BigQuery 管理者リファレンス ガイド: クエリの最適化

Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
先週の BigQuery 管理者リファレンス ガイドでは、クエリの実行とクエリプランを活用する方法について説明しました。今週はより踏み込んで、より高度なクエリや戦術的最適化手法についてご説明します。クエリのコンセプトや、関連する SQL の最適化手法についてお話ししましょう。
データのフィルタリング
先週の投稿で説明しましたので、クエリ実行の詳細から、(永続ストレージ、フェデレーション テーブル、メモリ シャッフルのいずれかからの)データの読み取り、および(メモリシャッフル、永続ストレージのいずれかへの)データの書き込みにかかった時間を確認できることはすでにご存じかと思います。クエリで使用されるデータ量や、次のステージに返されるデータ量を制限することは、クエリの高速化や効率化に有効です。
最適化の手法
1. 必要なカラムのみ: 必要なカラムだけを取得します(特に内部クエリの場合)。SELECT * はコスト効率が悪く、パフォーマンスを低下させる可能性もあります。返されるカラム数が多い場合は、SELECT * EXCEPT を使用して不要なカラムを除外することを検討します。
2. パーティションやクラスタによる自動プルーニング: BigQuery ストレージの投稿で説明したように、パーティションとクラスタがデータの分割や並べ替えに使用されます。データがパーティショニングまたはクラスタリングされている列にフィルタを使用することで、スキャンされるデータ量を大幅に削減できます。
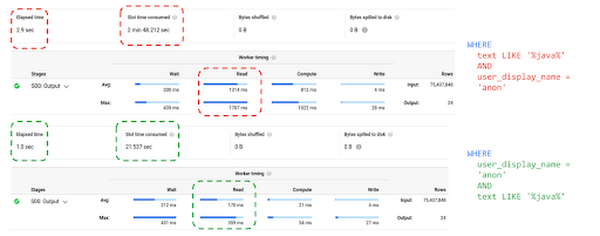
3. 式の順番が重要: BigQuery は WHERE 句で指定されている式の順序が最適だと想定し、式の順序を変更することはありません。WHERE 句には、最もデータを絞り込むことのできる式を最初に並べる必要があります。以下の最適化されたクエリでは、コストの高い LIKE 式を列のコンテンツすべてに対して実行せずに、ユーザー名が「anon」のコンテンツに対してのみ実行するため、処理が速くなります。
4. ORDER BY と LIMIT を指定する: ORDER BY 句を使用してクエリの結果を書き込むと、Resources Exceeded のエラーが発生する場合があります。最終的な並べ替え作業は単一のワーカーで実行される必要があるため、大規模な結果セットを並べ替える場合、データを処理するスロットに大きな負荷がかかることがあります。大量の値を並べ替える場合は、最後のスロットに渡されるデータ量を制限する LIMIT 句を使用します。
集計について
集計クエリの場合は、それぞれのワーカーで GROUP BY が実行され、同じキーを持つ Key-Value ペアが同じワーカーに入るようにシャッフルされます。その後さらに集計が行われ、単一のワーカーに渡された後、結果が提供されます。
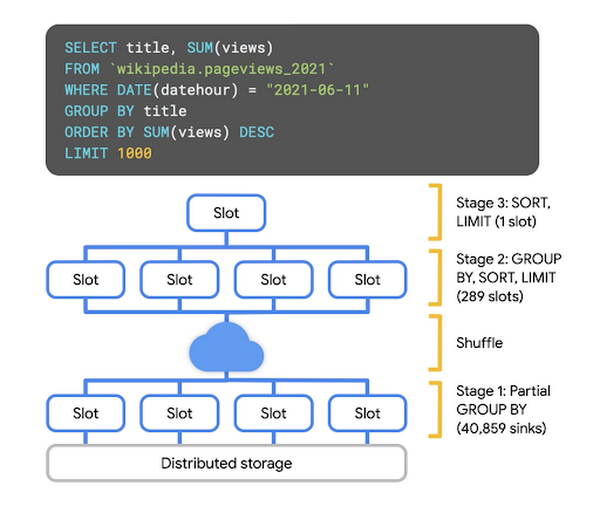
再パーティショニング
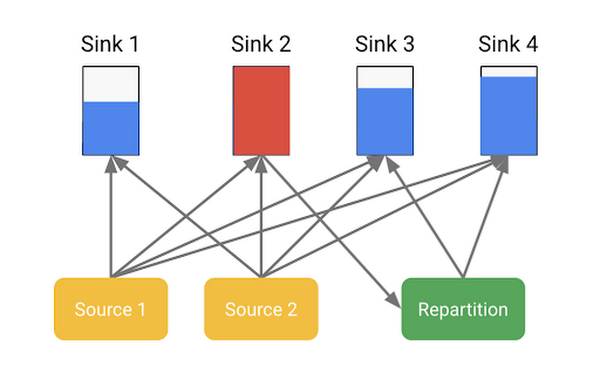
大量のデータが 1 つのワーカーに入った場合、BigQuery によりそのデータが再度パーティショニングされることがあります。以下の例で考えてみましょう。ソースはまず、シンク 1 とシンク 2(メモリ シャッフル層内のパーティション)に書き込みを開始します。次に、シャッフル モニターによりシンク 2 が上限超過であることが検出されます。ここで、パーティショニング スキームが変更され、ソースはシンク 2 への書き込みを停止し、代わりにシンク 3 およびシンク 4 への書き込みを開始します。
