Vertex AI AutoML とパイプラインによるスケーラブルな MLOps システムの構築
Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習(ML)プロダクトを構築する際には、少なくとも 2 つの MLOps シナリオを検討する必要があります。まず、学会や産業界で画期的なアルゴリズムが導入された場合、モデルの入れ替えが可能であることです。次に、変化を続ける環境のデータに合わせて、モデル自体を進化させる必要があります。
Vertex AI が提供するサービスを利用すれば、この 2 つのシナリオに対処できます。次に例を示します。
AutoML 機能により、予算、データ、設定に基づき、最適なモデルを自動的に特定します。
Vertex マネージド データセットを使用すると、新規のデータセットを作成するか既存のデータセットに付加的なデータを追加して、データセットを簡単に管理できます。
Vertex Pipelines を使って、データセットのインポートからモデルのデプロイまでの一連の流れを自動化する ML パイプラインを構築できます。
このブログ投稿では、このシステムの構築方法をご紹介します。再現用の完全なノートブックについては、こちらをご覧ください。MLOps というと ML パイプラインに注目されがちですが、MLOps を「システム」として構築するものはそれだけではありません。この投稿では、Google Cloud Storage(GCS)と Google Cloud Functions がどのようにデータを管理し、MLOps のシステムでイベントを処理するのかを見ていきます。
アーキテクチャ
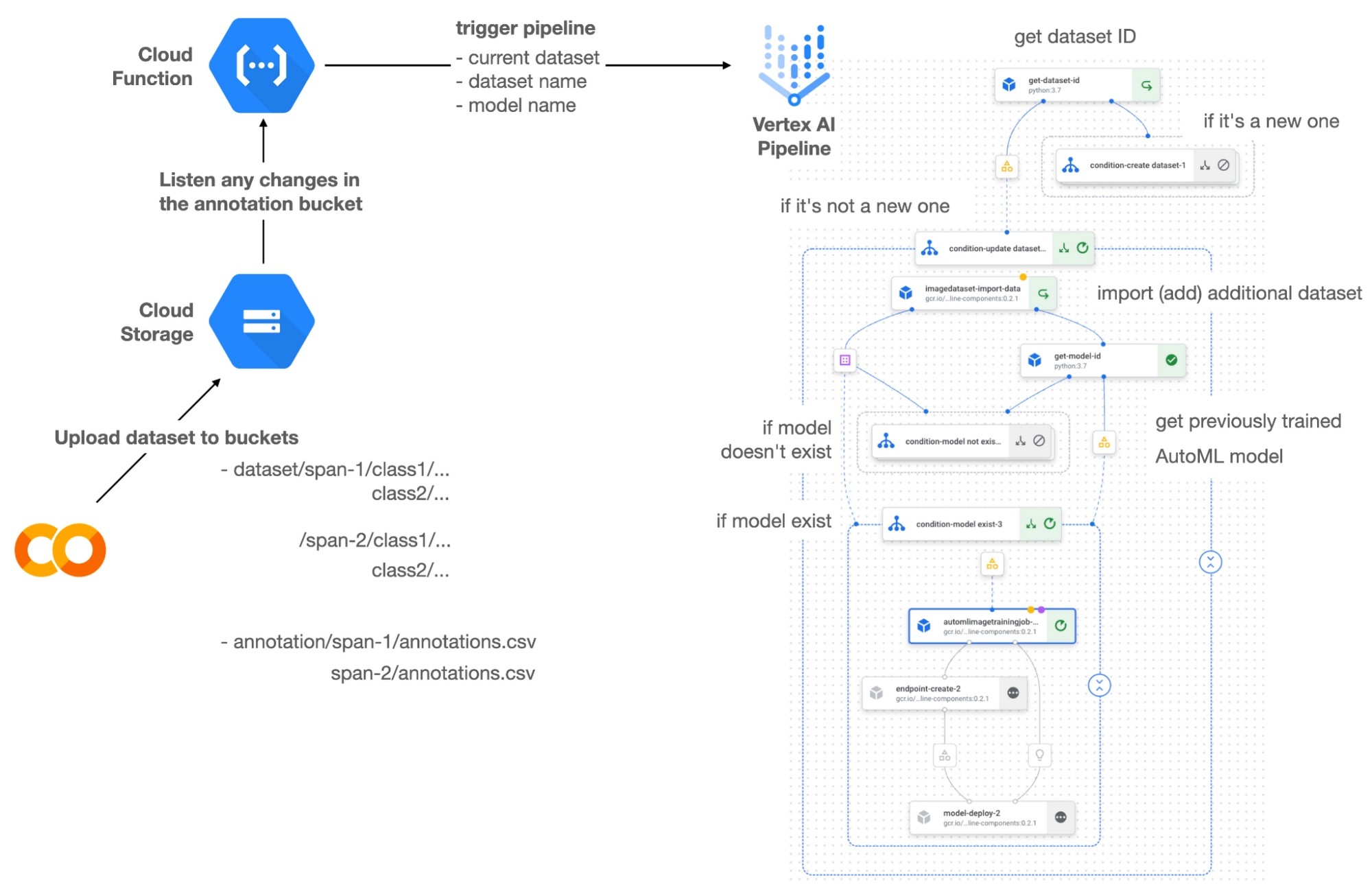
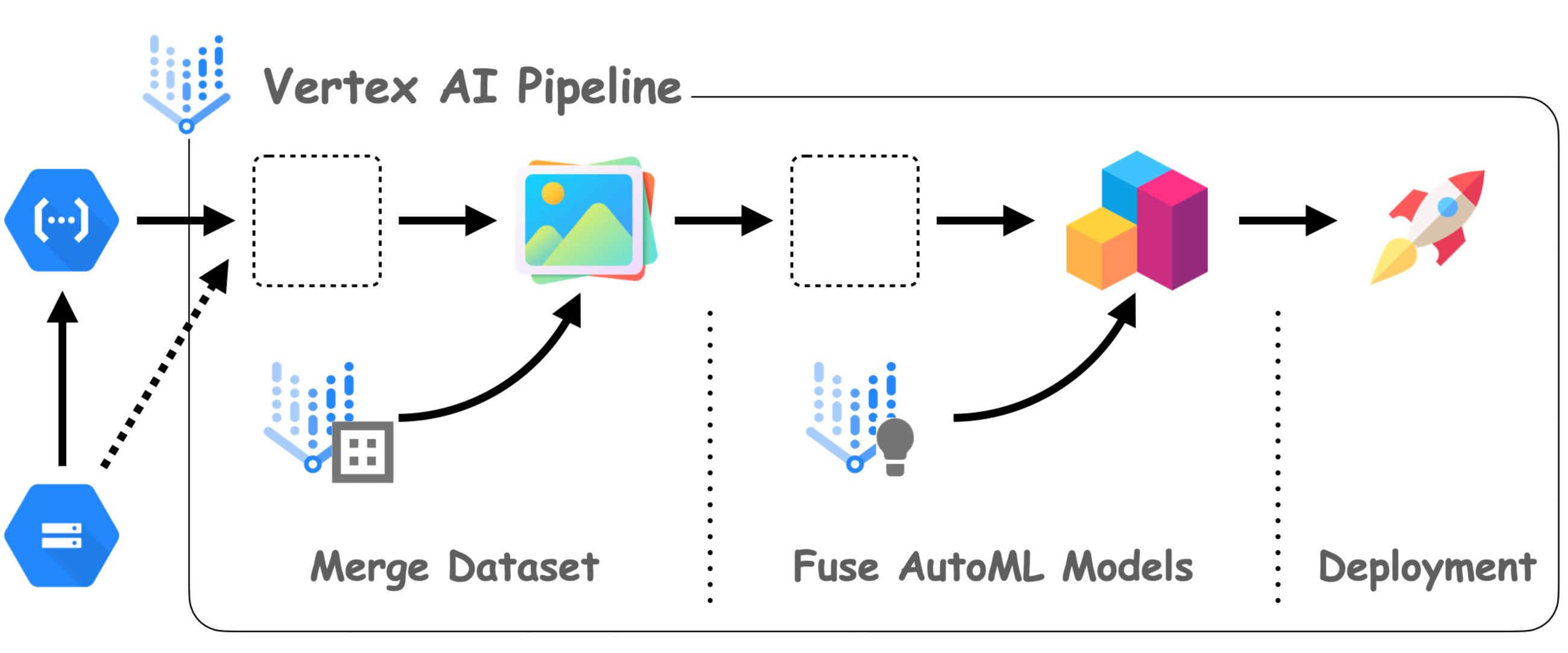
図 1 MLOps アーキテクチャの全体図 (クリックして図を拡大表示)
図 1 に、本ブログで紹介する全体的なアーキテクチャを示します。MLOps システムで一般的な 2 つのワークフローを例に、コンポーネントとその接続について説明します。
コンポーネント
Vertex AI は MLOps システムの中心にあり、Vertex マネージド データセット、AutoML、Prediction、Pipelines を活用しています。Vertex マネージド データセットを使って、データセットを作成し、その拡張に合わせて管理できます。Vertex AutoML は、モデリングについてあまり知らなくても、最適なモデルを選択できます。Vertex Predictions は、クライアントが通信するためのエンドポイント(RestAPI)を作成します。
データセットからモデルのトレーニング、そしてデプロイまで、シンプルかつフルマネージドのエンドツーエンドの MLOps ワークフローを実現します。このワークフローは、Vertex Pipelines でプログラムで記述できます。Vertex Pipelines は、ML パイプラインの仕様を出力するため、いつでもどこでもパイプラインを再実行できます。Cloud Functions と Cloud Storage を使用して、パイプラインをいつ、どのように起動するかを指定します。
Cloud Functions は、サーバーレスでコードを GCP にデプロイする方法です。この特定のプロジェクトでは、指定した Cloud Storage のロケーションに関する変更をリッスンしてパイプラインをトリガーするために使用されます。具体的には、新しいスパン番号などの新しいデータセットを追加すると、パイプラインがトリガーされてデータセットがトレーニングされ、新しいモデルがデプロイされます。
