Agent Factory のハイライト: TPU での強化学習とファインチューニング

Shir Meir Lador
Head of AI, Product DevRel
※この投稿は米国時間 2026 年 1 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
Agent Factory のホリデー スペシャルでは、Google の TPU トレーニング チームのシニア プロダクト マネージャーである Kyle Meggs をゲストに迎え、Don McCasland と私の 3 人で、モデルのファインチューニングの世界を深く掘り下げました。特に、強化学習(RL)と、Google 独自の TPU インフラストラクチャがこれらの大量のワークロードを大規模に処理できるように設計されている点に焦点を当てました。
この投稿では、今回の対談からの重要なアイデアをいくつか紹介します。なお、この投稿は、トピックをすばやく振り返ったり、リンクやタイムスタンプを使用して特定のセグメントを詳しく調べたりできるような構成になっています。

ファインチューニングを検討するタイミング
タイムスタンプ: 3:13
私たちは基本的な疑問点から話し始めました。Gemini のような基盤モデルが、最初から非常に強力で、プロンプトによるカスタマイズで十分な場合も多いなか、ファインチューニングを検討すべきなのはどのような場合なのでしょうか?
独自のモデルのファインチューニングが適しているのは、(医療分野などで)独自のデータセットに高度な専門性が求められ、汎用モデルでは優れた結果が得られない可能性がある場合や、データでトレーニングされた独自のモデルをホストする必要がある厳格なプライバシー制限がある場合です。
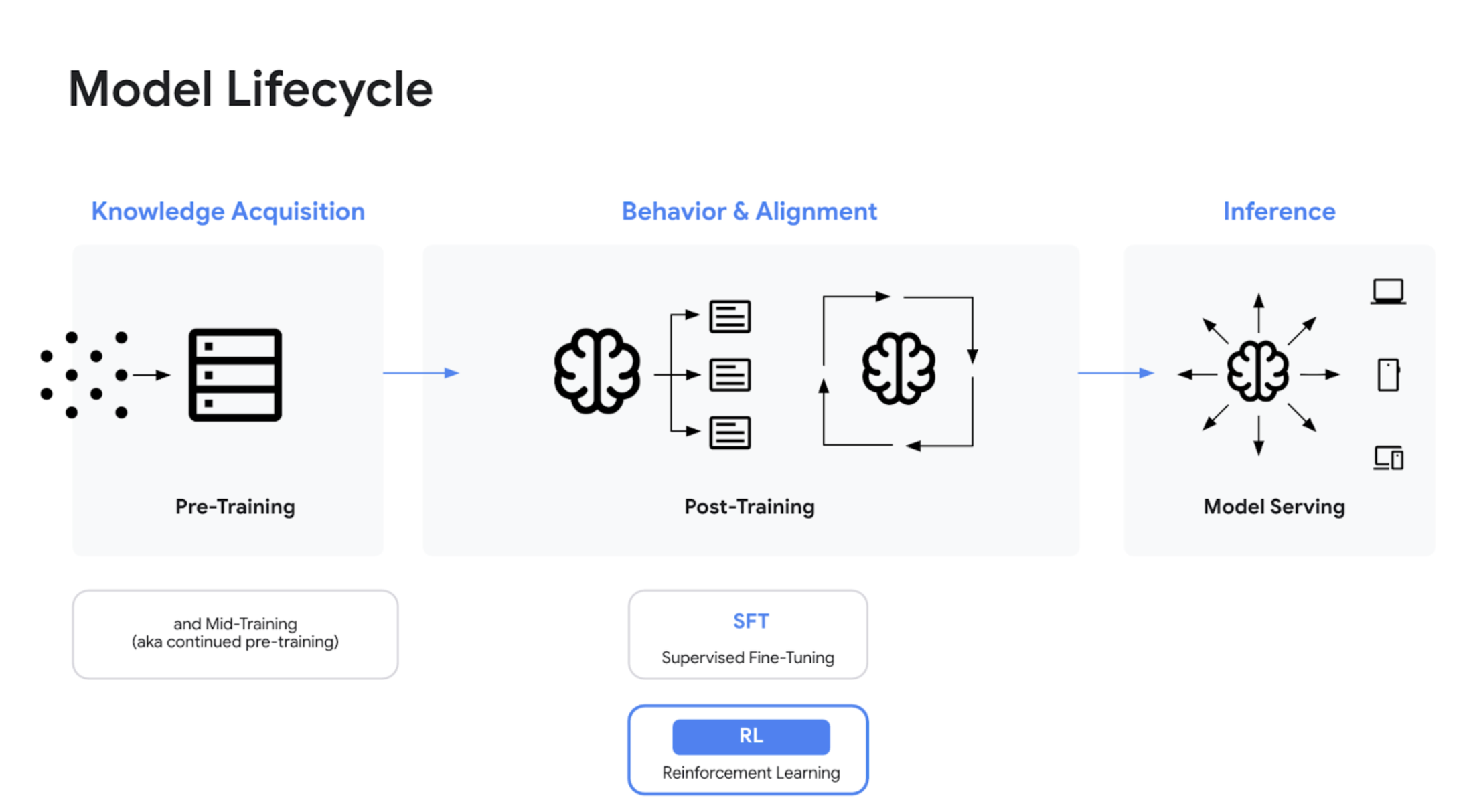
モデルのライフサイクル: 事前トレーニングと事後トレーニング(SFT と RL)
タイムスタンプ: 3:52
Kyle は、Andrej Karpathy の発想から得た素晴らしい例えを使って、トレーニングを段階分けしました。事前トレーニングは「知識の獲得」であり、化学の教科書を読んで物質の仕組みを学ぶようなものだと説明しました。事後トレーニングはさらに、教師ありファインチューニング(SFT)と強化学習(RL)に分けられます。SFT は、教科書の章で解き方がすでに説明されている練習問題を行うのに似ています。RL は、新しい練習問題を自力で解き、問題集の巻末で答えを確認して、最適なアプローチと正解に照らして自分の理解度を測るのに似ています。
