碳足迹报告方法
本页介绍了与碳足迹工具提供的客户专属温室气体排放报告有关的背景、方法概要和技术细节。日后对数据源和方法所做的任何更改都会在“版本说明”中记录。
碳足迹报告简介
为帮助客户尽可能以最小的碳足迹经营业务,Google Cloud 提供了碳足迹工具。这样,每位客户都可以了解从 Google Cloud购买的商品对气候的影响,进而生成报告并采取措施来减少这些影响。
Google Cloud 客户通常会在多个区域使用各种Google Cloud 产品组合,这使得跟踪其工作负载的碳足迹变得复杂。为了向客户提供量身定制的碳足迹报告,Google 会检视为其内部服务提供支持的计算基础设施产生的碳排放。Google 会将这些排放量分配给每款 Google Cloud 产品,并根据客户对这些Google Cloud 产品的使用情况,将这些排放量分配给客户。
Google Cloud 碳足迹报告提供的客户专属温室气体排放量数据尚未经过第三方验证或鉴证。我们的方法或数据来源的任何更新都可能会导致计算结果发生实质性变化,并可能致使当前和以往 Google Cloud 由碳足迹报告提供的客户专属温室气体排放数据需要进行调整。
计算方法解析
碳足迹报告是根据广受认可的温室气体核算体系碳排放报告和核算标准 (GHGP) 编制的,该标准针对碳排放报告提供了详细的指导。
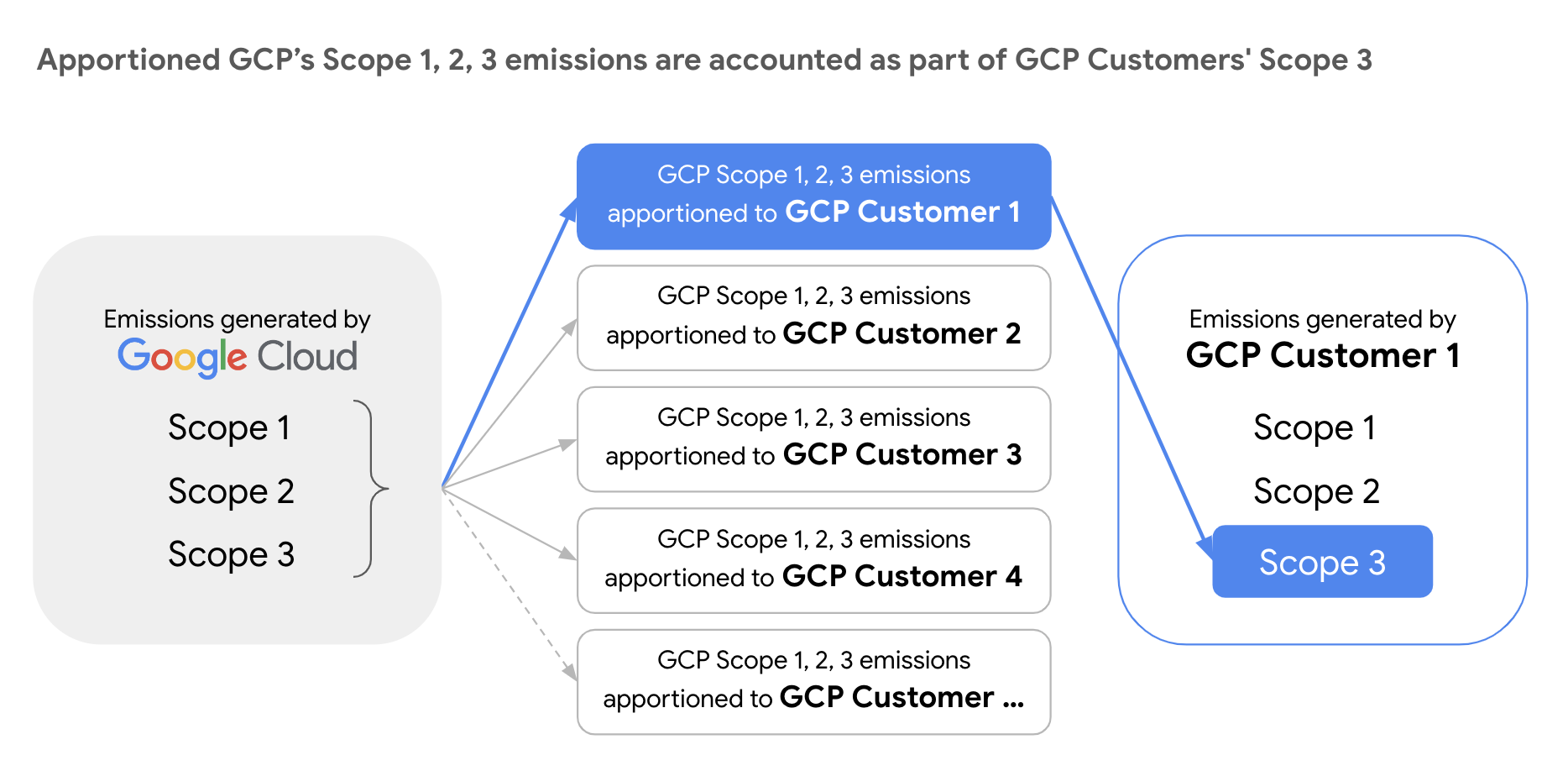
由于 Google Cloud 会根据使用情况将其排放量(包括 Google Cloud的范围 1、2 和 3)分配给所有客户,因此客户可以将分配的 Google Cloud 排放量数据作为范围 3 排放(与价值链相关的间接排放)纳入到自己的报告中。
碳足迹工具在报告和信息中心中使用 GHGP 基于位置和基于市场的报告标准。
基于位置的范围 2 碳排放数据表示给定位置所用的全部发电来源产生的碳排放。基于位置的排放数据未将 Google 的可再生购电协议或其他无碳电力合同纳入考量。因此,这些指标有助于客户在不考虑 Google 外购无碳电力的情况下,了解其对Google Cloud 产品的选择和使用模式如何影响温室气体排放。
根据 GHGP 基于市场的方法和标准,基于市场的范围 2 排放数据包括了 Google 外购无碳电力对相应数据中心的影响。 Google Cloud 如果客户希望为自己的产品和服务编制范围 3 年度排放清单,则基于市场的碳足迹可能最为有用。
碳足迹采用自下而上的计算方法,主要依赖 Google 数据中心内部的机器级电力和活动监控。这样,我们就可以将排放量分配给直接使用这些机器或推动机器购买决策的内部服务。这种精细程度最终使我们能够根据客户的具体使用情况来分配排放量。
除了基于位置和基于市场排放数据对 Google 购买的无碳电力采用不同的计算方式之外,碳足迹工具在估算基于位置和基于市场排放量时,也使用了不同精细级别的排放因子:
- 基于位置的排放是采用小时温室气体排放因子来计算的。这是因为向电网供电的发电机组在不断变化;小时温室气体排放因子能够逐小时反映发电来源的组合情况。当与每小时的电力负荷数据相结合时,这种计算方法能够生成一个排放数据,该数据能精准捕捉电网电力需求与为满足需求而调度的发电资源之间的动态关系。排放量计算的精细程度更高,更适合优化工作负载的位置和时间,以减少运营温室气体排放量。
- 基于市场的排放是采用年度温室气体排放因子来计算的。这是因为这些排放因子在企业温室气体核算的其他范围中最为常用。这些排放因子结合 Google 外购无碳电力的影响,使其成为适合纳入报告范围 3 排放清单的数据来源。
