Vertex AI でのデュアル デプロイ
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
この投稿では、Kubeflow、TensorFlow Extended(TFX)、Vertex AI を使用して、デュアルモデルのデプロイ シナリオを可能にするエンドツーエンドのワークフローをご紹介します。まずプロジェクトの背後にある目的、次にこのプロジェクトの一部として実現したアプローチ、最後に各アプローチの料金内訳を説明します。この投稿ではコード スニペットとコードレビューの詳細までは説明しませんが、こちらの GitHub リポジトリでコード全体をいつでもご確認いただけます。
この投稿の内容を十分に理解していただくには、TFX、Vertex AI、Kubeflow の基本的な知識が必要になります。TensorFlow と Keras も主要なディープ ラーニング フレームワークとして使用するため、多少の知識があると役立ちます。
目的
シナリオ 1(オンライン予測 / オフライン予測)
オンライン モードとオフライン モードの両方でユーザーによるアプリケーション実行を許可するとします。モバイル アプリケーションでは、ネットワーク帯域やバッテリーなどに応じた TensorFlow Lite(TFLite)モデルが使用されます。また、十分なネットワーク カバレッジやインターネット帯域を使用できる場合、アプリケーションでは代わりにオンラインのクラウドモデルが使用されます。このようにして、アプリケーションの復元性と高可用性が確保されます。
シナリオ 2(階層型の予測)
階層型の予測を行う場合もあり、まず問題を次のような小さなタスクに分けます。
1)Yes/No 型であるかを予測、2)1)の結果によって最終モデルを実行。
これらのケースについて、スムーズなユーザー エクスペリエンスを確保するため、1)はデバイス上で行われ、2)はクラウド上で行われます。さらに、モバイル デプロイを検討している場合は、モバイル対応のネットワーク アーキテクチャ(MobileNetV3 など)を使用することをおすすめします。この状況の詳細な分析は、ML Design Patterns という書籍で説明されています。
上記の説明から次の疑問が生じます。
同じデプロイ パイプライン内で 2 つの異なるモデルをトレーニングし、シームレスに管理できるでしょうか。
このプロジェクトはこの課題が原動力になっています。この投稿では、このようなパイプラインを自己完結型のシームレスな方法で運用するために導入した、さまざまなコンポーネントについて説明します。
データセットとモデル
このプロジェクトでは Flowers データセットを使用します。これは、5 つのクラス(デイジー、タンポポ、バラ、ヒマワリ、チューリップ)に分類された 3,670 の花のサンプルから構成されます。つまり、花の分類モデルの構築がタスクであり、このケースでは基本的にマルチクラスの分類となります。
前述のように、2 つの異なるモデルを使用します。1 つのモデルは、クラウド上にデプロイされ、REST API 呼び出しを介して使用されます。もう 1 つのモデルは、スマートフォン内にあり、モバイル アプリケーションによって使用されます。最初のモデルでは、DenseNet121 を使用し、モバイル対応のモデルでは、MobileNetV3 を使用します。転移学習を活用し、モデルのトレーニング プロセスを高速化します。こちらのノートブックでトレーニング パイプライン全体を学ぶことができます。
一方、同じワークフローに AutoML ベースのトレーニング パイプラインも利用します。ここで特定のタスクについて、事前構成済みのコンピューティング予算内での最適なモデルが、ツールによって自動的に検出されます。ただし、このケースでデータセットは同じままです。AutoML ベースのトレーニング パイプラインは、こちらのノートブックで確認できます。
アプローチ
