Introducing the Hive-BigQuery open-source Connector
Julien Phalip
Solutions Architect, Google Cloud
In our work on the Big Data solutions architecture, BigQuery, and Dataproc teams, we talk to a lot of customers who are interested in migrating all or part of their data warehouse from Apache Hive to BigQuery, but who have hit some speed bumps along the way. To help, we are proud to announce the public GA release of the Hive-BigQuery Connector.
With this open-source connector, you now can let Apache Hive workloads read and write to BigQuery and BigLake tables. The underlying data can be stored either in BigQuery native storage or in open-source data formats on Cloud Storage. Whether you're fully migrating from Apache Hive to BigQuery or you want both systems to coexist and interact together, this new connector covers a wide range of use cases.
What is the Hive-BigQuery Connector?
If you've run Hadoop or Spark workloads on Google Cloud, you should already be familiar with the Cloud Storage Connector and the Apache Spark SQL connector for BigQuery. The former implements the Hadoop Compatible File System (HCFS) API that lets you store and access data files in Cloud Storage, Google Cloud's highly-scalable and highly-available object storage service. The latter implements the Spark SQL Data Source API to allow reading BigQuery tables into Spark's dataframes and writing DataFrames back into BigQuery.
Similarly, the Hive-BigQuery connector implements the Hive StorageHandler API to allow Hive workloads to integrate with BigQuery and BigLake tables. While Hive's execution engine still handles all compute operations such as aggregates and joins, the connector manages all interactions with the data layer in BigQuery, whether the underlying data is stored in BigQuery native storage or in Cloud Storage buckets via a BigLake connection.
The following diagram illustrates how the Hive-BigQuery connector fits in the architecture:
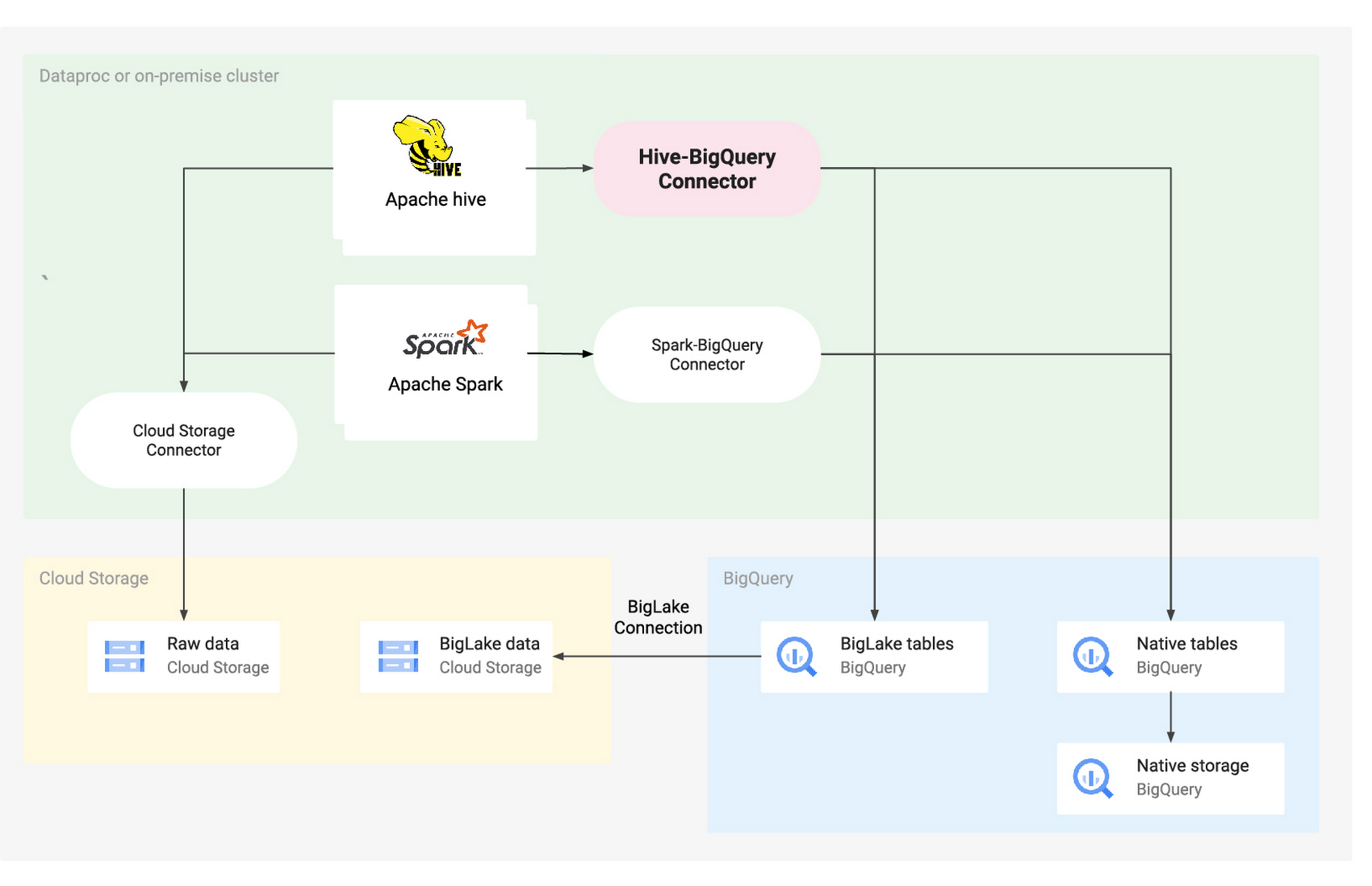
For its part, Apache Hive is one of the most popular open-source data warehouses, and provides an SQL-like interface to query data stored in various databases and file systems that integrate with Apache Hadoop. Over time Hive evolved from using HDFS on-premises as its exclusive data storage layer, to using cloud storage services. And now, thanks to this new connector, Hive integrates with native storage solutions like BigQuery, simplifying migration.
