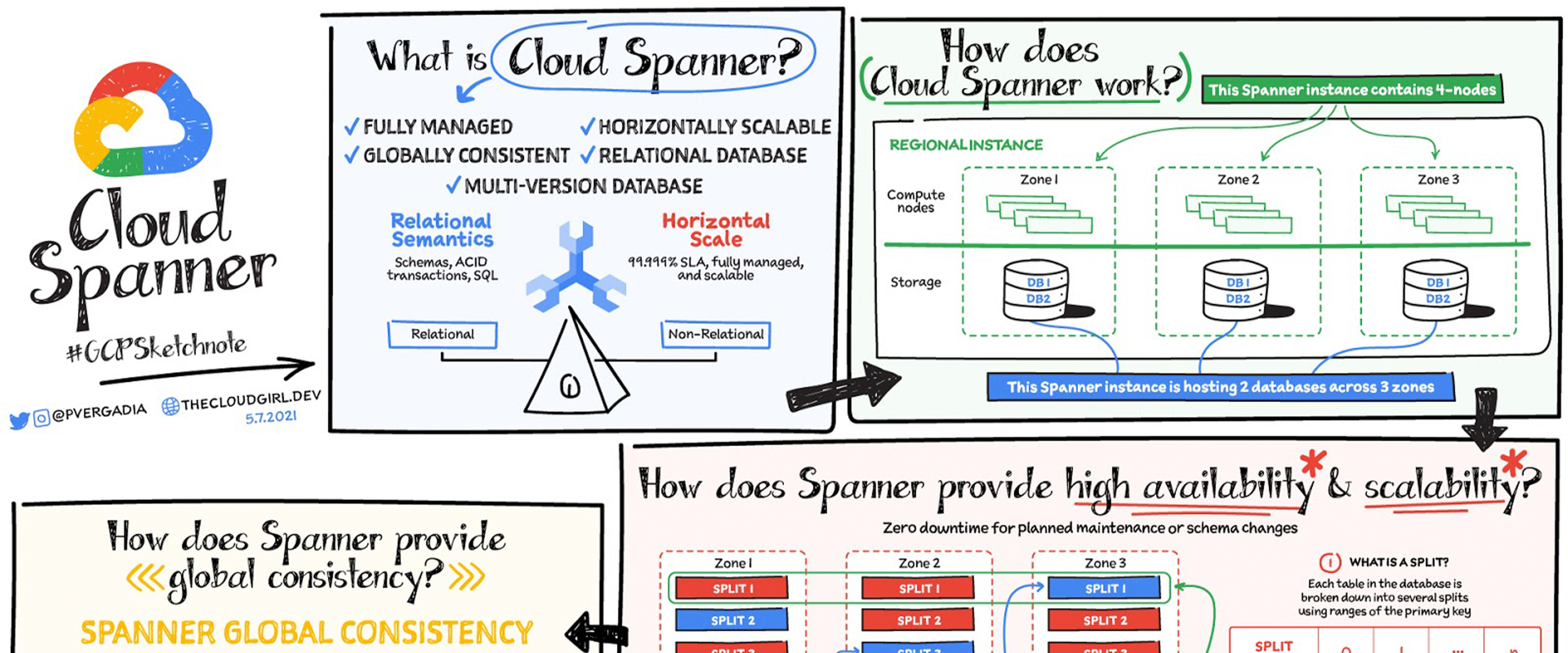
What is Cloud Spanner?
Priyanka Vergadia
Staff Developer Advocate, Google Cloud
Databases are part of virtually every application you run in your organization and great apps need great databases. This post is focused on one such great database—Cloud Spanner.
Cloud Spanner is the only enterprise-grade, globally-distributed, and strongly-consistent database service built for the cloud, specifically to combine the benefits of relational database structure with non-relational horizontal scale. It is a unique database that combines transactions, SQL queries, and relational structure with the scalability that you typically associate with non-relational or NoSQL databases.
