Cloud Spanner とは
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
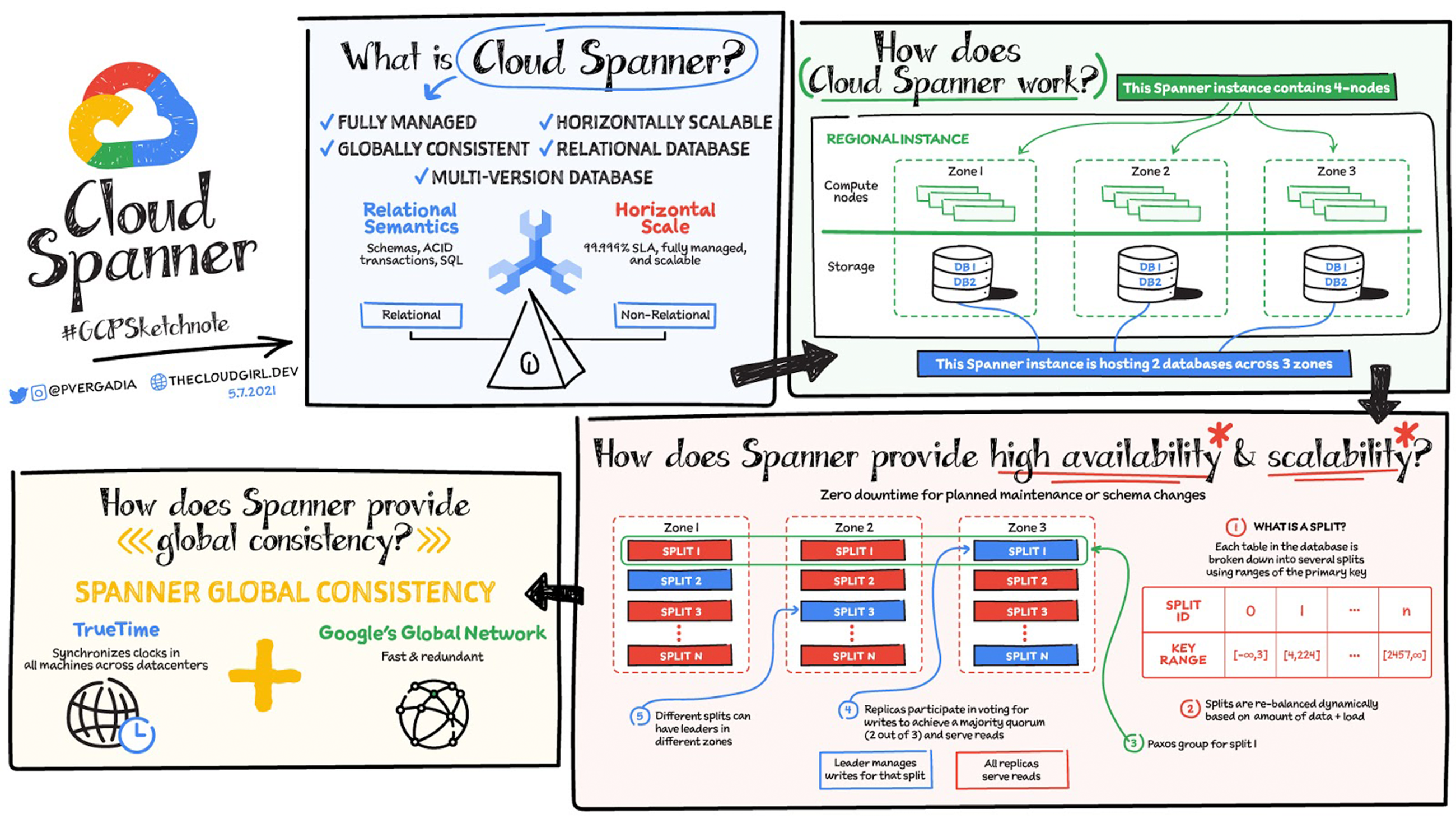
データベースは、組織で実行するほぼすべてのアプリケーションに組み込まれており、優れたアプリケーションには優れたデータベースが必要です。この投稿では、そのような優れたデータベースの 1 つである Cloud Spanner に焦点を当てます。
Cloud Spanner は、エンタープライズ クラスで唯一、グローバルに分散され、強整合性を備えたデータベース サービスです。リレーショナル データベースの構造と非リレーショナル データベースの水平スケーラビリティを兼ね備え、クラウドに特化した設計となっています。スケーラビリティは通常、非リレーショナル データベースや NoSQL データベースと関連して語られるものですが、Cloud Spanner はスケーラビリティをトランザクション、SQL クエリ、リレーショナル構造と組み合わせている点でユニークなデータベースといえます。
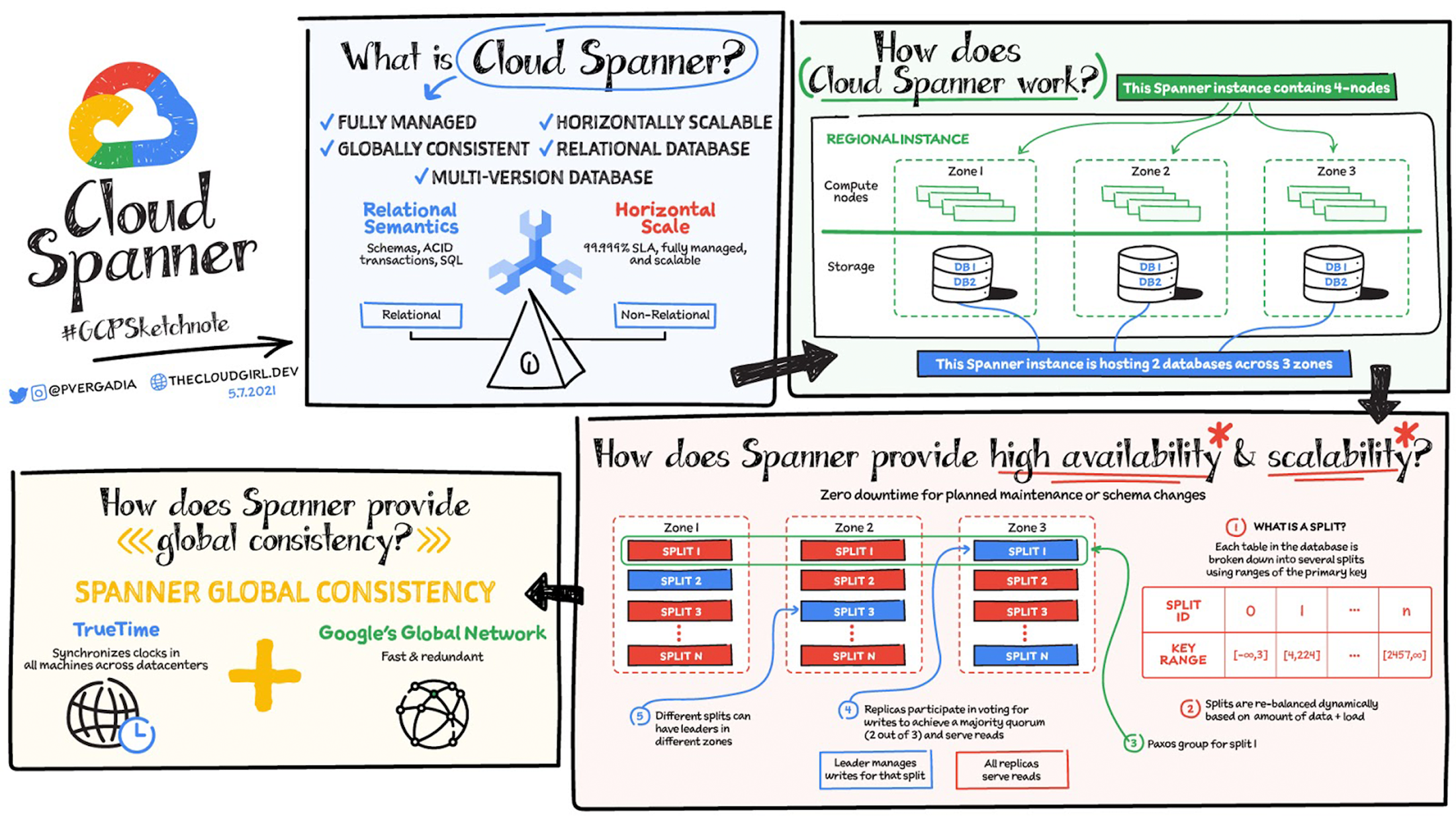
Spanner の仕組み
この画像は、2 つのデータベースをホストしている 4 ノードの単一リージョン Cloud Spanner インスタンスを示しています。ノードとは、Spanner におけるコンピューティングの単位のことです。ノードサーバーは、読み取り、書き込み、commit のトランザクション リクエストを処理しますが、データは保存しません。各ノードはリージョン内の 3 つのゾーンに複製されています。データベース ストレージも 3 つのゾーンに複製されています。ゾーン内のノードは、ゾーン内のストレージに対する読み取りと書き込みを担当します。データは、基盤となる Google の Colossus 分散複製ファイル システムに保存されます。