強化学習(RL)が不可欠な理由
タイムスタンプ: 5:50
私たちは、最新の LLM を構築するうえで RL が現在非常に重要である理由を探りました。Kyle は、模倣を目的とする SFT とは異なり、RL は「調整」を促進するためにアクションを評価するものだと説明しました。モデルに安全性について教えたり(してはならないことに対してペナルティを与える)、モデルが検索などのツールを使用し、試行錯誤を通じて物理世界とやり取りできるようにしたり、正しい答えにつながる思考の連鎖全体に報酬を与えることで、数学やコーディングなどの検証可能なタスクを実行したりするのに不可欠です。
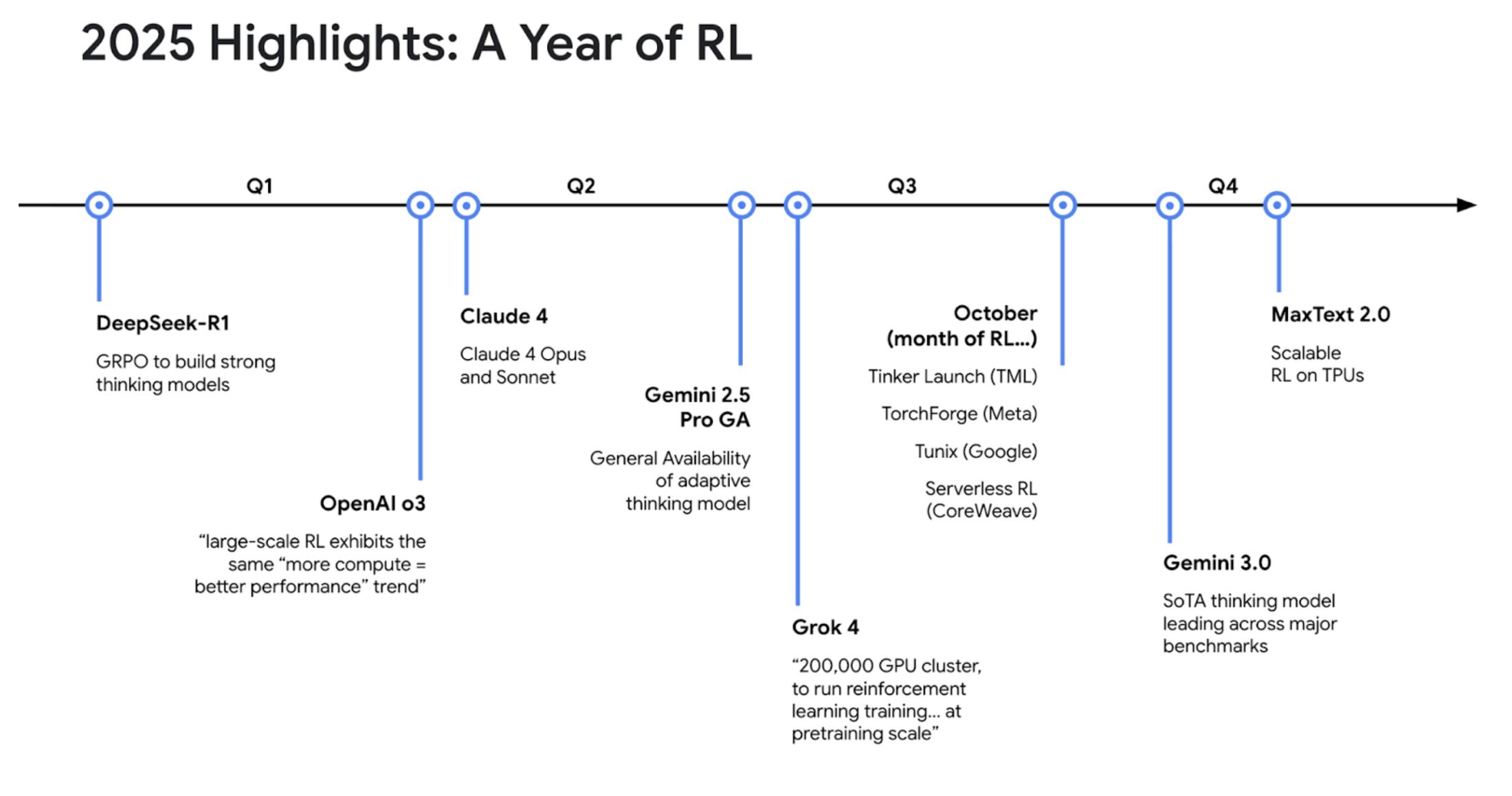
エージェントにまつわる業界の動向: 2025 年が RL の年である理由
タイムスタンプ: 8:33
このセグメントでは、急速に進化する RL の状況を確認しました。Kyle は、2025 年は「RL の年」と言えると述べ、業界全体で投資とリリースが大幅に増加していることを強調しました。
-
1 月: DeepSeek-R1 がリリースされ、オープンソースの GRPO で大きな話題を呼びました。
-