ワークフロー
この MLOps システムは、Vertex データセットに組み込まれたユーザー インターフェース(UI)、またはお好みに応じて外部ツールを使用してデータセットを準備します。準備したデータセットを、SPAN-NUMBER という新規フォルダを作成し、指定の GCS バケットにアップロードします。すると、Cloud Functions は GCS バケットの変更を検出し、Vertex Pipelines をトリガーして、AutoML のトレーニングからエンドポイントのデプロイまでのジョブを実行します。
Vertex Pipelines は、以前に作成された既存のデータセットがあるかどうかを内部でチェックします。データセットが新しい場合、Vertex Pipelines は GCS のロケーションからデータセットをインポートして新しい Vertex データセットを作成し、対応するアーティファクトを出力します。それ以外の場合、追加のデータセットを既存の Vertex データセットに追加し、アーティファクトを出力します。
Vertex Pipelines はデータセットが新しいと判断すると、新しい AutoML モデルをトレーニングし、新しいエンドポイントを作成してデプロイします。データセットが新しいものでない場合、Vertex モデルからモデル ID の取得を試み、新しい AutoML モデルまたは更新された AutoML モデルが必要であるかどうかを判断します。2 番目のブランチは、AutoML モデルが作成されたかどうかを判断します。まだ作成されていない場合は、2 番目のブランチで新しいモデルが作成されます。また、モデルがトレーニングされると、対応するコンポーネントもアーティファクトを出力します。
異なるディストリビューションを反映したディレクトリ構造
このプロジェクトで CIFAR-10 データセットのサブセットを 2 つ作成しました。1 つは SPAN-1 用で、もう 1 つは SPAN-2 用です。このプロジェクトのより一般的なバージョンについては、こちらをご覧ください。トレーニングとバッチ評価のパイプラインを構築する方法を確認できます。パイプラインを協調して設定することで、現在デプロイされているモデルを評価し、再トレーニング プロセスを起動できます。
Kubeflow Pipelines(KFP)で記述した ML パイプライン
パイプラインのオーケストレーションには、Kubeflow Pipelines を使用することにしました。いくつか注目していただきたい点として、まず、KFP で条件ステートメントを使用してブランチを作成する方法を理解しておきます。次に、AutoML API の仕様を確認し、AutoML 機能を十分に活用する必要があります(以前にトレーニングしたモデルに基づくモデルのトレーニングなど)。最後に、Vertex データセットと Vertex モデルのアーティファクトを出力して、Vertex AI が認識できるように消費させる方法も必要です。1 つずつ見ていきましょう。
ブランチ戦略
このプロジェクトには、2 つのメイン条件があり、2 つ目のメインブランチ内に 2 つのサブブランチがあります。メインブランチは、既存の Vertex データセットがあるかどうかの条件に基づいてパイプラインを分割します。サブブランチは、既存の Vertex データセットがある場合に選択される 2 つ目のメインブランチで適用されます。モデルのリストを検索し、ゼロから AutoML モデルをトレーニングするか、事前トレーニング済みモデルをトレーニングするかを決定します。
