Verizon Media がスケーリング、パフォーマンス、優れたコスト効率を実現するために BigQuery を選択した理由
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
Verizon Media の中心的ブランドの一つである、Yahoo の分析、収益化、成長プラットフォームを任されている立場として、私は選択したソリューションが実環境のシナリオで完全にテストされているかどうかを確認する責任を負っています。本日ようやく、Hadoop とエンタープライズ データ ウェアハウス(EDW)のワークロードを、Google Cloud の BigQuery と Looker に大規模に移行する作業が完了しました。
このブログでは、現在のアーキテクチャに至るまでの技術的および財務上の考慮事項についてご紹介します。データ プラットフォームの選択は、標準ベンチマーク テストを行うよりも複雑です。ベンチマークは選択の開始にあたって役立ちますが、データ プラットフォームを実環境のシナリオに照らし合わせてテストすることに勝るものはありません。そこで、私たちが BigQuery と別のクラウド(AC)を比較した際の、各プラットフォームの優れている点や、BigQuery と Looker を選択した理由について説明したいと思います。これらの情報が、業界標準のベンチマークに捉われず、ビジネスの適切な意思決定を行うための一助になれば幸いです。では、詳しく見てみましょう。
MAW の概要とデータサイズ
MAW(Media Analytics Warehouse)は Yahoo の大規模なデータ ウェアハウスであり、Yahoo Finance、Yahoo Sports、Yahoo.com、Yahoo Mail、Yahoo Search に加え、現在 Verizon Media の一部となっているウェブ上のさまざまな人気サイトのクリックストリーム データをすべて格納しています。2020 年第 4 四半期のある 1 か月間の BigQuery 使用状況を測定したところ、アクティブ ユーザー数とクエリ数、スキャン、取り込み、保存されたバイト数について、次の数字になることがわかりました。

MAW データの使用者と活用方法
Yahoo の経営幹部、アナリスト、データ サイエンティスト、エンジニアはすべて、このデータ ウェアハウスを使用しています。ビジネス ユーザーは Looker ダッシュボードの作成と配信、アナリストは SQL クエリの記述、データ サイエンティストは予測分析、データ エンジニアは ETL パイプラインの管理にそれぞれ活用しています。一般的に、次のような基本的な質問に詳しくお答えすることができます。「Yahoo のユーザーはどのようにしてさまざまなサービスを利用していますか?ユーザーにとって最も有用なサービスは何ですか?どのようにサービスを改善したらユーザー エクスペリエンスを向上できますか?」
