BigQuery 管理者リファレンス ガイド: クエリ処理

Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery には複数の便利な機能が備わっています。正規表現に基づく何十億行ものスキャン、大きなテーブルの結合、1 つの SQL クエリだけを使った複雑な ETL タスクの実行などです。BigQuery(および一般的には SQL)の利点の一つは宣言型の性質を有することです。SQL によってユーザーの要求が示されますが、そのリクエストをどのように実現するかの決定はシステムが担当します。
ただし、このアプローチにも欠点があります。つまり、意図の理解という問題です。SQL は記述者と受け手(この場合は BigQuery)の会話を表します。作者が自分の意図をどれだけ忠実にコード化できるか、BigQuery がクエリをどれだけ効果的にレスポンスに変換できるかという点に、記述の適確さや変換などの要因が大きく影響する可能性があります。
今週の BigQuery 管理者リファレンス ガイドの投稿では、クエリ処理について踏み込んで解説していきます。BigQuery を統合しているデベロッパーや、クエリの最適化を試みている担当者やクエリのパフォーマンスに予約とスロットがどう影響するかを理解するための手引を求めている管理者の皆様に、この情報が役に立つことを願っています。
アーキテクチャの復習
クエリ処理の概要に進む前に、BigQuery のアーキテクチャをもう一度見てみましょう。先週は、左側の BigQuery のネイティブ ストレージについてお話ししました。今週は、BigQuery の検索エンジンである Dremel に焦点を当てます。今日は BigQuery の標準実行エンジンを取り上げますが、ほかにも高速のメモリ内分析に利用できる BI Engine というクエリ実行エンジンもあります。
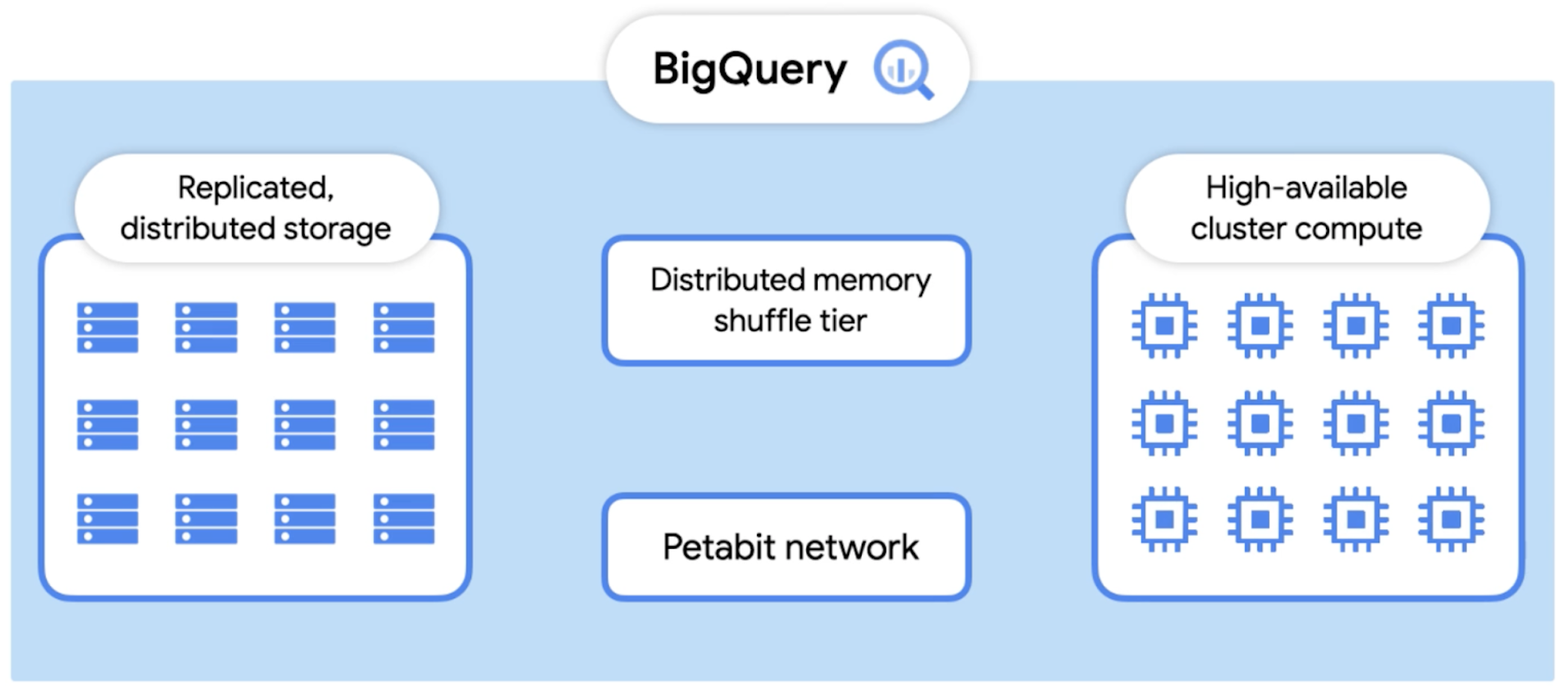
図からわかるように、Dremel はワーカーのクラスタで構成されています。これらのワーカーは、それぞれ独立して同時にタスクの一部を実行します。BigQuery は、実行のさまざまなステージでワーカーから生成される中間データを保存するために、分散メモリ シャッフル層を使用します。このシャッフルには、超高速ペタビット ネットワーク テクノロジーなどの Google の斬新なテクノロジーや、可能な場合には RAM が活用されます。シャッフルされた各行はプロデューサーによって作成されるとすぐにワーカーで使用されます。
これにより、パイプラインでの分散処理が可能になります。また、ワーカーが出力を部分的に書き込んだ後に強制終了した場合(たとえば、基盤となるハードウェアの電源障害)は、単純に作業ユニットをもう一度キューに追加し、別のワーカーに送信できます。あるステージで 1 つのワーカーに障害が発生しても、ワーカー全体の再実行が必要になるわけではありません。
