Pokémon GO が数百万ものリクエストへの対応を実現している方法

Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
ポケモンを捕まえたことはありますか?Pokémon GO は何百万人もの人がプレイする人気ゲームですが、非常に優れたスケーラビリティを実現しています。このブログでは、Pokémon GO のエンジニアリング チームがどのようにこの大規模なサービスを管理し、維持しているのか、その舞台裏を紹介しています。Niantic Labs のシニア エンジニアリング マネージャーで、 Pokémon GO のサーバー インフラストラクチャ チームを率いる James Prompanya 氏に、この大人気ゲームを支える アーキテクチャについてお話を伺いました。動画をご覧ください。
Priyanka: Pokémon GO とは?
James: これは典型的なモバイルゲームではありません。これは現実の世界で自分の周りに現れる小さなポケモンという生きものを捕まえるために歩き回るゲームであり、外に出て、探索し、拡張現実を使ってさまざまなものを発見することを後押しするゲームです。
コミュニティとしての側面はこのゲームの大きな部分を占めています。発売当初は、まだコミュニティ機能が搭載されていませんでした。しかし、プレイヤーの皆さんは、現実に他の人と会って一緒にプレイしたり、レアで強力なポケモンの出現を指摘したりしていました。誰もが同じポケモンを見て、同じ仮想世界を共有しているので、ポケモンが出現したことを誰かが報告すると、大勢の人がそれを急いで追いかけます。現在では、コミュニティ機能は、 コミュニティ デイやレイドアワーなどのライブイベントを開催したり、夏の恒例行事であり、年間最大のイベントである GO Fest を開催することでゲームの主要な部分を占めるようになってきました。
このようなイベントでは、リージョンがオンラインになると同時に、1 秒間に 40 万件だったトランザクションが数分で 100 万件近くになります。
Priyanka: Pokémon GO Fest のようなイベント時のトラフィックのピークに対応するにあたって、Pokémon GO バックエンドのスケーリングはどのように実現しているのでしょうか?
James: 当社でスケーリングを利用しているサービスはたくさんありますが、Google Kubernetes Engine と Cloud Spanner が主なものです。当社のフロントエンド サービスは GKE でホストされていますが、ノードをスケールするのはとても簡単です。Google Cloud が Kubernetes クラスタの管理に必要なすべてのツールを提供してくれるからです。Google Cloud Console は使いやすく、数回クリックするだけで詳細なモニタリング グラフやツール、ロギングを利用できます。Google のエンジニアのサポートは最高で、いつでもサポートしてくれますし、Pokémon GO Fest のような大きなイベントに向けての準備もしてくださります。 このような大規模なイベントを運営するうえでの問題に備え、Google のエンジニアが(仮想的に)席を並べて作業に携わってくれました。私たちにとってまるでサポートチームと直接一緒に働いているようでした。
トラフィックの処理用に常時稼働している約 5,000 台の Spanner ノードに加え、Pokémon GO 専用の数千の Kubernetes ノードと、ゲーム体験をより優れたものにするためのさまざまなマイクロサービスを実行している GKE ノードもあります。それらが一体となって、世界中でプレイする何百万人ものプレイヤーをサポートしています。また、他の多人数同時参加型オンライン ゲームとは異なり、すべてのプレイヤーが 1 つの「レルム」を共有しているため、常にお互いに影響し合い、同じゲーム ステータスを共有できます。
Priyanka: 当初から Spanner を使っていたのでしょうか?それとも、ゲームの人気が出てきたときに、アーキテクチャを変更する判断をしたのでしょうか?
James: まずは Google Datastoreを使ってみました。インフラストラクチャの管理に煩わされることなく、簡単に始めることができました。ゲームが成熟してくると、データベースのサイズと規模をさらにコントロールする必要があると考えました。また、Cloud Spanner が提供する整合性のあるインデックスが気に入っています。これにより、主キーと副キーを持つより複雑なデータベース・スキーマを使用できます。
最後に、Datastore はアトミックで耐久性のあるトランザクションを持つ非リレーショナル データベースですが、当社は完全な整合性を持つリレーショナル データベースを必要としていました。Spanner はこれらすべてに加えて、グローバルな ACID トランザクションを提供します。
Priyanka: 私がプレイヤーで、今、ゲームをプレイしているとします。ポケモンを捕まえるためにアプリを開きました。裏で何が起きていて、リクエストの流れはどうなっているのでしょうか?