プラットフォーム上に構築された MAW と分析ツールは、社内のさまざまな組織で使用されています。編集スタッフは記事や動画のパフォーマンスのリアルタイムでのモニタリングに、ビジネス パートナーシップ チームはパートナーのライブ動画番組の追跡に、プロダクト マネージャーと統計担当者はプロダクト機能の評価と改善のための A/B テストと実験分析に、アーキテクトとサイト信頼性エンジニアはネイティブ アプリ、ウェブ、動画全体におけるユーザー レイテンシ指標の長期的な傾向を追跡するために使用しています。このプラットフォームでサポートされるユースケースは、企業のほぼすべてのビジネス分野をカバーできます。特に私たちは、アクセス パターンの傾向や、特に人気の高いコンテンツを提供しているパートナーを発見するために分析を使用して、次の投資対象を評価するのに役立てています。また、メディア プラットフォームの成功にはエンドユーザーのエクスペリエンスが常に重要であることを踏まえ、すべてのサイトにおいてレイテンシ、エンゲージメント、チャーンに関する指標を継続的に追跡しています。さらに、クリックストリームのユーザー セグメントを詳細に分析することで、どのユーザーのコホートがどのコンテンツを求めているかについても評価しています。
自社のデータに対して、これに近い内容の疑問をお持ちの場合は、ぜひ続けてお読みください。ユーザーにサービスを提供し、このような分析を大規模に実現できるようにするプロダクトやテクノロジーのアーキテクチャについてご説明します。
古いインフラストラクチャの問題の特定
数年前、当社では大きな問題が発生していました。処理すべきデータ量が多すぎて、信頼性と適時性に対するユーザーの期待に応えることができませんでした。システムは断片化されているうえに、操作も複雑でした。これにより、信頼性を維持するのが難しくなり、サービス停止時に発生した問題の追跡は困難を極めました。挙句の果てには、ユーザーの不満、度重なるエスカレーションの発生、そしてリーダーの怒りさえ招くようになっていました。
大規模な Hadoop クラスタの管理は、それまでもずっと Yahoo の強みでした。そのため、これが問題になることはなく、大規模なデータ パイプラインは毎日ペタバイト規模のデータを処理して正常に動作していました。しかし、この専門知識と規模では、従業員のインタラクティブな分析のニーズを満たすことができませんでした。
分析のニーズに応じたソリューション要件の決定
