Cloud Spanner の分散結合というマジック
Google Cloud Japan Team
※この投稿は米国時間 2021 年 1 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
リレーショナル データベース管理システムである Cloud Spanner は、リレーショナル結合をサポートしています。Spanner の結合の仕組みは複雑で、その複雑さは、テーブルおよびインデックスがすべてスプリットにシャーディングされていることに起因しています。テーブルやインデックスを構成する各スプリットは特定のサーバーによって管理され、それぞれのサーバーは通常、異なるテーブルに由来する多数のスプリットを管理しています。このシャーディングは Spanner によって管理されており、Spanner の大きな特長であるスケーラビリティを支える重要な機能となっています。では、2 つのテーブルがあり、それぞれが複数のスプリットに分割され、これらのスプリットが異なるマシンによって管理されているような場合に、これらのテーブルを結合するにはどうすればよいでしょうか。このブログ投稿では、分散クロス適用(DCA)演算子を用いた分散結合についてご説明します。
例として、以下のスキーマとクエリを使用します。
テーブルが別のテーブルにインターリーブされていない場合、その主キーは範囲シャーディング キーにもなります。したがって、Albums テーブルのシャーディング キーは(SingerId, AlbumId)になります。以下に、上述のクエリのクエリ実行プランを示します。
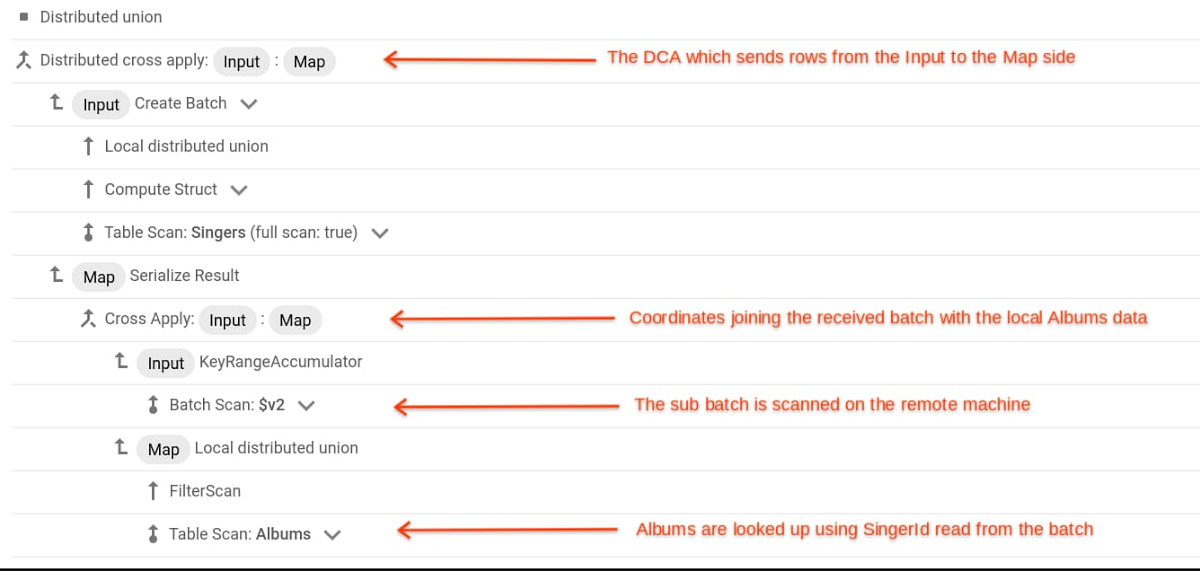
クエリ実行プランの基本的な考え方は次のとおりです。このプラン内の各行は、イテレータです。各イテレータの下にその子が 1 段階インデントして表示されるようなツリー構造となっています。この例でいうと、上から 2 行目の Distributed cross apply というラベルの付いた行に、Create Batch という子と、その 4 行下に Serialize Result という子があります。これらの子から親の Distributed cross apply に向かう矢印をご確認ください。各イテレータは、親に対して GetRow API というインターフェースを提供します。親はこの API 呼び出しを使って、子に対してデータ行を問い合わせることが可能です。ツリーのルートに対する最初の GetRow 呼び出しによって、実行が開始されます。この呼び出しがツリーの下に向かって伝わっていき、リーフノードに到達します。このノードにおいて行がストレージから取得され、取得された行がツリーのルートに向かってさかのぼっていき、最終的にアプリケーションに到達します。行の並べ替えや、2 つの入力ストリームの結合などの処理は、ツリー内の専用ノードにおいて行われます。
結合を実行するには、通常、マシン間で行を移動する必要があります。インデックス ベースの結合の場合、分散クロス適用(DCA)演算子を使って行を移動します。この例のプランを見ていただくと、DCA の子に Input(Create Batch)および Map(Serialize Result)というラベルが付いており、DCA が Input から Map への行の移動を行います。行を結合する実際の処理は Map で行われ、その結果が DCA に戻されて、ツリーの上へと送られます。ここで理解しておかなければならないのは、DCA の子である Map がマシンの境界線になるということです。つまり Map は通常、DCA と同じマシン上にはありません。