BQML 用の新しいパイプライン演算子を 20 個以上リリース
Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
本日、Google は、Vertex AI Pipeline 用の BigQuery ジョブと BigQuery ML(BQML)ジョブを Vertex AI Pipeline で容易に運用化する、Vertex AI Pipeline 用の 20 個以上の新しい BigQuery 演算子と BQML 演算子をリリースしました。今年初めには、最初の 5 つの BigQuery パイプライン コンポーネントと BQML パイプライン コンポーネントをリリースしました。これら Google が提供する 21 個の新しい Google Cloud 対応コンポーネントは、データ サイエンティスト、データ エンジニアなどのユーザーが予測、Explainable AI、MLOps など Google Cloud の BQML 機能をすべて活用できるよう支援します。
BQML と Vertex AI のシームレスなインテグレーションにより、BQML モデルのトレーニングからサービス提供までのモデル ライフサイクル全体の自動化およびモニタリングが行いやすくなります。開発者、特に ML エンジニアは、BQML ワークフローを ML パイプラインに組み込むために特別なコードを書く必要がなくなります。これらの新しい BQML コンポーネントをパイプラインにネイティブに組み込むだけで、エンドツーエンドの ML ライフサイクル パイプラインを容易かつ迅速にデプロイできるようになりました。
さらに、これらのコンポーネントを Vertex AI Pipelines の一部として使用することで、データとモデルを管理できるようになります。パイプラインが実行されるたびに、自動的に生成されるアーティファクトを Vertex AI Pipelines が追跡、管理します。
BigQuery では、以下のコンポーネントが利用可能になりました。
BigQuery | ||
カテゴリ | コンポーネント | 説明 |
クエリ | 任意の BQ クエリを送信し、一時テーブルまたは永続テーブルに書き込めます。BigQuery のクエリジョブを起動し、終了を待ちます。 | |
BigQuery ML(BQML)では、以下のコンポーネントが利用可能になりました。
BigQuery ML | |||
カテゴリ | コンポーネント | 説明 | |
コア | DDL ステートメントを送信して BigQuery ML モデルを作成できます。 | ||
BigQuery ML モデルを評価できます。 | |||
BigQuery ML モデルを使用して予測を作成できます。 | |||
BigQuery ML モデルを Google Cloud Storage バケットにエクスポートできます。 | |||
新しいコンポーネント | |||
