Bigtable と BigQuery: その違いは何か
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
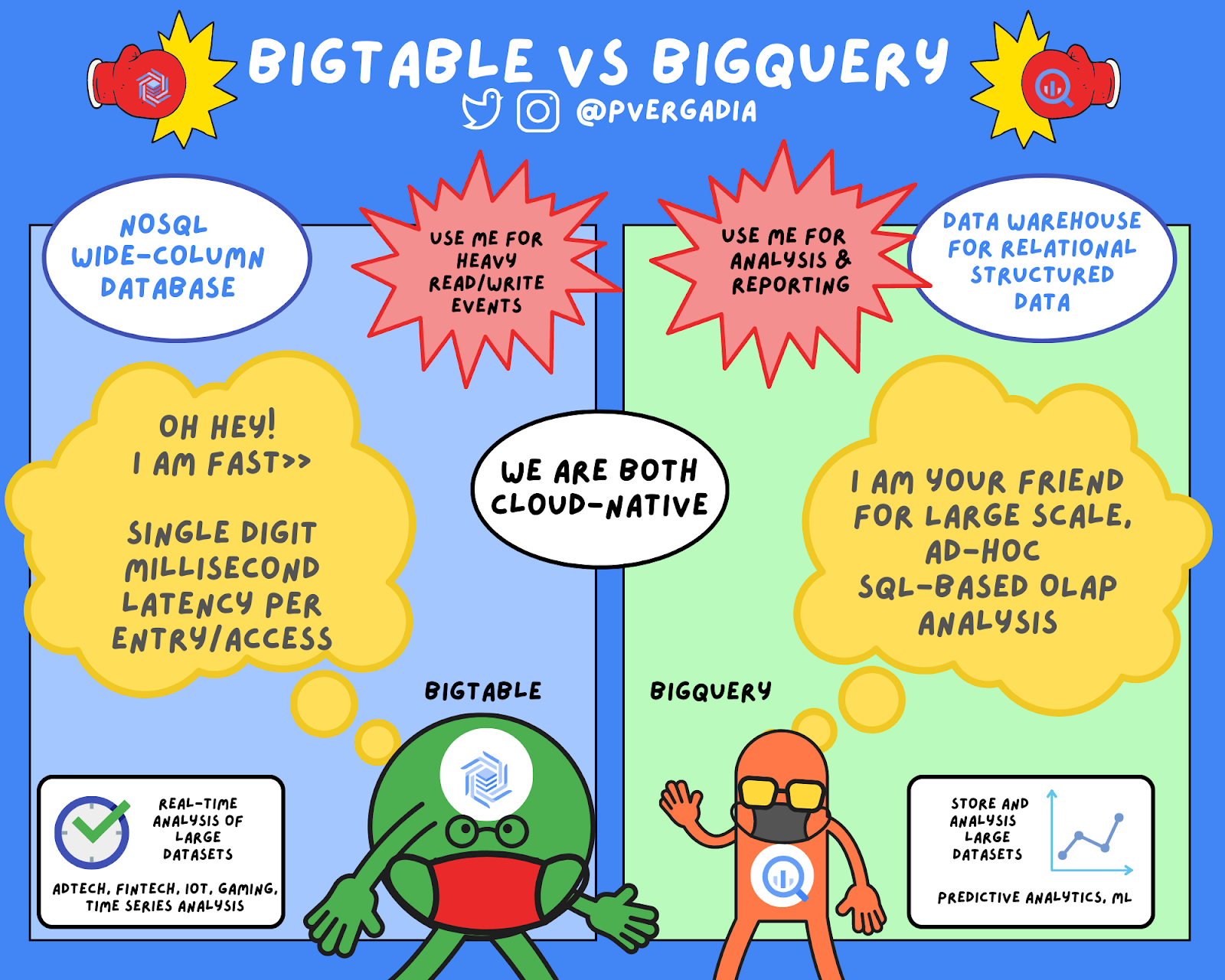
BigQuery と Bigtable のどちらを使うべきかで迷っているユーザーは多いと思います。この 2 つのサービスは、名前に「Big」が含まれているなど多くの共通点がありますが、ビッグデータのエコシステムにおいてこの両者がサポートするユースケースは大きく異なります。
大まかに言うと、Bigtable は NoSQL ワイドカラム型データベースであり、低レイテンシ、大量の読み取りと書き込み、大規模なパフォーマンスの維持向けに最適化されています。IoT、アドテック、フィンテックなど、一定の規模やスループットでレイテンシ要件が厳しいものは、Bigtable のユースケースに該当します。大規模な高スループットと低レイテンシが優先事項でない場合は、Firestore などの別の NoSQL データベースが適しているかもしれません。
Bigtable は、大量の読み取りと書き込み用に最適化された NoSQL ワイドカラム型データベースです。
一方、BigQuery は大量のリレーショナル構造化データ用のエンタープライズ データ ウェアハウスです。大規模なアドホック SQL ベースの分析やレポート用に最適化されており、組織に関する分析情報を得るために最適です。BigQuery を利用して Cloud Bigtable のデータを分析することもできます。
BigQuery は、大量のリレーショナル構造化データ用のエンタープライズ データ ウェアハウスです。
Cloud Bigtable の特徴
Bigtable は、大規模でスケーラブルなアプリケーションをサポートすることを目的に設計された NoSQL データベースです。1 秒あたりの読み取りと書き込みに関して大規模なスケーリングの必要があるアプリケーションを作成する場合は、Bigtable を使用します。Bigtable のスループットはノードの追加や削除によって調整します。1 つのノードで、最大 1 秒間に 10,000 クエリ まで利用できます(読み取りと書き込み)。Bigtable は、大容量の低レイテンシ アプリケーションのストレージ エンジンとして利用することも、スループット重視型のデータ処理、解析ツールとして利用することもできます。ゾーン インスタンスで SLA 99.5% の高可用性を実現します。1 つのクラスタ内で強整合性があり、レプリケーションにより 2 つのクラスタ間で結果整合性が追加されて、SLA が 99.99% に向上します。
Cloud Bigtable は、スパース(低密度)に格納されるテーブルとして設計された Key-Value のストアです。数十億行、数千列の規模にスケール可能で、これにより、数テラバイト、あるいは数ペタバイトのデータを格納できます。このデザインは、行や項目ごとに大量のデータを格納する場合にも役立つため、機械学習予測に最適です。MapReduce スタイルのオペレーションに最適なデータソースであり、Hadoop、Dataflow、Dataproc などの既存のビッグデータ ツールと簡単に統合できます。また、オープンソースの HBase API 規格もサポートしているため、Apache エコシステムとも簡単に統合可能です。