クエリが完了すると、結果が永続ストレージに書き込まれ、ユーザーに返されます。こうすることで、次回クエリが実行されたときにキャッシュに保存されている結果を返すことも可能になります。
クエリ処理の概要
クエリ処理のアーキテクチャを確認したところで、次は、クエリ実行のプロセス全体を概観し、各工程がどのように合流するかを見ていきましょう。
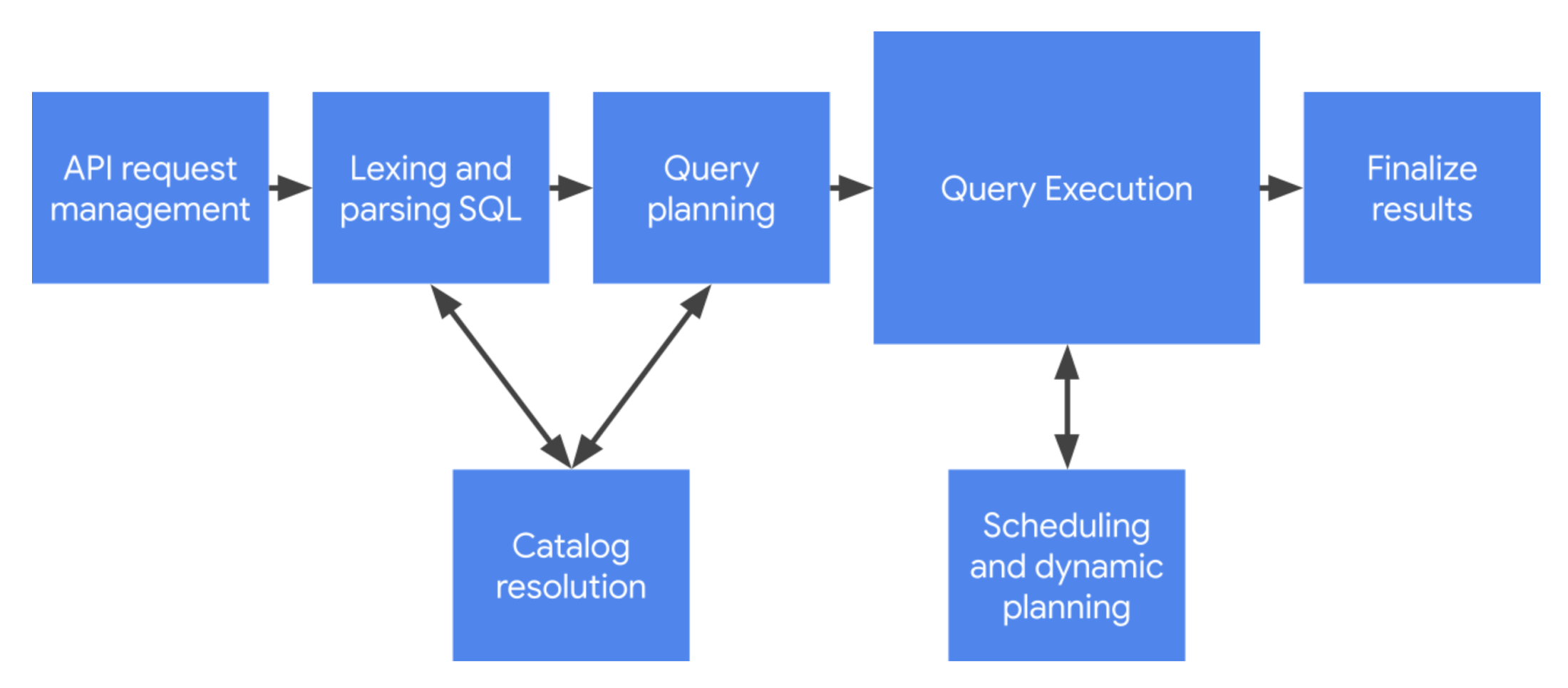
最初の工程: API リクエスト管理
BigQuery はクエリ実行用の非同期 API をサポートします。呼び出し元はクエリジョブ リクエストを挿入してから、完了するまでポーリングできます。これは数週間前にご説明したとおりです。BigQuery はこのために REST ベースのプロトコルをサポートしており、JSON でエンコードされたクエリに対応しています。
この工程を開始するにあたり、API 処理がある程度必要になります。他に実施する必要のあるものとしては、認証とリクエストの承認、関連するメタデータ(SQL ステートメント、クラウド プロジェクト、クエリ パラメータなど)の構築と追跡が挙げられます。
クエリテキストのデコード: 字句解析と構文解析