KFP で書かれた ML パイプラインは、kfp.dsl.Condition という特殊な構文で条件を指定できます。例えば、次のようにブランチを定義できます。
get_dataset_id と get_model_id は、それぞれ既存の Vertex データセットと Vertex モデルがあるかどうかを判断するために使用されるカスタム KFP コンポーネントです。どちらもモデルが見つかれば「None」を、見つからなければ他の値を返します。また、Vertex AI 対応のアーティファクトを出力します。これについては、次のセクションで解説します。
Vertex AI 対応のアーティファクトを出力する
アーティファクト は、ML パイプラインにおける各テストの経路を追跡し、Vertex Pipeline UI にメタデータを表示します。Vertex Pipeline UI は、Vertex AI 対応のアーティファクトがパイプラインにリリースされる際に、Vertex データセットなどの内部サービスへのリンクを表示し、ユーザーが詳細な情報を得るためのウェブページにアクセスできるようにするものです。
では、Vertex AI 対応のアーティファクトを生成するカスタム コンポーネントを記述するにはどうすればよいでしょうか。その場合、カスタム コンポーネントのパラメータに Output[Artifact] を指定する必要があります。次に、メタデータ属性の resourceName を特別な文字列形式で入力する必要があります。
次のコード例は、前のコード スニペットで使用した get_dataset_id の実際の定義です。
ご覧のように、パラメータで dataset が Output[Artifact] として定義されています。パラメータに表示されていますが、実際には自動的に出力されます。関数の変数と同じように必要なデータを用意する必要があります。
データセット コンポーネント は、aiplotform.ImageDataset.list API を呼び出して、Vertex データセットのリストを取得します。長さがゼロの場合は、単に「None」を返します。それ以外の場合は、Vertex データセットの検出されたリソース名を返し、同時に dataset.metadata['resourceName'] にリソース名を入力します。Vertex AI 対応のリソース名は、「projects/<project-id>/locations/<location>/<vertex-resource-type>/<resource-name>」という特別な文字列形式に従います。
<vertex-resource-type> は、内部の Vertex AI サービスを指すものであれば何でも問題ありません。たとえば、アーティファクトが Vertex モデルであることを指定する場合、<vertex-resource-type> をモデルに置き換える必要があります。<resource-name> はリソースの一意の ID であり、aiplatform API で検出されたリソースの name 属性でアクセスできます。もう 1 つのカスタム コンポーネントである get_model_id も、よく似た方法で記述されています。
以前のモデルに基づいた AutoML
新しいモデルを、以前の最適なモデルに基づいてトレーニングしたい場合があります。それが可能な場合、新しいモデルは、以前にトレーニングした知識を活用するため、おそらく最初からトレーニングしたモデルよりもはるかに優れているはずです。