使用机器级数据和小时排放因子是一种新方法,因此这些排放报告尚未经过第三方验证或鉴证。尽管 Google 每年都会从独立的认证审计机构获得对其自上而下碳足迹的第三方鉴证,但生成这些客户报告所需的数据流和流程尚未经过类似的验证或鉴证。不过,第三方对我们按照 GHG 协议计算和分配产品产生的温室气体排放量并将其分配给各个客户的方法进行了详细审核,以便对我们的工作进行批评和改进。随着这项工作不断完善,我们期待进一步优化。 Google Cloud
边界
碳足迹报告涵盖以下活动产生的排放:
- 范围 1
- 现场燃烧的化石燃料,例如用于备用电源的柴油、用于供暖的天然气,以及车队车辆使用的燃料。
- 数据中心 HVAC 系统冷却剂的逸散性排放。
范围 2
- Google Cloud 产品的电力消耗,包括 Google 自有计算和网络设备以及冷却和照明等辅助电力服务的电力消耗,无论是在 Google 自有数据中心内还是在其他方拥有的设施中(基于位置和基于市场的计算方法)。
范围 3
- 数据中心设备的上游生命周期(隐含)排放。
- 数据中心建筑的上游生命周期(隐含)排放。
- 与在 Google 数据中心工作的员工相关的商务旅行和通勤。
- 发电(随后在输配电过程中产生损耗)。
- 电网发电所用燃料的开采、生产和运输。
碳足迹报告不包括以下活动产生的排放:
- 因互联网服务提供商合作伙伴部署小型设备而产生的排放量。
- 部署在数据中心外部的 Google 网络设备产生的排放。
- 数据中心设备和建筑物的下游生命周期排放。
- 与电网发电设施和设备相关的隐含排放。
方法
系统会自动计算 Google Cloud 客户专属的碳足迹报告(以下简称“碳足迹报告”)。本部分介绍了 Google Cloud 如何进行这些计算。
主要概念
- Google Cloud 是一个共享的计算平台。其计算资源(如处理能力、内存、存储空间、网络等)由 Google Cloud 客户共享。
Google 围绕称为内部服务的功能单元进行组织。内部服务是指在 Google 的数据中心机器上运行的特定软件功能。Google Cloud 产品使用内部服务,并以面向客户的产品单元 (SKU) 的形式进行消耗。
电力消耗是 Google Cloud温室气体排放的最大来源之一。数据中心会将计算资源整合到共用建筑物中。这些建筑物会消耗电力来运行计算设备,照明、制冷、电力系统和其他辅助需求也要额外消耗电力。
电力由世界各地不同电网中的各种发电厂提供。发电产生的温室气体因发电所用燃料(例如天然气、煤炭、风力、太阳能、水力)等因素而异。每个电网的发电来源各不相同,且一个电网内的发电来源在一天中也会有所变化。
将 Google Cloud的电力消耗及其产生的碳足迹细分到特定产品和客户是一项技术难题。由于客户的计算需求需要调用多层次的共享资源,确定客户的碳足迹非常复杂。通过制定新的分配方法和假设(在下文深入讨论), Google Cloud 可以生成适合且能代表每位客户云计算使用情况和产品选择的客户碳足迹报告。
计算摘要
碳足迹工具首先会根据计算资源使用情况和数据中心资源需求计算能耗。然后,碳足迹工具会基于位置和基于市场计算因使用电力而产生的碳排放,并将这些排放量分配给客户,进而分配给每个客户购买的产品。然后,系统会将每位客户和每件产品因使用电力而产生的碳排放量与非电力来源的排放量按比例分配。