Migrating a data warehouse to the cloud is a complex process, but it can offer significant benefits, including:
Reduced costs: pay only for the resources you use
Increased scalability: easily scale up or down to meet your evolving needs
Improved reliability: leverage redundant, highly-available systems
Enhanced security: encrypt data in transit and at rest and implement granular access control
Expanded capabilities: integrate directly or indirectly with a vast array of Google Cloud native tools and solutions such as:
BigQuery's materialized views and BI Engine for increased performance and efficiency
Pub/Sub to transport data with low-latency
Dataflow to process data at scale in batch or streaming mode
Vertex AI to build, deploy, and scale machine learning models
and many, many more
Google Cloud offers the BigQuery Migration Service as a comprehensive solution to accelerate migration from your Hive data warehouse to BigQuery. It includes free-to-use tools that help you with each phase of migration, including assessment and planning, data transfer, and data validation. Two of those tools, the BigQuery batch SQL translator and interactive SQL translator, enable you to translate your Hive queries to BigQuery's own ANSI-compliant SQL syntax so you can then run those queries natively with BigQuery execution engine.
The new Hive-BigQuery connector offers one additional option: You can keep your original queries in their HiveQL dialect, continue to run those queries with the Hive execution engine on your cluster, but let those queries access data migrated to BigQuery and BigLake tables.
Here’s how the Connector assisted Flipkart's data lake migration to Google Cloud:
“Flipkart places great importance on interoperability with open source technologies as a part of their reliance on and contribution to the open source community. The Hive-BigQuery Connector has played a crucial role in enabling queries on BigQuery data from Hive, as Hive is the primary query engine on our data lake. This integration has provided Flipkart the flexibility to utilize fast query engines like BigQuery without the need for data duplication or silos across various data stores.” - Venkata Ramana Gollamudi, Principal Architect, Flipkart; Apache Committer
Use cases
The Hive-BigQuery Connector can help you in at least the following core use cases:
Ensure continuity of operations during a wholesale migration. Imagine you decide to move your entire Hive data warehouse to BigQuery and you intend to eventually translate all of your existing Hive queries to BigQuery's SQL dialect. You expect that the migration will take a significant amount of time due to the sheer size of your data warehouse and the large number of connected applications. You need to ensure smooth continuity of operations during the migration period. To do this, you can first move your data to BigQuery then let your original Hive queries access that data through the Connector while you gradually translate them to BigQuery's own ANSI-compliant SQL dialect. Once the migration is complete, you can use BigQuery exclusively and retire Hive altogether.
Use BigQuery for some, but not all, data warehouse needs. With the Hive-BigQuery Connector, you can choose to continue using Hive for most workloads and only use BigQuery for certain workloads that you think would benefit from specific BigQuery features like, for example, BI Engine or BigQuery ML. For this use case, you can use the Connector to unify the two environments by letting Hive join its own tables with the tables managed by BigQuery.
Maintain a full open-source software (OSS) stack. Let’s say you want to avoid any potential vendor lock-in and decide to continue using a full OSS stack for your data warehouse. You migrate your data in its original OSS format (e.g. Avro, Parquet or ORC) to Cloud Storage and continue using Hive to execute and process your queries in Hive's own SQL dialect. For this use case, you can use the Connector to augment your OSS stack foundation by leveraging some BigLake and BigQuery features such as metadata caching for query performance, or Data Loss Prevention, column-level access control, and dynamic data masking for security and governance at scale.
Features
The Connector's public preview release already ships with many features, including:
Running queries with MapReduce and Tez execution engines
Creating and deleting BigQuery tables from Hive
Joining BigQuery and BigLake tables with Hive tables
Fast reads from BigQuery tables using the Storage Read API streams and the Apache Arrow format
Two methods for writing data to BigQuery:
Direct writes using the BigQuery Storage Write API in pending mode. Use this method for workload that requires low write latency like near real-time dashboards with short refresh time windows.
Indirect writes by staging temporary Avro files to Cloud Storage then loading those files into the destination table using the Load Job API. This method is cheaper than the direct method, since BigQuery load jobs are free. However, it is slower, so it should only be used for workloads that aren't time critical.
- Accessing BigQuery time-partitioned and clustered tables. Here's an example defining the relation between a Hive table and a table that is natively partitioned and clustered in BigQuery:
Column pruning to avoid retrieving unnecessary columns from the data layer
Predicate pushdowns to pre-filter data rows at the BigQuery storage layer. This can drastically reduce the amount of data traversing the network and therefore improve overall query performance.
Automatic conversion of Hive data types to BigQuery data types
Reading BigQuery views and table snapshots
Getting started
To get started, see the documentation on how to install and configure the connector on your Hive cluster.
We're continuously adding new features and making improvements, and your feedback is welcome! Send us your thoughts and feature requests either by contacting your Google Cloud sales representative or opening a Github issue. We are excited to see all the innovative ways you will use this new Connector.
Thanks to contributors to the design and development of this connector, in no particular order: David Rabinowitz, Yi Zhang, Dagang Wei, Vinay Londhe, Roderick Yao, Kartik Malik, Guruprasad S, Nikunj Bhartia, Gaurav Khandelwal, Vijay Dulipala, Savitha Sethuram, Palak Mishra, Akanksha Singh, Prathap Reddy.

