Vertex AI Experiments でテストを追跡、比較、管理する
Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
テストの管理はデータ サイエンス チームにとって主な課題のひとつです。
特定の問題に対して機能する最適なモデリング手法を見つけるには、仮説の検証と試行錯誤の両方が必要です。ドキュメントとスプレッドシートを使った開発と成果の追跡は、信頼性がなく、共有が容易ではありません。その結果、ML 開発プロセスに大きな影響がおよびます。
トラッキング サービスを使わない場合、手動でパラメータと指標をコピーして貼り付けることになります。テストの数が増えると、モデルビルダーはモデルのトレーニングに使われたデータとモデルの構成を再現できなくなります。その結果、モデルの予測動作とパフォーマンスの変化を検証できません。
このような情報の不足は、さまざまなユースケースに伴って異なるチームがあるときに重大な影響をおよぼします。
規模が大きくなると、パイプラインを使って ML テストのステップをオーケストレートする必要があります。しかし、一か所で成果を管理および検証しないまま、データ サイエンス チームはどうやってテストの迅速なイテレーションと準備の改善を同時に保証できるでしょうか?
結論としては、モデルを会社とそのビジネスにとっての資産に変えることがさらに難しくなります。
こうした課題を解決するため、Vertex AI のマネージド テスト トラッキング サービスである Vertex AI Experiments が一般提供となりました。
Vertex AI Experiments は追跡するだけでなく、シームレスなテストをサポートするために設計されています。このサービスによってパラメータを追跡し、モデルとパイプラインのテストにおけるパフォーマンス指標を可視化および比較できます。同時に Vertex AI Experiments はテストのリネージを提供します。これは、最適なモデル構成にたどり着くのに必要な各ステップを表すために使用できます。
このブログでは、Vertex AI Experiments の仕組みについて掘り下げ、以下のことを可能にする機能を紹介します。
Vertex AI SDK を使って、ローカルでトレーニングしたモデルのパラメータと指標を追跡する
チーム内の他のユーザーが再利用できるテスト アーティファクトにおけるテストのリネージ(データの前処理や特徴量エンジニアリングなど)を作成する
複数のパイプライン実行のトレーニング構成を記録する
詳しく学ぶ前に、Vertex AI Experiment とは何か明確にしましょう。
実行、テストおよびメタデータ サービス
Vertex AI Experiments には、2 つの主なコンセプトがあります。実行とテストです。