最適化
1. 集計は後で行う: 集計の処理には過大なコストがかかるため、できるだけ少なく、できるだけ後で行うようにします。ただし、結合する前に集計することでテーブルを大幅に削減できる場合は、早い段階で集計します(詳細は後述)。
たとえば、以下のようなクエリで、サブクエリと最後の SELECT の両方で集計するのではなく、
以下の外部クエリのように、一度だけ集計するようにします。
2. 繰り返しデータをネストする: 小売取引のデータを含むテーブルがあるとします。1 行が 1 つの注文に対応するようにして、ARRAY フィールドで商品項目をネストするようにすれば、GROUP BY を不要にすることができます。たとえば、ARRAY_LENGTH を使用すれば、任意の注文における商品項目の数を確認できます。
結合について
BigQuery の強力な機能の 1 つとして、データを結合して、異なるソースの関係性や相関を確認できることがあります。JOIN 構文の多くは、そのデータをどのように組み合わせるかや、情報が一致しない場合にデータをどのように処理するかを表現することに関するものです。ただし、その関係がエンコードされた後でも、BigQuery はそれを実行する必要があります。
ハッシュベースの結合
まず、大規模な結合操作から説明しましょう。共通のキーを含む 2 つのテーブルを結合する際、BigQuery では、ハッシュベースの結合(または単にハッシュ結合)という手法がよく用いられます。この手法では、調整ノードでデータを移動せずに、複数のワーカーを使用してテーブルを処理できます。
では、ハッシュとはいったい何でしょうか。入力値がハッシュ化されると、その値は既知の範囲に収まる何がしかの値に変換されます。ハッシュ結合に関して、注意すべきハッシュ関数の性質は数多くありますが、その中でも重要なものは、ハッシュ関数が決定論的(同じ入力値は必ず同じ出力値を生成する)であることと、均一性(出力値が許容数値範囲内で均一に分散する)があることです。
適切なハッシュ関数であれば、出力を値のバケット化に使用できます。たとえば、ハッシュ関数が 0~1 の浮動小数点値を生成する場合には、このキー範囲を N 個(N は必要なバケットの数)の部分に分割することで値をバケット化できます。このハッシュ値に基づいてデータをグループ化すれば、各バケットにおよそ同じ数の離散値が入ることになり、またさらに重要なこととして、すべての重複値が同じバケットに入ることになります。
ハッシュの役割については以上ですので、次に結合について説明しましょう。
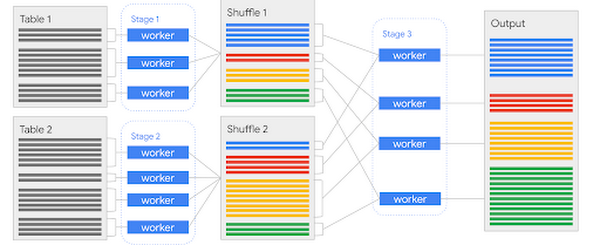
ハッシュ結合の実行は、次の 3 つのステージに分けることができます。
ステージ 1: 1 番目のテーブルを用意する
BigQuery では、テーブルのデータは通常、複数のカラム型ファイルに分割されていますが、これらのファイルの中で、結合キーを表す列の並べ替えがなされていて、なおかつ同じ場所に配置されているという保証はありません。そこで、ハッシュ関数をこの結合キーに適用して、必要なバケットに基づいて、異なるシャッフル パーティションに行を書き込みます。
上の図では、1 番目のテーブルに 3 つのカラム型ファイルがありますが、このデータがハッシュ化手法で 4 つのバケット(色分けで識別)に分割されています。ステージ 1 の完了後、1 番目のテーブルの行は、重複が共存した状態で 4 つの「ファイルのような」パーティションに効果的に分割され、シャッフルに書き込まれます。