それぞれの組織には、さまざまな技術的背景を持つ人員がいます。まず最も簡単なソリューションを提供し、続いてさらにカスタマイズ可能なソリューションの提供を目指しました。
AutoML
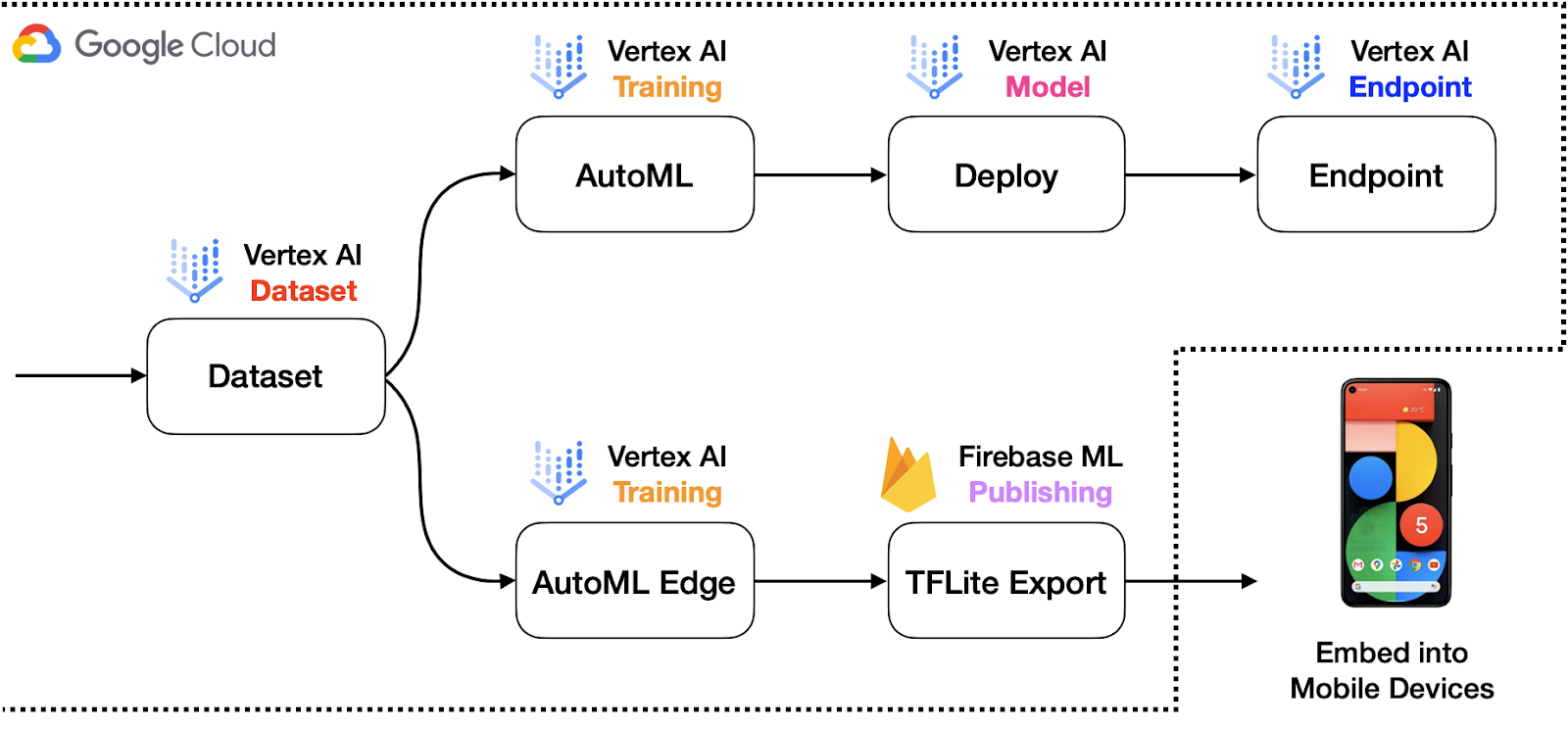
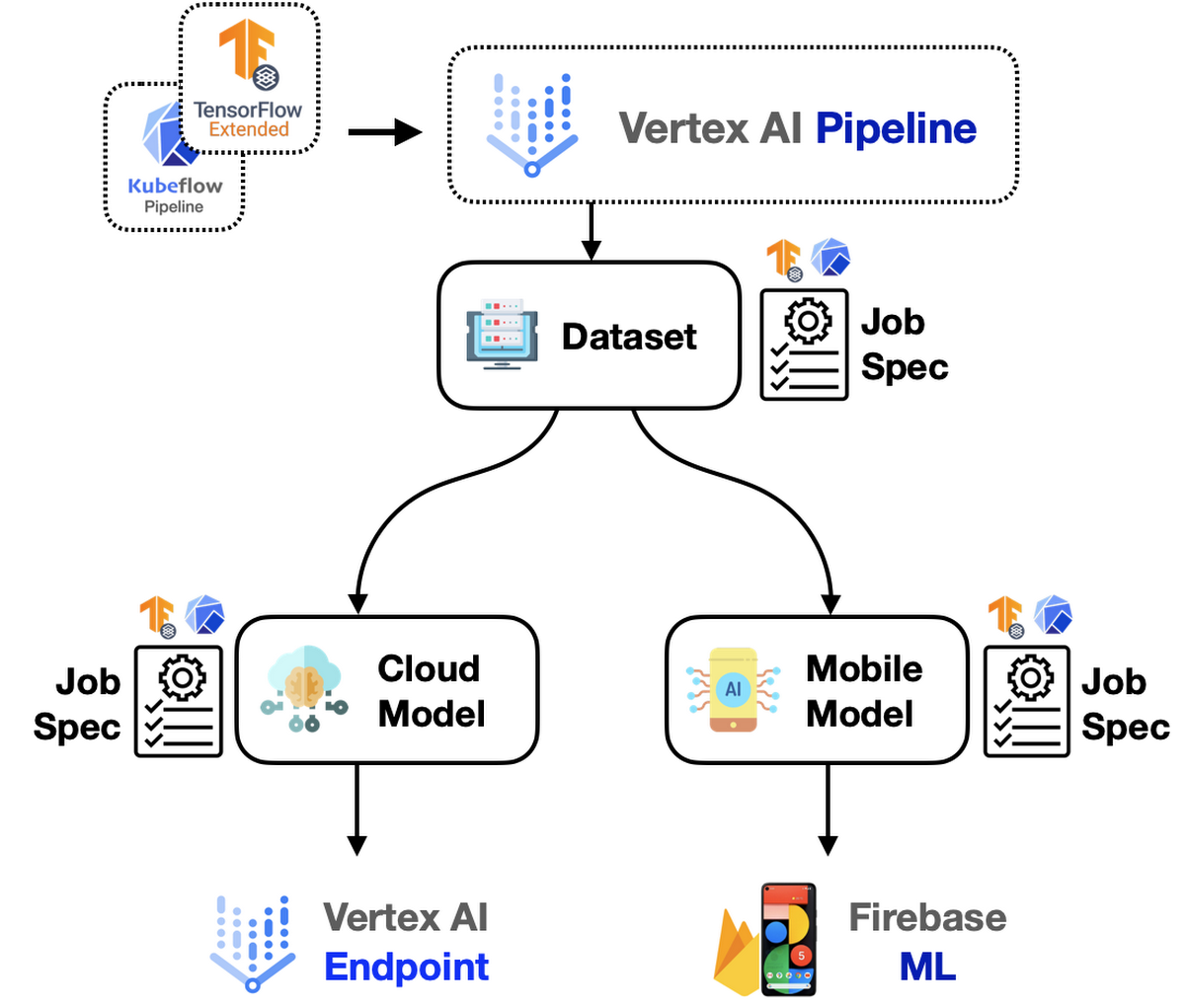
この目的のため、Google Cloud パイプライン コンポーネント ライブラリからの標準コンポーネントを活用し、さまざまな本番環境のユースケースを有するモデルを構築、トレーニング、デプロイします。AutoML を使用することで、開発者はワークフローの大部分を SDK に委任でき、コードベースも比較的小さく維持できます。図 1 は、このシナリオのシステム アーキテクチャのサンプルを示しています。
参考として、画像分類からオブジェクト トラッキングまで、Vertex AI でサポートされている多くのタスクがあります。
TFX
ただし、話はここで終わりません。モデルの構築、トレーニング、デプロイをより適切に制御するにはどうすればいいいでしょうか。そこで TFX の出番です。TFX によって、カスタム コンポーネントを柔軟に記述し、パイプライン内に追加できます。そして、機械学習エンジニアは得意なモデルの構築とトレーニングに集中でき、手間のかかる作業の一部を TFX と Vertex AI に任せることができます。Vertex AI(オーケストレーターとして機能)で、このパイプラインは次のようになります。
上記の両方のアプローチで Fiberbase が使用されているのはなぜかと思われるかもしれません。モバイル アプリケーションで使用されるモデルについては、モバイル プラットフォームとの多大な相互運用性のため、TFLite モデルである必要があります。Firebase では、カナリア ロールアウト、A/B Testing など、TFLite モデル用の優れたツールとインテグレーションが提供されます。Firebebase で TFLite デプロイを強化する方法については、こちらのブログ投稿でご確認いただけます。
ここまでで、このプロジェクトで行われているアプローチに関するアイデアを簡単に説明しました。次のセクションでは、機能させるために調整しなければならなかったコードとさまざまな基本事項について、さらに詳しく見ていきます。以降のセクションで示されるすべてのコードについては、こちらでご確認いただけます。
実装の詳細
このプロジェクトでは、AutoML ベースの最小限のコードと TFX ベースのカスタムコードという 2 つの別々の設定を使用しているため、このセクションを 2 つに分けています。まず、AutoML の方を紹介し、続いて TFX に進みます。どちらの設定でも、同様の結果が生み出され、同一の機能が実装されます。
Kubeflow の AutoML コンポーネントを使用した Vertex AI Pipelines
Google Cloud パイプライン コンポーネント ライブラリには、Vertex AI に組み込みのサービスをサポートする、事前定義済みのさまざまなコンポーネントが備わっています。たとえば、Vertex AI のマネージド データセット機能から直接データセットをパイプラインにインポートできます。また、Vertex AI のトレーニング機能に委任するモデル トレーニング ジョブを作成できます。ノートブック全体でこのセクションの残りの部分をご確認いただけます。このプロジェクトでは次のコンポーネントが使用されます。
ImageDatasetCreateOp を使用して、次のコンポーネント AutoMLImageTrainingJobRunOp に挿入されるデータセットを作成します。Vertex AI のすべての種類のデータセットがサポートされています。import_schema_uri 引数により、ターゲット データセットのタイプが決まります。たとえば、このプロジェクトについては multi_label_classification に設定されます。