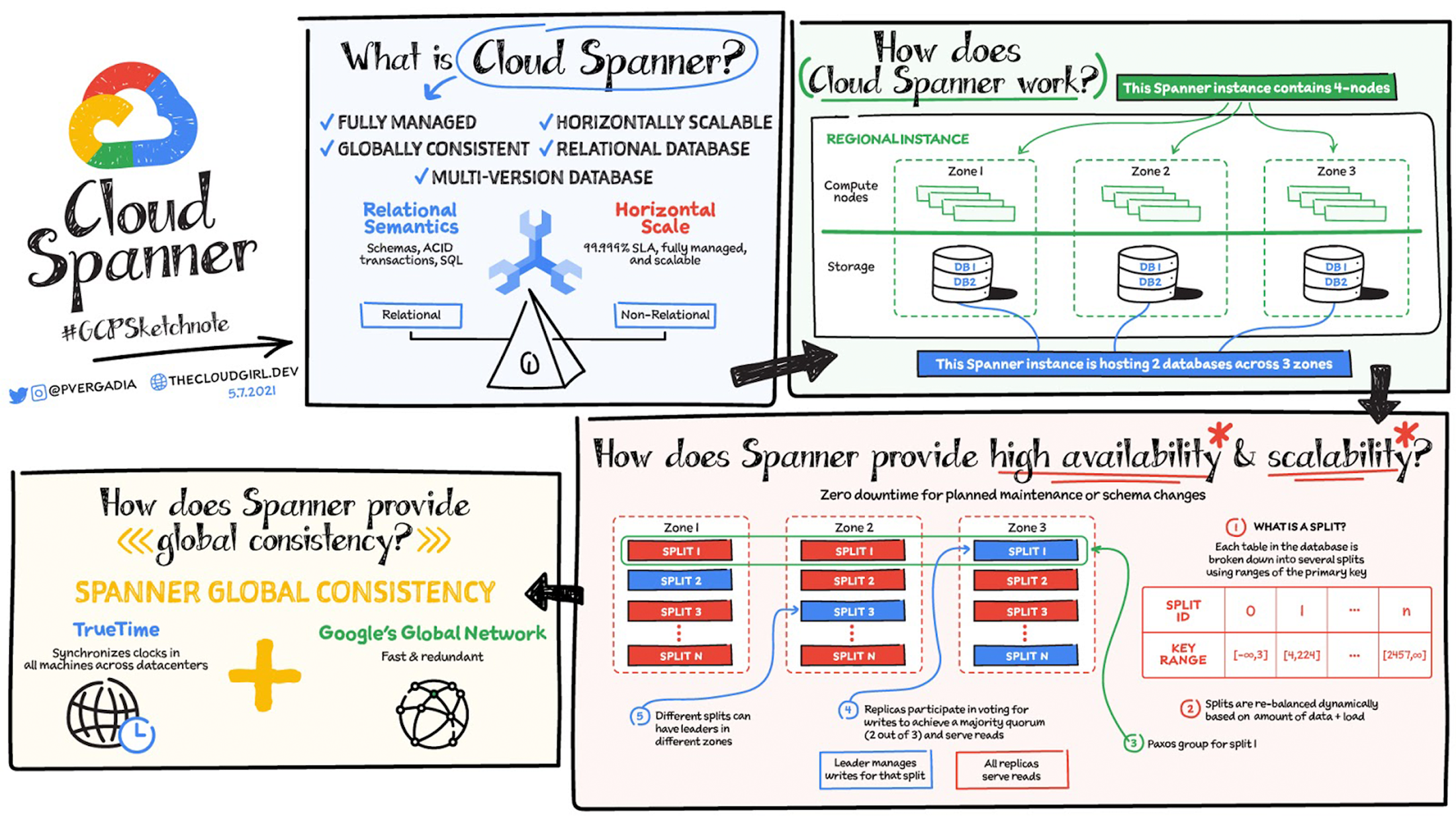
How does Spanner work?
In the image you see a four-node regional Cloud Spanner instance hosting two databases. A node is a measure of compute in Spanner. Node servers serve the read and write/commit transaction requests, but they don’t store the data. Each node is replicated across three zones in the region. The database storage is also replicated across the three zones. Nodes in a zone are responsible for reading and writing to the storage in their zone. The data is stored in Google’s underlying Colossus distributed replicated file system. This provides huge advantages when it comes to redistributing load, as the data is not linked to individual nodes. If a node or a zone fails, the database remains available, being served by the remaining nodes. No manual intervention is needed to maintain availability.
How does Spanner provide high availability and scalability?
Each table in the database is stored sorted by primary key. Tables are divided by ranges of the primary key and these divisions are known as splits. Each split is managed completely independently by different Spanner nodes. The number of splits for a table varies according to the amount of data: empty tables have only a single split. The splits are rebalanced dynamically depending on the amount of data and the load (dynamic resharding). But remember that the table and nodes are replicated across three zones, how does that work?
Everything is replicated across the three zones - the same goes for split management. Split replicas are associated with a group (Paxos) that spans zones. Using Paxos consensus protocols, one of the zones is determined to be a leader. The leader is responsible for managing write transactions for that split, while the other replicas can be used for reads. If a leader fails, the consensus is redetermined and a new leader may be chosen. For different splits, different zones can become leaders, thus distributing the leadership roles among all the Cloud Spanner compute nodes. Nodes will likely be both leaders for some splits and replicas for others. Using this distributed mechanism of splits, leaders, and replicas, Cloud Spanner achieves both high availability and scalability.