予測 | BigQuery の ML.FORECAST ジョブを起動し、ARIMA_PLUS モデルまたは ARIMA モデルを予測できます。 | ||
BigQuery の ML.EXPLAIN_FORECAST ジョブを起動し、ARIMA_PLUS モデルまたは ARIMA モデルを予測できます。 | |||
BigQuery の ML.ARIMA_EVALUATE ジョブを起動し、終了を待ちます。 | |||
異常 検出 | BigQuery の異常モデル検出ジョブを起動し、終了を待ちます。 | ||
モデルの評価 | BigQuery の混同行列ジョブを起動し、終了を待ちます。 | ||
BigQuery の ML.CENTROIDS ジョブを起動し、終了を待ちます。 | |||
BigQuery の ML トレーニング情報取得ジョブを起動し、終了を待ちます。 | |||
BigQuery の ML 試行情報ジョブを起動し、終了を待ちます。 | |||
BigQuery の ROC 曲線ジョブを起動し、終了を待ちます。 | |||
Explainable AI | BigQuery のグローバル説明取得ジョブを起動し、終了を待ちます。 | ||
BigQuery の機能情報ジョブを起動し、終了を待ちます。 | |||
BigQuery の機能重要性取得ジョブを起動し、終了を待ちます。 | |||
モデルの重み付け | BigQuery の ML 重みづけジョブを起動し、終了を待ちます。 | ||
BigQuery の ML 詳細重みづけジョブを起動し、終了を待ちます。 | |||
BigQuery の ML.PRINCIPAL_COMPONENTS ジョブを起動し、終了を待ちます。 | |||
BigQuery の ML.principal_component_info ジョブを起動し、終了を待ちます。 | |||
BigQuery の ML.ARIMA_COEFFICIENTS ジョブを起動し、ARIMA 係数を確認できます。 | |||
モデルの推論 | BigQuery の ML 再構成損失ジョブを起動し、終了を待ちます。 | ||
BigQuery の予測モデル説明ジョブを起動し、終了を待ちます。 | |||
BigQuery の ML.Recommend ジョブを起動し、終了を待ちます。 | |||
その他 | BigQuery のドロップモデル ジョブを起動し、終了を待ちます。 | ||
すべての BQML 用パイプライン演算子の概要がわかったところで、エンドツーエンドの需要予測構築の例で、予測演算子をどのように使用するかを見てみましょう。コードは GitHub の Vertex AI サンプル リポジトリで確認できます。
BigQuery ML における需要予測パイプラインの例
