BigQuery 管理者リファレンス ガイド: ストレージの仕組み

Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery 管理者リファレンス ガイド シリーズではこれまで、BigQuery 内で利用できるさまざまな論理リソースについて説明してきました。ここからは BigQuery のアーキテクチャについて解説していきます。この投稿では、BigQuery でデータをネイティブ ストレージに保存する方法と、データ保存の最適化に有効な手法について詳しく説明します。
カラム型ストレージ形式
BigQuery には、フルマネージド ストレージが用意されているので、サーバーをプロビジョニングする必要がありません。サイジングは自動的に行われ、使用分に対してのみ料金が発生します。BigQuery は大規模なデータ分析用に設計されているので、データはカラム型形式で保存されます。
Postgres や MySQL などの従来のリレーショナル データベースでは、データはレコード指向のストレージに 1 行ずつ保存されます。そのため、データの読み取りや書き込みに 1 つの行を開くだけでよいので、トランザクションの更新や OLTP (オンライン トランザクション処理)のユースケースに適しています。しかし、列全体を合計するなどの集計を行う場合は、テーブル全体をメモリに読み込む必要があります。
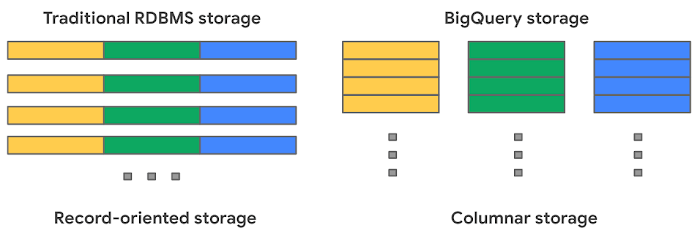
BigQuery は、各列が独立したファイル ブロックに保存されるカラム型ストレージを使用しており、OLAP(オンライン分析処理)のユースケースの理想的なソリューションとなっています。集計を行う際、読み取る対象を集計する列のみに限定することができるのです。
最適化されたストレージ形式
BigQuery の内部では、Capacitor と呼ばれる独自のカラム型形式でデータが保存されます。前述のとおり、Capacitor は列指向の形式です。各フィールドまたは列の値は個別に保存されるので、ファイル読み込みのオーバーヘッドは、実際に読み込むフィールドの数に比例します。これは、必ずしも各列がそれぞれ独自のファイルにあるということではなく、各列が 1 つのファイル ブロックに保存されるということです。ファイル ブロックは、最適化のために実際には個別に圧縮されます。
Capacitor の利点は、データの種類(非常に長い文字列か整数型かなど)やデータの使用法(WHERE 句でフィルタとして使用される可能性が高い列であるなど)といった関連要素を取り込む近似モデルを構築できることです。そのモデルによって、行の再シャッフルや列のエンコードを行うことが可能になります。各列をエンコードしている間に、BigQuery はデータに関するさまざまな統計情報を収集します。この情報は保持され、後でクエリの実行中に使用されます。

Capacitor の詳細については、Google の BigQuery 最高責任者によるこちらのブログ投稿をご覧ください。
暗号化と耐久性管理
データが特定のファイルに保存される方法が理解できたところで、こうしたファイルが実際にはどこにあるのかという点も考えましょう。BigQuery の永続性レイヤは、Google の分散ファイル システムである Colossus によって提供されます。データの圧縮、暗号化、レプリケート、分散は自動的に行われます。
Google Cloud Platform には、不正アクセスに対するさまざまなレベルの防御策があります。たとえば、データが保存時に 100% 暗号化されるよう設定したり、顧客管理の暗号鍵を使用してご自身で暗号化を制御したりすることができます。
Colossus では、イレージャー エンコーディングまたは消失訂正符号化と呼ばれる手法で耐久性も確保されます。この手法により、データはフラグメントに分割され、冗長性を持たせた断片として複数のディスクで保存されます。また、データの耐久性だけでなく可用性も確保するために、データはデータセット作成時に指定されたのと同じリージョン内にある別のアベイラビリティ ゾーンにレプリケートされます。