基于市场的排放指标会将 Google 购买的清洁电力与相关数据中心负载进行匹配,以便在 Google 购买清洁能源的任何地方建立基于市场的区域性电力排放因子。在按市场统计的排放报告中,基于市场的区域性排放因子取代了基于位置的排放因子。
能耗与内部服务能耗分配
为了将机器总能耗分配到内部服务,Google 会分别评估运行工作负载时的能耗(“动态功耗”)与机器空闲时的能耗(“空闲功耗”)。根据内部服务的相对 CPU 占用率,将每台机器的每小时动态功耗分配给在该小时所支持的内部服务。根据每个内部服务在数据中心内的“资源分配”(CPU、RAM、SSD、HDD)情况,为其分配机器空闲功耗。
根据机器在相应小时内的总能耗,将每小时能源开销(电力系统、制冷和照明)分配给每台机器及其用户。
Google 的共享基础架构服务会跟踪调用它们的其他内部服务的使用情况。这样,系统就可以根据这些内部服务的相对使用情况,将共享基础架构服务的能耗重新分配给这些内部服务。对于某些没有足够使用数据的内部服务,Google 会使用内部成本重新分配共享基础设施的能源消耗。
完成这些计算和分配后,我们得到分配给每个数据中心中每个内部服务的每小时用电量。
参与非公开预览的客户可以查看与每个客户的使用情况相关的能耗。
电力产生的温室气体排放:基于位置的计算方法
Google 会将特定位置的能耗乘以电网电力碳排放强度因子,每小时计算一次按位置统计的温室气体排放量。这反映了在能源消耗地点馈送到电网的实际能量来源(化石燃料、可再生能源等)组合。值得注意的是,基于位置的范围 2 碳排放不考虑能源采购选择或合同(例如能源属性证书 [EAC] 或购电协议 [PPA])。
纳入碳足迹报告中的每小时电网碳排放强度数据仅涵盖与发电相关的排放,不包括其他生命周期阶段。小时排放因子数据由 Electricity Maps 提供。如果 Electricity Maps 数据不可用,Google 会使用国际能源署发布的各国家/地区年度平均碳排放强度因子。
为了计算排放量,Google 会将每个位置每个内部服务的每小时能耗乘以相应时段和位置的适当碳排放强度因子,以确定每个位置每小时相应内部服务基于位置的电力碳足迹。
电力产生的温室气体排放:基于市场的计算方法
基于市场的电力碳足迹是根据 GHGP 标准,将 Google 购买的清洁电力与相关数据中心负载进行匹配来估算。
Google 按年计算基于市场的排放,并会考虑我们清洁电力合同设施的实际发电量以及每个场所的用电量。此计算使用国际能源署发布的政府来源的公开年度排放因子。
在每个购买清洁电力的地区,Google 为其数据中心按基于市场的方法计算年度总排放量。基于位置的电力排放通过该地区上一年度可再生电力百分比占比进行缩减。这个缩放比例乘以相应地区基于位置的精细排放计算结果,即得到按客户和产品细分的按市场统计的月度排放报告。
基于市场的缩放比例每年调整一次,因为它依赖于 Google 整体基于市场的排放量计算方法。因此,基于市场的排放报告不会显示 Google 在任何给定时间的电力采购和可再生发电的动态视图,而是代表我们上一年的可再生能源活动。
GHGP 范围 2 指南规定,只有当所购买的清洁能源在同一地理区域内生成并在合理的时间范围内使用时,才能将其视为零排放。
请注意,基于位置的排放数据和基于市场的排放数据所用的排放因子不同。
- 基于位置的排放是采用小时温室气体排放因子来计算的。这是因为向电网供电的发电机组在不断变化;小时温室气体排放因子能够逐小时反映发电来源的组合情况。当与每小时的电力负荷数据相结合时,这种计算方法能够生成一个排放数据,该数据能精准捕捉电网电力需求与为满足需求而调度的发电资源之间的动态关系。排放量计算的精细程度更高,更适合优化工作负载的位置和时间,以减少运营温室气体排放量。
