Vertex AI Pipelines の BigQuery および BigQuery ML 演算子に関するお知らせ
Google Cloud Japan Team
※この投稿は米国時間 2022 年 4 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
Vertex AI Pipelines の一部として、BigQuery と BigQuery ML(BQML)のオペレーションをオーケストレートしようとする開発者(特に ML エンジニア)は、これまで独自のカスタム コンポーネントを記述する必要がありました。本日、新しい Vertex AI Pipelines の BigQuery と BQML コンポーネントをリリースしたことをお知らせします。これにより、BigQuery と BQML のジョブを Vertex AI Pipelines で行うことがさらに容易になります。Google Cloud の公式コンポーネントであるこれらを使えば、BigQuery と BigQuery ML を Vertex AI Pipelines により簡単に組み込むことができます。たとえば、Vertex AI Pipelines を使って、トレーニングからサービス提供に至るまですべての BQML モデルのモデル ライフサイクルを自動化し、モニタリングできます。さらに、これらのコンポーネントを Vertex AI Pipelines の一部として使うことで、パイプラインを実行するたびに、自動的に生成されたアーティファクトを Vertex AI Pipelines がトラッキングするので、さらなるデータとモデルのガバナンスが利用可能となります。
BigQuery では、以下のコンポーネントが利用可能になりました。
任意の BQ クエリを送信し、一時テーブルまたは永続テーブルに書き込めます。BigQuery クエリのジョブを開始し、終了するまで待ちます。 |
BigQuery ML(BQML)では、以下のコンポーネントが利用可能になりました。
DDL ステートメントを送信して BigQuery ML モデルを作成できます。 | |
BigQuery ML モデルを評価できます。 | |
BigQuery ML モデルを使用して予測を作成できます。 | |
BigQuery ML モデルを Google Cloud Storage バケットにエクスポートできます。 |
シンプルな Vertex AI Pipelines の作成方法、BQML モデルのトレーニング方法、オンライン予測のために Vertex AI にモデルをデプロイする方法を学びます。
上記のノートブックに加えて、Dataflow、BigQuery、BigQuery ML コンポーネントを使って BQML と Dataflow を用いたテキスト ドキュメントのトピックラベルを予測するエンドツーエンドの例をご覧ください。
Vertex AI Pipelines で BigQuery と BQML コンポーネントを使ったエンドツーエンドの例
このセクションでは、Vertex AI Pipelines で BigQuery と BQML コンポーネントを使ったエンドツーエンドの例を示します。このパイプラインは、まず生テキスト ドキュメントを BQML で事前トレーニング済みの Swivel TensorFlow モデルを使ってエンベディングに変換し、トピックを予測します。その後、パイプラインはテキスト エンベディングを使って BQML のロジスティック回帰モデルをトレーニングし、ドキュメントのトピックとなるラベルを予測します。わかりやすくするために、ここでは、モデルはトピックが「acq」に等しいか(1)、そうでないか(0)を予測します。「acq」は、ドキュメントがデータセットで定義されている「企業買収」のトピックに関連していることを意味します。