クラウド ソリューションの成功に向けて、私たちはすべての構成ユーザーの要件を整理しました。これらの各種使用パターンのそれぞれが、統制のとれたトレードオフ調査をもたらすと同時に、4 つの重要なパフォーマンス要件を導き出しました。
パフォーマンス要件
データ読み込みの要件: 翌日の午前 9 時までに、前日のデータすべてを読み込む。予測量として、1 日あたり 200 TB 以上の容量が必要とされる。
インタラクティブなクエリのパフォーマンス: 一般的なクエリの場合、1~30 秒。
日常的に使用するダッシュボード: 30 秒以内に更新する。
複数週のデータ: 1 分以内にアクセスしてクエリを実行する。
最も重要な基準は、エンジニアが実行する個別のベンチマークに基づくのではなく、実環境のユーザー エクスペリエンスに基づいてこういった決定を行うことでした。
また、パフォーマンス要件に加え、最新のデータ ウェアハウスが対応しなくてはならない、複数の段階にまたがるシステム要件がいくつかありました。その要件とは、シンプルなアーキテクチャ、スケーリング、パフォーマンス、信頼性、インタラクティブな可視化、コストです。
システム要件
シンプルさとアーキテクチャの統合
ANSI SQL に準拠
NoOps / サーバーレス - 適切なサーバーの種類の決定、調達、導入、起動などのサイクルを必要とせずに、ストレージやコンピューティングを追加可能
ストレージやコンピューティングの独立したスケーリング
信頼性
信頼性と可用性: 各月の稼働率 99.9%
スケーリング
ストレージ容量: 数百 PB
クエリの容量: エクサバイト/月
同時実行: グレースフル デグラデーションとインタラクティブな応答に対応した 100 以上のクエリ
ストリーミング取り込みで 1 日あたり数百 TB をサポート
可視化とインタラクティブ性
BI ツールとの成熟した統合
マテリアライズド ビューとクエリの書き換え
大規模なコスト効率向上の実現
概念実証: 戦略、戦術、結果
戦略上、使用するソリューションが本番環境規模で上記の要件を満たせることを証明する必要がありました。これはつまり、テストでは本番環境のデータに加え、本番環境のワークフローまで使う必要があることを意味します。私たちは、最も重要なユースケースとユーザー グループに集中的に取り組むために、概念実証(POC)インフラストラクチャを使用してダッシュボードのユースケースをサポートすることに専念しました。これにより、新旧の複数のデータ ウェアハウス(DW)バックエンドを持つことができ、必要に応じてそれらバックエンド間のトラフィックを接続できました。ユーザーに通知することなく、CDW のトラフィックをスケールアップした後に、レガシー システムから新しいシステムへとリアルタイムでカットオーバーできたため、実質的に、この方法で POC アーキテクチャを本番環境へと段階的にロールアウトしました。