字句解析と構文解析はプログラミング言語に共通のタスクで、SQL でも同様です。字句解析とは、バイト配列(生の SQL ステートメント)をスキャンして、一連のトークンに変換する処理を指します。構文解析は、そのトークンを使用してクエリの統語表示を作る処理で、統語表示は BigQuery のソフトウェア アーキテクチャで検証、解釈されます。
この点に特にご興味をお持ちでしたら、ZetaSQL プロジェクトを確認することをおすすめします。この中には BigQuery や他の GCP プロジェクトで使用される SQL エンジンのオープンソース リファレンスの実装が含まれています。
リソースの参照: カタログの解決
SQL には通常 BigQuery システムで保持されるエンティティ(テーブル、ビュー、ストアド プロシージャ、関数など)への参照が含まれます。BigQuery でこの参照を処理するには、もっとわかりやすいものに変換する必要があります。この段階を経ることで、クエリ処理システムは次のような質問を解決できます。
この ID は有効か、何を参照しているか
このエンティティはマネージド テーブルか、それとも論理ビューか
この論理ビューの SQL 定義はどのようなものか
このテーブルにはどのような列とデータタイプがあるか
このテーブルにあるデータはどのように読めばよいか、URI のセットを使う必要があるか
解答は多くの場合、クエリ実行の構文解析フェーズとプランニング フェーズを通して不連続に配置されます。
設計図の作成: クエリ プランニング