パイプラインの全体像を以下に示します。
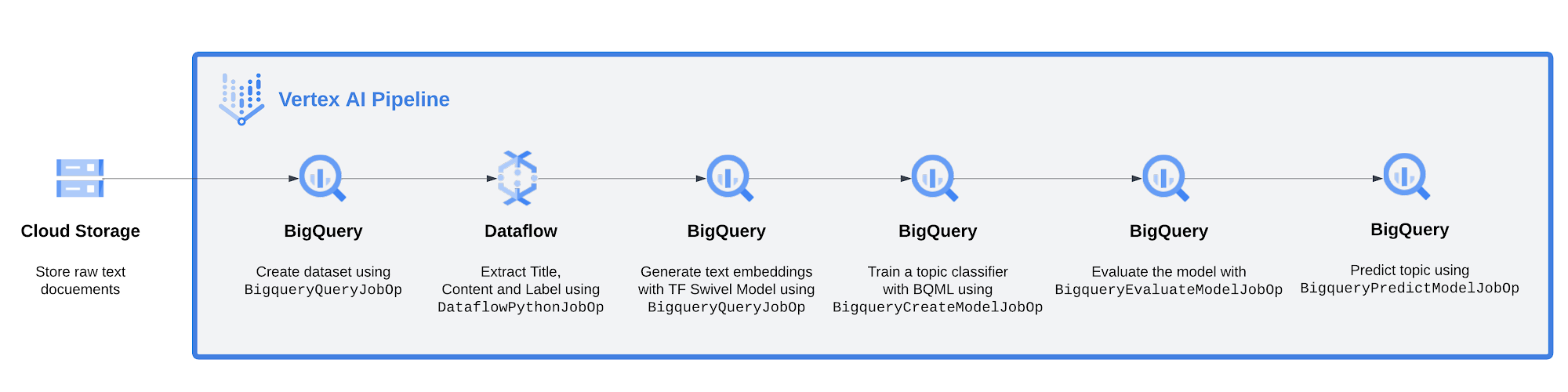
左から右に:
Google Cloud Storage に保存されているニュース関連のテキスト ドキュメントから始める
BigqueryQueryJobOp を使って BiqQuery でデータセットを作成する
Dataflow を使ってタイトル、コンテンツ、(HTML)ドキュメントのトピックを抽出し、BigQuery に取り込む
BigQuery ML を使って、Swivel TensorFlow モデルを適用して各ドキュメントのコンテンツにエンベディングを生成する
ロジスティック回帰モデルをトレーニングして、ドキュメントのエンベディングが事前定義済みトピックに関連しているかを予測する(関連していれば 1、関連していなければ 0)
モデルを評価する
データセットにモデルを適用して、予測を作成する
詳しく見ていきましょう。
DataflowPythonJobOp コンポーネントでの ETL
Google Cloud Storage(GCS)に保存された Reuters からの生のテキスト ドキュメントがあるとします。それを前処理し、BigQuery にテキストをインポートして、BQML を使って分類モデルをトレーニングしたいと考えています。
そのためにはまず、CREATE SCHEMA IF NOT EXISTS mydataset という SQL クエリを実行し、BQ データセットを作成する必要があります。Vertex AI Pipelines では、BigqueryQueryJobOp 内でクエリを実行できます。
完全なコードはこちらのノートブックをご覧ください。
データセットを作成したら、モデル トレーニング用のテキスト ドキュメントを準備します。重要なのは、生のドキュメントからテキストの関連セクション(「Title」、「Body」、「Topic」)を解析する必要があることです。今回のケースでは、Python の Beautiful Soup (bs4)ライブラリを使った Dataflow 上の Beam パイプラインを用いて、以下を抽出します。
Title、記事のタイトル
Body、記事のテキスト コンテンツ全体
Topics、記事が属するカテゴリ(1 つまたは複数)
この前処理ステップは、Apache Beam を使った ETL パイプラインに基づいており、DataflowPythonJobOp にラップして Vertex AI Pipelines で使用できます。DataflowPythonJobOp コンポーネントは、Python で記述された Apache Beam のジョブを Dataflow に送信して、Google Cloud 上で実行します。言い換えれば、このコンポーネントを使えば、データの前処理ステップを実行し、Dataflow を介して、関連したテキストのセクションを抽出できるということです。
完全なコードはこちらのノートブックをご覧ください。