これはつまり、異なる電力システムとネットワークを持つ別々の建物にデータが保存されるということであり、そうした異なるアベイラビリティ ゾーンが同時にオフラインになる可能性は非常に低いと言えます。ただし、米国や EU などの「マルチ リージョン」ロケーションを使用する場合、BigQuery はデータのもう 1 つのコピーをオフリージョン レプリカに保存します。このようにして、大規模な災害が発生した際にデータを復旧できるようにしています。
こうした機能はすべて、クエリに使用するコンピューティング リソースに影響を及ぼすことなく利用できます。また、エンコード、暗号化、レプリケートは BigQuery ストレージの料金に含まれており、隠れコストはありません。
クエリ パフォーマンスに合わせてストレージを最適化
BigQuery にはストレージの最適化機能があらかじめ組み込まれており、これによってファイルが定期的に書き換えられ、クエリに最適な形にデータが調整されます。ファイルは、初めは書き込みが速い形式で書き込まれるとしても、後で BigQuery により、クエリを速く実行できる形式に変換されます。こうした見えないところで行われる最適化の他に、ストレージをさらに強化するためにユーザーが自分で行えることもいくつかあります。
パーティショニング
パーティション分割テーブルは、パーティションと呼ばれるセグメントに分割された特別なテーブルです。BigQuery は、パーティショニングを活用して、ワーカーがディスクから読み込むデータ量を最小限に抑えます。パーティショニング列にフィルタがあるクエリを使用すると、スキャンされるデータ全体を大幅に削減できるので、パフォーマンスが向上し、オンデマンド クエリのクエリコストが抑えられます。パーティション分割テーブルに書き込まれた新しいデータは、適切なパーティションに自動的に配信されます。

BigQuery は、パーティション分割テーブルの作成方法として次のものをサポートしています。
取り込み時間パーティション分割テーブル: データが BigQuery に取り込まれた時間を反映する日単位のパーティションです。このオプションは、新しいデータが追加された時間に基づいてデータをフィルタリングする場合に有効です。たとえば、新たに発表された Google トレンド データセットは毎日更新されるので、最新のトレンドだけを取得するといったことが可能です。
時間単位列パーティション分割テーブル: パーティショニング列の日付の値に基づき、BigQuery がデータを適切なパーティションにルーティングします。パーティション作成にあたっての最小粒度は 1 時間単位です。このオプションは、テーブルの日付の値に基づいてデータをフィルタリングする場合に有効です。たとえば、transaction_created_date を使用した WHERE 句を含めることで、最新のトランザクションを確認するといった使い方ができます。
整数範囲パーティション分割テーブル: バケット化できる整数列に基づいてパーティショニングを行います。このオプションは、テーブルの整数列に基づいてデータをフィルタリングする場合に有効です。たとえば、customer_id を使用して特定の顧客に注目するといった使い方ができます。整数値をバケット化して、0~100 の ID を持つ顧客はすべて同じパーティションに配置するというように、適切なサイズのパーティションを作成できます。
パーティショニングは、クエリのパフォーマンスを最適化するための優れた方法です。特に、分析中によくフィルタが使用される大きなテーブルに効果的です。適切なパーティション キーを決めるときは、組織内で皆がテーブルをどのように利用しているかを必ず考慮してください。コストの高いクエリが生じる可能性がある大きなテーブルには、パーティションの使用を必須にすると良いかもしれません。
パーティションは、データ量は膨大であるものの固有値が少ないという条件を想定して設計されています。目安として、パーティションは 1 GB 以上にすることをおすすめします。テーブルを過剰にパーティショニングすると、多くのメタデータが作成されます。すると、多くのパーティションで読み込みが行われ、クエリはむしろ遅くなる可能性があります。
クラスタリング
BigQuery でテーブルがクラスタ化される際、データは 1 つから 4 つの列(指定可能)の内容に基づいて自動的に並べ替えられます。クラスタリングには通常、カーディナリティの高い非時間列が推奨されます。対照的に、パーティショニングにはカーディナリティの低いフィールドが適しています。パーティショニングとクラスタリングは、どちらか一方を選択しなければいけないわけではありません。1 つのテーブルで両方実施できます。

