BigQuery のユーザー フレンドリーな SQL とともに一歩を踏み出そう

Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
春が来ました。時は進んでいます。日本では、桜まつりで新しい季節の始まりを祝います。インドでは、色粉を掛け合うホーリー祭が収穫の季節を告げます。今までの方法を考え直し、新しいやり方を試してみましょう。
今月は、アナリストやデータ エンジニア達に新しい一歩をもたらす、BigQuery の最新 SQL 機能をご紹介します。今までのやり方はいったん脇に置いて、BigQuery SQL を使ってあらゆるデータを保存し、分析するという新しい方法を考えてみましょう。
より大きなデータ
より高精度で柔軟な機能により、増えつづけるデータを BigQuery で管理できます。
BIGNUMERIC データ型(一般提供版)
今や自動運転車から、グローバルな株式為替取引システム、高速の 5G ネットワークに至るまで、インテリジェントなデバイスやシステムが、現代生活のほぼすべての側面において牽引する時代となっています。こういったシステムは、大量の高精度データに依存し、リアルタイムの分析を行っています。この分析をサポートするために、BigQuery は 76 桁の精度と 38 桁のスケールをサポートする BIGNUMERIC データ型の一般提供版を発表しました。NUMERIC と同様に、この新しいデータ型はクラスタリングから BI Engine まで、BigQuery のあらゆる側面で利用可能であり、JDBC / ODBC ドライバやクライアント ライブラリでもサポートされています。
ここでは、e のさまざまな累乗、オイラー数、自然対数の基数に BIGNUMERIC を適用して、追加の精度とスケールを示した例をご紹介します。ドキュメント
余談ですが、2020 年 12 月 5 日の時点で、e を表す最大桁数の世界記録は 10π 兆桁であることをご存じでしたか?
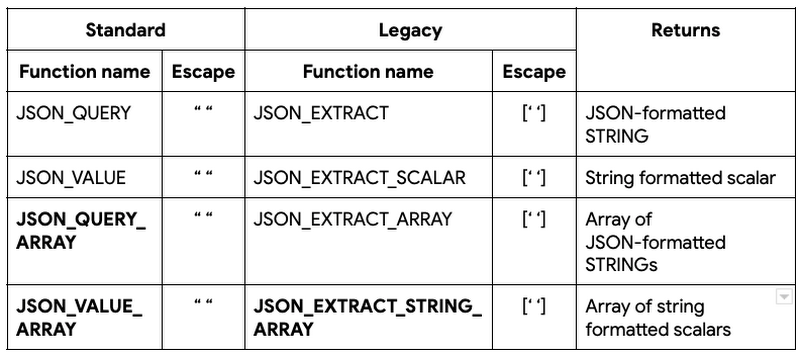
JSON 抽出関数(一般提供版)
お客様が BigQuery で構造化および半構造化されたさまざまなデータを分析する中で、半構造化データの事実上の標準として JavaScript Object Notation(JSON)が登場しました。JSON は、スキーマレスなデータをテーブルに格納する柔軟性を備えており、列にデータタイプとそれに伴う精度を指定する必要がありません。新しい要素が追加されても、スキーマを変更することなく、新しい Key-Value ペアを追加して JSON ドキュメントを拡張できます。
BigQuery は、2016 年に ANSI SQL 規格の一部になる前から、JSON データと、JSON データを照会、変換する JSON 関数をサポートしてきました。JSON 抽出関数は、通常 2 つのパラメータを使用します。JSON ドキュメントを含む JSON フィールドと、抽出する必要のある特定の要素や要素の配列を指す JSONPath です。JSONPath が、ドット(.)、ドル($)、スター(*)などの予約文字を含む要素を参照する場合、それらの文字は JSONPath の式として解釈されるのではなく、文字列として扱われるようにエスケープする必要があります。エスケープをサポートするために、BigQuery は標準とレガシーの 2 種類の JSON 抽出関数をサポートします。標準(ANSI 準拠、推奨)では、予約文字を二重引用符(" ")で囲むことでエスケープしています。レガシー(ANSI 以前)の方法では、角括弧と一重引用符([' '])で囲みます。
ここでは、既存の JSON 抽出機能と新しい(太字で強調された)JSON 抽出機能を簡単にまとめています。
TABLESAMPLE 句(プレビュー版)
BigQuery ではあらゆる種類のデータが集約され、増加しているため、特にアナリストやデータ サイエンティストが大規模なテーブルのデータのアドホック分析を行う場合、お客様にとってクエリのコスト管理は重要な問題となってきます。そこで、大規模なテーブルのデータ全体をクエリするのではなく、テーブルのパーセンテージで指定したデータ サブセットをサンプリングできるクエリの TABLESAMPLE 句をご紹介します。この SQL 句は、テーブルからデータブロックのパーセンテージをランダムに選択し、選択されたブロック内のすべての行を読み取ることで、ネイティブの BigQuery テーブルや、Google Cloud Storage のストレージ バケットに保存されている外部テーブルのデータをサンプリングできます。これにより、アドホックなクエリを試す際のクエリコストを下げることができます。ドキュメント
アジャイルなスキーマ
分析ニーズの変化に合わせてデータを進化させられる、SQL のコマンドや機能が増えました。
データセット(SCHEMA)オペレーション(一般提供版)