実行は、データ サイエンティストがある ML の課題を解決するときに使用した特定のトレーニング構成と関連します。各実行で次のことを記録できます。
実行の Key-Value 入力であるパラメータ。
実行の Key-Value 出力であるサマリーと時系列指標(各エポックの最後に記録される指標)。
入力データや変換されたデータセット、トレーニング済みモデルなどのアーティファクト。
複数回の実行が考えられるため、それらの実行をひとつのテストにまとめることができます。テストとは、実務者が特定のデータ サイエンス課題を解決するために行ったことをすべて格納する最上位のコンテナです。
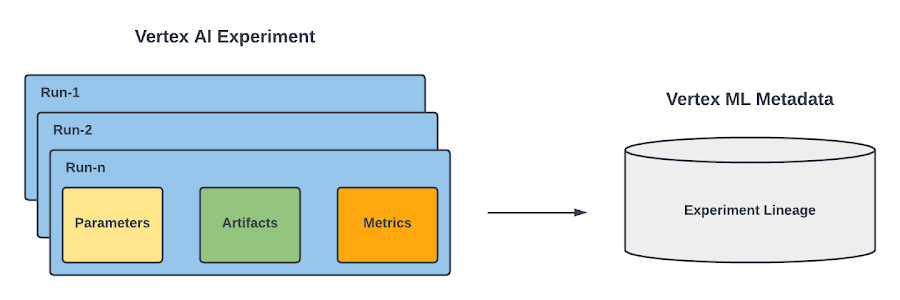
実行とテストの両方で Vertex ML Metadata が活用されています。Vertex ML Metadata とは、Google の TensorFlow Extended チームが開発したオープンソースの ML Metadata(MLMD)ライブラリに基づいているマネージド ML メタデータ ストアです。これによって、ML の間に生成されたメタデータとアーティファクトを記録、分析、デバッグ、監査できます。Vertex AI Experiments では、ML テストの ML リネージを可視化できます。