このセクションでは、需要予測用の Vertex AI Pipelines で BigQuery と BQML コンポーネントを使ったエンドツーエンドの例を示します。このパイプラインは、Google Cloud のデータ分析で食品廃棄問題を解決というブログ投稿から引用しています。このシナリオでは、生鮮食品の流通販売を専門とする架空の食料品店 FastFresh が、食品廃棄を最小限に抑え、全店舗で在庫量を最適化することを目指しています。同社は、在庫の更新頻度が高い(すべての商品について分単位で更新)ため、需要予測モデルを 1 時間単位でトレーニングしたいと考えています。1 日あたり 24 回のトレーニング ジョブが実行されるので、BQML の予測モデルタイプである BQML ARIMA_PLUS のパイプライン演算子を使用した ML パイプラインを使ってモデルのトレーニングを自動化することも検討しています。
パイプラインの流れの全体像を以下に示します。
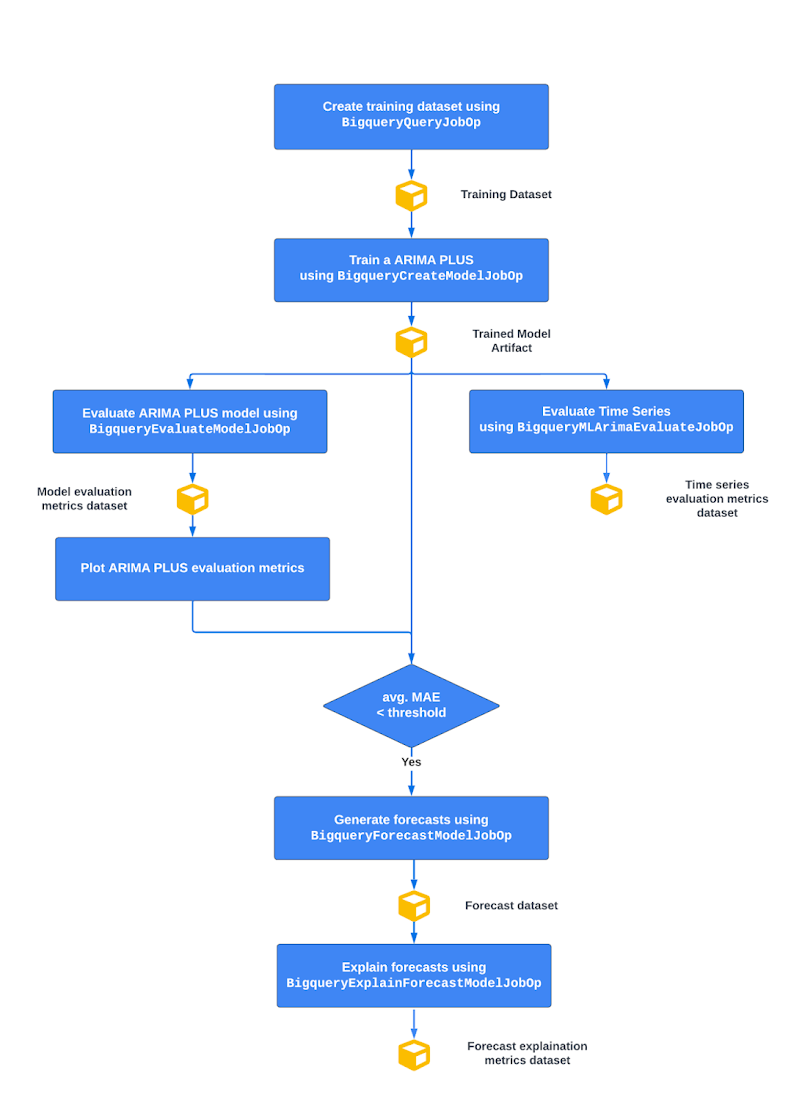
図 1 - パイプラインの流れの全体構成
上から順に:
BigQuery でトレーニング データセットを作成する
BigQuery ML ARIMA_PLUS モデルをトレーニングする
ARIMA_PLUS の時系列とモデル指標を評価する
次に、予測値と実績値の差の絶対値の平均を表す平均絶対誤差(MAE)が特定のしきい値未満であれば、以下を行います。
トレーニングした時系列 ARIMA_PLUS モデルを基に時系列予測を作成する
予測を説明するためにトレーニング データと予測データの両方から別々の時系列コンポーネントを作成する
ここで、BQML ARIMA_PLUS のパイプライン演算子について説明します。
需要予測モデルのトレーニング
トレーニング データ(表形式)を準備できたら、ARIMA_PLUS アルゴリズムによる需要予測モデルの構築を開始できます。この BQML モデル作成のオペレーションは、Vertex AI Pipelines 内で BigqueryCreateModelJobOp を使って自動化できます。前回の記事で説明したとおり、このコンポーネントでは、BQML トレーニング クエリを渡して BigQuery 上の ARIMA_PLUS モデルのトレーニングを送信できます。このコンポーネントは Vertex ML Metadata に記録される google.BQMLModel を返します。これにより、すべてのアーティファクトのリネージを追跡できます。以下のモデル トレーニング演算子では、set_display_name 属性により、実行中のコンポーネントに名前をつけることができます。また、after 属性では、パイプライン ステップの順序を制御できます。
時系列とモデル指標の評価
