Why Verizon Media picked BigQuery for scale, performance and cost
Nikhil Mishra
Sr. Director of Engineering, Verizon Media
As the owner of Analytics, Monetization and Growth Platforms at Yahoo, one of the core brands of Verizon Media, I'm entrusted to make sure that any solution we select is fully tested across real-world scenarios. Today, we just completed a massive migration of Hadoop and enterprise data warehouse (EDW) workloads to Google Cloud’s BigQuery and Looker.
In this blog we’ll walk through the technical and financial considerations that led us to our current architecture. Choosing a data platform is more complicated than just testing it against standard benchmarks. While benchmarks are helpful to get started, there is nothing like testing your data platform against real world scenarios. We’ll discuss the comparison that we did between BigQuery and what we’ll call the Alternate Cloud (AC), where each platform performed best, and why we chose BigQuery and Looker. We hope that this can help you move past standard industry benchmarks and help you make the right decision for your business. Let’s get into the details.
What is a MAW and how big is it?
Yahoo’s MAW (Media Analytics Warehouse) is the massive data warehouse which houses all the clickstream data from Yahoo Finance, Yahoo Sports, Yahoo.com, Yahoo Mail, Yahoo Search and various other popular sites on the web that are now part of Verizon Media. In one month in Q4 2020, running on BigQuery, we measured the following stats for active users, number of queries, and bytes scanned, ingested, and stored.

Who uses the MAW data and what do they use it for?
Yahoo executives, analysts, data scientists, and engineers all work with this data warehouse. Business users create and distribute Looker dashboards, analysts write SQL queries, scientists perform predictive analytics and the data engineers manage the ETL pipelines. The fundamental questions to be answered and communicated generally include: How are Yahoo’s users engaging with the various products? Which products are working best for users? And how could we improve the products for better user experience?
The Media Analytics Warehouse and analytics tools built on top of it are used across different organizations in the company. Our editorial staff keeps an eye on article and video performance in real time, our business partnership team uses it to track live video shows from our partners, our product managers and statisticians use it for A/B testing and experimentation analytics to evaluate and improve product features, and our architects and site reliability engineers use it to track long-term trends on user latency metrics across native apps, web, and video. Use cases supported by this platform span across almost all business areas in the company. In particular, we use analytics to discover rends in access patterns and in which partners are providing the most popular content, helping us assess our next investments. Since end-user experience is always critical to a media platform’s success, we continually track our latency, engagement, and churn metrics across all of our sites. Lastly, we assess which cohorts of users want which content by doing extensive analyses on clickstream user segmentation.
If this all sounds similar to questions that you ask of your data, read on. We’ll now get into the architecture of products and technologies that are allowing us to serve our users and deliver these analytics at scale.
Identifying the problem with our old infrastructure
Rolling the clock back a few years, we encountered a big problem: We had too much data to process to meet our users’ expectations for reliability and timeliness. Our systems were fragmented and the interactions were complex. This led to difficulty in maintaining reliability and it made it hard to track down issues during outages. That leads to frustrated users, increasingly frequent escalations, and the occasional irate leader.
Managing massive-scale Hadoop clusters has always been Yahoo’s forte. So that was not an issue for us. Our massive-scale data pipelines process petabytes of data every day and they worked just fine. This expertise and scale, however, were insufficient for our colleagues’ interactive analytics needs.
Deciding solution requirements for analytics needs
We sorted out the requirements of all our constituent users for a successful cloud solution. Each of these various usage patterns resulted in a disciplined tradeoff study and led to four critical performance requirements:
Performance Requirements
Loading data requirement: Load all previous day’s data by next day at 9am. At forecasted volumes, this requires a capacity of more than 200TB/day.
Interactive query performance: 1 to 30 seconds for common queries
Daily use dashboards: Refresh in less than 30 seconds
Multi-week data: Access and query in less than one minute.
The most critical criteria was that we would make these decisions based on user experience in a live environment, and not based on an isolated benchmark run by our engineers.