ここまでで Vertex AI Experiment とは何かについて学びました。続いて、その機能を活用することで大規模なテストを追跡し、管理する際に起こりうる課題を解決する方法を見てみましょう。
ローカルでトレーニングおよび評価されたモデルを比較する
データ サイエンティストの方は、ローカルでモデルのトレーニングを始めるのではないでしょうか。最適なモデリング手法を見つけるために、異なる構成を試したいはずです。
例えば TensorFlow モデルを構築している場合は、tf.data.Dataset の「buffer_size」や「batch_size」などのデータ パラメータと、レイヤ名やオプティマイザーの「learning_rate」、最適化したい「metrics」などのモデル パラメータを追跡したいでしょう。
さまざまな構成を試したら、さらなる分析のための指標を生成することで、作成したモデルを評価する必要があります。
Vertex AI Experiments を活用すれば、Google Cloud コンソールの Vertex AI セクションと Vertex AI Python SDK の両方を使うことで、テストを簡単に作成し、テスト実行に関連する両方のパラメータと指標、アーティファクトをロギングできます。
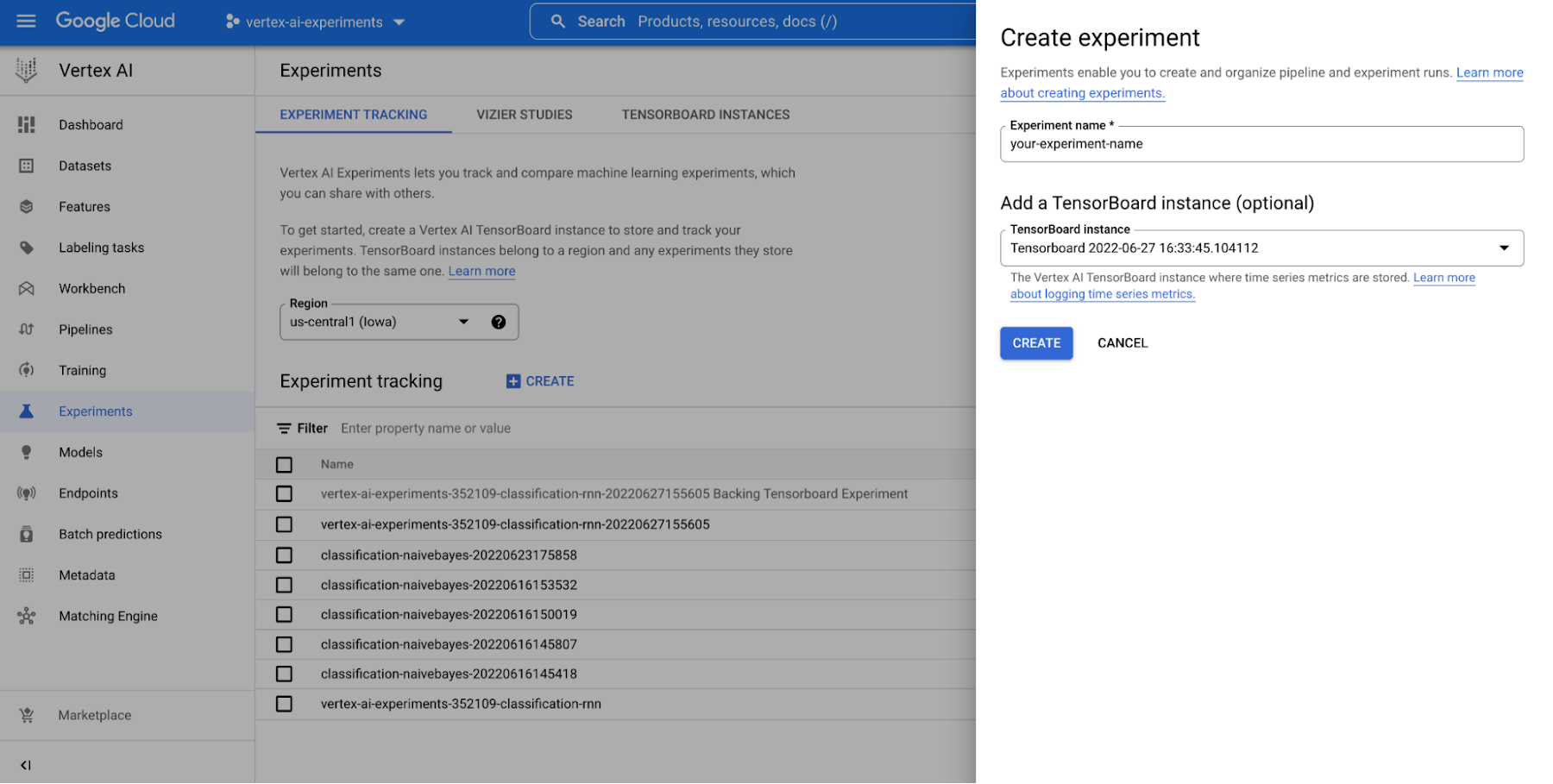