- 基于市场的排放是采用年度温室气体排放因子来计算的。这是因为这些排放因子在企业温室气体核算的其他范围中最为常用。这些排放因子结合 Google 外购无碳电力的影响,使其成为适合纳入报告范围 3 排放清单的数据来源。
向 SKU 分配电力碳足迹
每个 Google Cloud 商品都会作为面向客户的商品单元进行消耗,并通过其唯一的 SKU 进行标识。Google 会将每个 SKU 与提供它的内部服务相关联(该服务通常与等效的 Google Cloud 产品一对一映射)。并非所有 Google Cloud 产品都在碳足迹报告的涵盖范围内,因为这种映射并不总是可行。SKU 用量是分配各 Google Cloud 产品的电力碳足迹总量的主要方式。
Google 首先量化每个 SKU 的排放足迹。内部服务的碳足迹会按其使用量(购买数量)和定价(全部以美元为单位)的比例分配给其 SKU,同时还会考虑内部服务部署在每个位置的碳强度不同。此分配以一系列满足以下原则的方程的形式求解:
- 部署在同一位置的给定内部服务的 SKU 的碳足迹与其定价成正比
- 部署在多个位置的特定内部服务的特定 SKU 在每个位置的碳足迹不同,与每个位置的电网碳强度成正比
- 每个内部服务中所有 SKU 的汇总足迹等于该内部服务的总碳足迹,加上上述内部服务分配中未计入的某些活动产生的一些开销。所有 SKU 的总电力碳足迹等于Google Cloud 基于位置的电力碳足迹总和。
向客户分配电力碳足迹
解算这些方程可得出每个 SKU 在其部署的每个区域的总碳足迹。计算电量消耗的最后一步是将 SKU 的区域碳足迹分配给特定客户,并汇总为有实际意义的单位(产品、项目、区域)。以下是此流程的概览:
- 首先,将每个 SKU 的碳足迹除以给定地区的 SKU 总使用量(销量指标),以确定每个 SKU 在该地区的每次使用碳强度因子。
- 然后,将每个客户在每个地区对每个 SKU 的使用量乘以相应的 SKU 碳强度因子。这样便可生成按 SKU、按地区和按客户的足迹。
- 然后,客户 SKU 足迹会汇总为特定于客户的Google Cloud 产品足迹,以提高对所报告碳排放量数据的信心。
- 最后,系统会将数据汇总到月度粒度,以最大限度地减少每日波动。生成的报告包含客户专属的基于位置的电力碳足迹,按月总计,并按Google Cloud 产品、客户定义的项目和区域进行细分。
请注意,我们会进行验证,以确保客户的所有电力碳足迹总和等于 Google Cloud基于位置的电力碳足迹总和。
非电力排放源
尽管电力生产产生的排放占Google Cloud碳排放的大部分,但其他排放源也对总排放量有所贡献。
碳足迹工具使用 Google 公司整体排放清单的非电力排放源数据流。因此,在计算非电力来源的排放并添加到广告碳足迹时,不如电力排放那样动态和精细。 Google Cloud虽然我们按小时测量电力消耗及基于地理位置的相关排放,但其他来源的排放数据是按月或按年建立的,且无法提供具体地理位置的数据。请注意,Google 公司整体关于数据中心设备和数据中心设施的隐含排放数据尚未经过鉴证。
为了在碳足迹报告中将公司整体非电力排放量分配给客户的具体细分数据,我们会确定一个分配系数(即客户 Google Cloud 电力消耗与 Google Cloud 总电力消耗的比率),然后将该系数乘以每个来源的全球 Google Cloud 排放量(按此处所述方法确定)。