In addition to the performance requirements, we had several system requirements that spanned the multiple stages that a modern data warehouse must accommodate: simplest architecture, scale, performance, reliability, interactive visualization, and cost.
System Requirements
Simplicity and architectural integrations
ANSI SQL compliant
No-op/serverless—ability to add storage and compute without getting into cycles of determining the right server type, procuring, installing, launching, etc.
Independent scaling of storage and compute
Reliability
Reliability and availability: 99.9% monthly uptime
Scale
Storage capacity: hundreds of PB
Query capacity: exabyte per month
Concurrency: 100+ queries with graceful degradation and interactive response
Streaming ingestion to support 100s of TB/day
Visualization and interactivity
Mature integration with BI tools
Materialized views and query rewrite
Cost-efficient at scale
Proof of concept: strategy, tactics, results
Strategically, we needed to prove to ourselves that our solution could meet the requirements described above at production scale. That meant that we needed to use production data and even production workflows in our testing. To focus our efforts on our most critical use cases and user groups, we focused on supporting dashboarding use cases with the proof-of-concept (POC) infrastructure. This allowed us to have multiple data warehouse (DW) backends, the old and the new, and we could dial up traffic between them as needed. Effectively, this became our method of doing a staged rollout of the POC architecture to production, as we could scale up traffic on the CDW and then do a cut over from legacy to the new system in real time, without needing to inform the users.
Tactics: Selecting the contenders and scaling the data
Our initial approach to analytics on an external cloud was to move a three petabyte subset of data. The dataset we selected to move to the cloud also represented one complete business process, because we wanted to transparently switch a subset of our users to the new platform and we did not want to struggle with and manage multiple systems.
After an initial round of exclusions based on the system requirements, we narrowed the field to two cloud data warehouses. We conducted our performance testing in this POC on BigQuery and “Alternate Cloud.” To scale the POC, we started by moving one fact table from MAW (note: we used a different dataset to test ingest performance, see below). Following that, we moved all the MAW summary data into both clouds. Then we would move three months of MAW data into the most successful cloud data warehouse, enabling all daily usage dashboards to be run on the new system. That scope of data allowed us to calculate all of the success criteria at the required scale of both data and users.
Performance testing results
Round 1: Ingest performance.
The requirement is that the cloud load all the daily data in time to meet the data load service-level agreement (SLA) of “by 9 am the next day”—where day was local day for a specific time zone. Both the clouds were able to meet this requirement.
Bulk ingest performance: Tie
Round 2: Query performance
To get an apples-to-apples comparison, we followed best practices for BigQuery and AC to measure optimal performance for each platform. The charts below show the query response time for a test set of thousands of queries on each platform. This corpus of queries represents several different workloads on the MAW. BigQuery outperforms AC particularly strongly in very short and very complex queries. Half (47%) of the queries tested in BigQuery finished in less than 10 sec compared to only 20% on AC. Even more starkly, only 5% of the thousands of queries tested took more than 2 minutes to run on BigQuery whereas almost half (43%) of the queries tested on AC took 2 minutes or more to complete.