構文解析と解答でリクエストの全体像がより明確になると、クエリプランがはっきりとし始めます。より速く効率的になるようクエリプランをリファクタリングして改善する方法はたくさんあります。たとえば代数化を使用すると、解析木が、サブクエリをリファクタリングして簡素化できる形に変換されます。他の手法を使用してさらに最適化を行い、データの枝刈りのようなタスクをデータの読み込みに近づけることができます(これにより、システム全体の仕事量を削減できます)。
別の方法として、こうした手法を一連の分散実行タスクとして実行するために採用することもできます。この投稿で最初に述べたように、BigQuery はクエリ計算ノードまたはワーカーの大規模なプールを利用しています。このため、クエリプランのさまざまなステージで、ストレージからの読み取りと書き込みによってデータを共有する方法と、シャッフル システム内で一時データをステージングする方法を調整する必要があります。
作業の実施: クエリ実行
クエリ実行は、完了に至るまでの実行グラフの各クエリステージを処理していくプロセスであると言えます。クエリステージの作業ユニットは、たった 1 つで済むこともあれば、何千も必要になることもあります。たとえば、独立した多くのカラム型入力ファイルで構成された大規模なテーブルのすべてのデータを読み込む場合には、作業ユニットは膨大になります。
クエリ管理: スケジューリングと動的プランニング