AutoMLImageTrainingJobRunOp は、モデル トレーニング ジョブを特定の構成の Vertex AI Training に委任します。AutoML モデルは非常に大きく拡張できるため、budget_milli_node_hours 引数と model_type 引数を使用して制約を設定できます。budget_milli_node_hours では、トレーニングで許可される時間数、model_type では、トレーニング ジョブのターゲット環境およびトレーニング済みモデルのフォーマットが指定されます。AutoMLImageTrainingJobRunOp のインスタンスが 2 つ作成されており、それぞれの model_type は「CLOUD」と「MOBILE_TF_VERSATILE_1」に設定されています。このように、文字列パラメータ自体で内容が表されています。他のオプションもありますので、API の公式ドキュメントをご覧ください。
ModelDeployOp は 1 つの場所で 3 つのジョブを実行します。トレーニング済みモデルの Vertex AI モデルへのアップロード、エンドポイントの作成、トレーニング済みモデルのエンドポイントへのデプロイを行います。ModelDeployOp を使用すると、クラウドに簡単かつ迅速にモデルをデプロイできます。一方、ModelExportOp は、トレーニング済みモデルを GCS バケットなどの指定の場所にのみエクスポートします。モバイルモデルはクラウドにはデプロイされないため、保存されたモデルを明示的に取得する必要があり、デバイスに直接組み込むか、Firebase ML にパブリッシュできるようにします。
トレーニング済みモデルをオンデバイス モデルとして作成するには、export_format_id を ModelExportOp で適切に設定する必要があります。使用できる値は「tflite」、「edgetpu-tflite」、「tf-saved-model」、「tf-js」、「core-ml」、「custom-trained」です。このプロジェクトでは「tflite」に設定されます。
これら 4 つのコンポーネントを使用して、データセットの作成、AutoML でのクラウドとモバイルモデルのトレーニング、トレーニング済みモデルのクラウドへのデプロイ、.tflite の形式のファイルへのトレーニング済みモデルのエクスポートを行うことができます。最後に、エクスポートされたモデルをモバイル アプリケーション プロジェクトに組み込みます。ただし、アプリケーションをコンパイルし、毎回マーケットプレイスにアップロードする必要があるため、これは柔軟ではありません。
Firebase
他の方法として、トレーニング済みモデルを Firebase ML にパブリッシュできます。Firebase ML の詳細については説明しませんが、基本的に、アプリケーションを実行中に機械学習モデルのダウンロードとアップロードが可能となります。これにより、ユーザーの利便性は格段に向上します。パブリッシュ機能をパイプラインに統合するため、KFP ネイティブ用に 1 つ、TFX 用にもう 1 つのカスタム コンポーネントが作成されています。まず KFP ネイティブの場合について説明し、TFX 用のコンポーネントについて次のセクションで説明します。前提として、Fiberbase の公式ドキュメントの「始める前に」のセクションで一般的な手順を必ず確認してください。
このプロジェクトでは、KFP ネイティブ環境用の Python 関数ベースのカスタム コンポーネントが記述済みです。最初に、インストールするパッケージを指定して、@component デコレータで関数をマークします。パイプラインをコンパイルする際に、KFP はこの関数を Docker イメージとしてラップします。つまり、関数内のすべての要素は完全に分離されているため、packages_to_install を介してこの関数が必要とする依存関係について説明する必要があります。