クラスタ化列の順序によって、データの並べ替え順序が決まります。新しいデータがテーブルまたは特定のパーティションに追加されると、BigQuery は課金なしで、バックグラウンドでの自動再クラスタリングを行います。具体的には、クラスタリングによって以下のようなクエリのパフォーマンスが向上します。
クラスタ化列を WHERE 句に含むクエリ: BigQuery は並べ替えられたブロックを使用して不要なデータのスキャンを回避します。WHERE 句ではフィルタの順序が重要なので、最初にクラスタリングを利用するフィルタを使用してください。
クラスタ化列の値に基づいてデータを集計するクエリ: ブロックの並べ替えによって類似の値を持つ行が並置されるためパフォーマンスが向上します。
テーブルのクラスタ化に使用された列をキーとする結合を含むクエリ: スキャンされるデータが少なくなり、クエリによってはパーティショニング以上にパフォーマンスが向上します。
さらに詳しい情報や、クエリの例を確認するには、こちらのブログ投稿をご覧ください。
非正規化
従来のデータベースの使用経験があれば、正規化されたスキーマの作成には慣れていることでしょう。これにより、データが繰り返されないように構造を最適化できます。(前述のとおり)これは、データを更新することが多い OLTP ワークロードにとって重要です。購入客の住所の保存を購入した場所でいちいち行っていると、住所変更の際に更新が面倒になることが考えられます。
しかし、正規化されたスキーマでの分析オペレーションには通常、複数のテーブルを結合する必要があります。代わりにデータを非正規化すると、情報(顧客の住所など)が繰り返されて同じテーブルに保存されます。そうすると、クエリに JOIN 句を含める必要がなくなります。特に BigQuery では、ネスト構造と繰り返し構造を利用することもできます。STRUCT と ARRAY を使用してレコードを表現すると、基になるデータをより自然に表現できるだけでなく、場合によっては GROUP BY ステートメントを使用する必要がなくなります。たとえば、COUNT の代わりに ARRAY_LENGTH を使用できます。

非正規化にはいくつかの欠点があるので注意してください。まず、ストレージ面では最適化されていません。ただし、BigQuery はストレージが低コストなので、この点が問題になることはあまりありません。次に、データの整合性を維持するため、マシンの稼働時間と場合によってはテストと検証に人間が対応する時間が増大します。非正規化の前にパーティショニングとクラスタリングを実施し、それから更新がほとんど必要ないデータを対象にすることをおすすめします。
ストレージ費用の最適化
BigQuery でのストレージ費用を最適化するにあたっては、不要なテーブルとパーティションの削除に取り組んでください。データセットのデフォルトのテーブル有効期限、テーブルの有効期限、パーティション分割テーブルのパーティションの有効期限をそれぞれ構成します。これは、アドホック ワークフロー用にマテリアライズド ビューやテーブルを作成する場合や、ごく最近のデータにだけアクセスできればよい場合に特に役立ちます。
さらに、BigQuery の長期保存も活用できます。90 日間にわたり一度も使用されていないテーブルがある場合、そのテーブルのストレージの料金は自動的に 50% 値引きされ、毎月 1 GB あたり $0.01 になります。これは Cloud Storage Nearline と同じ費用なので、使用していない古いデータを Cloud Storage にエクスポートするのではなく、BigQuery に保持したままにしたほうが賢明な場合があります。
ご覧くださりありがとうございました。次回はクエリ処理について説明します。トラブルシューティングと費用削減に役立つクエリ最適化の前提となる内容ですのでご期待ください。このシリーズの最新情報を見逃さないよう、LinkedIn や Twitter でフォローしていただけたら幸いです。
-デベロッパー アドボケイト Leigha Jarett