ARIMA_PLUS モデルをトレーニングしたら、予測を生成する前にモデルを評価する必要があります。BigQuery ML では、ML.ARIMA_EVALUATE 関数と ML.EVALUATE 関数を使用できます。ML.ARIMA_EVALUATE 関数は、デフォルトで有効な自動ハイパーパラメータ調整(auto.ARIMA)によってトレーニングしたすべての ARIMA モデルについて、log_likelihood、AIC、分散などの統計指標と、季節性、休日効果、急上昇や急降下の外れ値などの時系列情報の両方を生成します。ML.EVALUATE は、平均絶対誤差(MAE)や平均二乗誤差(MSE)などの予測精度指標を取得します。これらの評価関数を Vertex AI のパイプラインに統合するために、対応する BigqueryMLArimaEvaluateJobOp 演算子と BigqueryEvaluateModelJobOp 演算子を使用できるようになりました。どちらの場合も、google.BQMLModel を入力とし、評価指標アーティファクトを出力として返します。
BigqueryMLArimaEvaluateJobOp については、パイプライン コンポーネントで使用される例を以下に示します。
以下は、BigQuery のテーブルで BigqueryMLArimaEvaluateJobOp 演算子から得られる統計的指標(最初の 5 列)です。
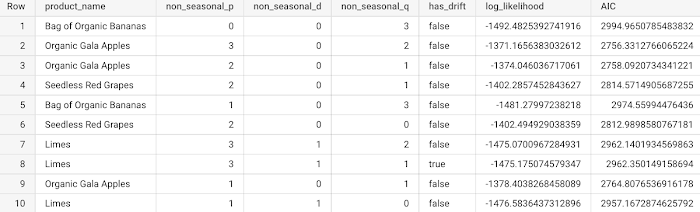
図 2 - BigQuery の BigqueryMLArimaEvaluateJobOp の結果として得られる指標の一覧
BigqueryEvaluateModelJobOp については、以下のように対応するパイプライン コンポーネントがあります。
ここに、評価予測指標を生成するためのテストサンプルを選択するクエリ文があります。
Vertex ML メタデータの評価指標アーティファクトとして、それらの指標を後で使用し、Kubeflow SDK visualization API を使用して Vertex AI Pipelines UI で可視化できます。Vertex AI では、Google Cloud コンソールから簡単にアクセスできる出力ページで、その HTML を表示できます。以下は、作成可能なカスタム予測 HTML レポートの例です。

図 3 - BigqueryEvaluateModelJobOp から得られるカスタム予測精度レポート
また、これらの値を使用し、パイプライン グラフで Kubeflow SDK の条件を使用して、条件付き if-else ロジックを実装できます。このシナリオでは、トレーニング済みモデルの平均二乗誤差が特定のしきい値を下回っていれば予測を生成するためにモデルを使用できるよう、平均二乗誤差を使用してモデル性能条件を実装しています。
需要予測の作成と説明
今後 n 時間の予測を生成する場合は、BigQuery の予測モデルジョブを起動する BigqueryForecastModelJobOp を使用できます。このコンポーネントは、google.BQMLModel を入力アーティファクトとして使用し、ここで予測する時点(ホライズン)数と予測区間に入る将来の値の割合(confidence_level)を設定できます。以下の例では、信頼区間 90% で 1 時間ごとの予測を生成することになっています。