夏: xAI が Grok 4 をリリースしました。RL 用に 20 万個の GPU のクラスタを「事前トレーニングの規模」で実行していると報じられています。
-
10 月: Google、Meta、TML で新しいツールが多数リリースされました。
-
11 月: Gemini 3 が最上位の思考モデルとしてリリースされました。
-
最近: Google が TPU でのファインチューニングに対応する MaxText 2.0 をリリースしました。
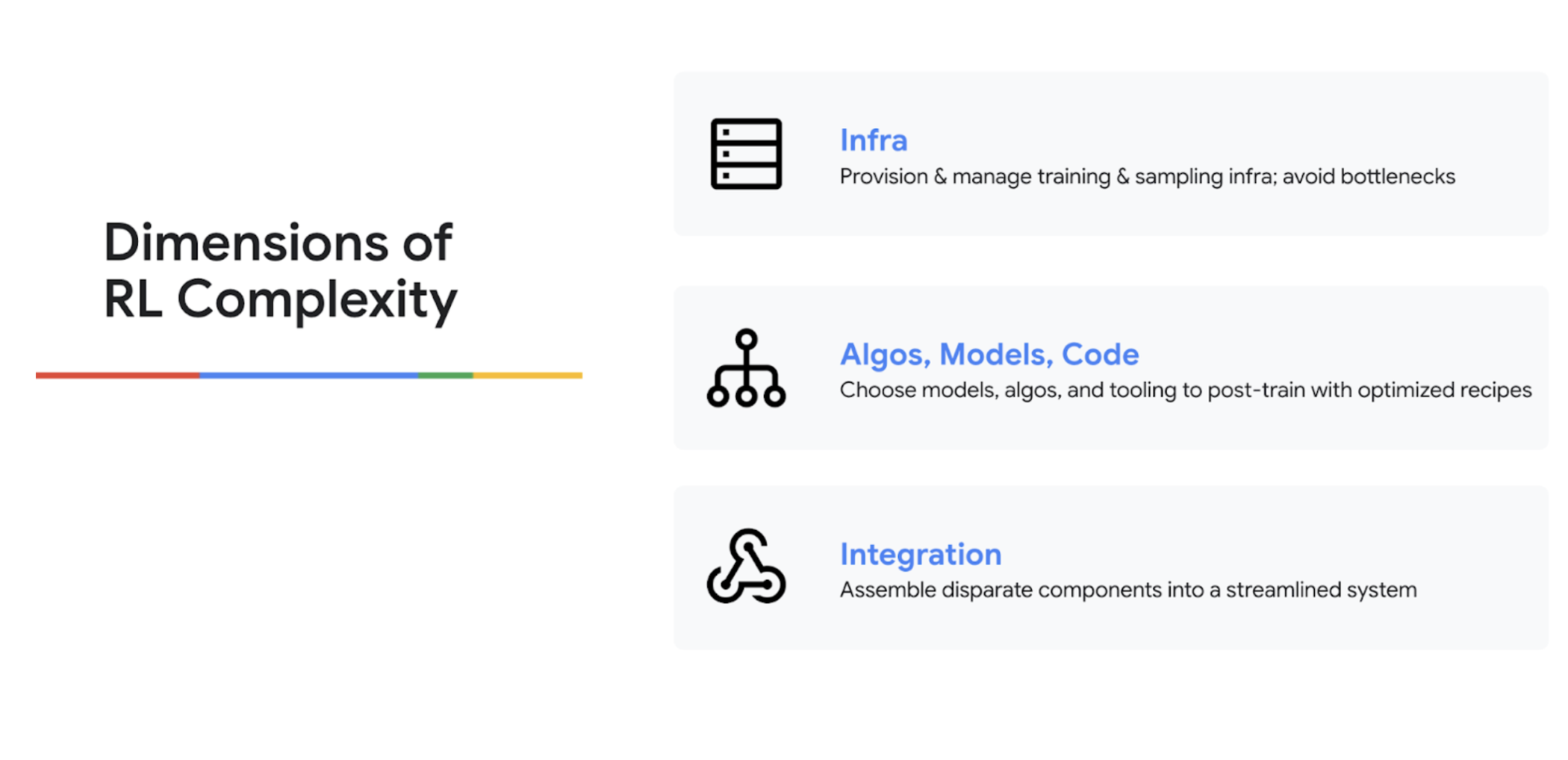
RL の実装におけるハードル
タイムスタンプ: 10:46
業界のトレンドに沿って、RL の実装が非常に難しい理由について話しました。Kyle は、RL はトレーニングと推論の両方の複雑さを 1 つのプロセスに組み合わせたものだと説明しました。3 つの主な課題として、ボトルネックを回避するために適切なバランスと規模でインフラストラクチャを管理すること、適切なコード、モデル、アルゴリズム(GRPO と DPO など)、データを選択すること、そして最後に、トレーニング、推論、オーケストレーション、重み同期のために異なるコンポーネントを統合することの難しさを挙げました。
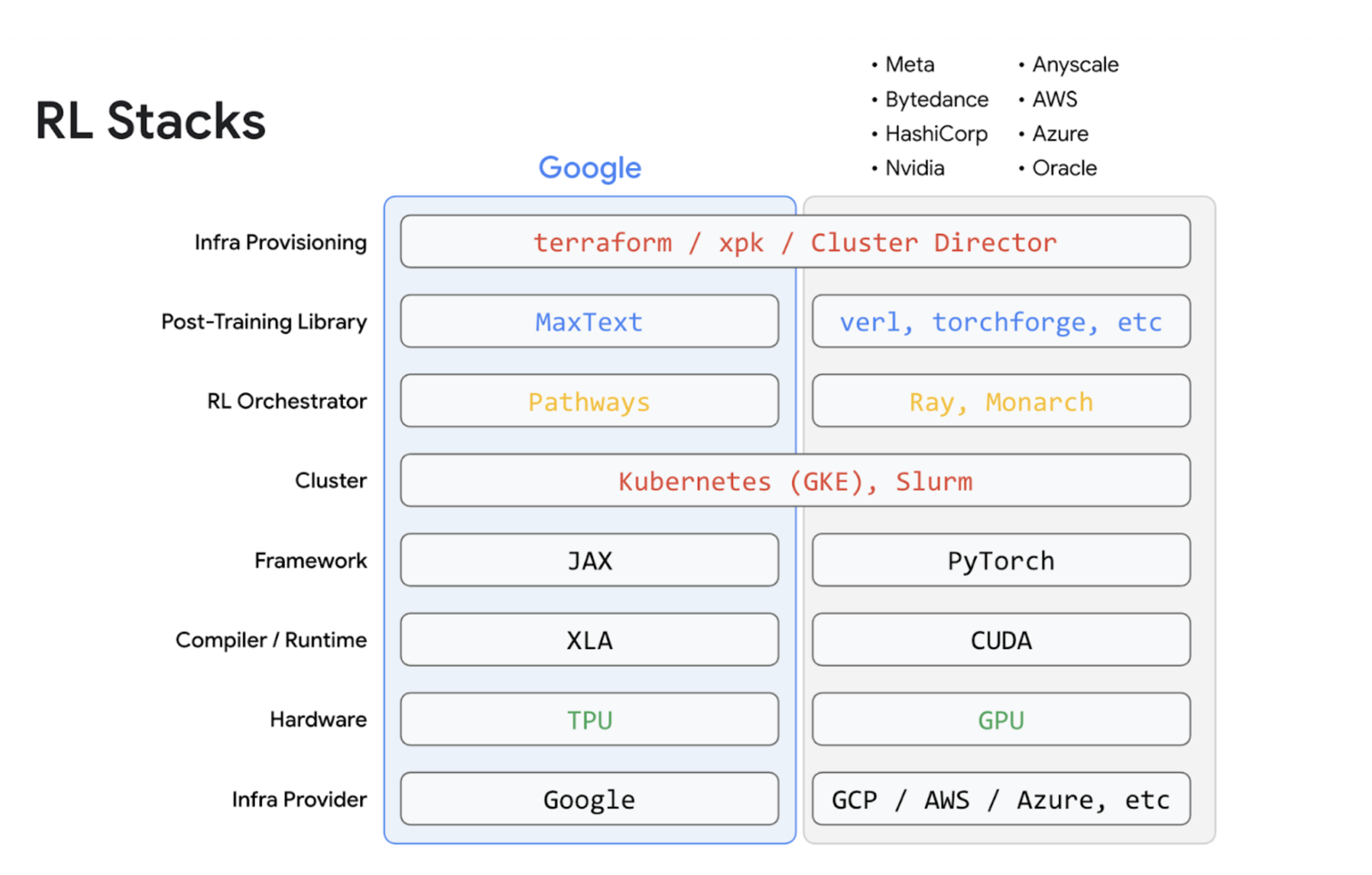