ステージ 2: 2 番目のテーブルを用意する
この操作は実質的にステージ 1 と同じですが、データの結合先になるもう片方のテーブルに対して行われます。ここで最も重要なことは、データのアラインメントで同じハッシュ関数、同じバケット グループを使用する必要があるということです。上の図では、2 番目のテーブルには 4 つの入力ファイル、つまり 4 つの作業単位があり、このデータがシャッフル パーティションの 2 番目のセットに書き込まれます。
ステージ 3: アラインメントされたデータを使用して結合を実行する
ステージ 1 と 2 で、共通のハッシュ関数とバケット化戦略による 2 つのテーブルのデータのアラインメントが完了しました。つまり、共通のハッシュ範囲に対応するシャッフル パーティションのペアを、複数用意することができました。これにより、各ワーカーに結合操作のサブセットを実行するために必要な関連データのみが提供されるため、大規模なデータセットをスキャンせずに、結合を個別に実行できるようになります。
ここでは、目的の結合関係に応じて、元の入力テーブルの特定の入力行から行が生成されないことも、単一の行が生成されることも、大量の行が生成されることもあるという結合操作の性質に留意する必要があります。
またここで、優れたハッシュ関数を利用することが重要である理由がわかります。出力値の分散が不十分な場合、1 つのワーカーが作業負荷の大半を担い、遅延が発生するという問題が発生する可能性があります。また同様に、バケットの数が不適切な場合、作業負荷の分割が細かくなりすぎる(または荒くなりすぎる)という問題が発生する可能性があります。幸いなことに、これは動的計画を活用して修正できるため、克服できない問題ではありません(クエリステージを挿入して、シャッフル パーティションを調整するだけで修正できます)。
ブロードキャスト結合
ハッシュベースの結合は、多数のデータを結合する場合にきわめて有効な手法ですが、データがそれに見合うくらいの大きさではない場合もあります。結合するテーブルのいずれかが小さい場合には、そのすべてでアラインメント操作を実行しなくてもよくなります。
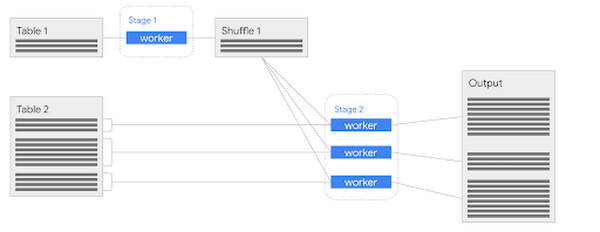
結合するテーブルのいずれかが小さい場合、ブロードキャスト結合が便利です。そのような場合には、アクセスを高速化するために、小さなテーブルをシャッフルしてから、他のテーブルの入力ファイルの処理を担当する各ワーカーにそのデータへの参照を渡すのが一番簡単です。
最適化の手法
最もサイズの大きいテーブルから: BigQuery のベスト プラクティスとして、最もサイズの大きいテーブルを最初に手動で配置し、その後に最もサイズの小さいテーブルを配置します。以降は、サイズの大きい順にテーブルを配置します。テーブルが特定の条件に該当する場合にのみ、BigQuery はテーブルサイズに基づいて自動的に並べ替えと最適化を行います。
結合前にフィルタリング: 結合するテーブルのサイズをできるだけ小さく抑えるために、WHERE 句はできるだけ早い段階で(特に結合内で)実行する必要があります。クエリ実行の詳細を確認して、フィルタリングが可能な限り早い段階で行われているかどうかを確認し、条件を修正するか、サブクエリを使用して JOIN の前にフィルタリングすることをおすすめします。