上記のコンポーネントで何が起きているかをご説明します。requirements_file_path は要件ファイルに GCS バケット URI を含み、python_module_path は Apache Beam パイプライン python スクリプトにバケット URI を含み、args は Beam Runner 経由で Apache Beam コードに渡される引数のリストを含みます。また、WaitGcpResourcesOp が要求されていることにも注目してください。これにより、パイプラインは、次のパートを続行する前に、コンポーネントが実行されるのを待つことができます。
BigqueryQueryJobOp と DataflowPythonJobOp による特徴量エンジニアリング
Dataflow でドキュメントが前処理されると、次のステップはその前処理されたドキュメントからテキスト エンベディングを抽出することです。そして、このエンベディングは、ロジスティック回帰モデルがトピックを予測するためのトレーニング データとして使われます。
テキストからエンベディングを抽出するために、Swivel モデルを利用できます。これは、トレーニング済みの TensorFlow モデルで、TensorFlow Hub で一般公開されています。BigQuery のテキストで、どのようにトレーニング済みの TensorFlow SavedModel を使用するのでしょうか。まず、BQML を使用して TensorFlow SavedModel をインポートし、ドキュメントのテキストに適用してエンベディングを生成します。そして、データセットを分割し、テキスト分類子で利用するトレーニング サンプルを取得します。
以下に、パイプライン内でコンポーネントがどのように表示されるかを示します。
完全なコードはこちらのノートブックをご覧ください。
ここで、bq_preprocess_query は、前処理のクエリ、プロジェクト、BigQuery ジョブが実行される場所を含みます。
例えば、bq_preprocess_query 内における最初のステップは、BigQuery ML を用いて Swivel モデルをインポートすることです。その次のステップでは、次のセクションのテキスト分類子モデルのトレーニング データとなるエンベディングを取得することになります。
完全なコードはこちらのノートブックをご覧ください。
BigqueryCreateModelJobOp を使ってドキュメント分類器をトレーニング
こうしてトレーニング データが(テーブルとして)入手できたので、ロジスティック回帰を用いて、ドキュメントのラベルが「acq」であるかどうかを判断するドキュメント分類器を構築する準備ができました。この BQML モデル作成のオペレーションは、Vertex AI Pipelines 内で、BigqueryCreateModelJobOp を用いて自動化できます。このコンポーネントは、BQML のトレーニング クエリを渡すことができ、必要に応じて、BigQuery 上でモデルのトレーニングをスケジュール設定するために、そのクエリおよび関連するジョブをパラメータ化できます。コンポーネントは google.BQMLModel を返します。これは、Vertex ML Metadata を使用して BQML モデルを自動的にトラッキングし、モデルとデータのリネージにさらなるインサイトを提供します。
完全なコードはこちらのノートブックをご覧ください。
BigqueryEvaluateModelJobOp を使ってモデルを評価