また、SDK は便利な初期化メソッドを提供しており、これによってモデルの時系列指標をロギングするために Vertex AI TensorBoard を使った TensorBoard インスタンスを作成できます。テストを始め、モデル パラメータをロギングし、エポックごとおよびトレーニング セッションの最後の両方で評価指標を追跡する方法を以下に示します。
Google Cloud コンソールの Vertex AI セクションを確認するか、ノートブックに結果を取得することでテストの結果を分析できます。この動画は結果の分析がどのようなものかを示しています。
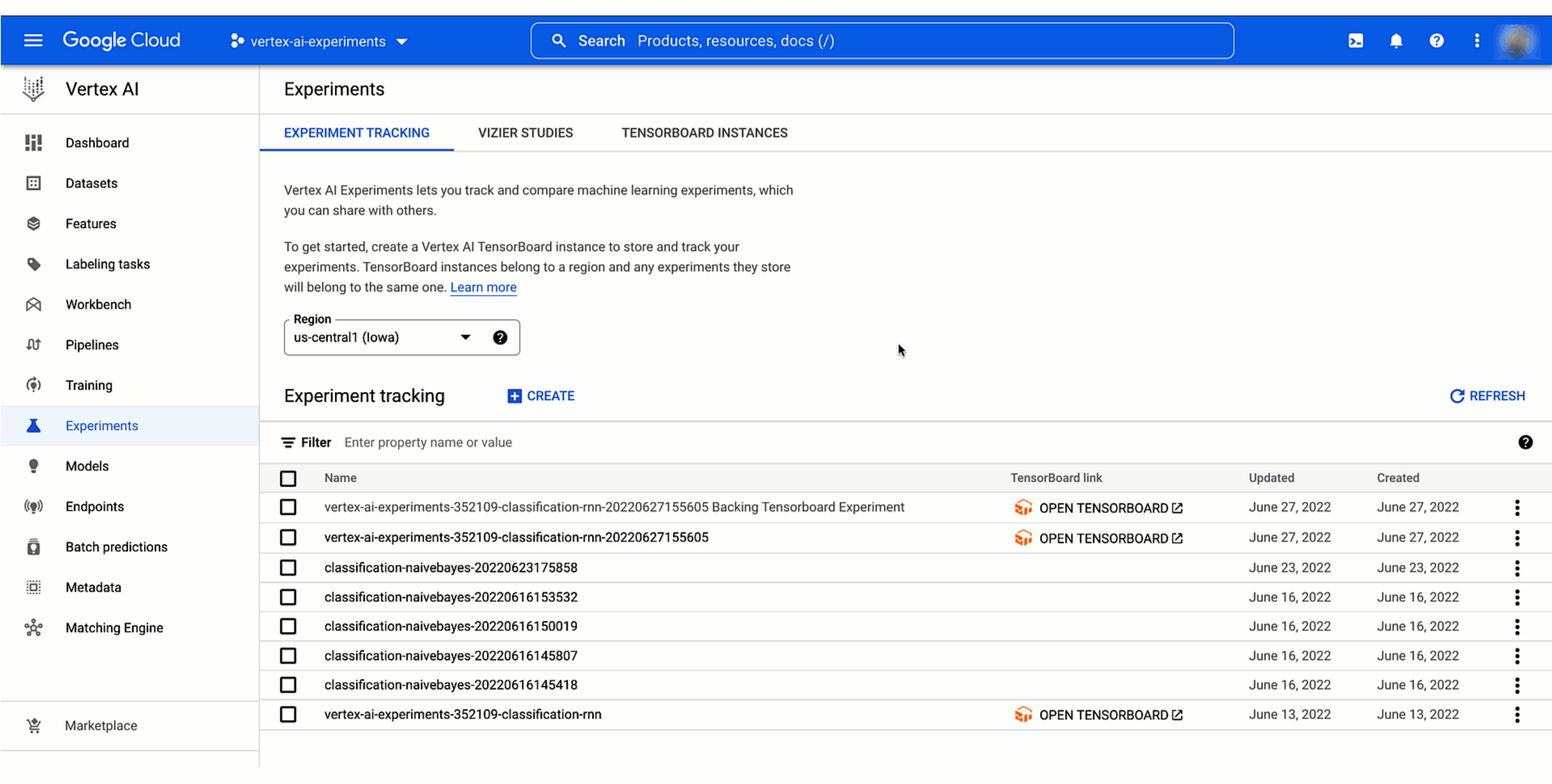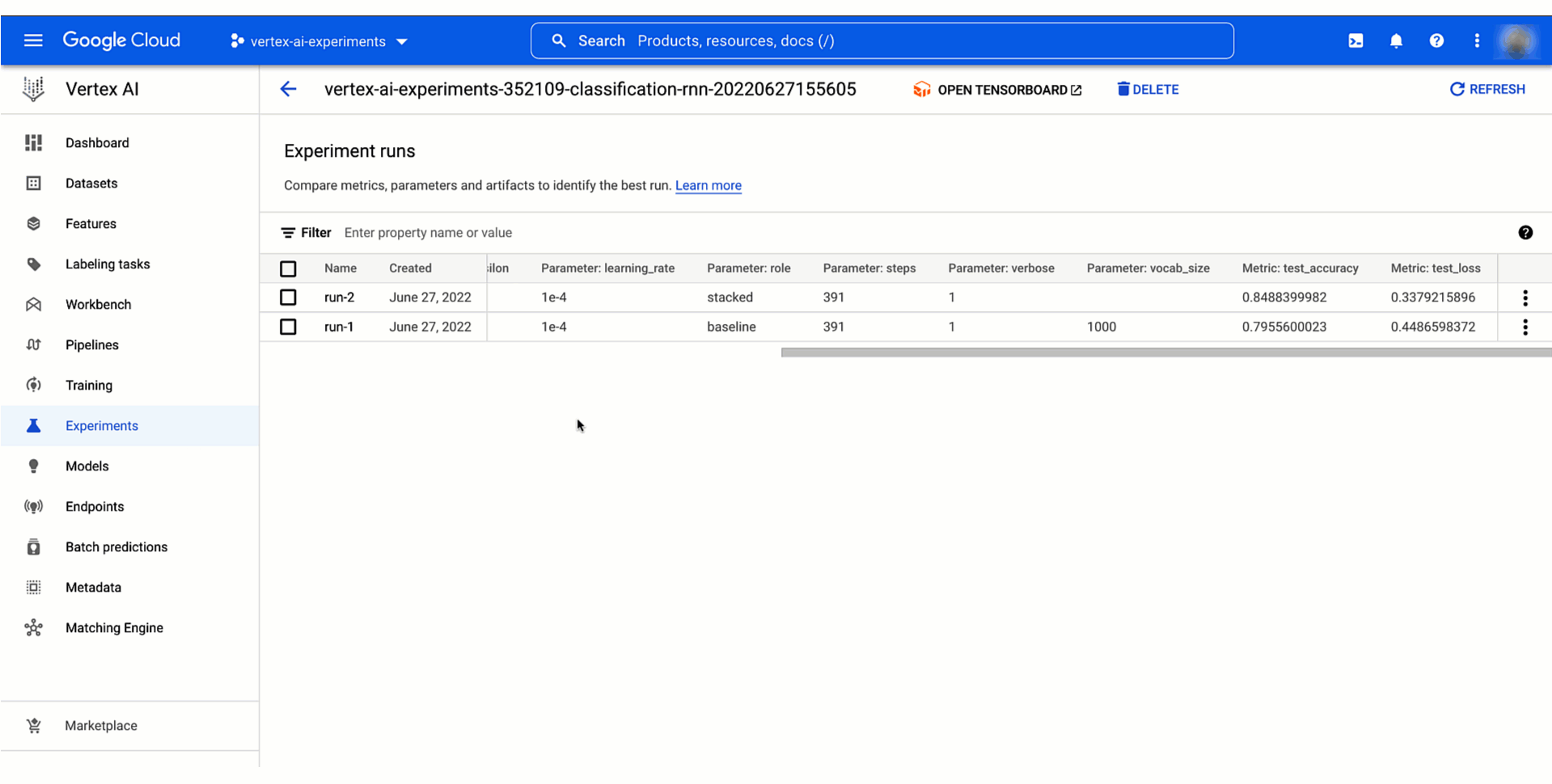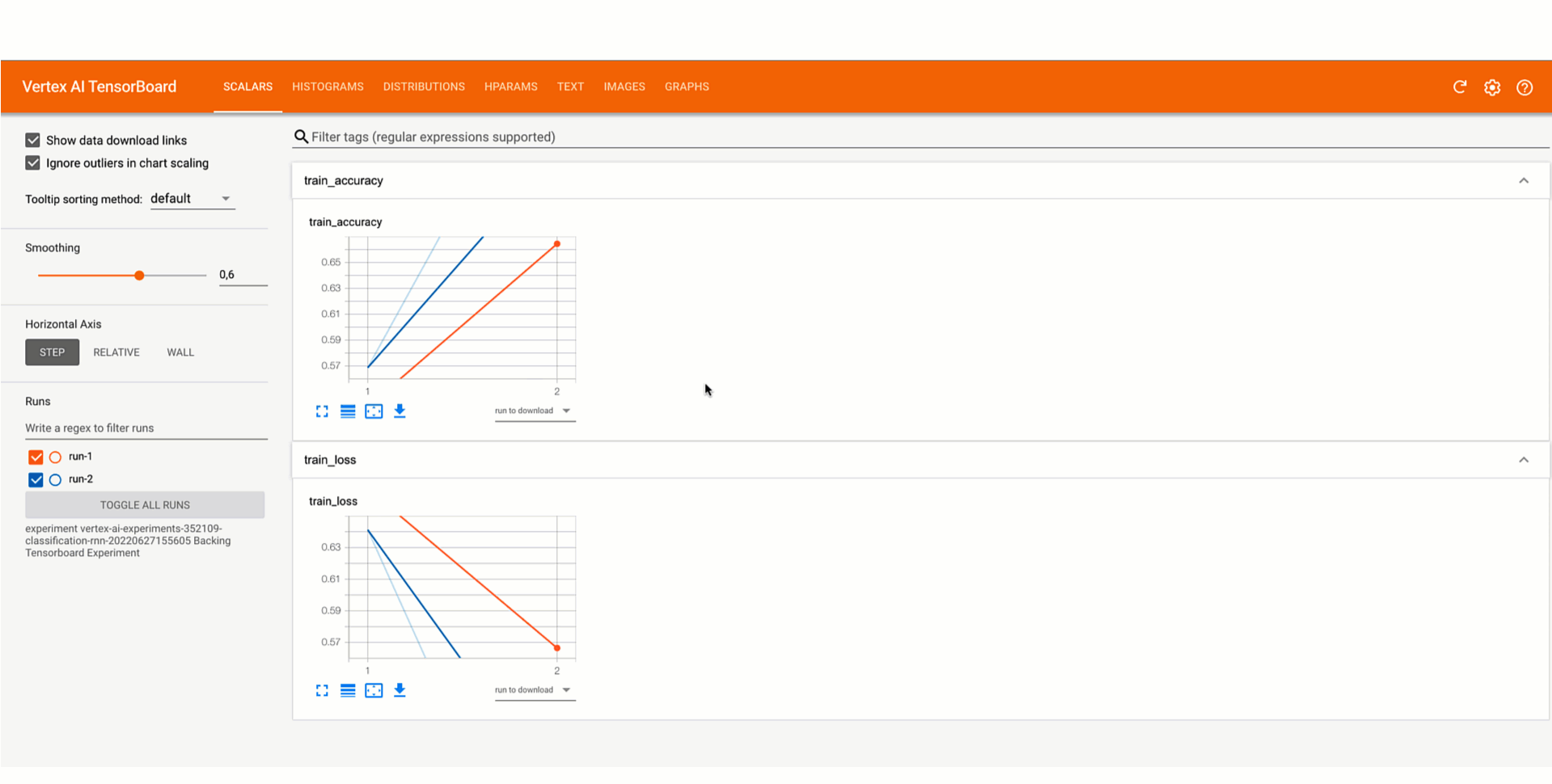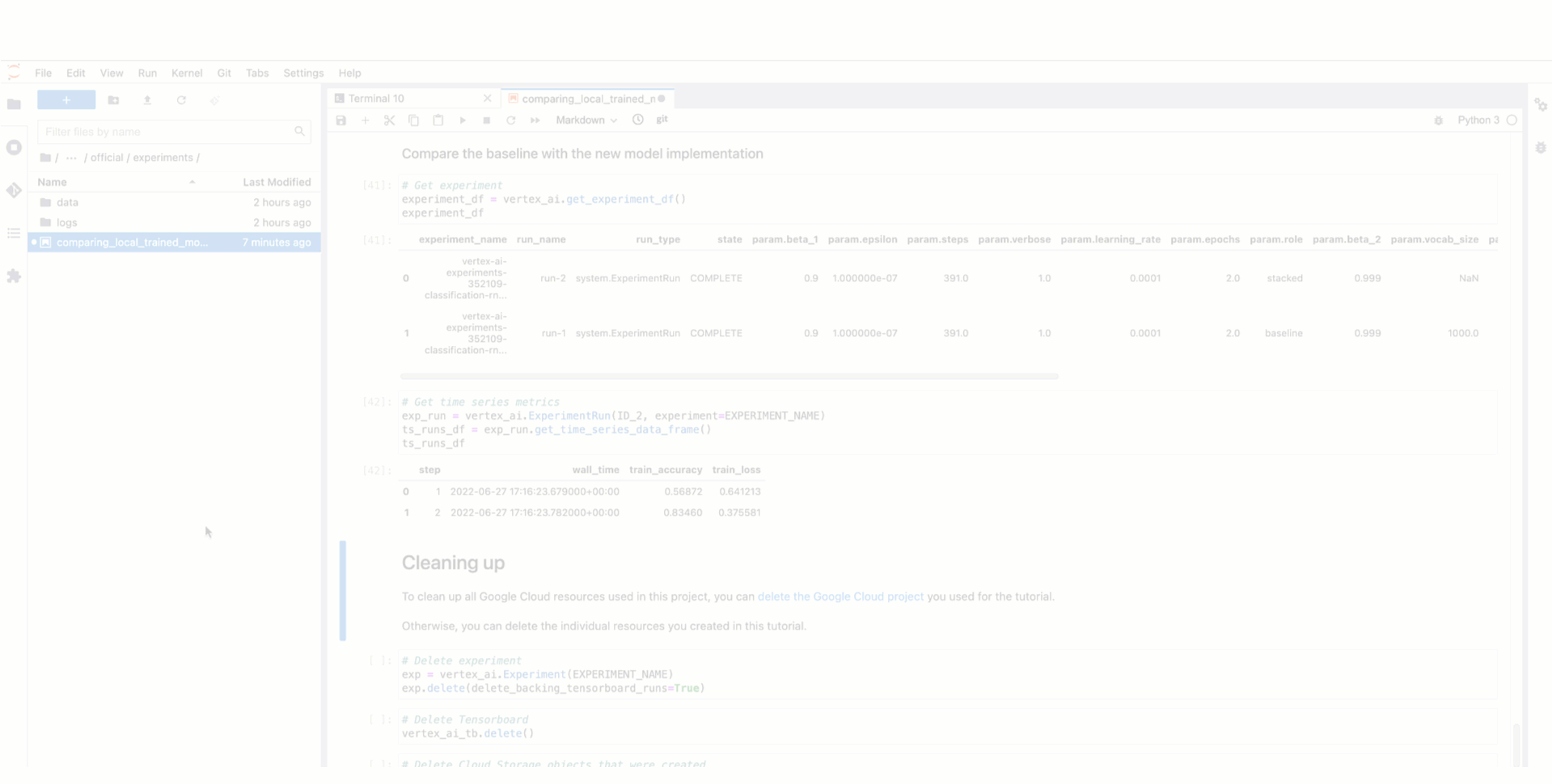
モデル トレーニング テストのリネージを追跡する
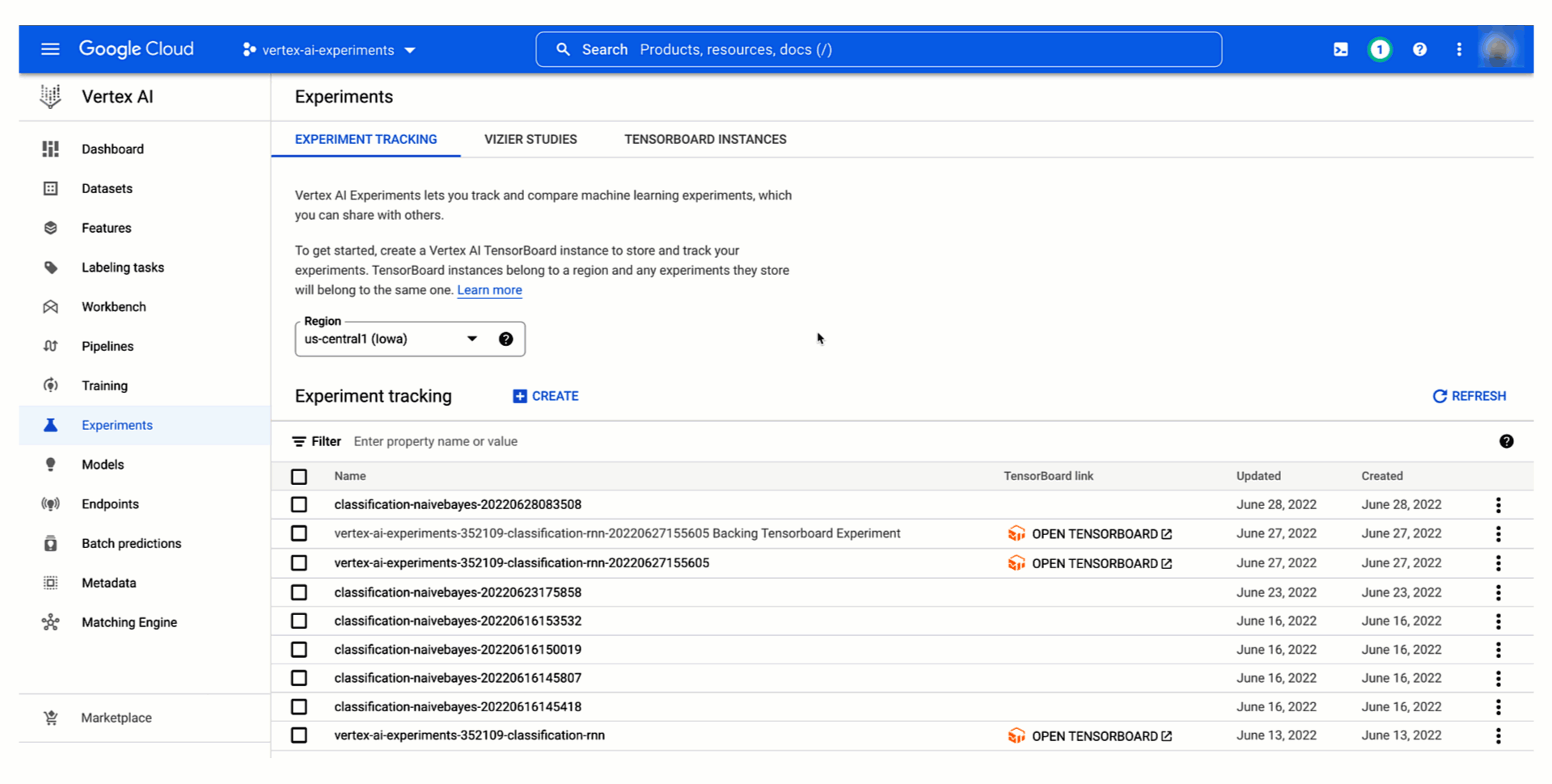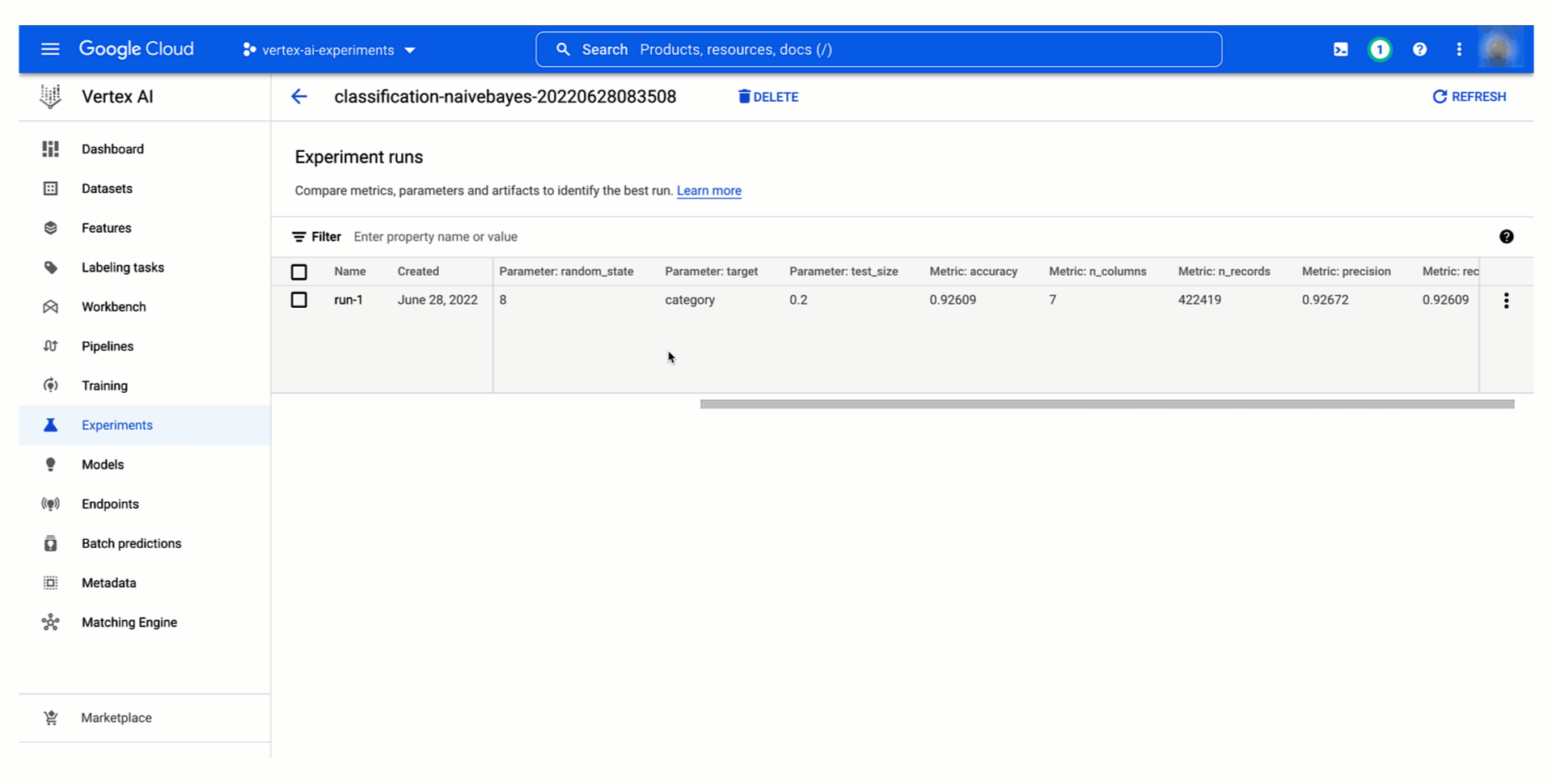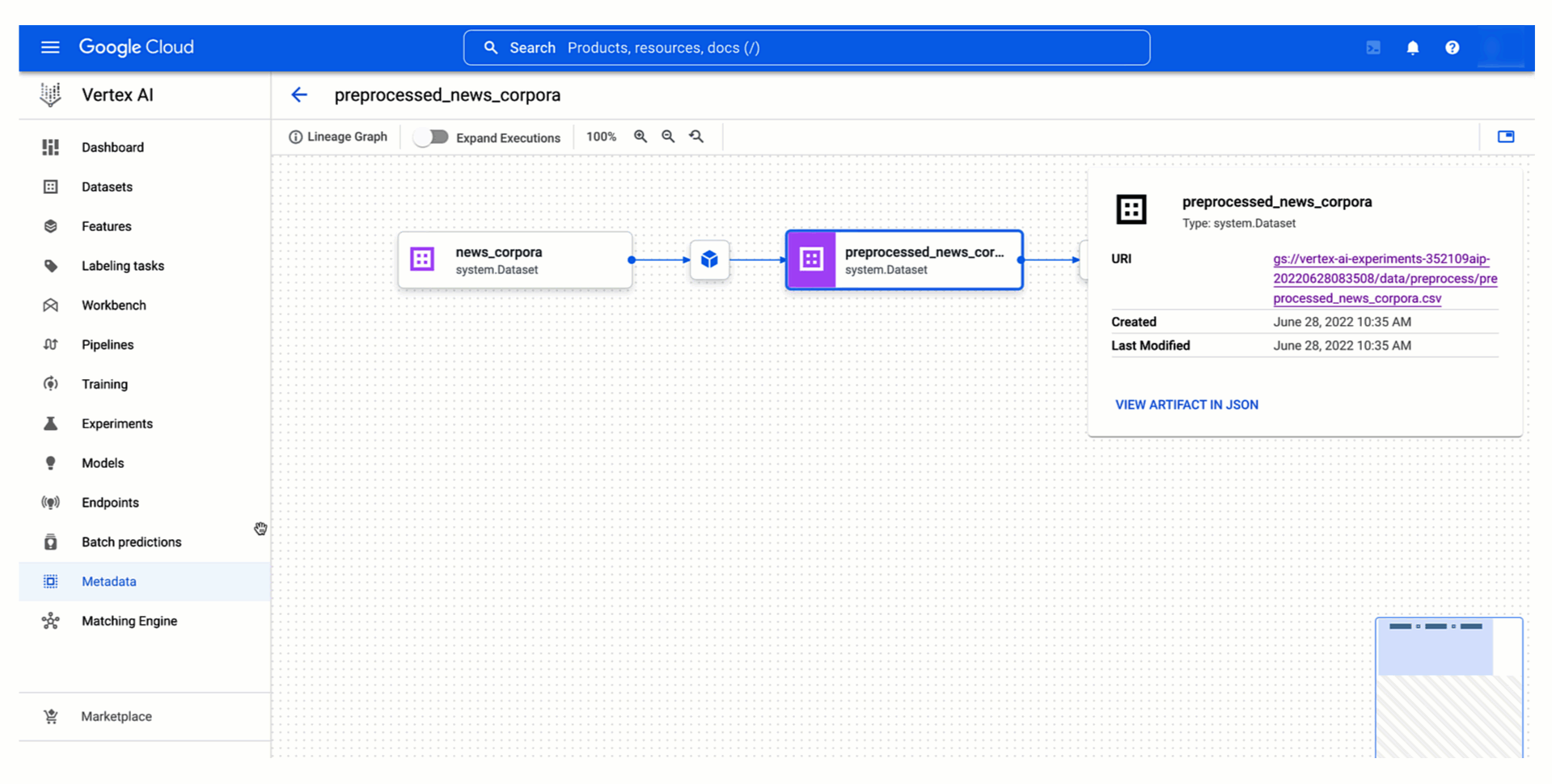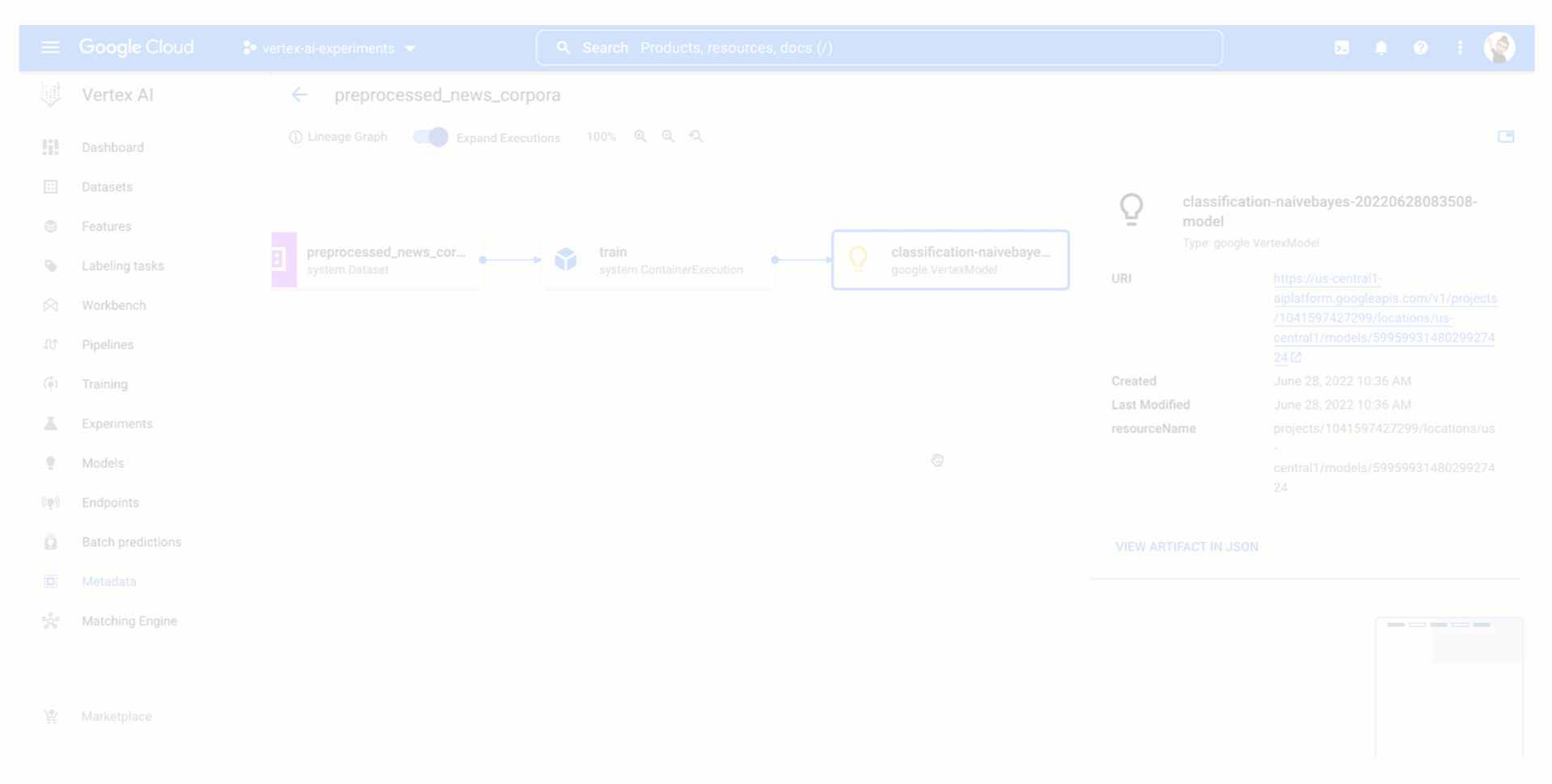