実例については、スイス最大のオンライン マーケットプレイスである Ricardo がベンチマークを実施して、自己管理型の Cassandra よりも Bigtable ははるかに管理が容易で費用効果も高いという結論に達した事例をご覧ください。
BigQuery の特徴
BigQuery は、データの取り込み、格納、分析、可視化を簡素化する目的で設計された、ペタバイト級のデータ ウェアハウスです。通常は、さまざまなデータベースやサードパーティ製のシステムから大量のデータを収集して特定の質問に回答します。このデータを一括アップロードによって BigQuery に取り込んだり、データを直接ストリーミングしてリアルタイムの分析情報を実現したりできます。BigQuery は ANSI に準拠した標準の SQL 言語をサポートしているため、すでに SQL の知識をお持ちの場合は、問題なくすぐに利用できます。Bigtable をデータベースとして利用するアプリケーションを提供することはあっても、BigQuey のクエリを実行するアプリケーションを提供することはほとんどないと言えるでしょう。Cloud Bigtable はサービスの提供において、BigQuery は分析において、それぞれの力を発揮します。
データを BigQuery に読み込んだら、クエリの実行を開始できます。クエリで大きなテーブルをスキャンする必要がある場合や、データベース全体を検索する必要がある場合は、BigQuery が最適な選択肢です。これには、合計、平均、カウント、グループ化などのクエリや、機械学習モデルを作成するためのクエリも含まれます。BigQuery の典型的なユースケースとして、大規模なストレージや分析、オンライン分析処理(OLAP)などが挙げられます。
実例については、Verizon Media がメディア分析パイプラインに BigQuery を使用して、大規模な Hadoop およびエンタープライズ データ ウェアハウス(EDW)のワークロードを Google Cloud の BigQuery および Looker に移行した方法をご覧ください。
共通の特徴
BigQuery と Bigtable はどちらもクラウドネイティブで、どちらもユニークな業界トップクラスの SLAを特色としています。また、どちらのサービスの場合も更新やアップグレードはバックグラウンドで透過的に行われるため、メンテナンスの時間枠やプランニングのダウンタイムを心配する必要がありません。さらに、どちらも無制限のスケーリング、自動シャーディング、自動障害復旧(レプリケーション機能付き)を備えています。高速なトランザクションと高速なクエリを実現するために、BigQuery と Bigtable のどちらも処理とストレージを分けて、スループットを最大化します。
まとめ
この投稿をお読みになり、データ戦略を支援するための今後のイノベーションについて興味を持ち、詳しく知りたいとお考えの場合は、5 月 26 日に開催されるデータクラウド サミットにご参加ください。BigQuery および Bigtable の詳細については、thecloudgirl.dev で個々の GCP スケッチノートをご覧ください。同様のクラウド コンテンツについては、Twitter(@pvergadia)をフォローしてください。
-Google デベロッパー アドボケイト Priyanka Vergadia



