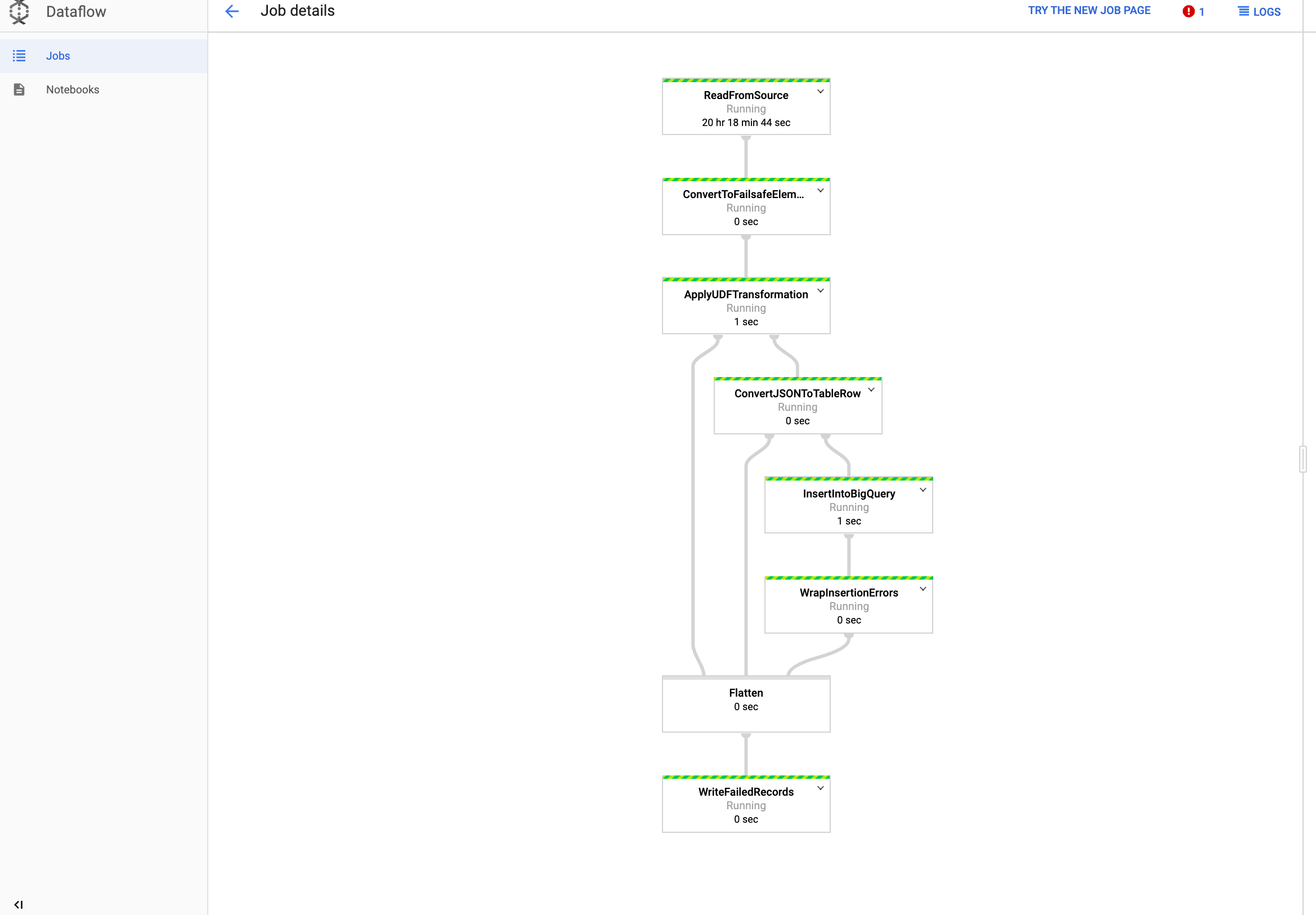
在 Dataflow 中查看工作
前往 Google Cloud 控制台的「Dataflow」頁面。
您的工作名稱為
dataflow_operator_transform_csv_to_bq,名稱結尾會以連字號加上專屬 ID,如下所示:
按一下名稱即可查看工作詳細資料。
在 BigQuery 中查看結果
前往 Google Cloud 控制台的「BigQuery」頁面。
您可以使用標準 SQL 提交查詢。使用下列查詢,查看新增至資料表的資料列:
SELECT * FROM projectId.average_weather.average_weather