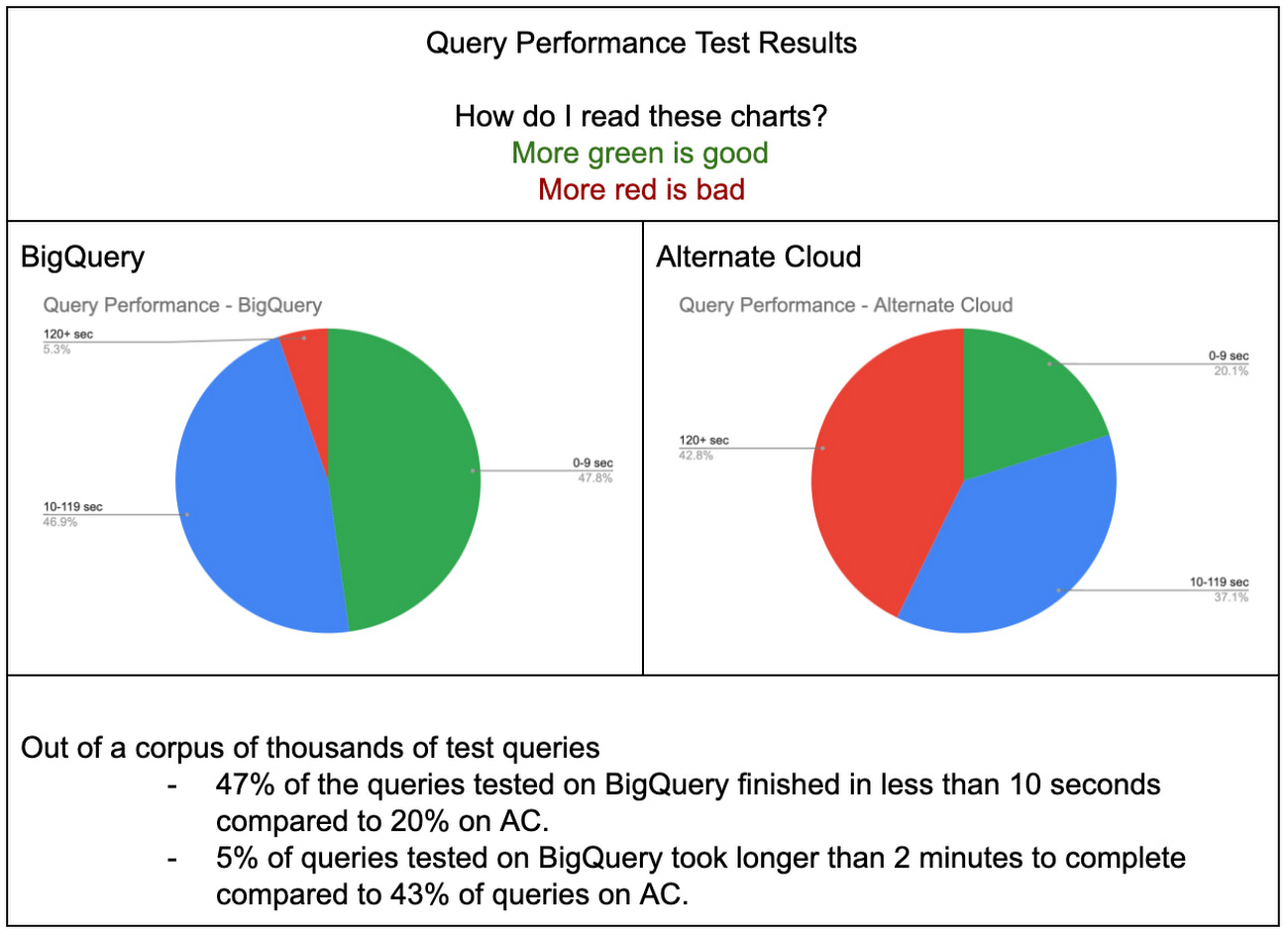
Query performance: BigQuery
Round 3: Concurrency
Our results corroborated this study from AtScale: BigQuery’s performance was consistently outstanding even as the number of concurrent queries expanded.