事前に集計してテーブルのサイズを制限する: すでに説明したように、結合する前にテーブルを集計することがパフォーマンスの改善に役立つ場合がありますが、これは、結合されるデータ量が大幅に削減される場合で、なおかつテーブルが同じレベルに集計される(結合するすべての Key-Value で 1 つの行しかない)場合に限ります。
結合キーでのクラスタリング: 結合に使用されるキーに基づいてテーブルをクラスタリングする場合、データがすでに共存しているため、ワーカーによりメモリ シャッフル内で必要なパーティションにデータを分割する操作が簡単になります。
詳細なクエリ: GitHub で人気のあるライブラリを見つける
ここまでで、データのフィルタリング、集計、結合のための最適化手法について学習できたので、複数の SQL 手法を使用した複雑なクエリについて見てみましょう。このクエリ実行の詳細をよく確認することで、クエリプランを移動するデータがどのように流れ、変化するかを理解できるはずです。また、この知識を応用すれば、自身の複雑なクエリの背後で何が起きているかを把握できるようになります。
この公開 GitHub データには、ソースコード ファイル名に関する情報を含むテーブルが 1 つあり、それとは別に、そのファイルの内容を含むテーブルが 1 つあります。この 2 つを組み合わせ、フィルタをかけて興味深いファイルに焦点を当て、これを分析することで、デベロッパーが頻繁に利用するライブラリがどれかを把握することができます。以下は、これを行うためのクエリの例であり、Go プログラミング言語を使用するデベロッパー向けです。このクエリは、適切な(.go)拡張子を持つファイルをスキャンし、ライブラリをインポートするためのソースコード内のステートメントを探し、それらのライブラリが使用される頻度と、それらを使用する個別のコード リポジトリの数をカウントします。
SQL では、次のようになります。
これを簡単に見てみると、サブクエリ、(コンテンツおよびファイル テーブルの)分散結合、配列操作(cross join unnest)、正規表現フィルタや区分計算といった強力な機能など、興味深い箇所が数多くあることがわかります。
詳細なステージとステップ
まず、このプランの全体像を図で確認してみましょう。この図には、クエリがどのように実行されるかに関して、低レベルの詳細が一連のステージとして示されています。各クエリステージの詳細を見てみましょう。ここに表示されているものと同様のグラフィック表現が必要な場合は、こちらのコードサンプルを確認してください。
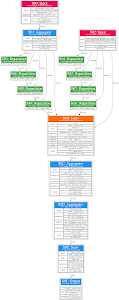
ステージ S00~S01: 「files」テーブルからの読み取りとフィルタリング
最初のステージ(SQL の内部サブクエリに対応)では、「files」テーブルを処理します。この最初のタスクでは、入力を読み取り、その入力をすぐにフィルタリングして、適切な接尾辞のあるファイルのみを抽出します。次に、ID とリポジトリ名に基づいてグループ化します。これは、多くの重複を処理する可能性があるものの、それぞれの個別のペアを一度に処理したいためです。ステージ S01 では、GROUP BY 操作を続行します。最初のステージの各ワーカーは、個々の入力ファイルのリポジトリと ID のペアの重複除去のみを行いましたが、この集計ステージではこれらを結合し、「files」テーブルのすべての入力行の重複を除去します。
ステージ S02: 「contents」テーブルの読み取り
