Going multi-cloud with Google Cloud Endpoints and AWS Lambda
Sowmya Kannan
Global Lead, Future Workforce
A multi-cloud strategy can help organizations leverage strengths of different cloud providers and spread critical workloads. For example, maybe you have an existing application on AWS but want to use Google’s powerful APIs for Vision, Cloud Video Intelligence and Data Loss Prevention, or its big data and machine learning capabilities to analyze and derive insights from your data.
One pattern (among many) to integrate workloads on Google Cloud Platform (GCP) and Amazon Web Services (AWS) is to use Google Cloud Endpoints and AWS Lambda. The pattern has the following architecture.
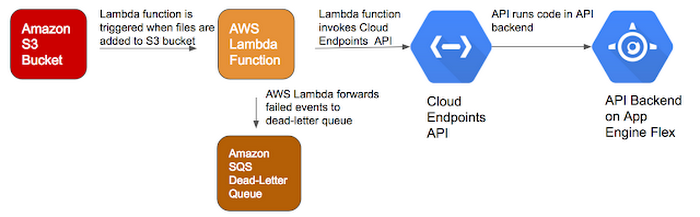
Cloud Endpoints enables you to develop, deploy, protect and monitor APIs based on the OpenAPI specification. Further, the API for your application can run on backends such as App Engine, Google Container Engine or Compute Engine.
AWS Lambda can automatically run code in response to events in other AWS services. For example, you can configure an AWS Lambda function to fire when an object is added to an Amazon S3 bucket, when a notification comes into an Amazon SNS topic or to process records in a DynamoDB Stream.
Note: When moving data from Amazon S3 to Google Cloud, Amazon S3 requests and data transfer changes apply.
In this blog, we'll create a Cloud Endpoints API and invoke it from an AWS Lambda function. You can download the complete source code for this sample from GitHub. Read on to learn how to implement this solution.
Setting up Cloud Endpoints
The first step toward implementing the solution is to deploy Cloud Endpoints APIs on App Engine flexible environment. GCP documentation contains excellent Quick Start topics with information to deploy APIs on App Engine flexible environment, Container Engine and more.Create a GCP Project, if you don’t already have one:
- Use the GCP Console to create a new GCP project and an App Engine application.
- When prompted, select the region where you want to run your App Engine application located and then enable billing.
- Note the ID of your project, because you'll need it later.
- Activate Google Cloud Shell
Retrieving source code
In Google Cloud Shell:- Clone the GitHub repository with source code for the example.
- Change directory to
blogs/endpointslambda/aeflex-endpoints/ - Launch the code editor to view source code.
Implementing application code
Next, you’ll need to implement code for your API backend. The aeflex-endpoints example is a Flask application. The main.py file defines the application code that should be executed when the processmessage endpoint is invoked.Configuring and deploying the Cloud Endpoints API
Use the OpenAPI specification to define your API. In the aeflex-endpoints example, the openapi.yaml file contains the OpenAPI specification for the API. For more information about each field, see documentation about the Swagger object.The openapi.yaml file declares that the host that will be serving the API. host: "echo-api.endpoints.aeflex-endpoints.cloud.goog"
The /processmessage endpoint is defined in the paths section. The inputMessage parameter contains the details about the Amazon S3 object to be processed.
paths:
Then, deploy the Open API specification:
This command returns the following information about the deployed Open API specification:
Update the service configuration in the app.yaml file:
Deploy the API:
Create an API Key to Authenticate Clients:
- In the GCP Console, on the Products & services menu, click API Manager > Credentials.
- Click Create Credentials > API key. Note the API key.
Setting up the AWS Lambda function
This section describes how to set up and trigger a Lambda function when a file is uploaded to an Amazon S3 bucket. In this example, the Lambda function is written in Python. The complete source code for the Lambda function is available in
Creating the S3 Bucket for your files
In the S3 Management Console in AWS, create an S3 bucket called images-bucket-rawdata. Your Lambda function will be triggered when files are added to this bucket.Creating an IAM Role
In the IAM Management Console, create an IAM role that has the permissions for the Lambda function to access the S3 bucket, SQS queue and CloudWatch logs as follows:- In the IAM Management Console, click Roles in the navigation pane.