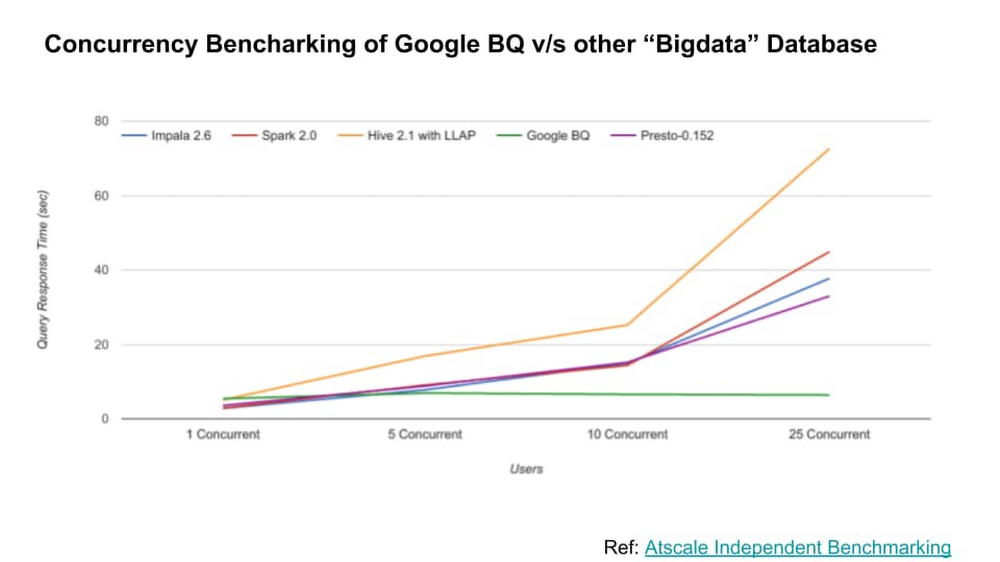
Concurrency at scale: BigQuery
Round 4: Total cost of ownership
Though we can’t discuss our specific economics in this section, we can point to third-party studies and describe some of the other aspects of TCO that were impactful.
We found the results in this paper from ESG to be both relevant and accurate to our scenarios. The paper reports that for comparable workloads, BigQuery’s TCO is 26% to 34% less than competitors.
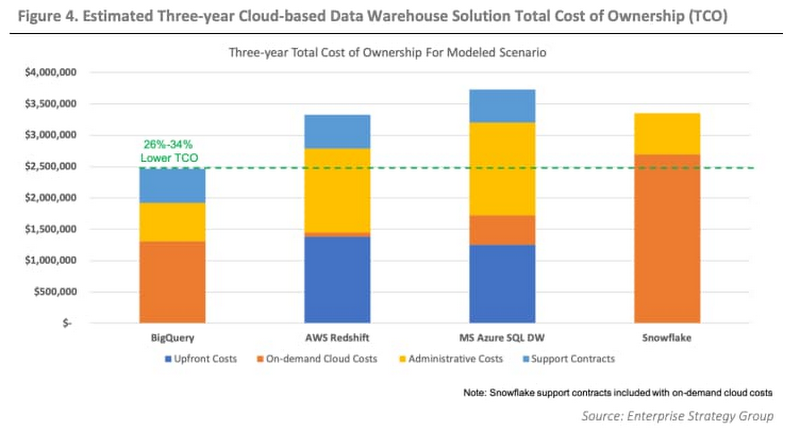
Other factors we considered included:
Capacity and Provisioning Efficiency
Scale
With 100PB of storage and 1EB+ of query over those bytes each month, AC’s 1PB limit for a unified DW was a significant barrier.
Separation of Storage and Compute
Also with AC, you cannot buy additional compute without buying additional storage, which would lead to significant and very expensive overprovisioning of compute.
Operational and Maintenance Costs
Serverless
With AC, we needed a daily standup to look at ways of tuning queries (a bad use of the team’s time). We had to be upfront about which columns would be used by users (a guessing game) and alter physical schema and table layout accordingly. We also had a weekly “at least once” ritual of re-organizing the data for better query performance. This required reading the entire data set and sorting it again for optimal storage layout and query performance. We also had to think ahead of time (at least by a couple of months) about what kind of additional nodes were required based on projections around capacity utilization.
We estimated this tied up significant time for engineers on the team and translated into a cost equivalent to 20+ person hours per week. The architectural complexity on the alternate cloud - because of its inability to handle this workload in a true serverless environment - resulted in our team writing additional code to manage and automate data distribution and aggregation/optimization of data load and querying. This required us to dedicate effort equivalent to two full time engineers to design, code and manage tooling around alternate cloud limitations. During a time of material expansion, this cost would go up further. We included that personnel cost in our TCO. With BigQuery, the administration and capacity planning has been much easier, taking almost no time. Infact, we barely even talk within the team before sending additional data over to Bigquery. With BigQuery we spend zero/little time doing maintenance or performance tuning activities.