戦術: 競合他社の選定とデータのスケーリング
外部クラウドでの分析に対する最初のアプローチは、3 ペタバイトのデータのサブセットを移動させることでした。また、クラウドに移行するために選択したデータセットは、1 つの完全なビジネス プロセスを表すものにしました。その理由は、ユーザーのサブセットを新しいプラットフォームに透過的に切り替えたかったため、そして複数のシステムを管理することに頭を悩ませたくなかったためです。
システム要件に基づいた最初の審査後、2 つのクラウド データ ウェアハウスに絞り込みました。この POC で、BigQuery と「別のクラウド(AC)」のパフォーマンス テストを実施し、POC をスケールするために MAW から 1 つのファクト テーブルを移動することから始めました(注: 取り込みのパフォーマンス テストでは別のデータセットを使用しています。詳細は以下をご覧ください)。続けて、MAW のあらゆる概要データを両方のクラウドに移動しました。その後、最も効果的なクラウド データ ウェアハウスに 3 か月分の MAW データを移動して、日々の使用状況を示すダッシュボードをすべて新しいシステムで実行できるようにしました。そのデータ範囲により、データとユーザーの両方に必要な規模で、すべての成功基準を明確にすることができました。
パフォーマンス テストの結果
ラウンド 1: 取り込みのパフォーマンス
要件は、「翌日の午前 9 時まで」というデータ読み込みのサービスレベル契約(SLA)を満たすために、クラウドが 1 日のデータすべてを時間内に読み込むことです。この 1 日とは、特定のタイムゾーンの現地時間になります。この要件は、両方のクラウドが満たすことができました。
一括取り込みのパフォーマンス: 引き分け
ラウンド 2: クエリのパフォーマンス
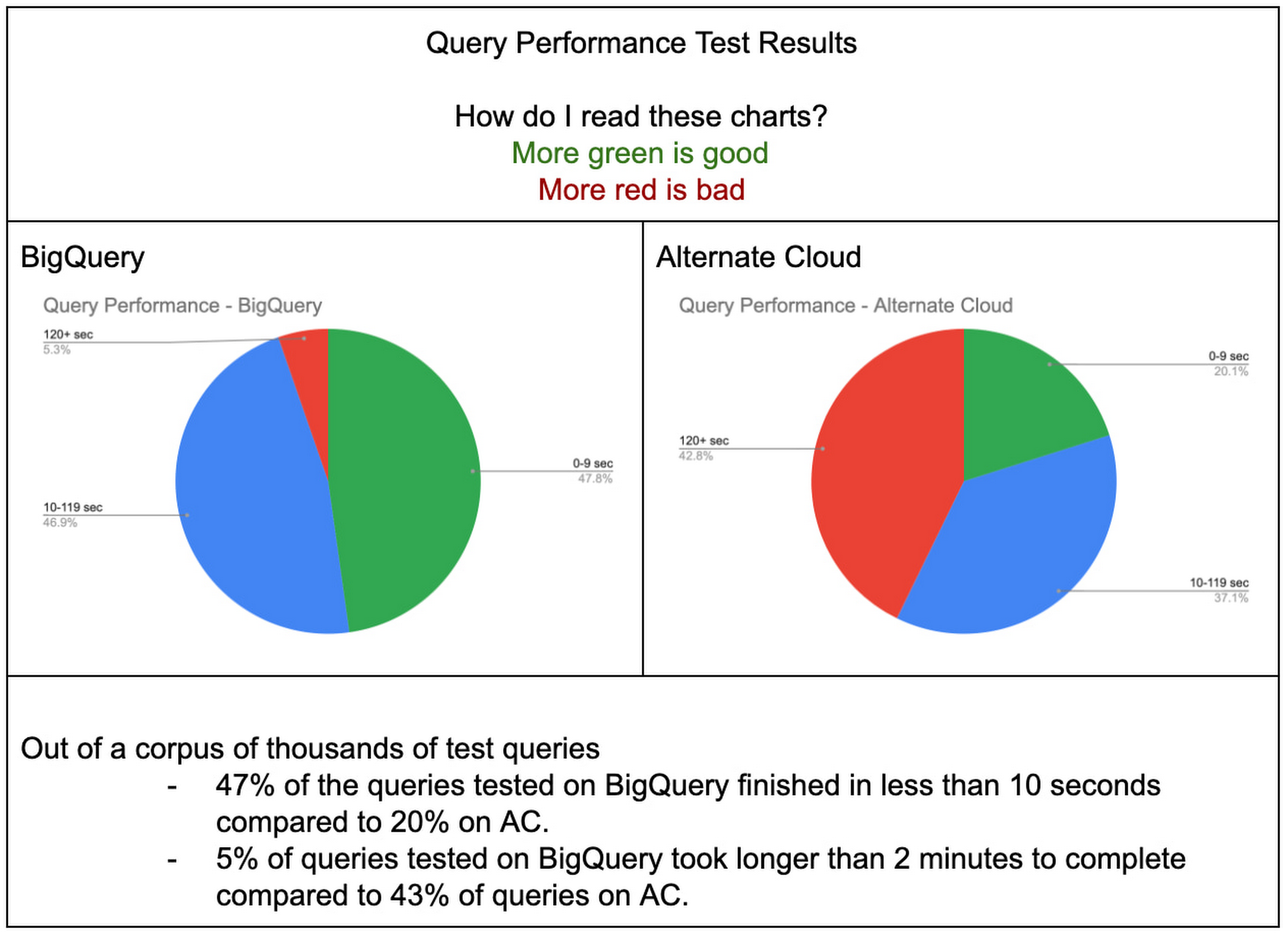
比較の基準を揃えるために、BigQuery と AC のベスト プラクティスに従って、各プラットフォームの最適なパフォーマンスを測定しました。下記のグラフは、各プラットフォームでの数千のクエリのテストセットに対するクエリ応答時間を示しています。このクエリのコーパスは、MAW の複数の異なるワークロードを表しています。BigQuery は、非常に短くかつ非常に複雑なクエリにおいて、AC よりも特にパフォーマンスが優れているのがわかります。BigQuery ではテストしたクエリのうち 10 秒未満で処理できたのは半分(47%)だったのに対し、AC ではわずか 20% でした。さらに詳しく言うと、テストした数千のクエリのうち、BigQuery での実行で 3 分以上かかったクエリはわずか 5% であるのに対し、AC では約半分(43%)が完了に 3 分以上かかりました。