モデルをトレーニングしたら、予測を生成するために本番環境にデプロイする前に評価することになるでしょう。BigqueryEvaluateModelJobOp では、以前のトレーニング BigqueryCreateModelJobOp で受け取った google.BQMLModel 出力を渡すだけで、モデルの種類に応じたさまざまな評価指標を生成してくれます。この例では、Vertex ML Metadata のパイプラインのリネージで利用可能な適合率、再現率、f1_score、log_loss、roc_auc を取得しています。
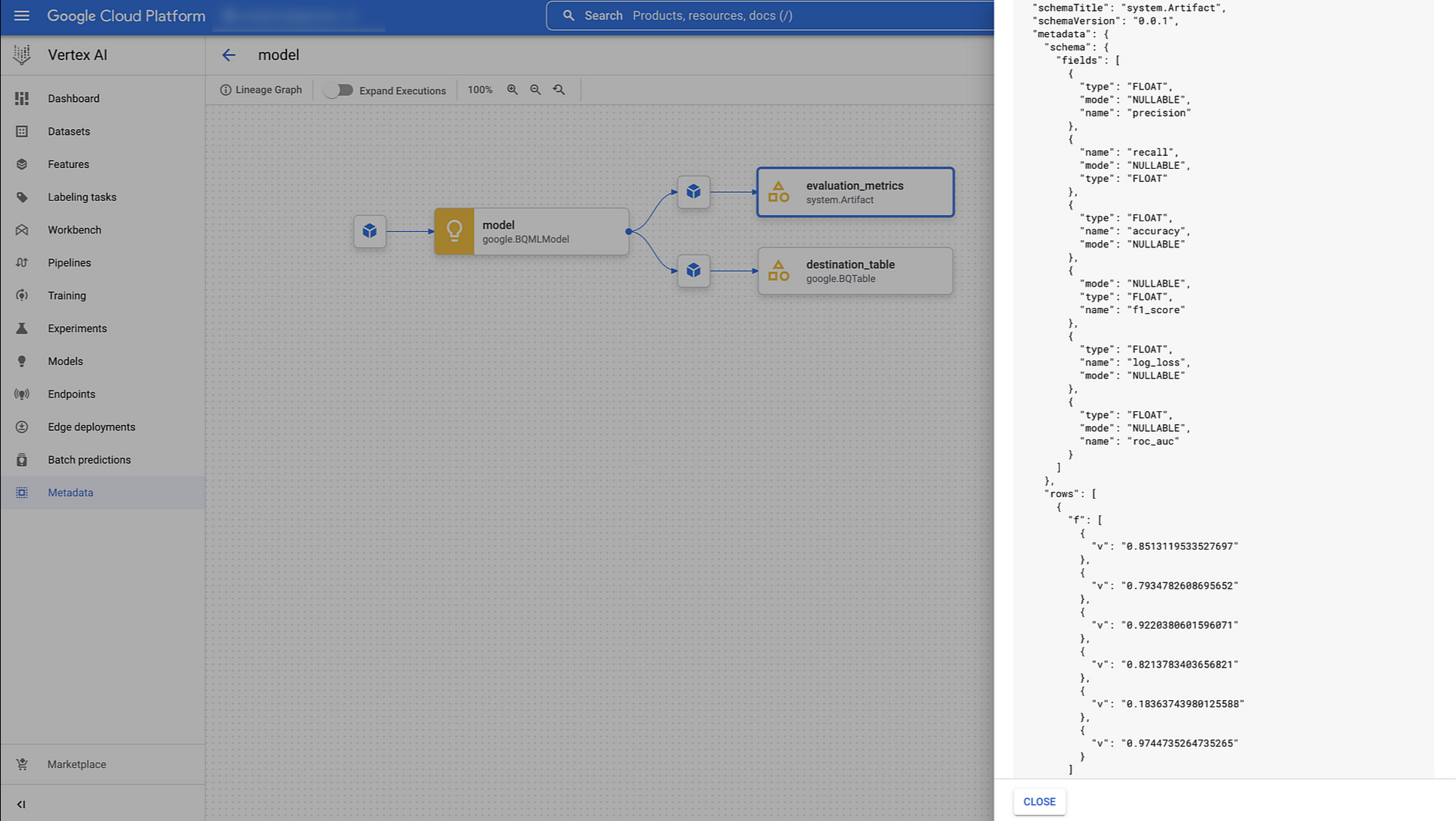
これらのコンポーネントのおかげで、ダウンストリーム モデルで何をしたいかを決定するための条件付きロジックを実装できるのです。例えば、パフォーマンスがあるしきい値以上であれば、パイプラインを続行させて BigQuery ML で直接予測を行ったり、モデルをモデル レジストリ サービスに登録したり、モデルをステージング エンドポイントにデプロイしたりできます。これは、ご自身の ML パイプラインで実装したいロジックが何かにより大きく左右されます。
ドキュメント分類を使用したこのパイプラインの例では、条件ロジックを使わずに直接バッチ予測のみを生成しています。
BigqueryPredictModelJobOp を使用して予測
BQML モデル予測を運用するために、google_cloud_pipeline_components ライブラリの bigquery モジュールは BigqueryPredictModelJobOp を提供しています。これにより、トレーニング コンポーネントの google.BQMLModel を使用して BigQuery 予測モデルジョブを開始できます。
完全なコードは、 こちらのノートブックをご覧ください。
このコンポーネントでは、 予測テーブルの列をフォーマットするクエリ ステートメントの他に、宛先テーブル(プロジェクト ID、データセット ID、テーブル ID)を定義するために、job_config も渡します。
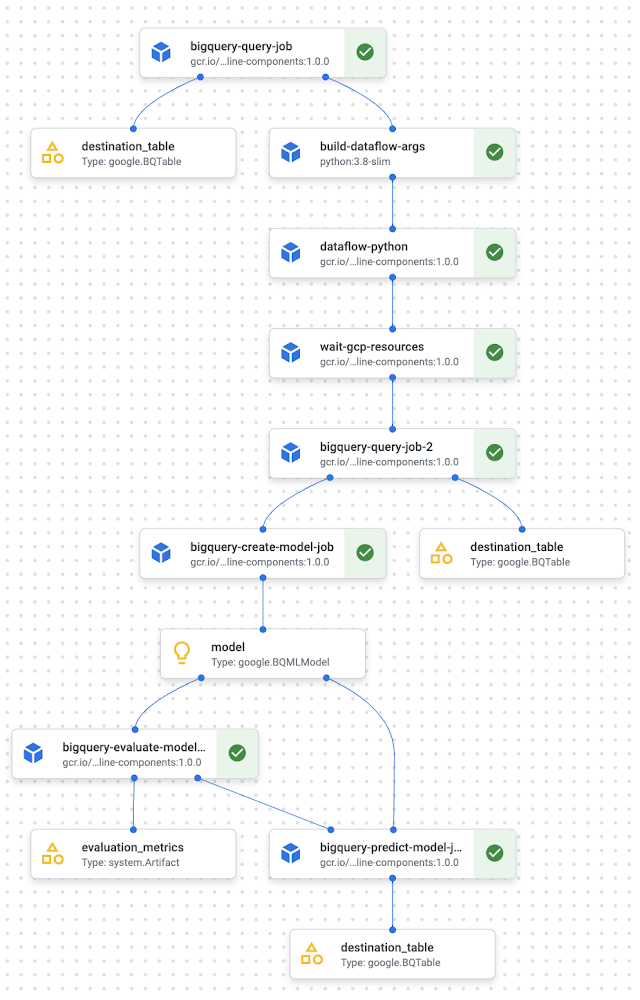
下の図は、Vertex AI Pipelines UI で得られるパイプライン全体を可視化したものです。
まとめ
今回のブログ記事では、Vertex AI Pipelines で新しい BigQuery と BQML のコンポーネントが利用可能になったことをお知らせしました。また、BigQuery ML と Vertex AI Pipelines を含む文書分類のためのコンポーネントを使用したエンドツーエンドの例も紹介しました。
次のステップ
Vertex AI Pipelines で BQML パイプラインを実行する準備はできましたか?以下の参考資料をご覧になって、ぜひお試しください。
ドキュメント
Code Labs
動画シリーズ: AI の基礎: Vertex AI
クイックラボ: Vertex AI での機械学習ソリューションの構築とデプロイ
参照
このブログ投稿を書くにあたって、Bo Yang、Andrew Ferlitsch、Abhinav Khushraj、Ivan Cheung、Gus Martins のご協力に感謝いたします。
- デベロッパー アドボケイト、Polong Lin
- Google Cloud、Ivan Nardini