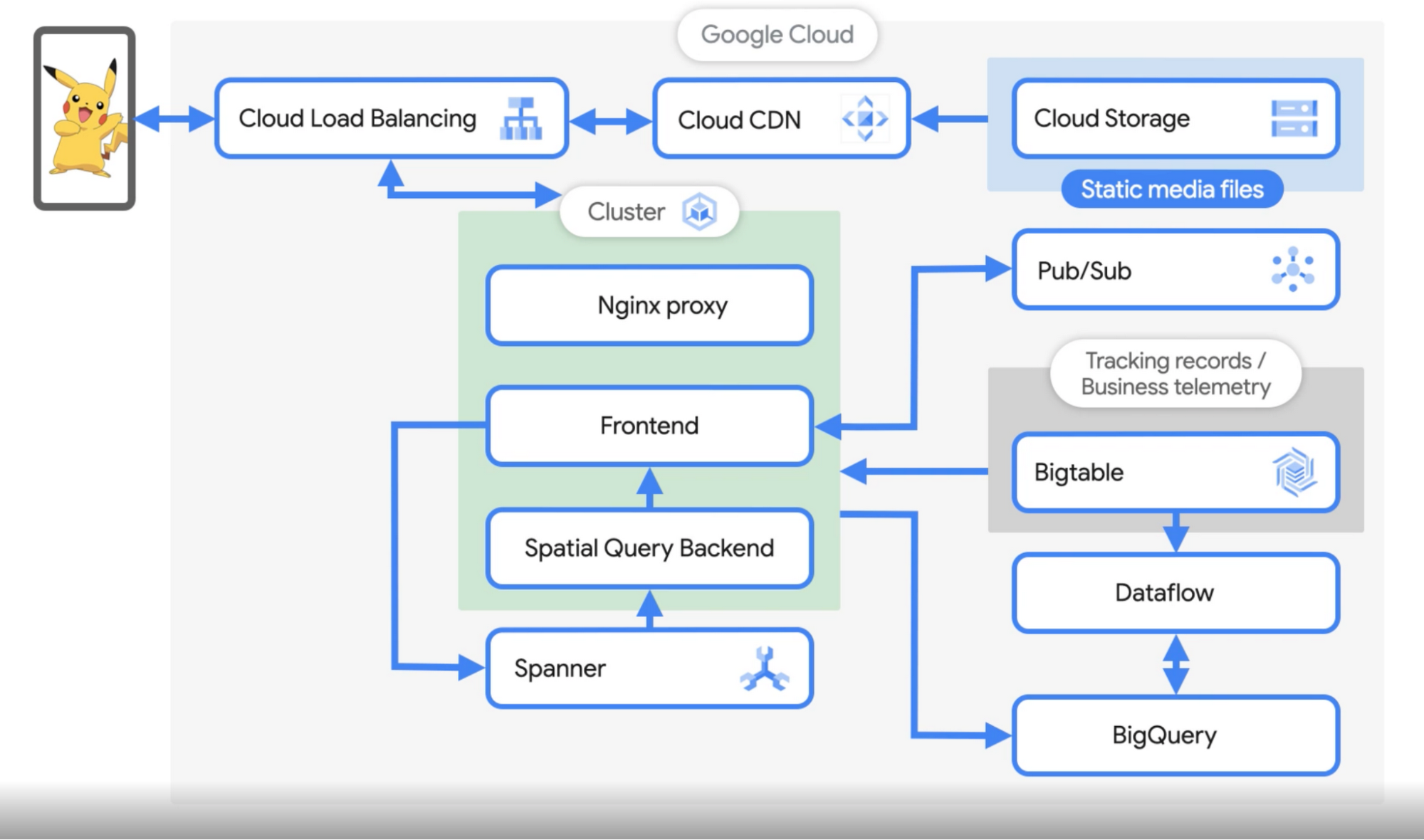
James: ユーザーがポケモンを捕まえると、そのリクエストを Cloud Load Balancingで受け取ります。Cloud Storage に保存されているすべての静的メディアは、アプリの初回起動時にスマートフォンにダウンロードされます。 また、このコンテンツをキャッシュに保存して提供するために、Cloud Load Balancing レベルで Cloud CDN を有効にしています。まず、ユーザーのスマートフォンからのトラフィックがグローバル ロードバランサに到達し、そこから NGINX リバース プロキシにリクエストが送られます。リバース プロキシは、このトラフィックをフロントエンドのゲームサービスに送ります。
クラスタの 3 番目のポッドは空間クエリ バックエンドです。このサービスは、ロケーションごとにシャーディングされたキャッシュを保持しています。このキャッシュとサービスが、地図上に表示されるポケモン、ユーザーの周りにあるジムやポケストップ、ユーザーがいる場所のタイムゾーンなど、基本的に位置情報に基づいたあらゆる機能の動作を決定します。フロントエンドはプレイヤーとそのゲームとのインタラクションを管理し、空間クエリ バックエンドはマップを処理する、と考えてもらっていいと思います。 フロントエンドは、空間クエリ バックエンドのジョブから情報を取得し、ユーザーに返信します。
Priyanka: ポケモンを追い詰めて捕まえるとどうなりますか?