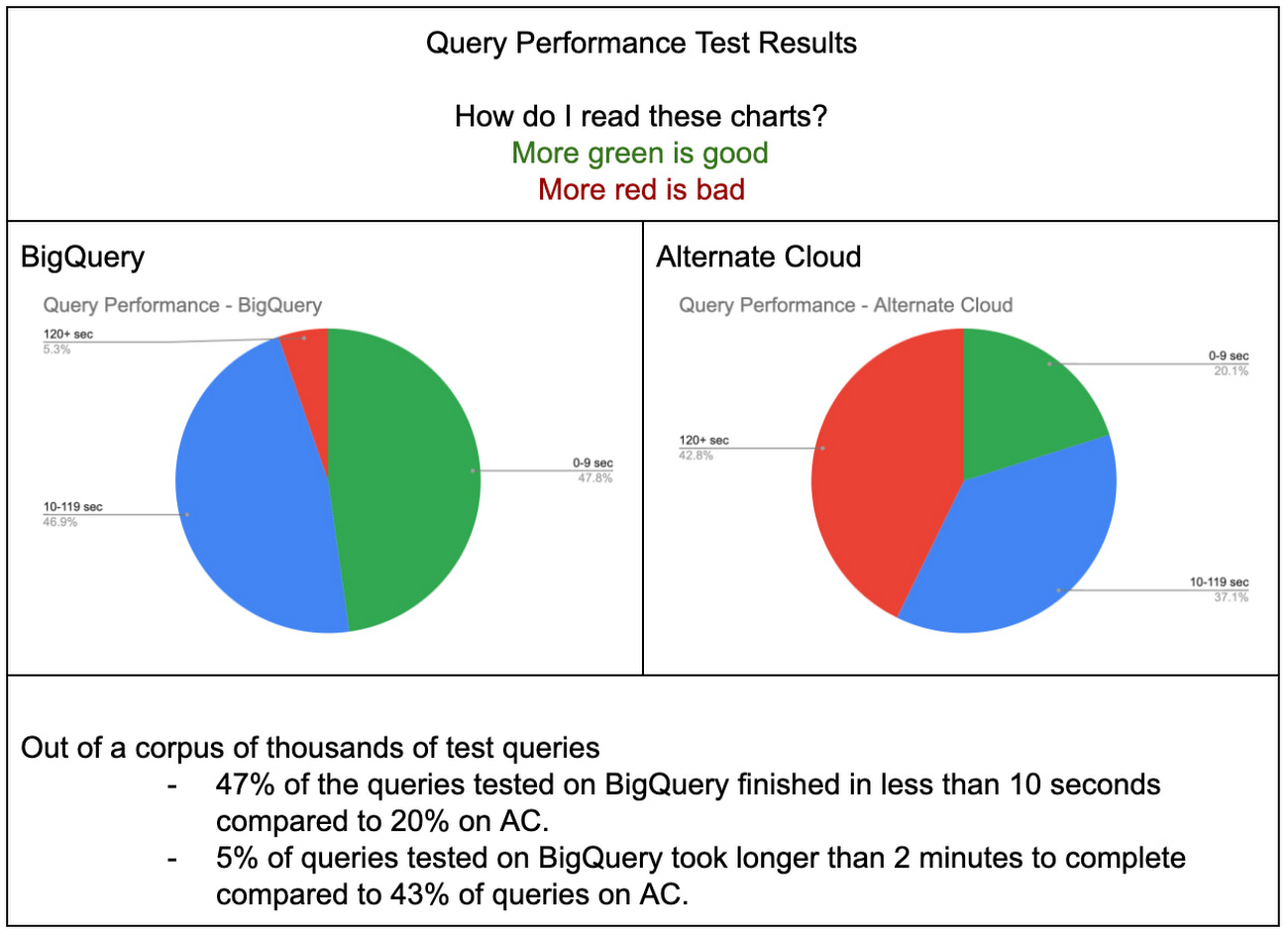
クエリのパフォーマンス: BigQuery
ラウンド 3: 同時実行
テスト結果については、AtScale のこちらの調査で確証されています。BigQuery は、同時実行クエリ数が増えても、卓越したパフォーマンスを実現可能であることが示されています。
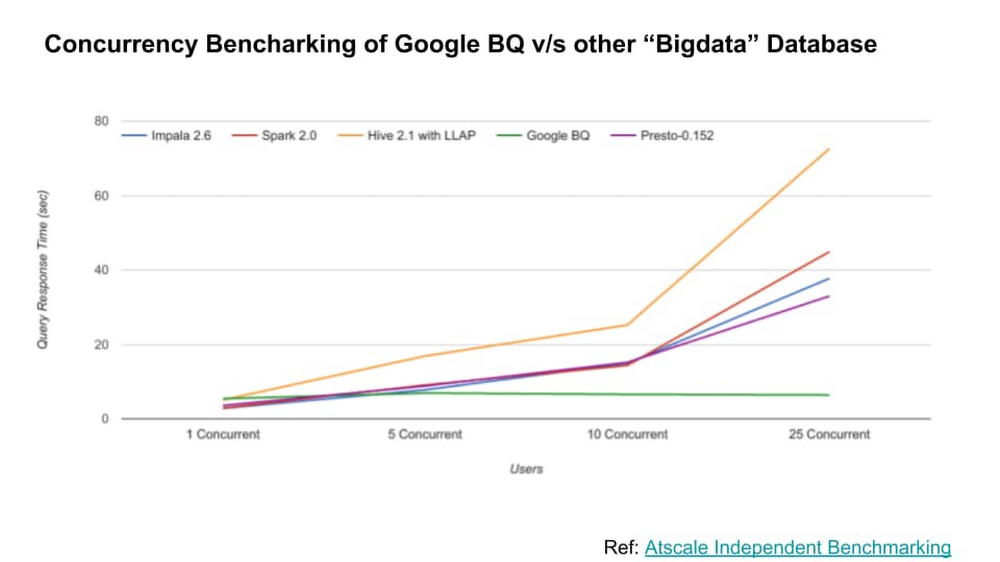
大規模な同時実行: BigQuery
ラウンド 4: 総所有コスト(TCO)
このセクションで当社の具体的な経済状況について述べることはできませんが、第三者による調査を提示して、TCO に大きな影響をもたらしたその他の要素について一部ご説明します。
ESG のこちらの論文にまとめられている内容が、私たちのシナリオに関連性があり、かつ正確な内容となっています。この論文では、ワークロードが同等である場合、BigQuery の TCO は競合他社と比較して 26%~34% 低いことが報告されています。
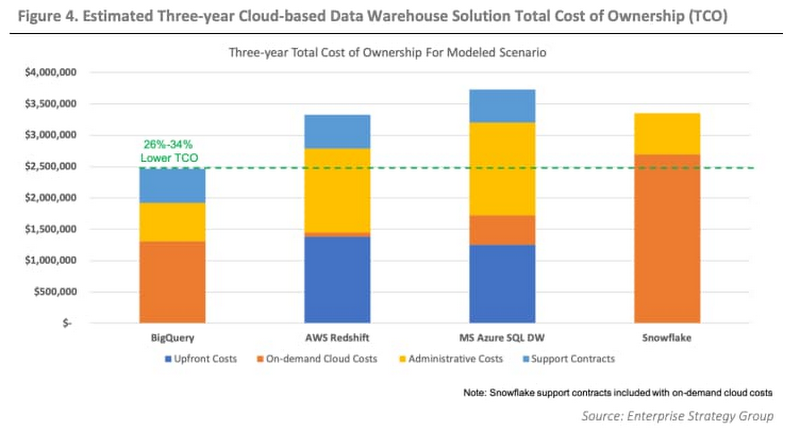
その他には、以下のような要因について考慮しました。
容量とプロビジョニングの効率化
スケーリング
毎月 100 PB のストレージと 1 EB 以上のクエリ処理が必要なため、AC の統合 DW の 1 PB という制限は大きな障壁でした。
ストレージとコンピューティングの分離
また AC では、追加のストレージを購入しないと追加のコンピューティングを購入できないため、大幅かつ非常に高額なコンピューティングのオーバープロビジョニングが発生する可能性があります。
運用コストとメンテナンス コスト
サーバーレス
AC では、クエリのチューニング方法を確認するために、デイリー スタンドアップを行う必要がありました(好ましくないチームの時間の使い方です)。ユーザーがどの列を使用するか(推測の域で)事前に把握し、それに応じて物理スキーマとテーブル レイアウトを変更しなくてはなりませんでした。また、クエリのパフォーマンスを向上させるために、少なくとも週に 1 回データの再編成も行っていました。これには、最適なストレージ レイアウトとクエリのパフォーマンスを実現するために、データセット全体を読み取り、再度並べ替える作業が必要でした。さらに、ストレージ容量の使用率に関する予測に基づいて、どのような追加ノードが必要であるかを前もって(少なくとも数か月前までには)考えなくてはなりませんでした。