数据中心设备的隐含排放:该排放源包括提取、精炼物料并将物料运输至设备制造地点所需的活动,以及与制造过程相关的排放。通过生命周期分析,Google 已为每台数据中心设备建立了隐含排放足迹。然后,将此足迹在 4 年的时间范围内分摊(选择 4 年是为了符合我们的财务会计准则,但实际上我们发现设备的使用寿命要长得多),即可确定每台设备的年度排放总量。
Google 数据中心内的机器总数及所有设备的总排放量每月都会更新,将新增机器纳入排放统计范围,达到 4 年使用年限的机器则会从中去除。
数据中心设施的隐含排放:该排放源包括提取、精炼物料并将物料运输至数据中心施工地点所需的活动,以及与施工本身相关的排放 - 包括冷却系统和电源系统等现场基础设施。通过生命周期分析,Google 已为数据中心建设建立了碳排放足迹。新建数据中心可在此基础上根据自身规模(数据容量)进行相应调整即可确定碳足迹。然后,这一经过调整的碳足迹会在 20 年的时间范围内分摊(选择 20 年是为了符合我们的财务会计准则)。
每月,Google 都会将新增建筑容量纳入到对设施隐含排放的持续计算中。
现场燃烧化石燃料:该排放源包括数据中心现场使用的所有燃料,例如备用电源、水和空间供暖以及运输(车队车辆)。作为年度排放报告过程的组成部分,Google 每年都会收集所有相关记录,汇总数据中心的总燃料消耗量,并计算由此产生的碳足迹。
数据中心燃料排放总量数据每年都会更新,以便准确计算碳足迹。
数据中心员工的通勤和商务旅行:该排放源包括与在 Google 数据中心工作的员工相关的旅行和通勤。Google 每年都会收集员工的旅行记录和通勤方式的估算数据,据此建立该活动在全球范围内的总排放足迹。然后,将某一数据中心员工在 Google 员工总数中的占比乘以 Google 全球排放总量,即可得出该数据中心员工的总排放量。
数据中心通勤和旅行排放总量数据每年都会更新,以便准确计算碳足迹。
技术详情
用电量
本部分介绍了 Google 自下而上的能源消耗计算方法。
首先,每台机器为一个或多个内部服务运行工作负载。Google 逐小时记录使用每台机器的内部服务。与此类似,Google 还会逐小时记录每台机器的用电量。
机器的电力消耗是执行工作负载所用功耗(动态功耗)和机器空闲时所用功耗(空闲功耗)的混合。您可以通过以下两种不同的方法将这些机器级的电力消耗分配至内部服务一级:
- 每台机器的每小时动态功耗会分配给在该小时内其支持的内部服务。当工作负载运行时,CPU 的使用是资源消耗的主要贡献者。Google 会监控数据中心内每台机器和内部服务工作负载的 CPU 使用情况。如果只有一个内部服务在使用一台机器,则会将该机器的动态能耗分配给该内部服务。如果一台机器支持多个内部服务,Google 会根据机器上运行的每个内部服务的 CPU 使用比例分配动态功耗。
- 根据每个内部服务在数据中心内的资源分配情况,为 Google 内部服务分配空闲能耗。让机器空闲的一个重要原因是希望计算资源(CPU、RAM、HDD、SDD)“随时待命”,以便在无延迟或无中断的情况下执行不确定但可能较大的工作负载。空闲功耗根据已购买的计算资源水平分配,无论内部服务是否正在使用这些资源。这种分配方式会为每个数据中心所在位置的每个内部服务生成空闲功耗分配。
然后,数据中心的电力开销负载(电力系统、制冷、照明)会分配给数据中心内的每台机器。Google 在建筑一级测量此负载,并在子建筑一级使用经过验证的算法更精确地估算此负载,这些算法是 Google 能效监控系统的组成部分。在子建筑级估算的电力开销负载会按照已确定的动态功耗和空闲功耗分配比例,分配到该区域内部署的每台机器上。