さらに Map 側だけを見ても、1 つのマシン上にまとまっていないのが普通であり、Map 側のツリー構造(この例では Serialize Result およびその下のすべて)は、一致行を含む可能性のある Map 側テーブルのスプリットごとにインスタンス化されたものとなります。この例でいうと、Albums テーブルがそれに該当します。したがって、Albums テーブルに 10 個のスプリットがあるとすると、Serialize Result をルートとするツリーのコピーが 10 個あり、それぞれのコピーがスプリットを 1 つずつ担当し、各スプリットを管理しているサーバー上で実行されることになります。
Input 側から Map 側への行の送信は、バッチで行われます。この際、DCA は GetRow API を使用して Input 側の行をインメモリ バッファにバッチとしてまとめていき、バッファがいっぱいになった時点で Map 側へと送信します。このバッチ化された行は、送信前に結合列に基づいて並べ替えられます。この例では、Input 側の行はすでに SingerId で並べられているため並べ替えは不要ですが、常にそうであるとは限りません。続けて、バッチがサブバッチ(Map 側のテーブル(Albums)のスプリットごとのサブバッチなど)に分割されます。バッチ内の各行は、それらの行と結合される行を含む可能性がある Map 側スプリットのサブバッチに付け加えられます。バッチを並べ替えておくと、サブバッチへの分割に役立つだけでなく、Map 側でのパフォーマンスも上がります。
実際の結合処理は Map 側で行われ、複数のマシンが、それぞれの管理するスプリットについて受信したサブバッチの結合処理を、平行して同時に行っています。具体的には、受信したサブバッチをスキャンして、その中にある値を使用し、管理対象のデータのインデックス構造の中を検索する、という処理を行います。バッチスキャンの開始から、Albums テーブルの検索まで、一連の処理はプラン内のクロス適用によって制御されます(Filter Scan および Table Scan: Albums というラベルの付いた行をご覧ください)。
入力順序の保持
前述のようなバッチ内での並べ替えやマシン間での行の受け渡しによって、DCA の Input 側でもともと保持していた行の並び順が失われてしまうのではないか、と思った方がいらっしゃるのではないでしょうか。その考えは当たっています。ORDER BY によって順序を指定した場合、どうなるでしょう。これは、ORDER BY に LIMIT 句が付いている場合に、特に重要となってきます。DCA には順序を保持するバリアントがあり、クエリのパフォーマンス向上に役立つと判断された場合、そのバリアントが Spanner によって自動的に選ばれるようになっています。この順序を保持する DCA バリアントでは、子の Input から受信した各行に、受信順を示す番号がタグ付けされます。そして、サブバッチ内の行が結合結果を生成したときに、元の順序に再び並べ変えられるという仕組みになっています。
左外部結合
外部結合を行う場合はどうすればよいでしょうか。このクエリの例でいうと、アルバムを出していない歌手も含め、すべての歌手をリストするとします。この場合、クエリは以下のようになります。
分散外部適用(DOA)と呼ばれる、基本的な DCA の代わりとなるバリアントがあります。これは DCA と同じものですが、外部結合のセマンティクスを提供するという特長があります。
詳細
Spanner の利用を開始するには、インスタンスを作成するか、Spanner Qwiklabs でお試しください。
-Google Spanner ソフトウェア エンジニア Campbell Fraser