クエリプランの作業自体を実行するワーカーに加え、別のワーカーがシステム全体の作業の進捗を監視、監督します。スケジューリングは、作業のキューへの追加、実行、完了がどれほど積極的に行われるかと関係しています。
しかしここで、BigQuery クエリエンジン特性の一つである動的プランニング機能に注目できます。クエリプランには多くの場合曖昧なところがあり、確実に実行されるようにするには、クエリステージでさらなる調整が必要になる場合があります。システムを流れるデータを再度パーティショニングするのは、クエリプランの付加的な調整の一例です。これにより、後続のステージでの使用に合わせてデータのバランスとサイズが適切に保たれます。
最終工程: 結果の終了処理
クエリが完了すると、多くの場合結果という形で出力アーティファクトが生成されるか、システム内のテーブルが変更されます。結果の終了処理には、変更をストレージ レイヤに戻して commit する作業が含まれます。また、システムによるクエリ処理が完了したことをユーザーに知らせる必要もあります。クエリに関するメタデータが更新されて作業の完了が記録されるか、エラー ストリームがアタッチされて不具合が表示されます。
クエリ実行について
クエリがどのように始まり、終わるかについての理解しておくと、クエリプランをより詳しく分析できるようになります。まず、単純なプランから見てみましょう。ここでは、BigQuery の一般公開データセットに対してクエリを実行し、「Broadway」を名前に含む駅を始点とするシティバイクの移動の総数を計算しています。