このステージでは、「contents」テーブルのソースコードの読み取りを開始し、「import」ステートメント(Go 言語でライブラリを参照するための構文)を探します。ID(これが結合キーになります)と一致するコンテンツに関する情報を収集します。また、このステージと前のステージ(S01)で、出力が BY HASH 操作に基づいて分割されます。これは、ハッシュ結合の前段階であり、結合キーにアラインメント操作を行い個別のシャッフル パーティションに分割します。作業を分割したいデータを扱うときは、この操作でデータをシャッフル バケットに分割します。
ステージ S03~S0A: 再パーティショニング
このクエリでは、複数回の再パーティショニング ステージが呼び出されます。これは、実行グラフを介して機能する動的プランナーのリバランス データの例です。フィルタリングなどの操作でクエリステージに出入りするデータ量が大幅に変わる可能性があるため、適切なバケットを選択する内部処理の多くはヒューリスティックに基づいています。この特定のクエリでは、クエリプランが最適ではないバケット化戦略を選択してから、作業のバランス調整をそれ以降に行います。また、このパーティショニングが、結合する双方のデータで発生していることに注意してください。これは、結合前にパーティショニングしたデータを調整する必要があるためです。
ステージ S0B: 結合の実行
このステージで、2 つの入力のデータを関連付けます。このステージでは、2 つの入力読み取り(結合する双方に 1 つずつ)があり、カウントの計算が開始されます。ここでは、負荷の高い操作もあります。ファイルの内容を使用して、インポートされる個々のライブラリを表す配列を生成し、それを以降のステージで利用できるようにします。
ステージ S0C~S0D: 部分的な集計
この 2 つのステージでは、トップレベルの統計の計算を行います(各ライブラリが参照された合計回数と、個別のリポジトリの数がカウントされます)。これは、最終的に 2 つのステージに分割されます。
ステージ S0E~S0F: 並べ替えと制限
このクエリでは、最初に個別のリポジトリ数、次に合計使用頻度で並べ替え済みの、上位 1,000 個のライブラリのみがリクエストされます。最後の 2 つのステージでは、この並べ替えと削減を行い、最終的な結果を生成します。
その他の最適化手法
最後に、クエリのパフォーマンス改善に役立つ場合があるその他の最適化手法についてご紹介します。
複数の WITH 句: BigQuery の WITH ステートメントは、マクロに類似したものです。実行時、サブクエリの内容は、エイリアスが参照されるすべての場所にインライン化されます。そのため、プランが同じクエリステージを複数回実行することになるため、クエリプランが急増する可能性があります。その代わりに、TEMP テーブルを使用してください。
文字列比較: REGEXP_CONTAINS の機能はより充実していますが、LIKE よりも実行時間が長くなります。(ワイルドカードを条件に指定する場合など)正規表現の機能が必要でなければ、LIKE を使用してください。
最初または最後のレコード: データのサブセットで最初または最後のレコードを計算する際、単一のパーティションに ORDER BY 操作を行う要素が大量にある場合に ROW_NUMBER() 関数を使用すると、Resources Exceeded エラーで失敗する可能性があります。その代わりに、ARRAY_AGG() を使用してください。これにより、ORDER BY で各 GROUP BY の最上位レコード以外のすべてを削除できるため、効率的に実行できるようになります。たとえば、以下は、
次のようになります。