接下来,共享基础设施服务软件层所需的电力根据更高级别的内部服务对这些基础设施服务的使用情况进行分配。共享基础设施服务的开销负载已包含在电力消耗分配中。这种分配仍在内部服务(而非机器)层级进行。
对于使用情况数据不足的内部服务,Google 会使用内部服务之间的事后分摊成本来重新分配共享基础设施的能源消耗。例如,Artifact Registry 使用 Cloud Storage。因此,重新分配给 Artifact Registry 的 Cloud Storage 能耗所占的比例为 Artifact Registry 使用 Cloud Storage 服务的费用除以 Cloud Storage 的总费用。某些内部服务不会产生收入。如果某项内部服务的收入为零或正,其所有能耗将重新分配给使用它的其他内部服务。
温室气体排放
本部分介绍了 Electricity Maps 的计算方法。
电网碳排放因子始于平衡机构提供的发电数据。这些数据提供了日内能源结构,即电网中不同电厂的相对发电量。然后,Electricity Maps 会添加互联电网之间的实时电力进出口数据。
最后,Electricity Maps 使用政府间气候变化专门委员会 (IPCC) 2014 年针对每种发电来源(例如煤炭、天然气、水电等)发布的发电排放因子,为每个电网创建按量加权的小时碳排放强度因子(每兆瓦时发电的排放量)。您可以在此处查看 Electricity Maps 的碳强度因子。
请注意,Electricity Maps 并未提供所有 Google Cloud 位置的数据,尤其是在亚洲地区存在明显的数据缺口。在这些数据不可用的情况下,Google 使用国际能源署发布的各国家/地区年度平均碳强度因子。
Google 将相关的碳排放强度因子映射到其每个 Cloud 位置。然后,我们将每个位置每个内部服务的每小时能耗乘以该位置的相应碳排放强度因子,即可确定每个位置每小时相应内部服务基于位置的碳足迹。每个内部服务的碳足迹每 24 小时汇总一次,以生成该内部服务在每个位置的每日足迹。这些基于位置的足迹会每天汇总为每个 Google Cloud 区域的内部服务足迹,以及全球总足迹。
向 SKU 和客户分配碳足迹
每个内部服务的基于位置的排放量会分配给 Google Cloud可供客户购买的产品单元 (SKU),然后 SKU 基于位置的碳足迹会汇总到 Google Cloud 产品,以便生成客户报告。
每个 Google Cloud 商品都包含一个或多个面向客户的单元,这些单元可供购买,并通过唯一的 SKU 进行标识(请参阅所有 Google Cloud SKU)。例如,Cloud Storage 是一项服务,而 Cloud Storage“芬兰标准存储空间”“芬兰 Nearline 存储空间”“芬兰 Coldline 存储空间”和“芬兰归档存储空间”是 SKU,表示芬兰 Cloud Storage 服务的不同存储类别(请参阅 所有 Cloud Storage SKU)。
Google Cloud 会将“购买的 SKU”用作在客户之间分配每个Google Cloud 产品的基于位置的碳足迹总量的首要方式。 Google Cloud请注意,大多数 Google Cloud SKU 都是体积型 SKU。例如,某些存储空间 SKU 的价格和购买方式是以每 TB 为单位。客户购买任何给定商品的数量(我们称之为“SKU 使用量”)是数据中心义务和负载的重要因素。