Drawings in the Cloud: introducing the Quick, Draw! dataset
By Ian Johnson
Data Visualization and UX Engineer
Quick, Draw! is an AI experiment that has delighted millions of people across the world. The game asks users to draw a doodle, then the game’s AI tries to guess what it is. Along the way, we’ve had the opportunity to help teach a neural network to recognize drawings, plus generate the world’s largest doodling data set, which is shared publicly to help further machine learning research. Over a billion doodles have been drawn by people playing the game and subsequently collected into this anonymized dataset. We’ve now released 50 million of those drawings, and we’re thrilled that it’s stirred interest in the ML research community as well as the general public.
Quick, Draw! was brought to life through a collaboration between artists, designers, developers and research scientists from different teams across Google. But it was all made possible through Google Cloud Platform services like App Engine, Cloud Datastore, and BigQuery. Read on to learn how the game was built, and how you can get your hands on what’s arguably the world’s cutest research dataset.

The game
The original Quick, Draw! game was developed and deployed on App Engine by Jonas Jongejan on the Google Creative Lab team. App Engine’s flexibility and ease-of-use allowed them to focus on making the game fun. Furthermore, the team found they didn't have to do any extra infrastructure work after they launched. Even with over 30,000 people playing at once, App Engine automatically scaled up instances to meet the demand.Most people tell us their favorite moment in the game is when the AI guesses your drawing correctly. This is made possible by a machine learning model built by the Handwriting team, part of the Machine Perception team based in the Mountain View and Zurich offices. Hand drawn doodles have a lot in common with handwritten words, so the Handwriting team was able to customize one of their models to recognize the game's drawings. Although our game uses an internal API, the Handwriting team has released a TensorFlow tutorial which you can follow to recreate the model.
The data
From the beginning of the project we thought a collection of anonymous drawings could lead to an interesting research dataset, so we saved each drawing into a Datastore collection once the user was finished drawing it. The team was very careful to respect user privacy so it only saved anonymous metadata, including timestamp, country code, whether or not the drawing was recognized, and which word the drawing corresponded to. The data needed to reconstruct the drawing was saved alongside the metadata in the same Datastore object, in the form of arrays of x,y and time coordinates.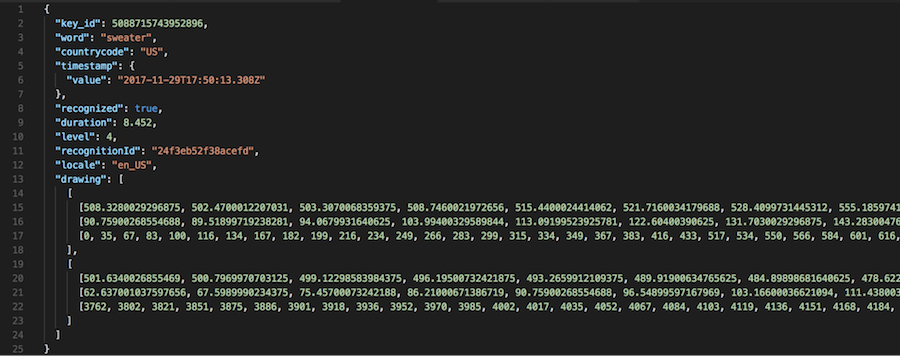
Datastore ended up being an excellent choice. Due to its flexible and scalable nature, the team never had to worry about how many drawings it was saving having an impact on the game's performance. When it came time to start analyzing the data though, we looked to another tool, BigQuery.
The Research
In order to ask questions about the data — from simple things like how many drawings exist for each word, to more complex inquiries into similarities between the way people represent certain concepts — we needed to move the data into a more powerful tool. Every five minutes, a cron job running on App Engine copies data from Datastore into BigQuery. The full dataset of more than one billion vector drawings and metadata weighs in at over 3TB of data, which is no problem for BigQuery. Once we started doing some basic analysis of the dataset, it became clear to us that it could offer some fascinating opportunities for more advanced research.One of the first research projects to come out of the dataset was done by David Ha of the Google Brain team. He developed SketchRNN, a neural network that has learned how to draw words and can do other interesting things like interpolate between drawings. You can try it out yourself as it’s been open sourced via TensorFlow Magenta. David ported the SketchRNN model to Javascript and built several inspiring demos that you can play with live in the browser.

One of the demos from the SketchRNN playground
In order to supply David with the data to train his model, we created a pipeline for processing the data from BigQuery into a simplified form that would be easier for him to consume. The pipeline lived on Google Compute Engine and, at first, consisted of a set of Node.js scripts that could query BigQuery and output data to Google Cloud Storage. With this pipeline, any one of us could find and create interesting subsets of the dataset for the others to explore.

Experimental visualization of 100,000 face drawings clustered via t-SNE and SketchRNN
The Creative Lab reached out to artist Kyle McDonald to help explore and visualize the data, and he brought his C++ expertise to bear on the dataset. At the same time, Jonas was developing python scripts to process and compress the data for use on the web. We all began by writing code on our individual laptops, but quickly realized we should move on to Compute Engine instances. We even shared code via a git repository stored in Cloud Source Repositories. By working in GCP, the three of us were able to collaborate on the data with three entirely different toolsets, all without worrying about cross-platform compatibility or compute resources. In fact, by the end of the project, we were maxing out the CPUs on 64-core Compute Engine instances, running bash, python and node scripts in parallel. These scripts resulted in a lot of data, which was no problem to store and access in Cloud Storage buckets.
64 CPUs at 100% utilization on one of our Google Compute Engine instances, via htop
After our initial explorations, we realized that we needed to get this dataset in the hands of researchers everywhere. Since we were already using Cloud Storage to share data with each other, it was easy to share that same data with everyone. So we wrote a few more scripts to create a variety of formats for different audiences.
We hope this post gave you a little insight into how Quick, Draw! came to be. Interested in experimenting with the dataset? What are you waiting for — try it out for yourself!