How do reads and writes work?
There are two types of reads in Cloud Spanner:
Strong reads - used when the absolute latest value needs to be read. Here is how it works:
- The Cloud Spanner API identifies the split, looks up the Paxos group to use for the split and routes the request to one of the replicas (usually in the same zone as the client) In this example, the request is sent to the read-only replica in zone 1.
- The replica requests from the leader if it is OK to read and it asks for the TrueTime timestamp of the latest transaction on this row
- The leader responds, and the replica compares the response with its own state.
- If the row is up-to-date it can return the result. Otherwise it needs to wait for the leader to send updates.
- The response is sent back to the client.
In some cases, for example, when the row has just been updated while the read request is in transit, the state of the replica is sufficiently up-to-date that it does not even need to ask the leader for the latest transaction.
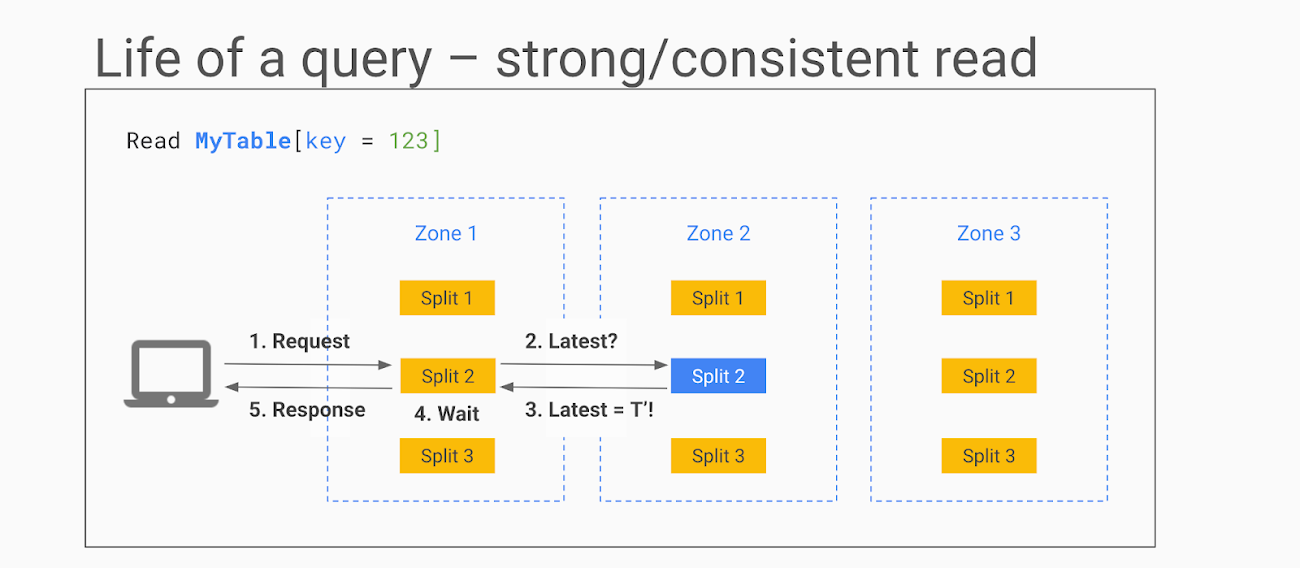
Stale reads are used when low read latency is more important than getting the latest values, so some data staleness is tolerated. In a stale read, the client does not request the absolute latest version, just the data that is most recent (e.g. up to n seconds old). If the staleness factor is at least 15 seconds, the replica in most cases can simply return the data without even querying the leader as its internal state will show that the data is sufficiently up-to-date. You can see that in each of these read requests, no row locking was required - the ability for any node to respond to reads is what makes Cloud Spanner so fast and scalable.

How does Spanner provide global consistency?
TrueTime is essential to make Spanner work as well as it does...so, what is it, and how does it help?
TrueTime is a way to synchronize clocks in all machines across multiple datacenters. The system uses a combination of GPS and atomic clocks, each correcting for the failure modes of the other. Combining the two sources (using multiple redundancy, of course) gives an accurate source of time for all Google applications. But, clock drift on each individual machine can still occur, and even with a sync every 30 seconds, the difference between the server's clock and reference clock can be as much as 2ms. The drift will look like a sawtooth graph with the uncertainty increasing until corrected by a clock sync. Since 2ms is quite a long duration (in computing terms, at least), TrueTime includes this uncertainty as part of the time signal.
Conclusion
If your application requires a highly scalable relational database, then check out Spanner. For a more in-depth look into Spanner, explore the documentation.
For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev.