データが個々のノードにリンクされていないため、負荷の再分散において大きな利点となります。ノードやゾーンに障害が発生した場合でもデータベースを使い続けることができ、残りのノードによってサービスが提供されます。可用性を維持するために手動で操作する必要はありません。
Spanner が高可用性とスケーラビリティを実現する仕組み
データベース内の各テーブルは主キーによって保存され、ソートされます。テーブルは主キーの範囲によって分割され、分割されたものはスプリットと呼ばれます。各スプリットは異なる Spanner ノードによって完全に独立して管理されます。テーブルのスプリット数はデータ量によって異なります。空のテーブルの場合、スプリットは 1 つだけになります。スプリットは、データ量と負荷に応じて動的にリバランスされます(動的リシャーディング)。ここで、テーブルとノードが 3 つのゾーンに複製されていたことを思い出してください。これはどのような仕組みになっているのでしょうか。
すべてが 3 つのゾーンに複製されていますが、これがスプリット管理にも当てはまります。スプリットのレプリカは、複数のゾーンにまたがるグループ(Paxos)に関連付けられます。Paxos コンセンサス プロトコルを使用して、ゾーンの 1 つがリーダーに決まります。リーダーはそのスプリットの書き込みトランザクションを管理し、それ以外のレプリカは読み取りに使用されます。リーダーに障害が発生した場合、コンセンサス プロトコルによって新しいリーダーが選出されます。別のスプリット グループについては、別のゾーンがリーダーになるため、リーダーのロールはすべての Cloud Spanner コンピューティング ノードで分配されます。ノードは、あるスプリットのリーダーになると同時に、他のスプリットのレプリカになることもあります。Cloud Spanner は、このスプリット、リーダー、レプリカの分配メカニズムを使用して、高可用性とスケーラビリティの両方を実現します。