最初の部分は省略されていますが、そこで実行されるのは、firebase_credential_uri と model_bucket のそれぞれからの Firebase 認証ファイルと保存されたモデルのダウンロードです。ダウンロードされたファイルは credential.json と model.tflite という名前が付けられていると想定できます。また、それらのファイルは GCS に保存されていると直接参照できないと確認されたことが、ローカルにダウンロードした理由です。
firebase_admin.initialize_app メソッドにより、指定の認証情報とモデルファイルの一時的な保存に使用される GCS バケットを使用して、Firebase に対する認証が初期化されます。GCS バケットは Firebase に必須であり、Firebase ダッシュボードのストレージ メニュー内に簡単に作成できます。
ml.list_models メソッドにより、Firebase ML にデプロイされたモデルのリストが返され、display_name または tags を使用してアイテムをフィルタできます。この行の目的は、同じ名前のモデルがすでにデプロイされているかを確認することです。これは、すでにモデルが存在する場合には新たに作成するのではなく、そのモデルを更新しなければならないからです。
更新と作成のルーティンには 1 つの共通点があります。それは、ml.TFLiteGCSModelSource.from_tflite_model_file メソッドを呼び出すことで、ローカルモデル ファイルを GCS の一時バケットにアップロードする読み込みプロセスです。読み込みプロセスの後、ml.create_model メソッドまたは ml.update_model メソッドのいずれかを選択します。これで、ml.publish_model メソッドを使用したモデルをパブリッシュできます。
統合する
カスタム コンポーネント push_to_firebase を含め、5 つのコンポーネントについて説明しました。これらのコンポーネントをまとめて接続する方法を示すパイプラインについての説明に入ります。まず、各デプロイ用に 2 つの異なるセットの構成が必要です。それらはハードコード化できますが、以下のようなディクショナリのリストを指定する方がはるかに適切です。
個々のコンポーネントとその機能を認識できる必要があります。ここで注目する必要があるのは、コンポーネントの接続方法、各デプロイ用の並列ジョブの作成方法、各デプロイメント固有のジョブを処理する条件付きブランチの作成方法です。
このように、push_to_firebase 以外の各コンポーネントには、以前のコンポーネントの出力から入力を取得する引数があります。たとえば、AutoMLImageTrainingJobRunOp は、dataset パラメータに基づいてモデルのトレーニング プロセスを起動し、その値は ImageDatasetCreateOp. の出力から挿入されます。
ModelExportOp コンポーネントと push_to_firebase コンポーネントとの間になぜ依存関係がないのかと思われるかもしれません。これは、エクスポートしたモデルの GCS ロケーションが、ModelExportOp. の artifact_destination パラメータを使用して手動で定義されるためです。そのため、同じ GCS ロケーションを push_to_firebase コンポーネントに手動で渡すことができます。