James: ポケモンを捕まえると、GKE のフロントエンドは API 経由で Spanner にイベントを送り、フロントエンドから Spanner への書き込み要求が完了します。ジムやポケストップなど、マップを更新するような操作をすると、そのリクエストによってキャッシュ更新が送信され、空間クエリ バックエンドに転送されます。
Spanner には結果整合性があります。更新を受信すると、空間データはメモリ内で更新され、その後、フロントエンドからの将来のリクエストに対応するために使用されます。そして、フロントエンドは、空間クエリ バックエンドから情報を取得し、ユーザーに送り返します。また、ユーザーの各アクションの protobuf 表現をBigtable に書き込み、厳格な保持ポリシーの下でデータをロギングし、追跡しています。さらに、フロントエンドからのメッセージを解析パイプラインに使用される Pub/Subトピックにパブリッシュします。
Priyanka: 同じリージョンにいる二人が同じポケモンのデータを見て、それを相対的に同期させるにはどうすればよいですか?(特にイベントの場合)
James: それはとても興味深いです。当社のサーバー上のすべてのものは確定的です。そのため、複数のプレイヤーが別々のマシンを使用していても、物理的に同じ場所にいれば、すべての入力が同じになり、同じポケモンが両方のユーザーに返されることになります。しかし、特にイベントの場合は、キャッシュ保存やタイミングが重要になります。すべてのプレイヤーが世界を共有していると感じるためには、すべてのサーバーが設定変更やイベントのタイミングと同期していることが非常に重要です。
Priyanka: ゲーム中に大量のデータを生成する必要があるはずです。データ分析のパイプラインはどのように機能し、何を分析していますか?
James: その通りです。1 日に 5~10 TB のデータが発生し、そのすべてを BigQuery と Bigtable に格納しています。Bigtableこれらのゲームイベントは、データ サイエンス チームがプレイヤーの行動を分析したり、ポケモンの分布が特定のイベントで想定されるものと一致しているかどうかなどの機能を検証したり、マーケティング レポートを作成したりするために利用されます。
当社は BigQuery を使用しています。スケーラビリティに優れ、フルマネージドなのでデータの構造やテーブルのスキーマをあまり気にせず、分析に集中して複雑なクエリを構築できるからです。クエリしたいフィールドはすべてインデックスに登録されているので、あらゆる種類のダッシュボード、レポート、グラフを構築し、チーム全体で共有できます。データ処理エンジンには Dataflow を使用しているので、Bigtable に格納されたプレイヤーのログを処理するために Dataflow のバッチジョブを実行しています。
また、不正の兆候を探して対応するチート検出のためのストリーミング ジョブもあります。また、世界中のポケストップやジム、生息地の情報を設定するために、OpenStreetMap や米国地質調査所、POI データをクラウドソーシングしている WayFarer など、さまざまなソースから情報を取り込み、それらを組み合わせて世界のライブマップを構築しています。
Priyanka: イベントが増え、トラフィックが毎秒数百万ユーザーになると、このシステムはどのようにスケールするのでしょうか?
James: はい。トランザクションの増加に伴い、データ パイプライン(Pub/Sub、BigQuery ストリーミングなど)など、システム全体の負荷が増加します。Niantic の SRE チームが確認しなければならないのは、これらのイベントに対処できる割り当てがあるかどうかだけです。これらはマネージド サービスであるため、Niantic チームの運用上のオーバーヘッドははるかに少なくて済みます。
Priyanka: これだけのトラフィックがあれば、システムの健全性は非常に重要です。このような大規模なイベントの際、どのようにしてシステムの健全性を監視しますか?
James: 組み込みの Google Cloud Monitoring を利用して、ログの検索やダッシュボードの作成、何か問題が発生した場合のアラート発出を行っています。ログやダッシュボードは非常に充実しており、ゲームのさまざまな側面や健全性をリアルタイムでモニタリングできます。
今後、ジェームズと Pokémon GO のエンジニアリング チームは、マネージド Agones や Game Servers の利用を計画しています。お客様のアーキテクチャの全プレイリストの更新をお楽しみに。
Pokémon GO のアーキテクチャの舞台裏をご紹介しました。GKE と Spanner を使ってどのようにピークに対応しているのか、データ サイエンス チームがどのように BigQuery、BigTable、Dataflow、Pub/Sub を使ってデータ分析を行っているのかについてお話を伺いました。
この話を聞いてどう思われましたか?Twitter @pvergadia でお聞かせください。
- Google デベロッパー アドボケイト Priyanka Vergadia
- Pokémon GO、シニア エンジニアリング マネージャー James Prompanya