こうした複雑さのあらゆる側面に対応するソリューションとして、Google は MaxText を提供しています。MaxText は、スケーラビリティとパフォーマンスに優れた方法で RL を実行するのに役立つ垂直統合ソリューションです。高度に最適化されたモデル、最新の事後トレーニング アルゴリズム、LLM による高パフォーマンスの推論、Pathways による強力なスケーラビリティと柔軟性を提供します。

ユーザーがさまざまなプロバイダから個別のコンポーネントを組み合わせて独自のスタックを構築する DIY アプローチとは対照的に、Google のアプローチでは、シリコンからソフトウェア、ソリューションまで、共同設計されたコンポーネントの単一の統合スタックが提供されます。
The Factory Floor
「The Factory Floor」は、実践的なセグメントです。ここでは、概念的な内容から一歩踏み込み、実際のコードを使ったライブデモを行いました。
TPU が RL で真価を発揮する理由
タイムスタンプ: 12:52
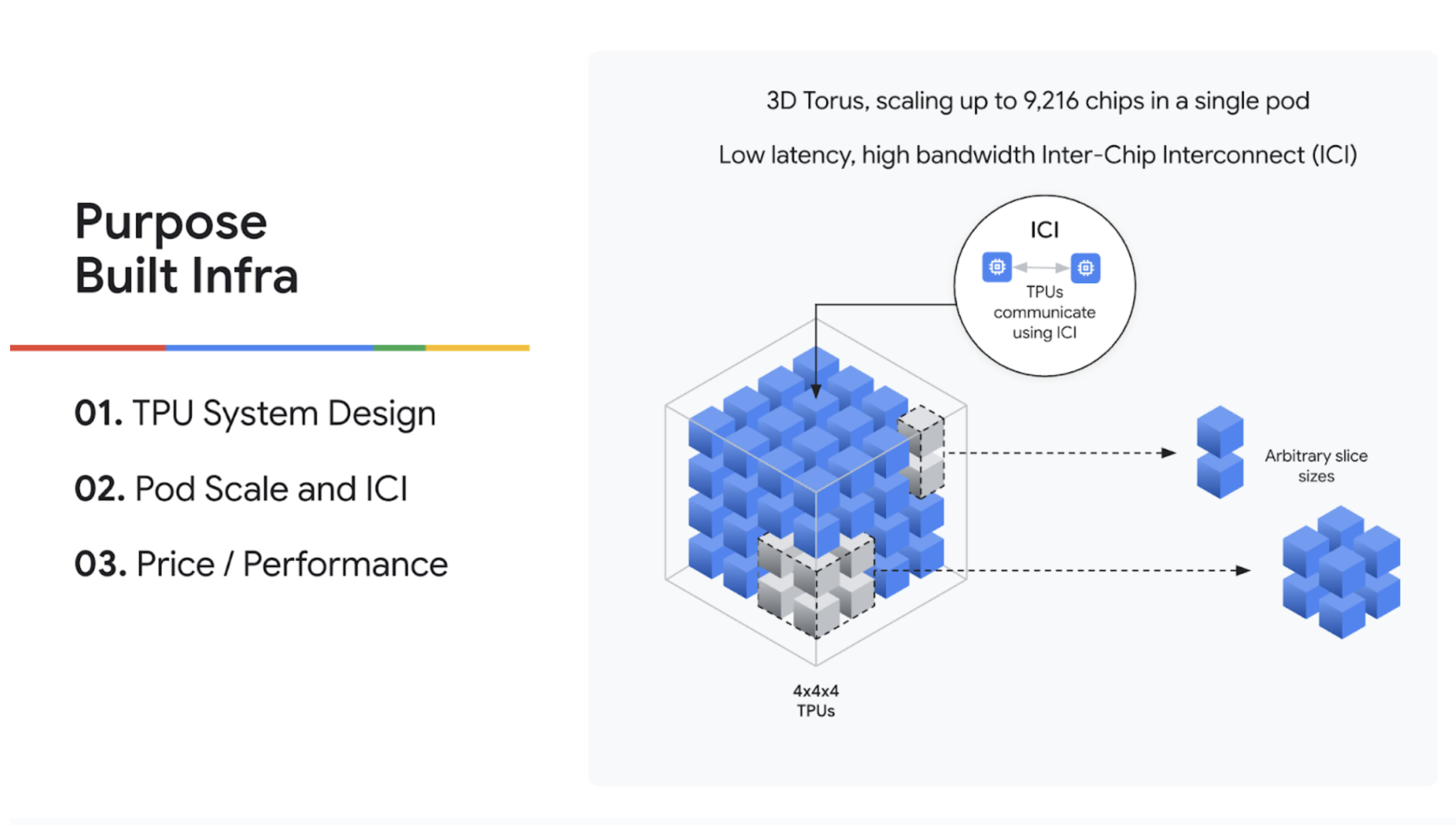