幸いなことに、Vertex AutoML には、以前のモデルを使用してモデルをトレーニングさせる機能が備わっています。AutoMLImageTrainingJobRunOp コンポーネントでは、以下のように base_model 引数を与えるだけで、モデルをトレーニングさせることができます。
新しい AutoML モデルを最初からトレーニングする場合、base_model 引数に None を渡します。これはデフォルト値です。ただし、この引数は VertexModel アーティファクトを使用して設定できるため、上記コンポーネントは他のモデルに基づいた AutoML トレーニング ジョブをトリガーします。
ここで注意すべきは、VertexModel アーティファクトは Python プログラミングの一般的な方法で構築できない点です。つまり、VertexModel ダッシュボードにある id を設定しても、VertexModel アーティファクトのインスタンスを作成することはできません。インスタンスを作成できる唯一の方法は、metadata['resourceName'] パラメータを適切に設定することです。同じルールが、VertexDataset などの他の Vertex AI 関連のアーティファクトにも適用されます。VertexDataset アーティファクトを適切に構築し、既存の Vertex データセット を取得して、追加のデータをインポートする方法を確認できます。このプロジェクトの詳細なノートブックについては、こちらをご覧ください。
費用
新しい GCP アカウントを作成すると、このプロジェクトの同じ結果を $300 の無料クレジットで再現できます。
このブログ投稿の時点で、Vertex Pipelines の費用は実行ごとに約 $0.03 であり、各パイプライン コンポーネントの基盤となる VM のタイプは e2-standard-4 で、その費用は約 $0.134/時間です。Vertex AutoML トレーニングの画像分類の費用は約 $3.465/時間です。GCS は実際のデータを保持し、費用は 100 GiB 容量で約 $2.40/月になり、Vertex データセット自体は無料です。
2 つの異なるブランチをシミュレートするために、テスト全体で約 1~2 時間かかりました。このプロジェクトの合計費用は約 $16.59 になります。Vertex AI の料金に関する詳細な情報については、こちらをご覧ください。
まとめ
AutoML の機能を過小評価している方は少なくありませんが、機械学習の基礎知識があまりないアプリ デベロッパーやサービス デベロッパーにとっては最適な選択肢です。Vertex AI は、機械学習ワークフローを自動化する AutoML とパイプライン機能を提供する優れたプラットフォームです。この記事では、データ インジェクションから、以前に獲得した最適なモデルに基づいたモデルのトレーニング、Vertex AI プラットフォームでのモデルのデプロイまで、基本的な MLOps ワークフローを設定して実行する方法をご紹介しました。さらに、機械学習モデルを新しいデータセットの変更に自動的に適応できます。残りの実装作業は、モデル モニタリング システムを統合してデータ / モデルのドリフトを検出することです。そうした一例については、こちらをご覧ください。
- ML Google Developer Expert、Chansung Park




{kind=link}