@kfp.dsl.pipeline デコレータにより定義されたパイプライン関数を使用して、kfp.v2.compiler.compile メソッドによるパイプラインをコンパイルできます。コンパイラは、パイプライン作成方法のすべての詳細を JSON 形式のファイルに変換します。異なるバージョンを管理する場合は、JSON ファイルを GCS バケット内に安全に保存できます。実際のパイプライン作成のコードをバージョン管理しないのはなぜでしょうか。それは、kfp.v2.google.client.AIPlatformClient の create_run_from_job_spec method を使用して JSON ファイルを参照するだけで、パイプラインを実行できるためです。
TFX のビルド済みコンポーネントとカスタム コンポーネントを使用した Vertex AI Pipelines
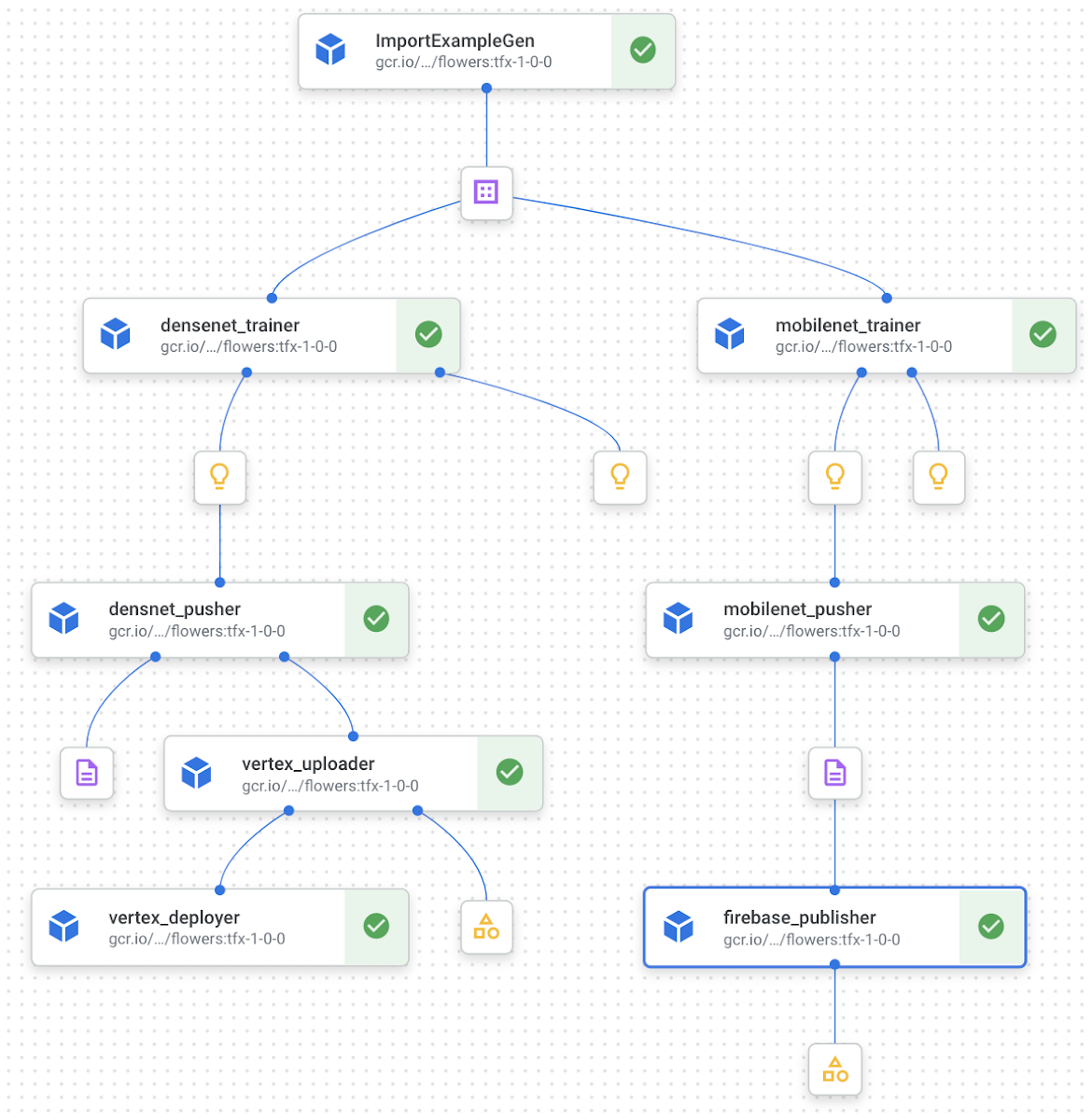
TFX には多数の有用なコンポーネントが組み込まれていますが、それらは機械学習プロジェクトをエンドツーエンドでオーケストレートするためにきわめて重要です。こちらで TFX で提供される標準コンポーネントのリストをご確認いただけます。このプロジェクトでは、次の既存の TFX コンポーネントを活用します。
● Trainer
● Pusher
ImportExampleGen を使用して、Google Cloud Storage(GCS)バケットから TFRecords を読み取ります。Trainer コンポーネントはモデルをトレーニングし、Pusher はトレーニング済みモデルを事前に指定済みの場所(このケースでは GCS バケット)にエクスポートします。このプロジェクトの目的のため、データの前処理の手順はトレーニング コンポーネント内で実行されますが、TFX にはデータの前処理についてのトップクラスのサポートが備わっています。
注: Vertex AI を使用してパイプライン全体をオーケストレートするため、ここでの Trainer コンポーネントは、tfx.extensions.google_cloud_ai_platform.Trainer です。このコンポーネントを使用すると、Vertex AI のサーバーレス インフラストラクチャを活用してモデルをトレーニングできます。
図 1 と図 2 で示したように、モデルはトレーニングされた後に、1)エンドポイント(後で詳しく説明します)と 2)Firebase という 2 つの異なるパスに進む必要があります。つまり、モデルのトレーニングと push 後に、次の操作が必要です。
1. いずれかのモデルを Vertex AI にエンドポイントとしてデプロイし、REST API 呼び出しで利用できるようにします。
Vertex AI を使用してモデルをデプロイするには、モデルが存在しない場合にはまずモデルをインポートする必要があります。
適切なモデルをインポートした後(または識別した後)で、エンドポイントにデプロイする必要があります。エンドポイントには、異なるモデルをバージョン管理する柔軟な方法が備わっており、本番環境のライフサイクル全体でデプロイできます。
2. Firebase に他のモデルを push し、モバイル デベロッパーがアプリケーションを構築するために使用できるようにします。
これらの要件に従って、次のような最低限 3 つのカスタム コンポーネントを開発する必要があります。
● 事前トレーニング済みモデルとして入力を受け取り、Vertex AI にインポートするコンポーネント(VertexUploader)。
● エンドポイントへのデプロイを行うコンポーネント(存在しない場合は自動的に作成されます)(VertexDeployer)。
● Firebase にモバイル対応モデルを push するコンポーネント(FirebasePublisher)。
それぞれの主要コンポーネントを 1 つずつ見ていきましょう。
モデルのアップロード
Vertex AI の Python SDK を使用して、Vertex AI で選択したモデルをインポートします。そのためのコードはごく簡単なものです。
