Building scalable web prototypes using the Google Cloud Platform stack
Jason Mayes
Google Web Engineer
As a web engineer at Google, I've been creating scaled systems for internal teams and customers for the past five years. Often these include a web front and back-end component. I would like to share with you a story about creating a bespoke machine learning (ML) system using the Google Cloud Platform stack — and hopefully inspire you to build some really cool web apps of your own.
The story starts with my curiosity for computer vision. I've been fascinated with this area for a long time. Some of you may have even seen my public posts from my personal experiments, where I strive to find the most simple solution to achieve a desired result. I'm a big fan of simplicity, especially as the complexity of my projects has increased over the years. A good friend once said to me, “Simplicity is a complex art,” and after ten years in the industry, I can say that this is most certainly true.
My background is as a web engineer and computer scientist, getting my start back in 2004 on popular stacks of the day like LAMP. Then, in 2011 I joined Google and was introduced to the Google Cloud stack, namely Google App Engine. I found that having a system that dealt with scaling and distribution was a massive time saver, and have been hooked on App Engine ever since.
But things have come a long way since 2011. Recently, I was involved in a project to create a web-based machine learning system using TensorFlow. Let’s look at some of the newer Google Cloud technologies that I used to create it.
Problem: how to guarantee job execution for both long running and shorter time critical tasks
Earlier in the year I was learning how to use TensorFlow — an open source software library for machine intelligence developed by Google (which is well worth checking out by the way). Once I figured out how to get TensorFlow working on Google Compute Engine, I soon realized this thing was not going to scale on its own — several components needed to be split out into their own servers to distribute the load.
Initial design and problem
In my application, retraining parts of a deep neural network was taking about 30 minutes per job on average. Given the potential for long running jobs, I wanted to provide status updates in real-time to the user to keep them informed of progress.I also needed to analyze images using classifiers that had already been trained, which typically takes less than 100ms per job. I could not have these shorter jobs blocked by the longer running 30-minute ones.
An initial implementation looked something like this:
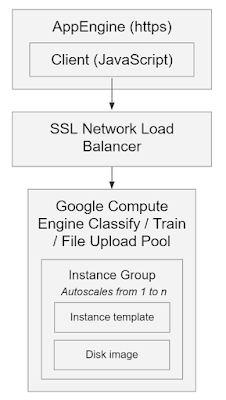
There are a number of problems here:
- The Google Compute Engine server is massively overloaded, handling several types of jobs.
- It was possible to create a Compute Engine auto-scaling pool of up to 10 instances depending on demand, but if 10 long-running training tasks were requested, then there wouldn’t be any instances available for classification or file upload tasks.
- Due to budget constraints for the project, I couldn’t fire up more than 10 instances at a time.
Database options
In addition to having to support many different kinds of workloads, this application required being able to store persistent data. There are a number of databases that support this, the most obvious of which is Google Cloud SQL. However, I had a number of issues with this approach:
- Time investment. Using Cloud SQL would have meant writing all that DB code to integrate with a SQL database myself, and I needed to provide a working prototype ASAP.
- Security. Cloud SQL integration would have required the Google Compute Engine instances to have direct access to the core database, which I did not want to expose.
- Heterogeneous jobs. It’s 2016 and surely there's something that solves this issue already that could work with different job types?
My solution was to use Firebase, Google’s backend as a service offering for creating mobile and web applications. Firebase allowed me to use their existing API to persist data using JSON objects (perfect for my Node.js based server), which allowed the client to listen to changes to DB (perfect for communicating status updates on jobs), and did not require tightly coupled integration with my core Cloud SQL database.
My Google Cloud Platform stack
I ended up splitting the server into three pools that were highly specialized for a specific task: one for classification, one for training, and one for file upload. Here are the cloud technologies I used for each task:
Firebase
I had been eyeing an opportunity to use Firebase on a project for quite some time after speaking with James Tamplin and his team. One key feature of Firebase is that it allows you to create a real-time database in minutes. That’s right, real time, with support for listening for updates to any part of it, just using JavaScript. And yes, you can write a working chat application in less than 5 minutes using Firebase! This would be perfect for real-time job status updates as I could just have the front-end listen for changes to the job in question and refresh the GUI. What’s more, all the websockets and DB fun is handled for you, so I just needed to pass JSON objects around using a super easy-to-use API — Firebase even handles going offline, syncing when connectivity is restored.
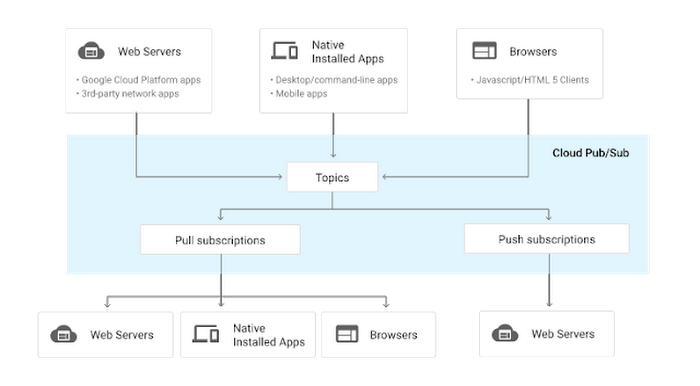
Cloud Pub/Sub
My colleagues Robert Kubis and Mete Atamel introduced me to Google Cloud Pub/Sub, Google’s managed real-time messaging service. Cloud Pub/Sub essentially allows you to send messages to a central topic from which your Compute Engine instances can create a subscription and pull/push from/to asynchronously in a loosely coupled manner. This guarantees that all jobs will eventually run, once capacity becomes available, and it all happens behind the scenes so you don't have to worry about retrying the job yourself. It’s a massive time-saver.