- Create a new role called LambdaExecRole.
- Select AWS Lambda Role Type, and then select the following policies:
- AWSLambdaExecute: This policy gives the Lambda function Put and Get access to S3 and full access to CloudWatch Logs.
- AmazonSQSFullAccess: This policy gives the Lambda function permissions to send messages to the dead-letter queue (DLQ).
- Review the settings and create the role.
Creating an SQS queue
- In the SQS Management Console, create an SQS queue called IntegrationDLQ that will act as the dead-letter queue for your Lambda function. AWS Lambda automatically retries failed executions for asynchronous invocations. In addition, you can configure Lambda to forward payloads that were not processed to a dead-letter queue.
Creating a Lambda function in the AWS Console
In the Lambda Management Console, create a Lambda function as follows:- In the Select blueprint page, use the s3-get-object-python blueprint.
- In the Configure triggers page, specify the following:
- Bucket: images-bucket-rawdata
- Event-type: Object-Created (All)
- Enable the trigger.
- In the Configure Function page, specify the following:
- Name: CallEndpoint
- Runtime: Python 2.7
- Code entry type: Edit code inline
- Environment variable key: ENDPOINT_API_KEY
- Environment variable: . Note: For production environments, consider securing the API key using encryption helpers in AWS.
- Handler: lambda_function.lambda_handler
- Role: Choose an existing role
- Existing role: LambdaExecRole (that you created earlier)
- In Advanced settings, DLQ resource: IntegrationDLQ
- In the inline code editor for the Lambda function, replace the original code with the following code. The Lambda function retrieves the bucket and object information from the event, retrieves object metadata, generates a pre-signed url for the object, and finally invokes the Cloud Endpoints API.
from __future__ import print_function import boto3 import json import os import urllib import urllib2 print('Loading function') s3 = boto3.client('s3') endpoint_api_key = os.environ['ENDPOINT_API_KEY'] endpoint_url = "https://aeflex-endpoints.appspot.com/processmessage" def lambda_handler(event, context): # Get the object information from the event bucket = event['Records'][0]['s3']['bucket']['name'] object_key = urllib.unquote_plus(event['Records'][0]['s3']['object']['key'].encode('utf8')) try: # Retrieve object metadata response = s3.head_object(Bucket=bucket, Key=object_key) # Generate pre-signed URL for object presigned_url = s3.generate_presigned_url('get_object', Params = {'Bucket': bucket, 'Key': object_key}, ExpiresIn = 3600) data = {"inputMessage": { "Bucket": bucket, "ObjectKey": object_key, "ContentType": response['ContentType'], "ContentLength": response['ContentLength'], "ETag": response['ETag'], "PresignedUrl": presigned_url } } headers = {"Content-Type": "application/json", "x-api-key": endpoint_api_key } # Invoke Cloud Endpoints API request = urllib2.Request(endpoint_url, data = json.dumps(data), headers = headers) response = urllib2.urlopen(request) print('Response text: {} \nResponse status: {}'.format(response.read(), response.getcode())) return response.getcode() except Exception as e: print(e) print('Error integrating lambda function with endpoint for the object {} in bucket {}'.format(object_key, bucket)) raise e
- Review the Lambda function configuration and create the function.
Testing the integration
Now for the moment of truth! To test the integration between your AWS Lambda function and Cloud Endpoints API, follow the steps below:- In the AWS S3 Management Console, upload a file to images-bucket-rawdata.
- In the Lambda Management Console, navigate to the CallEndpoint function, and view the Monitoring tab. The CloudWatch graphs show that the function was invoked successfully.
- Click View Logs in CloudWatch and view the details for the function’s log stream. The log shows that the Lambda function received a success response code (200) from the API as well as details about the S3 event that the API received from the Lambda function.