vertex_ai.Model.upload() のさまざまな引数については、こちらをご覧ください。これをカスタム TFX コンポーネントに変換するには(パイプラインの一部として実行されるように)、Python 関数の中にこのコードを挿入し、componentデコレータを使用して修飾する必要があります。
endpoint.deploy() の内部で使用されるさまざまな引数は、こちらをご確認ください。すぐに利用できる多数の本番環境対応の機能(自動スケーリング、ハードウェア構成、トラフィック分割など)が用意されているため実用的です。
これらの 2 つのコンポーネントを実装するためのリファレンスとして、こちらのリポジトリを使用しました。
Firebase
このパートでは、TFX コンポーネントを基にしたカスタム python 関数の作成方法を示します。ただし基本となるロジックは、AutoML のセクションで紹介したものとほとんど同じです。この投稿では内部の詳細は省略しますが、ソースコード全体はこちらでご確認いただけます。
ここではタイプ チェッカー tfx.dsl.components.InputArtifact[tfx.types.standard_artifacts.PushedModel] を使用しています。tfx.dsl.components.InputArtifact は、パラメータが TFX アーティファクトのタイプであり、コンポーネントへの入力として使用されることを意味しています。同様に、tfx.dsl.components.OutputArtifact では、コンポーネントが生成する出力の種類を指定できます。
次に、入力アーティファクトの出所を角かっこ内に指定する必要があります。このケースでは、push されたモデルを Firebase ML にパブリッシュするため、tfx.types.standard_artifacts.PushedModel が使用されます。URI のハードコード化も可能ですが、柔軟な方法ではありません。PushedModel コンポーネントからの情報を参照することをおすすめします。
カスタム Docker イメージ
TFX には、パイプラインを実行できるビルド済みの Docker イメージが用意されています。しかし、さまざまな外部ライブラリを活用するカスタム コンポーネントが含まれるパイプラインを実行するには、カスタム Docker イメージをビルドする必要があります。驚くべきことに、これには小さな変更で対応できます。上記のカスタム TFX コンポーネントをサポートするカスタム Docker イメージをビルドするための Dockerfile 構成を次に示します。
したがって、custom_components には、カスタム コンポーネントの .py ファイルが含まれます。あとは、イメージをビルドして Google Container Registry に push するだけです(Docker Hub も使用できます)。
イメージをビルドして push するには docker build コマンドと docker push コマンドのいずれかを使用するか、Google Cloud のサーバーレス CI / CD プラットフォームである Cloud Build を使用します。Cloud Build を使用してビルドをトリガーするには、次のコマンドを使用します。
TFX_IMAGE_URI は名称が示すように、最終パイプラインの実行に使用されるカスタム Docker イメージの URI ですので、ご注意ください。ビルドは、nice dashboard の形式で、すべてのビルドログとともに使用できます。
統合する
すべての重要な要素を揃えたので、それらを TFX パイプラインの一部にして、エンドツーエンドで実行できるようにする必要があります。コード全体は、こちらのノートブックをご覧ください。
