Incentro: How we built a serverless digital archive with machine learning APIs, Cloud Pub/Sub and Cloud Functions
Kees van Bemmel
Managing Director, Incentro
Editor’s note: Today we hear from Incentro, a digital service provider and Google partner, which recently built a digital asset management solution on top of Google Cloud Platform (GCP) It combines machine learning services like Cloud Vision and Speech APIs to easily find and tag digital assets, plus Cloud Pub/Sub and Cloud Functions for an automated, serverless solution. Read on to learn how they did it.
Here at Incentro, we have a large customer base among media and publishing companies. Recently, we noticed that our customers struggle with storing and searching for digital media assets in their archives. It’s a cumbersome process that involves a lot of manual tagging. As a result, the videos are often stored without being properly tagged, making it nearly impossible to find and reuse these assets afterwards.
To eliminate this sort of manual labour and to generate more business value from these expensive video assets, we sought to create a solution that would take care of mundane tasks like tagging photos and videos. This solution is called Segona Media, and lets our customers store assets and tag and index their digital assets automatically.
Segona Media management features
Segona Media currently supports images, video and audio assets. For each of these asset types, Google Cloud provides specific managed APIs to extract relevant content from the asset without customers having to tag them manually or transcribe them.- For images, Cloud Vision API extracts most of the content we need: labels, landmarks, text and image properties are all extracted and can be used to find an image.
- For audio, Cloud Speech API showed us tremendous results in transcribing an audio track. After extracting the audio into speech, we also use Google Cloud Natural Language API to discover sentiment and categories in the transcription. This way, users can search for spoken text, but also search for categories of text and even sentiment.
- For video, we typically use a combination of audio and image analysis. Cloud Video Intelligence API extracts labels and timeframes, and detects explicit content. On top of that, we process the audio track from a video the same way we process audio assets (see above). This way users can search content from the video as well as from spoken text in the video.
Segona Media architecture
The traditional way for developing a solution like this involves getting hardware running, determining and installing application servers, databases, storage nodes, etc. After developing and getting the solution into production you may then come across a variety of familiar challenges: the operating system needs to be updated or upgraded or databases don't scale to cope with unexpected production data. We didn't want any of this, so after careful consideration, decided on a completely managed solution and serverless architecture. That way we’d have no servers to maintain, we could leverage Google’s ongoing API improvements and our solution could scale to handle the largest archives we could find.We wanted Segona Media to also be able to easily connect to common tools in the media and publishing industries. Adobe InDesign, Premiere, Photoshop and Digital Asset Management solutions must all be able to easily store and retrieve assets from Segona Media. We solved this by using GCP APIs that were already in place for storing assets in Google Cloud Storage and just take it from there. We retrieve assets using the managed Elasticsearch API that runs on GCP.
Each action that Segona Media performs is a separate Google Cloud Function, usually triggered mostly by a Cloud Pub/Sub queue. Using a Pub/Sub queue to trigger a Cloud Function is an easy and scalable way to publish new actions.
Here’s a high-level architecture view of Segona Media:
High Level Architecture
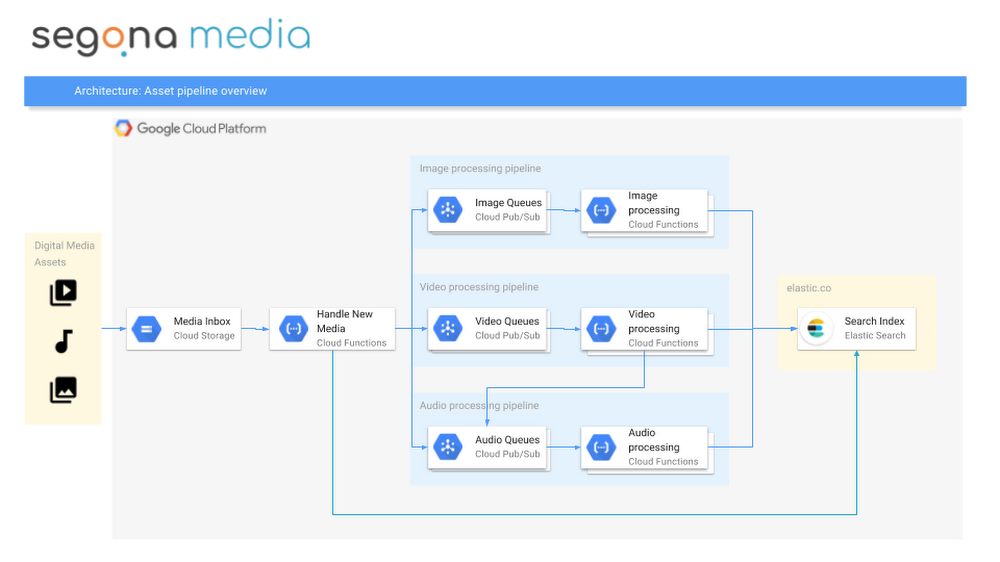
And here's how the assets flow through Segona Media:
- An asset is uploaded/stored to a Cloud Storage bucket
- This event triggers a Cloud Function, which generates a unique ID, extracts metadata from the file object, moves it to the appropriate bucket (with lifecycle management) and creates the asset in the Elasticsearch index (we run Elastic Cloud hosted on GCP).
- This queues up multiple asset processors in Google Cloud Pub/Sub that are specific for an asset type and that extract relevant content from assets using Google APIs.
Media asset management
Now, let's see how Segona Media handles different types of media assets.Images
Images have a lot of features on which you can search, which we do via a dedicated microservice processor.
- We use ImageMagick to extract metadata from the image object itself. We extract all XMP and EXIF metadata that's embedded in the file itself. This information is then added to the Elastic index and makes the image searchable by, for example, copyright info or resolution.
- Cloud Vision API extracts labels in the image, landmarks, text and image properties. This takes away manual tagging of objects in the image and makes a picture searchable for its contents.
- Segona Media offers customers to create custom labels. For example, a television manufacturer might want to know the specific model of a television set in a picture. We’ve implemented custom predictions by building our own TensorFlow models trained on custom data, and we train and run predictions on Cloud AI Platform.
- For easier serving of all assets, we also create a low resolution thumbnail of every image.
Audio
Processing audio is pretty straightforward. We want to be able to search for spoken text in audio files, and we use Cloud Speech API to extract text from the audio. We then feed the transcription into the Elasticsearch index, making the audio file searchable by every word.Video
Video is basically the combination of everything we do with images and audio files. There are some minor differences though, so let's see what microservices we invoke for these assets:- First of all, we create a thumbnail so we can serve up a low-res image of the video. We take a thumbnail at 50% of the video. We do this by combining FFmpeg and FFprobe in Cloud Functions, and store this thumbnail alongside the video asset. Creating a thumbnail with Cloud Functions and FFmpeg is easy!
- Using the same FFmpeg architecture, we extract the audio stream from the video. This audio stream is then processed like any other audio file: We extract the text from spoken text in the audio stream and add it to the Elastic index so the video itself can also be found by searching for every word that's spoken. We extract the audio stream from the video in a single channel FLAC format as this gives us the best results.
- We also extract relevant information from the video contents itself using Cloud Video Intelligence. We extract labels that are in the video as well as the timestamps for when the labels were created. This way, we know which objects are at what point in the video. Knowing the timestamps for a given label is a fantastic way to point a user to not only a video, but the exact moment in the video that contains the object they're looking for.