読み取りと書き込みの仕組み
Cloud Spanner には、以下の 2 種類の読み取りがあります。
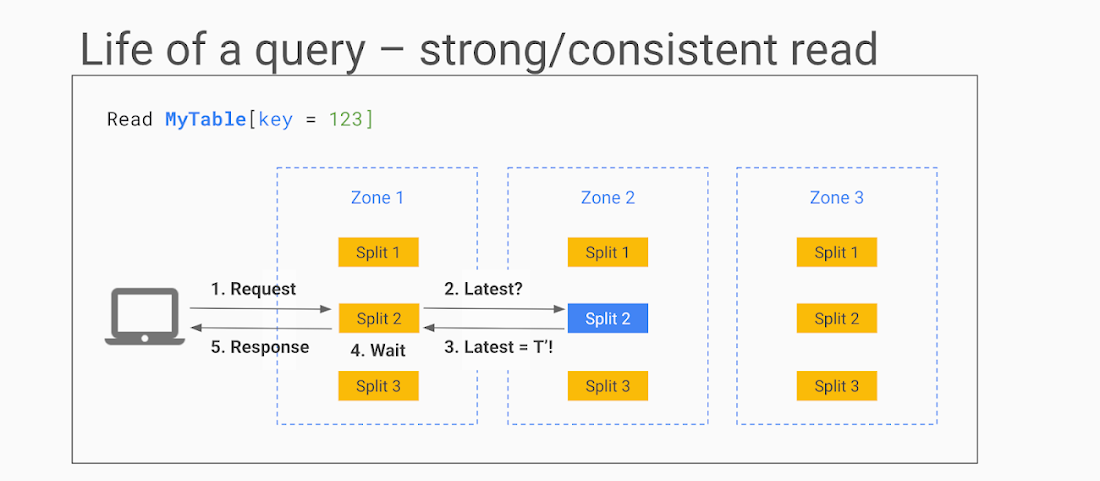
強力な読み取り: 絶対最新値を読み取る必要がある場合に使用します。仕組みは次のとおりです。
Cloud Spanner API がスプリットを識別し、そのスプリットに使用する Paxos グループを検索して、リクエストをレプリカ(通常はクライアントと同じゾーンにあります)の 1 つにルーティングします。この例では、リクエストはゾーン 1 の読み取り専用レプリカに送信されます。
レプリカはリーダーに読み取りリクエストを送信し、この行の最新トランザクションの TrueTime タイムスタンプを尋ねます。
リーダーが応答し、レプリカは応答を自身の状態と比較します。
行が最新の場合、レプリカは結果を返すことができます。最新でない場合は、リーダーから更新が送信されるのを待つ必要があります。
応答がクライアントに返送されます。
読み取りリクエストの転送中にちょうど行が更新されたときなど、場合によっては、レプリカの状態が十分に最新であるため、最新のトランザクションについてリーダーに問い合わせる必要がないこともあります。
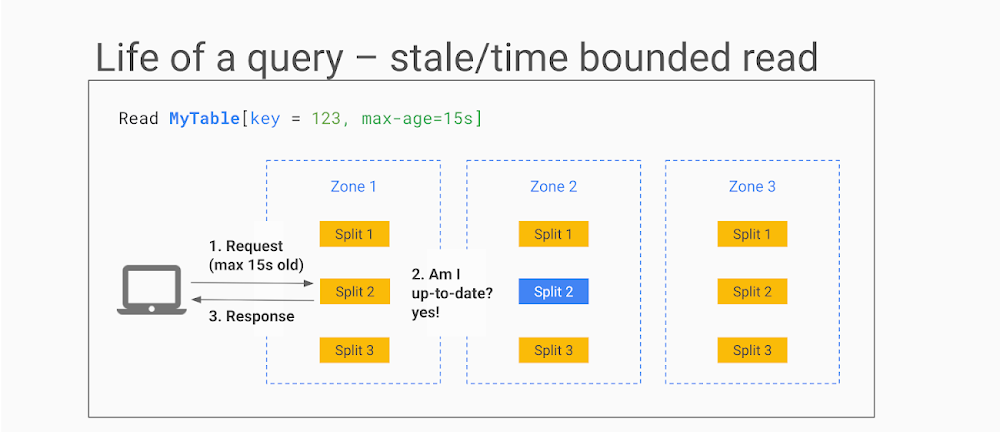
ステイル読み取り: 最新値の取得よりも低レイテンシの読み取りが重要な場合に使用されるため、ある程度のデータの古さは許容されます。ステイル読み取りでは、クライアントがリクエストするのは絶対最新値ではなく、最新のデータ(例: n 秒前のデータ)です。ステイルネス係数が 15 秒以上の場合、レプリカの内部ではデータが十分に最新な状態であるため、ほとんどの場合、レプリカはリーダーにクエリを実行しなくてもデータを返すことができます。このような読み取りリクエストでは、行のロックを毎回行う必要がありません。どのノードでも読み取りに応答できるということが、Cloud Spanner を非常に高速でスケーラブルなものにしています。