デモに入る前に、TPU が RL のような複雑な AI ワークロードに特に適している理由を Kyle が説明しました。他のハードウェアとは異なり、TPU はシステムを第一に考えて設計されました。TPU Pod は、低レイテンシの相互接続を介して最大 9,216 個のチップを接続できるため、標準的なデータセンター ネットワークに依存することなく大規模なスケールを実現できます。これは、重み同期などの RL のボトルネックを克服するうえで大きな利点となります。さらに、AI 専用に構築されているため、優れたコスト パフォーマンスと熱効率を実現します。
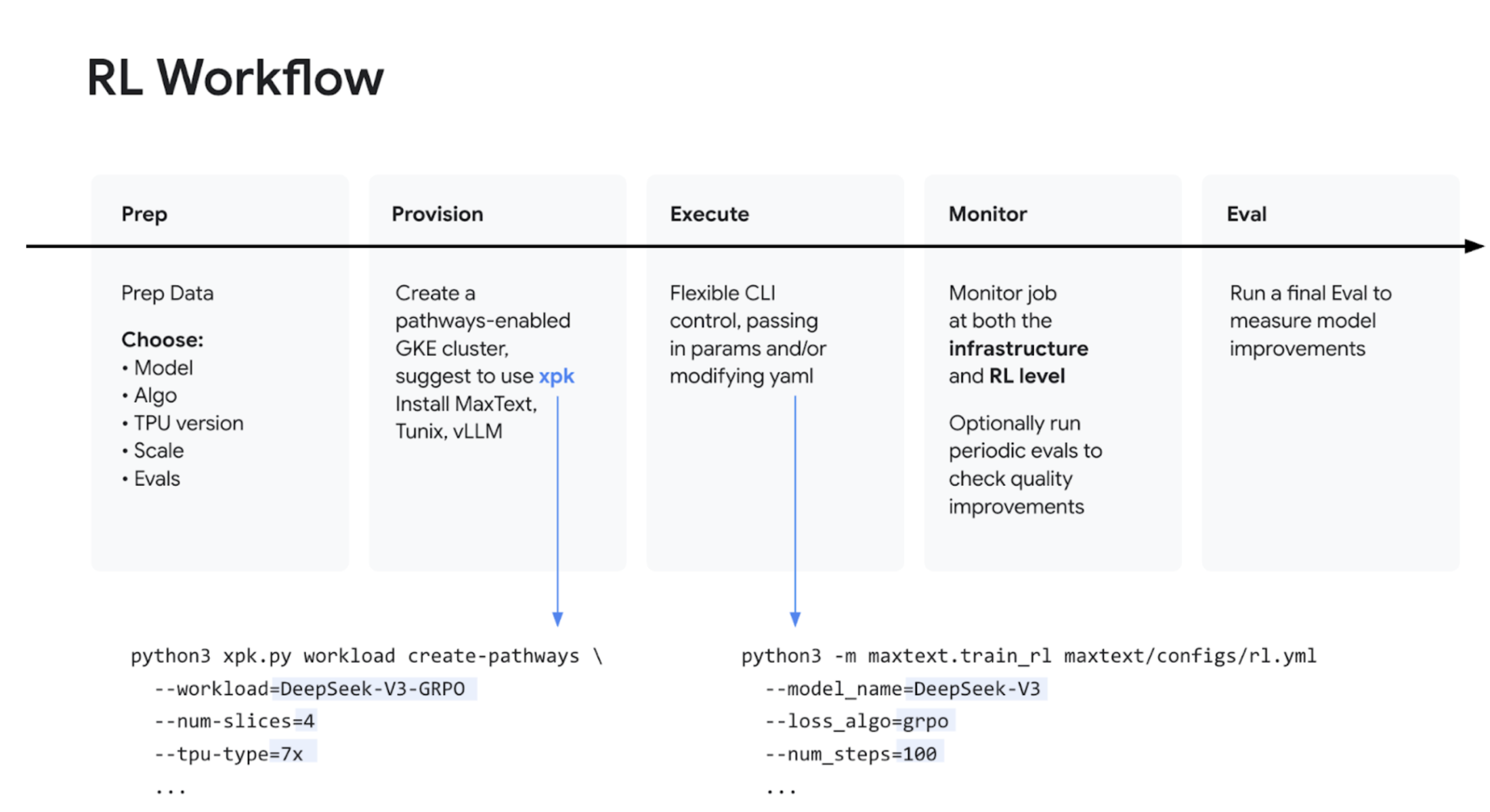
デモ: TPU を使用した強化学習(GRPO)
タイムスタンプ: 15:53
Don は、Google のインフラストラクチャを使用して RL が実際にどのように機能するかを示すハンズオンデモを行いました。デモでは、次の内容を紹介しました。
-
MaxText 2.0 をワークロードの統合ソリューションとして使用する。
-
MaxText のモデルと Tunix のアルゴリズムを活用する。
-
vLLM を使用して推論を処理する。
-
オーケストレーションとスケーリングに Pathways を利用して GRPO(Group Relative Policy Optimization)を実行する。
