生成 AI の評価をマスター: 単一のプロンプトから複雑なエージェントまで
Smitha Kolan
Senior Developer Relations
※この投稿は米国時間 2025 年 12 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
誰もが生成 AI アプリケーションを構築できるようになりましたが、アプリケーションをプロトタイプからプロダクション レディのシステムに移行するには、評価という重要なステップが必要となります。
LLM が安全かどうかはどのように判断すればよいでしょうか。RAG システムがハルシネーションを起こさないようにするにはどうすればよいでしょうか。SQL クエリをその場で生成するエージェントをテストするにはどうすればよいでしょうか。
生成 AI の評価では、システムによる回答の品質、安全性、有用性をデータと指標を使用して測定することが基本です。Vertex AI Evaluation と Agent Development Kit(ADK)などのツールを使用すれば、単に出力を確認する「感覚ベース」のテストから、厳密な指標主導のアプローチに移行できます。
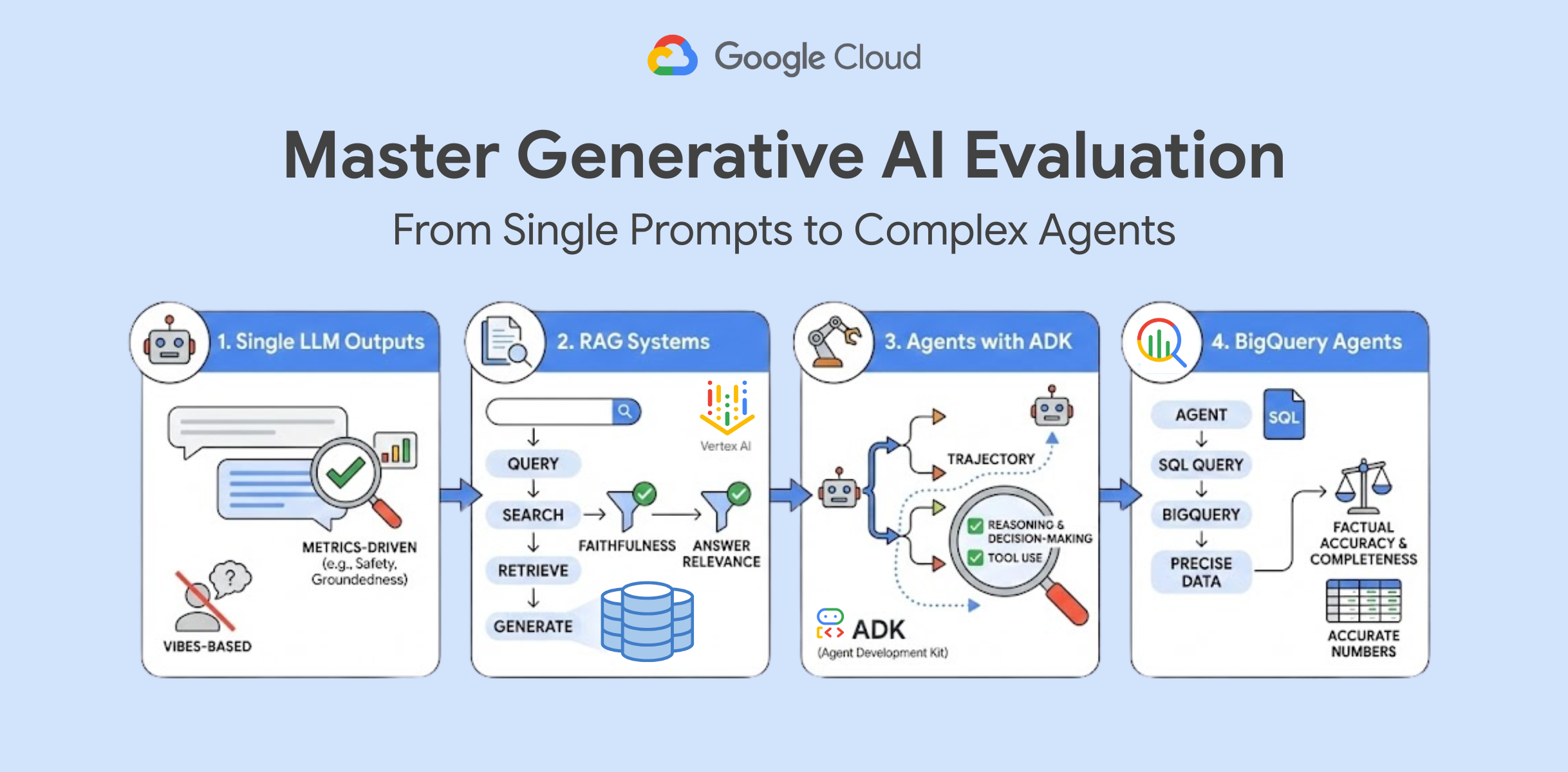
このプロセスをスムーズに実行できるよう、4 種類のハンズオンラボをリリースしました。プロンプト テストの基本の確認から、データ主導の複雑なエージェント評価まで実践できます。
単一の LLM 出力を評価する
複雑なシステムを構築する前に、単一のプロンプトとその回答を評価する方法について理解する必要があります。このラボでは、モデルの出力を自動的に評価するサービスである GenAI Evaluation を紹介します。
また、安全性、根拠、指示の実行などの指標を定義する方法を学びます。データセットに対して評価タスクを実行する方法も学びます。これはあらゆるプロダクション レディな AI アプリケーションにおいて基盤となるステップです。
Vertex AI で RAG システムを評価する
検索拡張生成(RAG)は強力なパターンですが、検索でドキュメントが見つからなかったのか、LLM がドキュメントを要約できなかったのか、という新たな障害ポイントも生じます。