モデル トレーニングはテスト内のひとつのステップにすぎません。また、チーム内の他のユーザーが書いた可能性があるデータの前処理も求められます。このような理由から、簡単に前処理のステップを統合し、得られたデータセットを記録することで、さまざまなテスト実行に再利用する方法が必要です。
Vertex ML Metadata との統合を活用すれば、テストのコンテキストで Vertex ML Metadata を実行することで、Vertex AI Experiments によってデータの前処理をテストのリネージの一部として追跡できます。Vertex AI Experiments の実行を使うことで、前処理のコードを統合する方法を紹介します。
実行がインスタンス化されたら、データの前処理ステップの記録を始めます。データセットを入力アーティファクトとして割り当て、前処理のコードでそのデータセットを使用し、前処理されたデータセットを実行の出力アーティファクトとして渡すことができます。その前処理ステップとデータセットは自動的にテストのリネージの一部として記録されます。記録されたものは、同じテストに関連する別のトレーニング実行の入力アーティファクトとしていつでも使用できます。これが、作成したモデルをトレーニングが正常に終了した後にモデル アーティファクトとしてアップロードする場合のトレーニング実行の方法です。
以下の動画は、Vertex AI Experiments のビューからテスト実行のデータとモデル アーティファクトにアクセスする方法および、Vertex ML Metadata における生成されたテストのリネージの見え方を示しています。