BigQuery においてデータセットは、テーブル、ビュー、プロシージャなどのデータおよびプログラム オブジェクトを含む最上位のコンテナ エンティティです。これらのデータセットの作成、維持、削除は、BigQuery では API、CLI、UI を使ってサポートされてきました。本日、データベースやデータ ウェアハウスにおける論理オブジェクトの集合体を表す ANSI 標準キーワードである SCHEMA を使用したデータセット操作のフル SQL サポート(CREATE、ALTER、DROP)を提供できることになりました。これにより、データ管理者が BigQuery プロジェクト全体のスキーマをプロビジョニングおよび管理する作業が大幅に簡素化されます。CREATE、ALTER、DROP SCHEMA 構文に関するドキュメント
INFORMATION_SCHEMA からのオブジェクト作成 DDL(プレビュー版)
データ管理者は、本番環境データセットの空のコピーをプロビジョニングして、架空のデータをロードできるようにしています。これにより、デベロッパーは本番データセットに追加する前に新しい機能をテストでき、新入社員はテストデータを使って本番環境同様のデータセットでトレーニングを行えます。データ管理者がオブジェクトのデータ定義言語(DDL)を生成できるように、BigQuery の INFORMATION_SCHEMA の TABLES ビューには、データセット内のすべてのテーブル、ビュー、マテリアライズド ビューの正確なオブジェクト生成 DDL を含む DDL という新しい列が追加されました。ダイナミック SQL との組み合わせにより、データ管理者は、スキーマ オブジェクトに関連するすべてのオプションや要素を手作業で再構築することなく、特定のオブジェクトや特定のタイプ(MATERIALIZED VIEW など)のすべてのオブジェクト、または指定されたデータセット内のすべてのデータ オブジェクトの作成 DDL コマンドを単一の SQL ステートメントで迅速に生成、実行できます。ドキュメント
DROP COLUMN のサポート(プレビュー版)
2020 年 10 月、BigQuery は SQL の ADD COLUMN サポートを導入し、ユーザーが SQL を使って既存のテーブルに列を追加できるようにしました。データ エンジニアやアナリストが新しいデータをサポートするためにテーブルを拡張すると、一部の列が古くなり、テーブルから削除する必要が出てきます。そこで BigQuery では、ALTER TABLE コマンドの一部として DROP COLUMN 句がサポートされ、ユーザーがこれらの列を 1 つまたは複数削除できるようになりました。プレビュー期間中は、DROP COLUMN の操作に一定の制限があるのでご注意ください。詳しくはこちらのドキュメントをご覧ください。
より長い列名(一般提供版)
BigQuery では、テーブル、ビュー、マテリアライズド ビュー内の列名を、従来の 128 文字から 300 文字まで長くできるようになりました。ドキュメント
ストレージ インサイト
パーティション分割テーブルと分割されていないテーブルのストレージ使用量の分析
テーブルの INFORMATION_SCHEMA.PARTITIONS ビュー(プレビュー版)
お客様は、分析データを BigQuery のテーブルに格納し、BigQuery の大規模テーブルに対して柔軟なパーティショニング スキームを使用してデータを整理し、クエリの効率を向上させます。データ エンジニアに、パーティション分割テーブルまたは分割されていないテーブルのストレージやレコード数に関するより優れたインサイトを提供するために、BigQuery の INFORMATION_SCHEMA の一部として、PARTITIONS ビューを導入することになりました。このビューには、テーブルのサイズ(論理および課金対象バイト)、行数、テーブル(またはパーティション)の最終更新日、特定のテーブル(またはパーティション)がアクティブか、またはより価格の安い長期保存に移行したかなど、テーブルまたはそのパーティションに関する最新の情報が表示されます。テーブルのパーティション エントリは PARTITION_ID で識別されますが、パーティション分割されていないテーブルの PARTITION_ID は単一の NULL エントリとなります。
INFORMATION_SCHEMA ビューへのクエリは、ベーステーブルへのクエリに比べてコスト効率が良くなります。このように、PARTITIONS ビューをクエリと併用することで、特定のパーティションへクエリをフィルタリングできます。例えば以下に示すように、直近に更新されたパーティション内のデータやパーティション キーの最大値を見つけることができます。ドキュメント
これらの新機能により、BigQuery ユーザーの皆様が新しい一歩を踏み出せることを願っています。そして、これからもよりユーザー フレンドリーな SQL をお届けできるよう、尽力してまいります。BigQuery について詳しくは Google のウェブサイトをご確認ください。BigQuery サンドボックスを無料ですぐにお試しいただけます。
-Google Cloud プロダクト マネージャー Jagan R. Athreya