Productivity Improvements
One of the advantages of using Google BigQuery as the database, was that we could now simplify our data model and also unify our semantic layer by leveraging a then new BI tool - Looker. We timed how long it took our analysts to create a new dashboard using BigQuery with Looker and compared it to a similar development on AC with a legacy BI tool. The time for an analyst to create a dashboard went from one to four hours to just 10 minutes - a 90+% productivity improvement across the board. The single biggest reason for this improvement was a much simpler data model to work with and the fact that all the datasets could now be together in a single database. With hundreds of dashboards and analysis conducted every month, saving about one hour per dashboard returns thousands of person-hours in productivity to the organization.
The way BigQuery handles peak workloads also drove a huge improvement in user experience and productivity versus the AC. As users logged-in and started firing their queries on the AC, they would get stuck because of the workload. Instead of a graceful degradation in query performance, we saw a massive queueing up of workloads. That created a frustrating cycle of back-and-forth between users, who were waiting for their queries to finish, and the engineers, who would be scrambling to identify and kill expensive queries, to allow for other queries to complete.
TCO Summary
In these dimensions—finances, capacity, ease of maintenance and productivity improvements— BigQuery was the clear winner with a lower total cost of ownership than the alternative cloud.
Lower TCO: BigQuery
Round 5: The intangibles
At this point in our testing, the technical outcomes were pointing solidly to BigQuery. We had very positive experiences working with the Google account, product and engineering teams as well. Google was transparent, honest and humble in their interactions with Yahoo. In addition, the data analytics product team at Google Cloud conducts monthly meetings of a customer council that have been exceedingly valuable.
Another reason why we saw this kind of success with our prototyping project, and eventual migration, was the Google team with whom we engaged. The account team, backed by some brilliant support engineers stayed on top of issues and resolved them expertly.
Support and Overall Customer Experience
POC Summary
We designed the POC to replicate our production workloads, data volumes, and usage loads. Our success criteria for the POC were the same SLAs that we have for prod. Our strategy of mirroring a subset of our production with the POC paid off well. We fully tested the capabilities of the data warehouses; and consequently we have very high confidence that the chosen tech, products, and support team will meet our SLAs at our current load and future scale.
Lastly, the POC scale and design are sufficiently representative of our prod workloads that other teams within Verizon can use our results to inform their own choices. We’ve seen other teams in Verizon move to BigQuery, at least partly informed by our efforts.
Here’s a roundup of the overall proof-of-concept trial that helped us pick BigQuery as the winner:
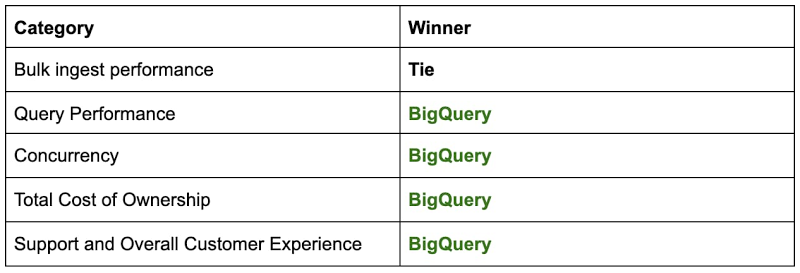
With these results, we concluded that we would move more of our production work to BigQuery by expanding the number of dashboards that hit the BigQuery backend as opposed to Alternate Cloud. The experience of that rollout was very positive, as BigQuery continued to scale in storage, compute, concurrence, ingest and reliability as we added more and more users, traffic, and data. I’ll explore our experience fully using BigQuery in production in the second blog post of this series.