次に、job_configuration_query パラメータを使用して、事前に定義された宛先テーブルで予測が具体化されます。これは Vertex ML Metadata で google.BQTable として追跡されます。以下は、取得される予測テーブルの例です(5 列のみ例示)。

予測を生成したら、BigqueryForecastModelJobOp 演算子の機能を拡張し、トレンド、検出された季節性、休日効果などの追加モデルを説明する ML.EXPLAIN_FORECAST 関数を使用可能にするBigqueryExplainForecastModelJobOpを使って、予測を説明することもできます。
ここで、Vertex AI Pipelines UI で定義したパイプライン全体を可視化したものを確認できます。
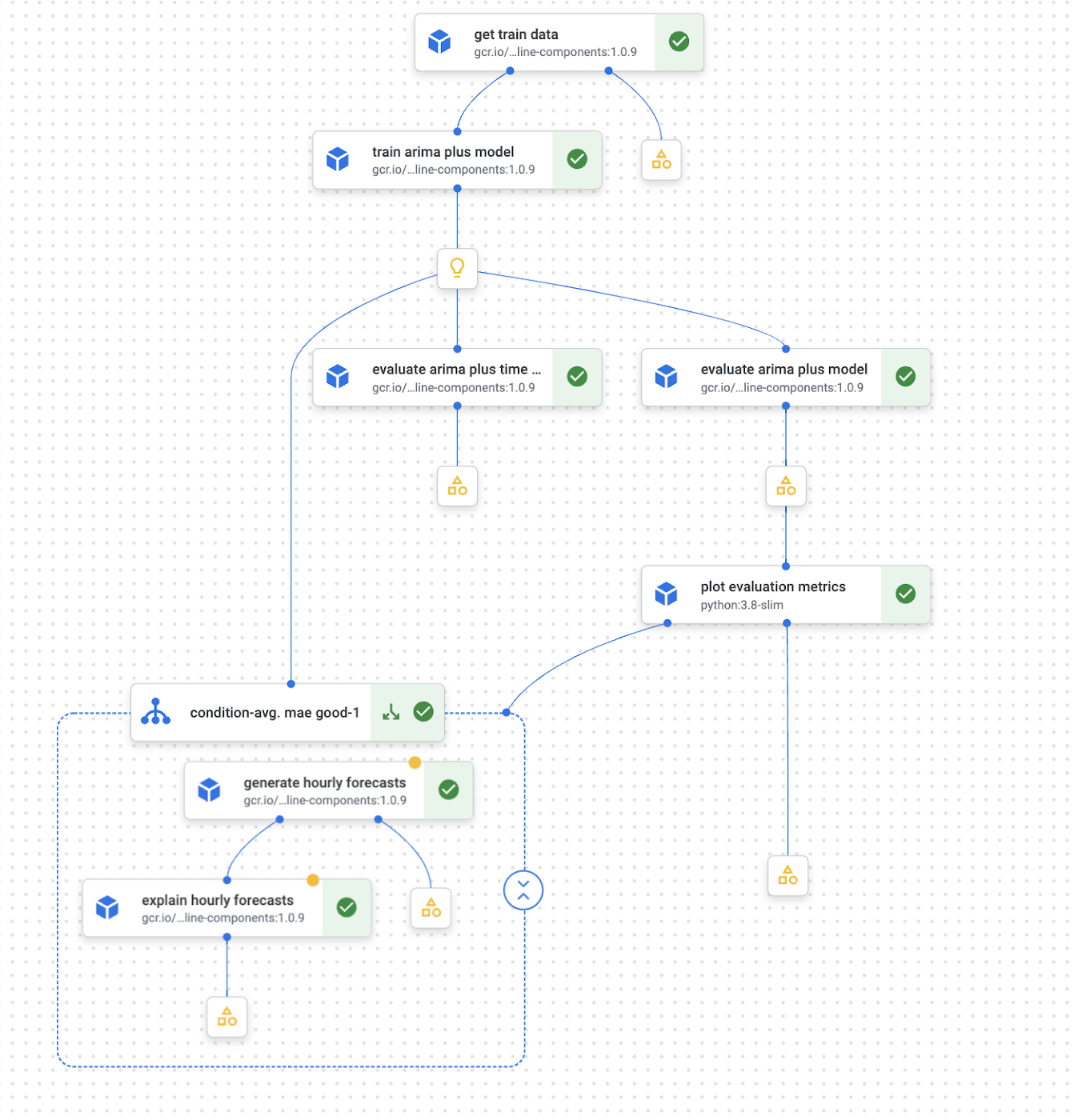
図 5 - Vertex AI Pipelines UI のパイプラインの可視化
また、ML パイプラインのアーティファクトとそのリネージを分析、デバッグ、監査したい場合は、Google Cloud コンソールによりレンダリングされた黄色のアーティファクト オブジェクトのいずれかをクリックすると、Vertex ML Metadata で以下の表現にアクセスできます。
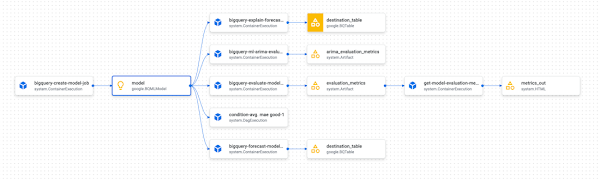
まとめ
このブログ投稿では、データ サイエンティストや ML エンジニアがあらゆる BigQuery 関数と BigQuery ML 関数をオーケストレーションおよび自動化できるよう、Vertex AI パイプラインで現在利用可能な新しい BigQuery コンポーネントと BigQuery ML コンポーネントについて説明しました。また、BigQuery ML と Vertex AI Pipelines を含む需要予測のためのコンポーネントを使用したエンドツーエンドの例も紹介しました。
次のステップ
Vertex AI Pipelines で BQML パイプラインを実行する準備はできましたか?以下の参考資料をご覧になって、ぜひお試しください。
ドキュメント
Code Labs
Vertex AI のサンプル: GitHub リポジトリ
動画シリーズ: AI の基礎: Vertex AI
クイックラボ: Vertex AI での機械学習ソリューションの構築とデプロイ
参照
https://cloud.google.com/blog/ja/topics/developers-practitioners/announcing-bigquery-and-bigquery-ml-operators-vertex-ai-pipelines
- カスタマー エンジニア、Ivan Nardini
- 機械学習担当カスタマー エンジニア、 Steve Walker