これはチームのエンジニアをかなりの時間拘束する作業となり、週に 20 を超える人的時間に相当するコストにつながるものと見積もりました。AC のアーキテクチャは複雑であり、真のサーバーレス環境ではこのワークロードを処理できないため、チームはデータの分散、そしてデータの読み込みとクエリの集約 / 最適化を管理して自動化するための追加のコードを記述したのです。この作業では、AC の制限事項を回避するためのツールの設計、コーディング、管理に、専任のエンジニア 2 人分の労力を費やさなくてはなりませんでした。ハードウェアを拡張するときには、このコストはさらに上昇します。私たちは、その人件費を TCO に含めました。しかし、BigQuery では、管理やキャパシティ プランニングがはるかに簡単になり、時間もほとんどかかりません。実際、追加データを BigQuery に送信する前に、チーム内で話し合うことすらほぼしなくなりました。BigQuery の使用により、メンテナンスやパフォーマンスのチューニングに費やす時間はゼロ、またはほんのわずかです。
生産性の向上
Google BigQuery をデータベースとして使用する利点の一つは、データモデルを簡素化し、当時の新しい BI ツールである Looker を活用してセマンティック レイヤを統一できることでした。私たちは、アナリストが Looker で BigQuery を使用して新しいダッシュボードを作成するのにかかる時間を計り、それを従来の BI ツールを使用した AC での類似の開発と比較しました。アナリストがダッシュボードの作成にかかる時間は 1~4 時間からわずか 10 分に短縮され、全体的な生産性を 90% 以上も改善できました。この改善の最大の理由として、使用するデータモデルが非常にシンプルになったこと、そしてすべてのデータセットを 1 つのデータベースにまとめられるようになったことが挙げられます。毎月、数百ものダッシュボードや分析を行っているため、1 ダッシュボードあたり約 1 時間の節約することで、数千の人的時間を組織の生産性向上に回すことができます。
AC と比較した場合、BigQuery のピーク時におけるワークロードの処理方法も、ユーザー エクスペリエンスと生産性に大きなメリットをもたらしています。ユーザーが AC にログインしてクエリを実行し始めると、ワークロードが原因で動作しなくなってしまいました。クエリのパフォーマンスがグレースフル デグラデーションする代わりに、ワークロードの大規模なキューイングが発生していたのです。そのため、クエリの完了を待つユーザーと、他のクエリを完了できるように高コストのクエリを特定して強制終了させるために慌てるエンジニアとの間で、相互にイライラが募ってしまいました。
TCO に関するまとめ
財務、容量、メンテナンスの容易さ、生産性の向上という面において、BigQuery は AC よりも総所有コストが低く、圧倒的な優位性を誇っています。