App Engine
This is where I hosted and delivered my front-end web application — all of the HTML, CSS, JavaScript and theme assets are stored here and scaled automatically on-demand. Even better, App Engine is a managed platform with built-in security and auto-scaling as you code against the App Engine APIs in your preferred language (Java, Python, PHP etc). The APIs also provide access to advanced functionality such as Memcache, Cloud SQL and more without having to worry about how to scale them as load increases.
Compute Engine with AutoScaling
Compute Engine is probably what most web devs are familiar with. It’s a server on which you can install your OS of choice and get full root access to that instance. The instances are fully customizable (you can configure how many vCPUs you desire, as well as RAM and storage) and are charged by the minute — for added cost savings when you scale up and down with demand. Clearly, having root access means you can do pretty much anything you could dream of on these machines, and this is where I chose to run my TensorFlow environment. Compute Engine also benefits from autoscaling, increasing and decreasing the number of available Compute Engine instances with demand or according to a custom metric. For my use case, I had an autoscaler ranging from 2 to 10 instances at any given time, depending on average CPU usage.
Cloud Storage
Google Cloud Storage is an inexpensive place in which you can store a large number of files (both in size and numbers) that are replicated to key edge server locations around the globe, closer to the requesting user. This is where I stored the uploaded files used to train the classifiers in my machine learning system until they were needed.
Network Load Balancer
My JavaScript application was making use of a webcam, and I therefore needed to access it over a secure connection (HTTPS). Google’s Network Load Balancer allows you to route traffic to the different Compute Engine clusters that you have defined. In my case, I had a cluster for classifying images, and a cluster for training new classifiers, and so depending on what was being requested, I could route that request to the right backend, all securely, via HTTPS.
Putting it all together
After putting all these components together, my system architecture looked roughly like this:
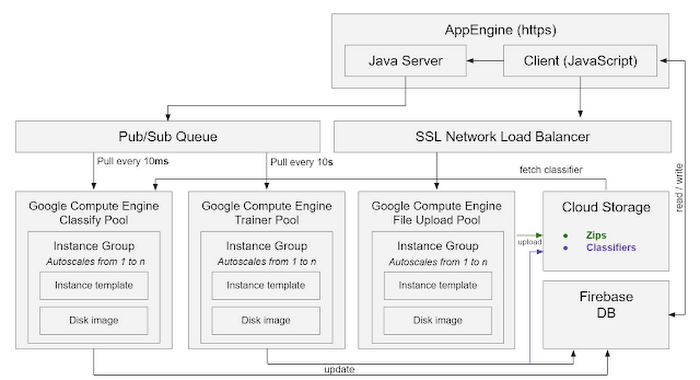
While this worked very well, some parts were redundant. I discovered that the Google Compute Engine Upload Pool code could be re-written to just run on App Engine in Java, pushing directly to Cloud Storage, thus taking out the need for an extra pool of Compute Engine instances. Woohoo!
In addition, now that I was using App Engine, the custom SSL load balancer was also redundant as App Engine itself could simply push new jobs to Pub/Sub internally, and deliver any front-end assets over HTTPS out of the box via appspot.com. Thus, the final architecture should look as follows if deploying on Google’s appspot.com:
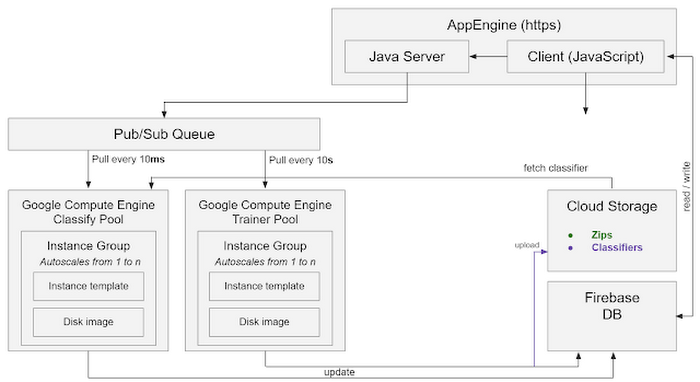
Reducing the complexity of the architecture will make it easier to maintain, and add to cost savings.
Conclusion
By using Pub/Sub and Firebase, I estimate I saved well over a week’s development time, allowing me to jump in and solve the problem at hand in a short timeframe. Even better, the prototype scaled with demand, and ensured that all jobs would eventually be served even when at max capacity for budget.Combining the Google Cloud Platform stack provides the web developer with a great toolkit for prototyping full end-to-end systems at rapid speed while aiding security and scalability for the future. I highly recommend you try them out for yourself.