このラボでは、評価ライフサイクルについてさらに詳しく説明していきます。「忠実性」(回答はコンテキストに基づくものか)と「回答の関連性」(ユーザーの質問に回答しているか)を検証する方法を学びます。これにより、RAG パイプラインの改善が必要な部分を正確に特定できるようになります。
ADK を使用してエージェントを評価する
エージェントは動的なものであり、入力に基づいてツールを選択し、手順を決定します。そのため、一般的なプロンプトよりもテストが困難です。最終的な回答を評価するだけでなく、エージェントが回答にたどり着くまでの軌跡も評価します。
このラボでは、Agent Development Kit(ADK)を使用してエージェントの意思決定をトレースし、評価する方法を説明します。具体的には、エージェントの推論プロセスの評価基準を定義する方法と、結果を可視化してエージェントがツールを正しく使用していることを確認する方法を学びます。
BigQuery エージェントを構築して評価する
エージェントがデータを扱う際には、正確性が最も重要となります。SQL 生成エージェントは、構文的に正しいクエリを記述し、正確な数値を取得する必要があります。ここでハルシネーションが発生すると、単なる出力ミスでは済まされず、誤ったビジネスの意思決定につながる可能性があります。
この上級ラボでは、BigQuery にクエリを実行できるエージェント機能を構築し、Gen AI Eval Service を使用して結果を検証します。事実に基づく正確さと完全性を測定する方法を学び、エージェントがリクエストされたデータを漏れなく正確に提供できるようにします。
本番環境で信頼できる AI に
AI アプリケーションを本番環境グレードにレベルアップする準備ができたら、以下の Codelab を使用して、モデルの出力またはエージェントがたどる軌跡を評価しましょう。
プロトタイプから本番環境へ
ここで紹介したラボは、Google の公式プログラムである Google Cloud でのプロダクション レディな AI の AI 評価モジュールの一部です。カリキュラム全体をご確認いただき、有望なプロトタイプを本番環境グレードの AI アプリケーションに移行するうえで役に立つ、別のコンテンツもご覧ください。
-シニア デベロッパー リレーションズ、Smitha Kolan