モデル トレーニング パイプラインの実行を比較する
パイプライン実行のテストを自動化することは、モデルを頻繁に再トレーニングする必要があるときに重要です。パイプラインでのテストを形式化するのが早いほど、簡単かつ迅速に本番環境に移行できます。下の図は迅速なテストプロセスの概要です。
データ サイエンティストの方は、モデルをトレーニングするために多くのパラメータを持つパイプラインで、テストを形式化します。パイプラインを用意したら、大規模なパイプラインの実行を追跡および評価することで、どのパラメータ構成が最適なモデルを生成しているかを特定する方法が必要になります。
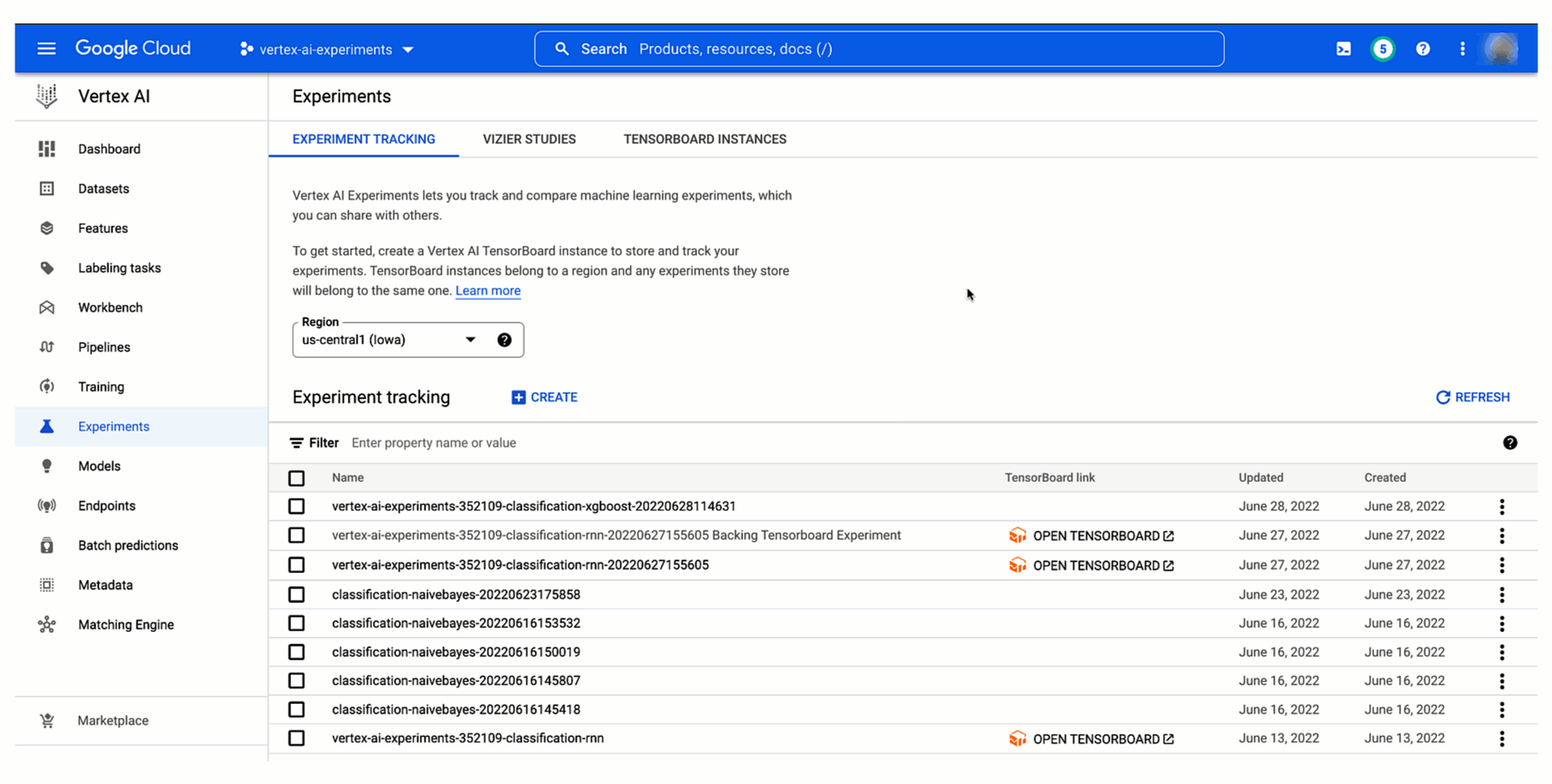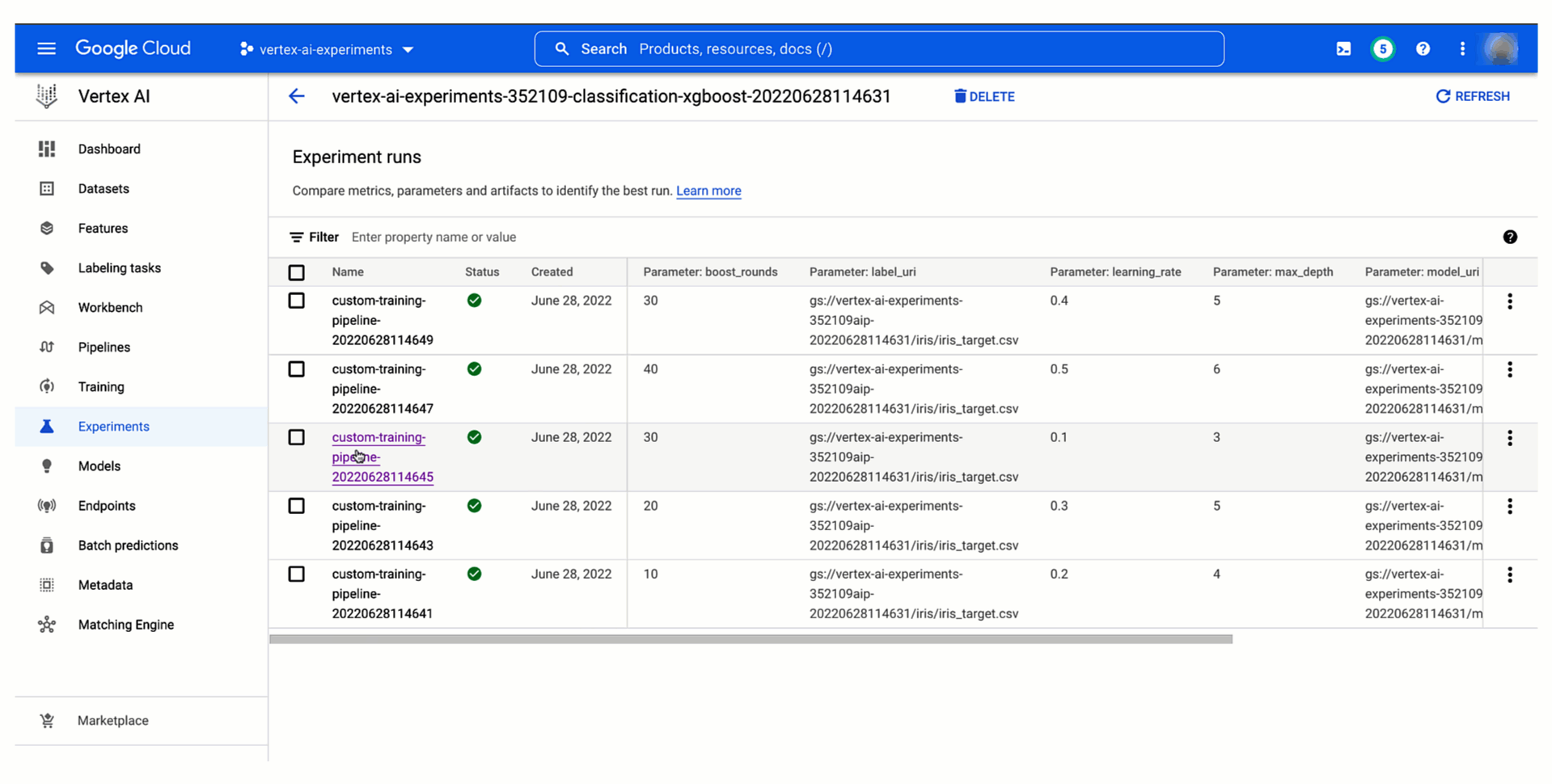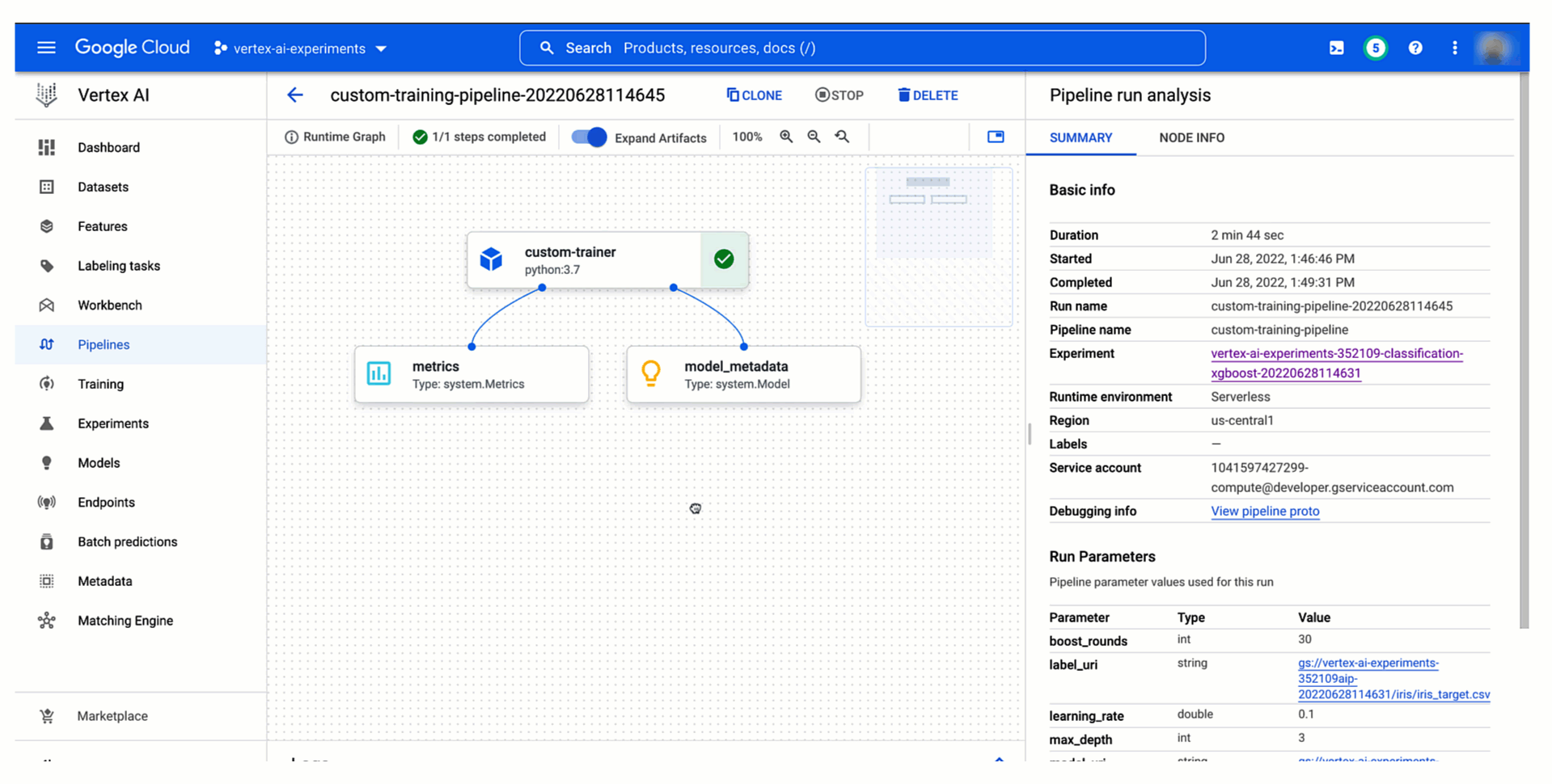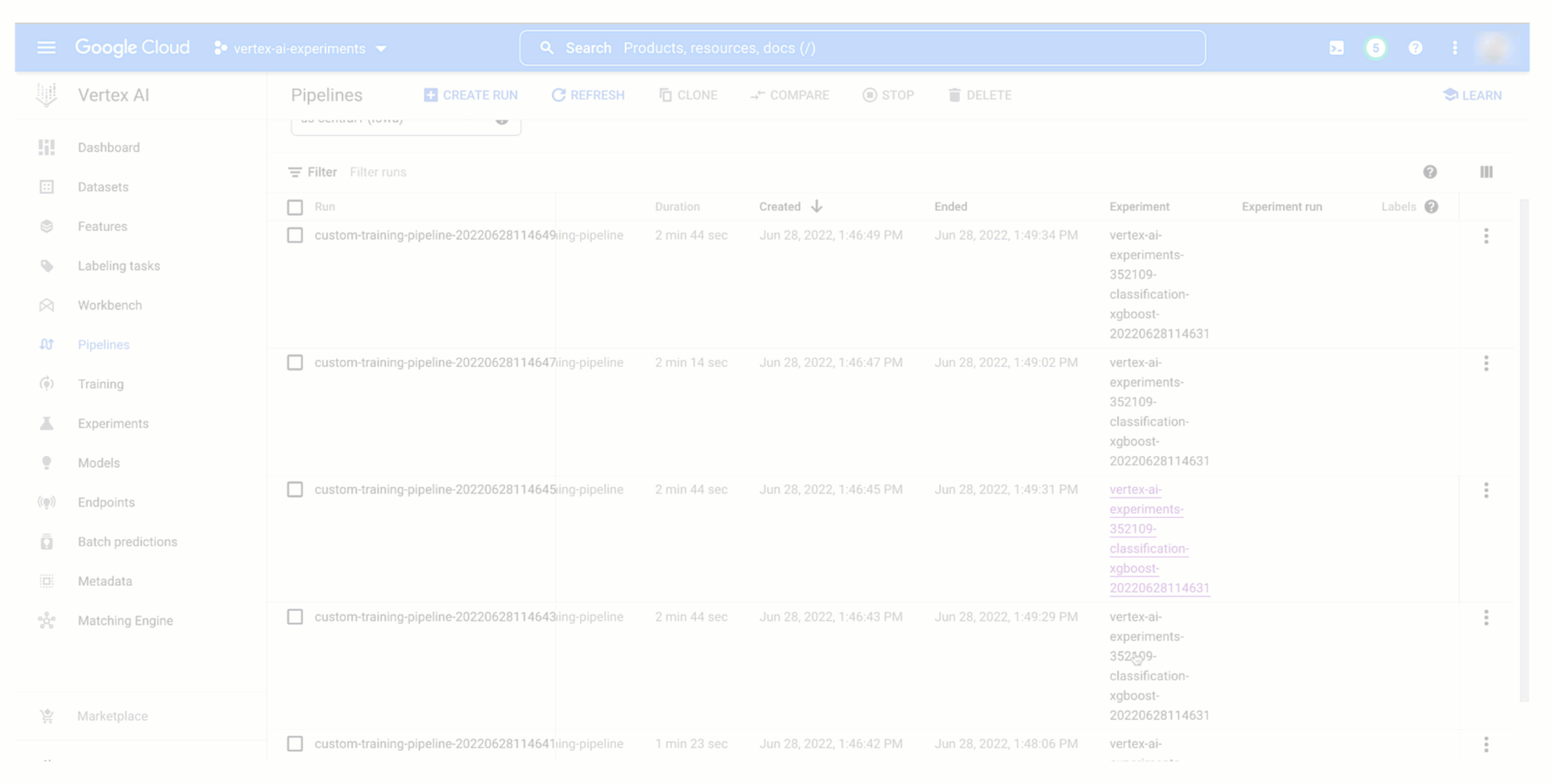
Vertex AI Pipelines との統合を活用することで、Vertex AI Experiments でパイプライン パラメータとアーティファクトおよび指標を追跡し、パイプラインの実行を比較できます。
必要なのは、Vertex AI でパイプライン ジョブを送信する前にテスト名を宣言することだけです。
以下のように、Vertex AI Experiments でパイプラインのテスト実行とそのパラメータおよび指標を確認し、過去の実行と比較することで、最適なトレーニング構成を本番環境にプロモートできます。また、テスト実行との関係を確認し、Vertex AI Pipelines でのパイプラインの実行をモニタリングできます。各実行は Vertex ML Metadata のリソースにマッピングされるため、Vertex AI で自動的に作成されるリネージを見せながら、他のユーザーに選択を説明できます。
まとめ
Vertex AI Experiments を使えば、パラメータを追跡し、モデルのパフォーマンス指標を可視化および比較できるだけではなく、Vertex AI における ML パイプラインとメタデータ リネージの統合機能のおかげで、すぐに本番環境へ移行できるマネージド テストを構築できます。
それでは実際に試してみましょう。再度、ブログ投稿をお届けする予定ですが、それまでの間、公式の GitHub リポジトリにあるノートブックと以下のリソースを読み、次の一歩を踏み出してください。そして、忘れないでください...楽しむ気持ちを持ち続けることを。
詳細を確認する
ドキュメント
サンプル
- カスタマー エンジニア Ivan Nardini
- Google Cloud プロダクト マネージャー May Hu