Spanner がグローバルな一貫性を実現している仕組み
TrueTime は Spanner を機能させるために不可欠です。では、TrueTime とはどのようなもので、どのように役立つのでしょうか。
TrueTime は、複数のデータセンターにまたがるすべてのマシンのクロックを同期する手段です。このシステムは GPS と原子時計を組み合わせて使用し、それぞれが他方のエラーモードを修正します。この 2 つのソースを組み合わせることで(もちろん、複数の冗長性を使用します)、すべての Google アプリケーションに正確な時間を提供します。ただし、個々のマシンのクロック ドリフトは依然として発生する可能性があり、30 秒ごとに同期しても、サーバーのクロックと参照クロックの差が 2 ミリ秒程度開いてしまうことがあります。クロック ドリフトは、クロック同期によって修正されるまで、不確実性が増加するのこぎり波のグラフのように見えます。コンピューティングにおいて 2 ミリ秒は非常に長い時間であるため、TrueTime はこの不確実性を時間信号の一部として含めます。
まとめ
スケーラビリティの高いリレーショナル データベースがアプリケーションで必要な場合は、ぜひ Spanner をご検討ください。Spanner の詳細については、ドキュメントをご覧ください。

#GCPSketchnote の詳細については、GitHub リポジトリをフォローしてください。同様のクラウド コンテンツについては、Twitter で @pvergadia をフォローしてください。thecloudgirl.dev もぜひご覧ください。
-Google デベロッパー アドボケイト Priyanka Vergadia