TCO の削減: BigQuery
ラウンド 5: 目に見えない価値
テストのこの時点で、技術面での結果は確実に BigQuery を示していました。Google アカウント、プロダクト、エンジニアリングの各チームとも協力して、非常に有意義な経験を得ることができました。Google は Yahoo とのやり取りにおいて、透明性があり正直で謙虚でした。また、Google Cloud のデータ分析プロダクト チームは、非常に価値ある顧客評議会を月に一度開催しています。
私たちが、プロトタイピングのプロジェクトでこのような成功を収め、最終的に移行したもう 1 つの理由は、Google チームとの関係にあります。優れたサポート エンジニアに支えられたアカウント チームは、常に問題を把握して巧みに解決してくれました。
サポートと全体的なカスタマー エクスペリエンス
POC に関するまとめ
POC の設計にあたり、本番環境のワークロード、データ量、使用状況の負荷を複製しました。この POC の成功基準は、本番環境と同じ SLA を実現することであり、POC で本番環境のサブセットをミラーリングするという戦略は功を奏しました。データ ウェアハウスの機能を完全にテストした結果、選択した技術、プロダクト、サポートチームは、現在のワークロードのみならず、将来的なワークロードのスケーリングにおいても SLA を満たすものと確信しています。
最後になりますが、POC の規模と設計は、本番環境のワークロードを十分に体現しているといえます。そのため、Verizon 内の他のチームもこの結果を使用して独自の選択に役立てることができます。Verizon の他のチームが BigQuery に移行しているのを見てきましたが、私たちの取り組みが少なからず影響を与えていると感じています。
以下は、最終的に BigQuery を選ぶ決め手となった、概念実証の結果を総合的にまとめたものです。
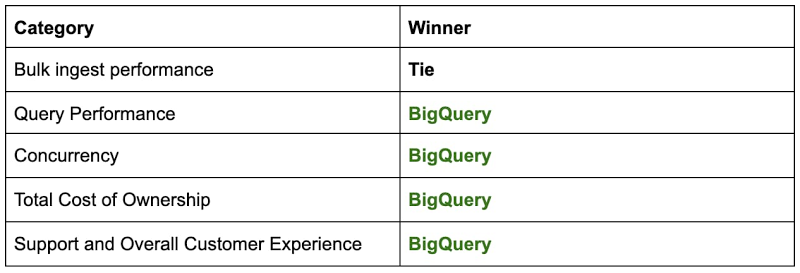
これらの結果から、AC ではなく BigQuery のバックエンドにヒットするダッシュボードの数を増やして、より多くの本番環境の作業を BigQuery に移行するという結論に至りました。ますます多くのユーザー、トラフィック、データを追加するのに伴い、BigQuery がストレージ、コンピューティング、同時実行、取り込み、信頼性をスケールし続けたため、非常にスムーズにロールアウトを完了できました。このシリーズの次回のブログ投稿では、本番環境で BigQuery を駆使した体験についてご説明する予定です。
-Verizon Media 社シニア エンジニアリング ディレクター Nikhil Mishra 氏




{kind=link}