パイプラインに統合する前に、読みやすくする目的で、いくつかの定数変数を個別に定義することをおすすめします。model_display_name、pushed_model_location、pushed_location_mobilenet 変数は、名称を見れば内容がほぼわかります。一方、TRAINING_JOB_SPEC は多少長くなります。次に示します。
TRAINING_JOB_SPEC は基本的にモデル トレーニングのためのハードウェアとソフトウェアのインフラストラクチャを設定します。worker_pool_specs を使用すると、Vertex AI で分散トレーニング機能を活用する場合に、さまざまなタイプのクラスタを設定できます。たとえば、最初のエントリはプライマリ クラスタ用に予約され、4 番目のエントリはエバリュエータ用に予約されます。このプロジェクトでは、プライマリ クラスタのみを設定しています。
各 worker_pool_specs について、machine_spec と container_spec によって、ハードウェア インフラストラクチャとソフトウェア インフラストラクチャがそれぞれ定義されます。ご覧のように、n1-standard-4 instance 内の NVIDIA_TESLA_K80 GPU を 1 個だけ使用し、Docker のベースイメージを TFX の公式イメージに設定しています。これらの仕様の詳細については、こちらをご覧ください。
以下のパイプラインでこれらの構成が使用されています。モデル トレーニング インフラストラクチャは、Vertex AI が各コンポーネントのジョブを内部で実行する GKE クラスタとはまったく異なることに注意してください。そのため、統合型 API を介してではなく、複数の場所にある Docker のベースイメージを設定する必要があります。
以下のコードは、パイプライン全体ですべての要素を編成する方法を示しています。コンポーネントの接続方法や Vertex AI を活用するために必要な特別なパラメータに注目して、コードを確認してください。
このように、それぞれの標準コンポーネントには少なくとも 1 つの特別なパラメータがあり、さまざまなコンポーネントの出力から入力を取得します。たとえば、Trainer には examples パラメータがあり、その値は ImportExampleGen から取得します。同様に、Pusher には model パラメータがあり、その値は Trainer から取得します。一方、コンポーネントで特別なパラメータが定義されていない場合は、add_upstream_node メソッドにより明示的に依存関係を設定できます。add_upstream_node の使用例については、VertexUploader と VertexDeployer. で確認できます。
TFX コンポーネントを定義して接続した後、次の手順でこれらのコンポーネントをリストに追加します。パイプライン関数は tfx.dsl.Pipeline タイプのオブジェクトを返し、そのリストを使用してインスタンス化できます。tfx.dsl.Pipeline では、tfx.orchestration.experimental モジュールの KubeflowV2DagRunner を使用して最終的にパイプライン仕様を作成できます。tfx.dsl.Pipeline オブジェクトを使用して KubeflowV2DagRunner の run メソッドを呼び出す場合、JSON 形式でパイプライン仕様ファイルが作成されます。
その JSON ファイルは kfp.v2.google.AIPlatformClient の create_run_from_job_spec メソッドに渡すことができ、Vertex AI Pipelines でパイプライン実行が作成されます。これらすべてはコードで次のように示されます。
上記の手順が実行されると、Vertex AI Pipelines ダッシュボード上にパイプラインを確認できます。ここで一つ重要なことは、パイプラインは、前記の手順の一つでビルドした TFX Docker のカスタム イメージ上で実行できるようにコンパイルする必要があることです。