まとめ
このホリデー スペシャルでは、モデルのファインチューニングの最先端について深く掘り下げました。基盤モデルは日々進化していますが、高度に専門化された高性能なエージェントの未来は、RL などの事後トレーニング手法を習得し、TPU などの適切な垂直統合インフラストラクチャを導入して効率的に実行できるかどうかにかかっています。
構築してみる
このエピソードが、独自の専門エージェントのファインチューニングについて考えるうえで貴重なツールと視点を提供できれば幸いです。以下のリソースで MaxText 2.0 を確認し、ワークロードに TPU を使用してみてください。来年、The Agent Factory の新シーズンでまたお会いしましょう。
関連情報
事後トレーニングのドキュメント https://maxtext.readthedocs.io/en/latest/tutorials/post_training_index.html
-
Google Cloud TPU(Ironwood)のドキュメント: https://docs.cloud.google.com/tpu/docs/tpu7x
-
Google Cloud のオープンソース コード:
-
Andrej Karpathy - 化学の例え: Deep Dive into LLMs like ChatGPT
-
論文:「Small Language Models are the Future of Agentic AI」(Nvidia): https://arxiv.org/abs/2506.02153
-
ファインチューニングに関するブログ記事: https://cloud.google.com/blog/topics/developers-practitioners/a-step-by-step-guide-to-fine-tuning-medgemma-for-breast-tumor-classification?e=48754805
Chrome Enterprise のソーシャル メディア
-
Shir Meir Lador → https://www.linkedin.com/in/shirmeirlador/、X
-
Don McCasland → https://www.linkedin.com/in/donald-mccasland/
-
Kyle Meggs → https://www.linkedin.com/in/kyle-meggs/
- プロダクト DevRel、AI 責任者 Shir Meir Lador