料金
Vertex AI Training は、パイプラインとは別個のサービスです。Vertex AI Pipelines は個別に課金され、パイプライン実行あたり約 $0.03 の料金です。各コンポーネントの Compute インスタンスのタイプは e2-standard-4 で、1 時間あたり約 $0.134 の料金です。パイプライン全体は終了までに 1 時間かからないため、合計料金は Vertex AI Pipelines の実行あたり約 $0.164 と予想できます。
AutoML トレーニングの料金は、タスクのタイプとターゲット環境によって決まります。たとえば、クラウドモデル用の AutoML トレーニング ジョブの料金は 1 時間あたり約 $3.15 ですが、オンデバイス モバイルモデル用の AutoML トレーニング ジョブは 1 時間あたり約 $4.95 です。トレーニング ジョブはこのプロジェクトでは 1 時間未満で終了したため、2 つのモデルの完全なトレーニングには約 $10 かかりました。
一方、カスタムモデルのトレーニングの料金は、マシンのタイプと時間数によって決まります。また、サーバーとアクセラレータの料金を別途検討する必要があります。このプロジェクトでは、1 時間あたり $0.19 の料金の n1-standard-4 マシンタイプと、1 時間あたり $0.45 の料金の NVIDIA_TESLA_K80 アクセラレータ タイプを選択しました。各モデルのトレーニングは 1 時間未満で終了したため、料金は合計で約 $1.28 でした。
モデル予測の料金は、AutoML とカスタム トレーニングされたモデルで別々に規定されています。AutoML モデルのオンライン予測とバッチ予測の料金は、それぞれ 1 時間あたり約 $1.25 と $2.02 です。一方、カスタム トレーニングされたモデルの予測料金は、マシンタイプによっておおまかに決定されます。このプロジェクトでは、us-central-1 リージョン内で、アクセラレータなしで 1 時間あたり $0.1901 である n1-standard-4 として指定しました。このプロジェクトで費やされた料金を合計すると、2 つのパイプライン実行の完了までの料金は約 $12.13 になります。詳細については、公式ドキュメントをご覧ください。
Firebase ML は無料です。カスタムモデルのデプロイに無料で使用できます。Firebase サービスの料金の詳細については、こちらをご覧ください。
まとめ
この投稿では、2 つの異なるタイプのモデルの使用が、ユーザーにサービス提供するために必要である理由を説明しました。GCP 上で Vertex AI を使用した 2 つの異なるアプローチを利用して、シンプルでありながらスケーラブルな自動化されたパイプラインを実現しました。1 つのアプローチでは、手間のかかる作業の多くをフレームワークに委任する Kubeflow の AutoML SDK を使用しました。もう 1 つのアプローチでは、TFX のカスタム コンポーネントを活用して、パイプラインのさまざまな部分を要件に従ってカスタマイズしました。今回の投稿では、機械学習エンジニアリング ツールボックスに備える必要がある重要なレシピをいくつかご紹介できたかと思います。こちらのコードを自由にお試しいただき、ご意見やご感想をお聞かせください。
謝辞
Google によるテストをサポートするために GCP クレジットを提供いただいた ML-GDE プログラムに感謝申し上げます。レビューに協力いただいた Google の Karl Weinmeister と Robert Crowe に感謝します。
- ML Google Developer Expert Changsung Park
- ML Google Developer Expert Sayak Paul




{kind=link}
{kind=link}