ここで、BigQuery がこのクエリを処理する際に内部で起きることを考えてみましょう。
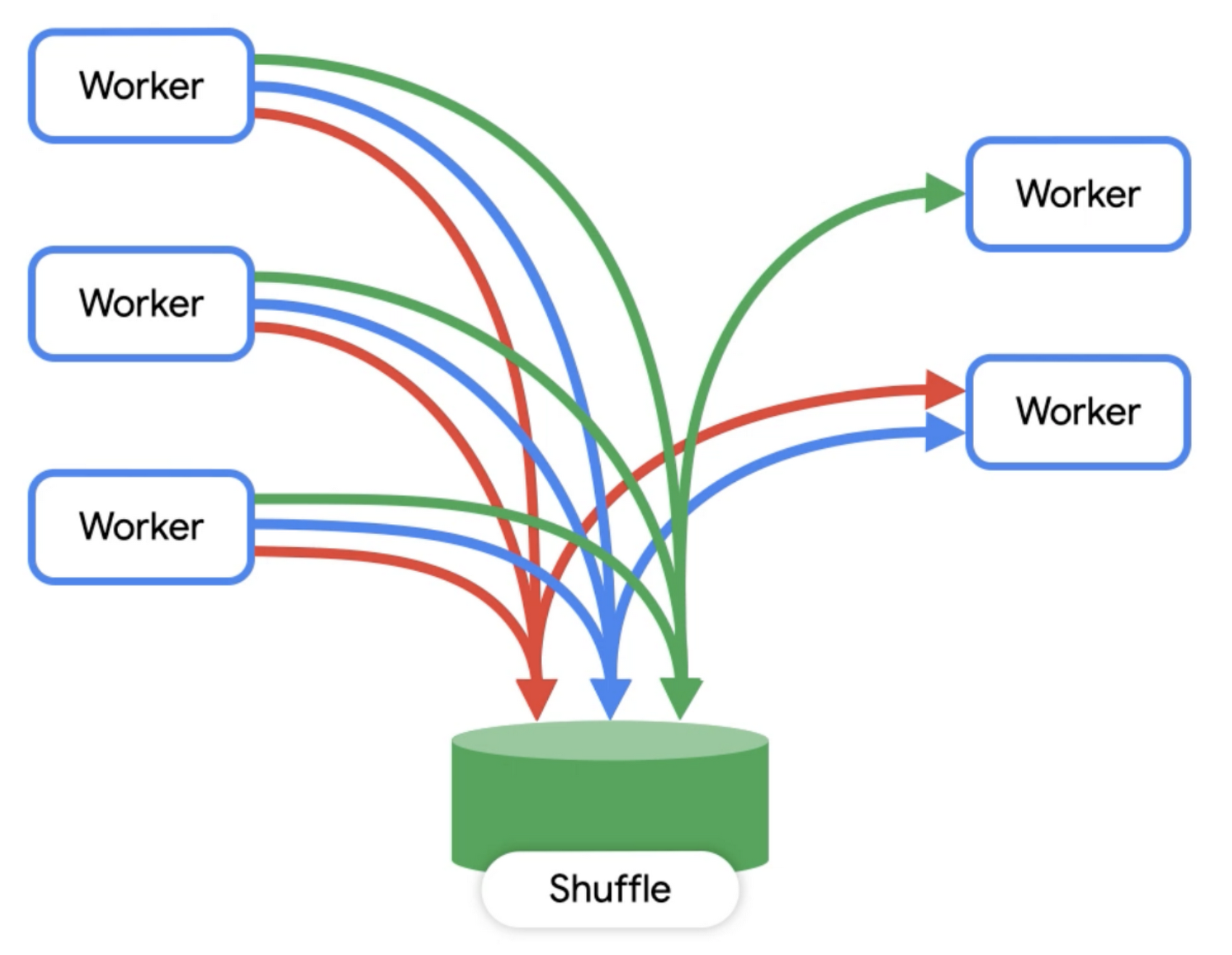
第 1 ステージとして、一連のワーカーが分散ストレージにアクセスし、テーブルの読み込み、データのフィルタリング、部分的な計算を行います。計算した値はワーカーからシャッフルに送信されます。
第 2 ステージでは、シャッフルのレコードを入力として読み込み、それを合計します。それから、その出力ファイルを 1 つのファイルに書き出します。このファイルが、クエリの結果としてアクセスできるファイルになります。
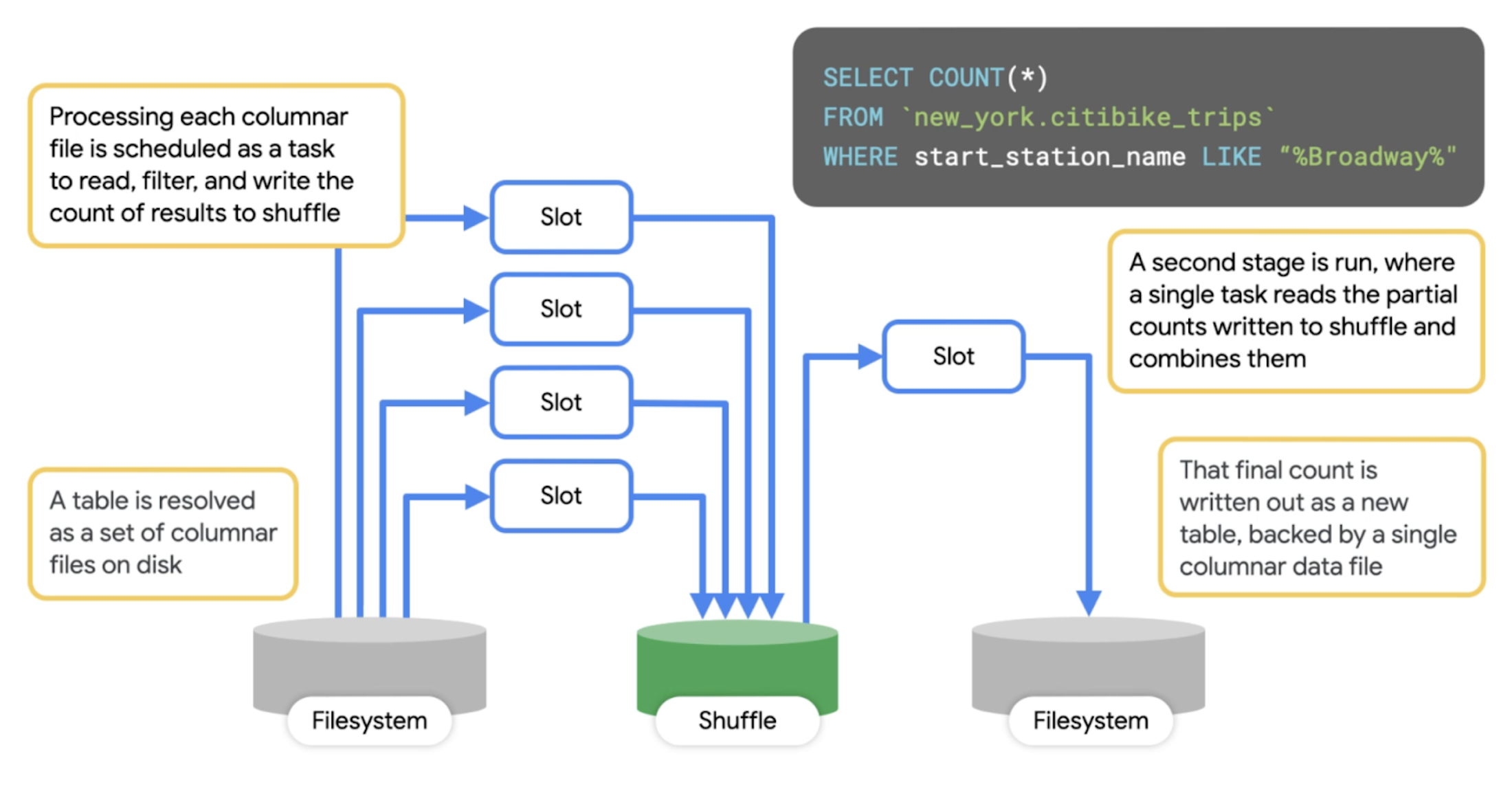
上図を見ると、ワーカーが直接相互に通信することはまったくなく、常にデータの読み込みと書き出しによって通信することがわかります。BigQuery コンソールでクエリを実行すると、実行の詳細がわかり、クエリプランに関する情報を収集できます(データには変更が加えられるため、以下に示す実行の詳細は、実際にコンソールに表示されるものとは少し違っているかもしれません)。
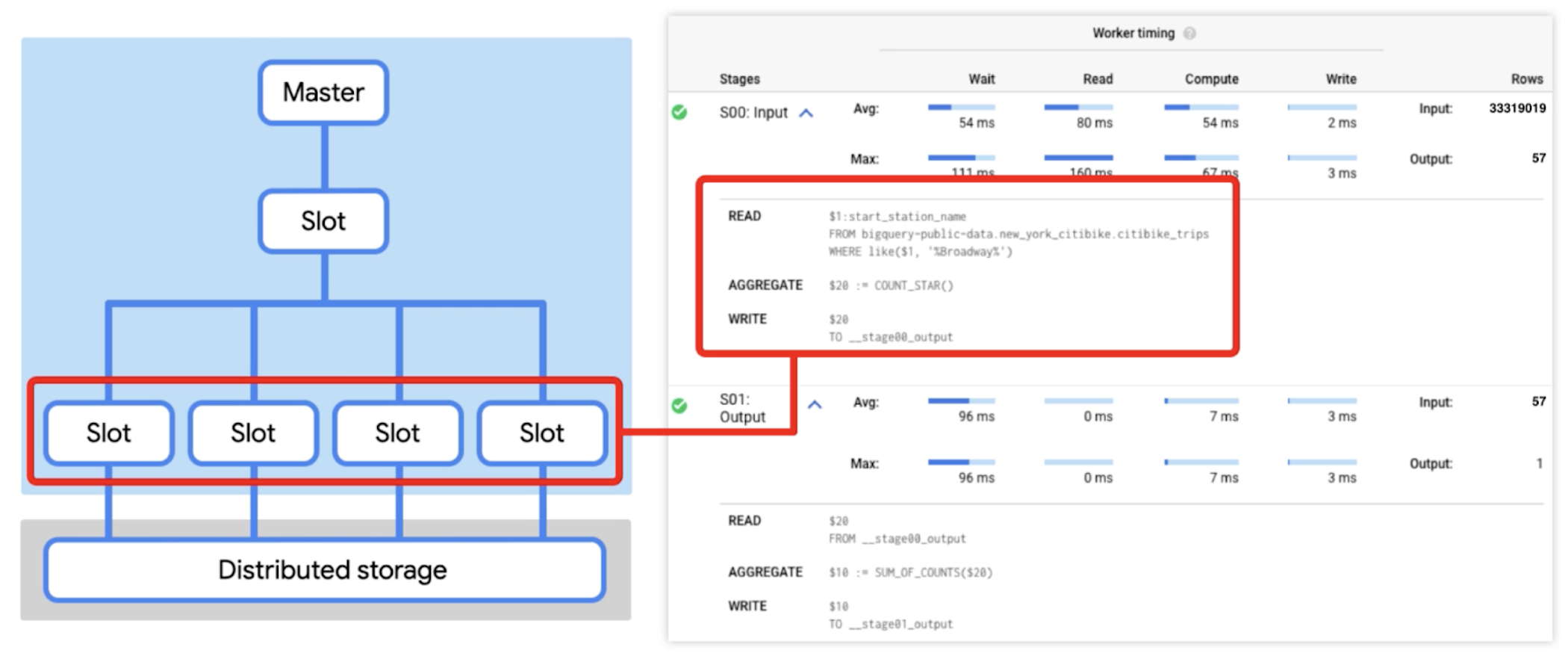
information_schema テーブルと Jobs API からも実行の詳細を取得できます。たとえば、次のようなコードを実行します。
クエリ統計情報の解釈
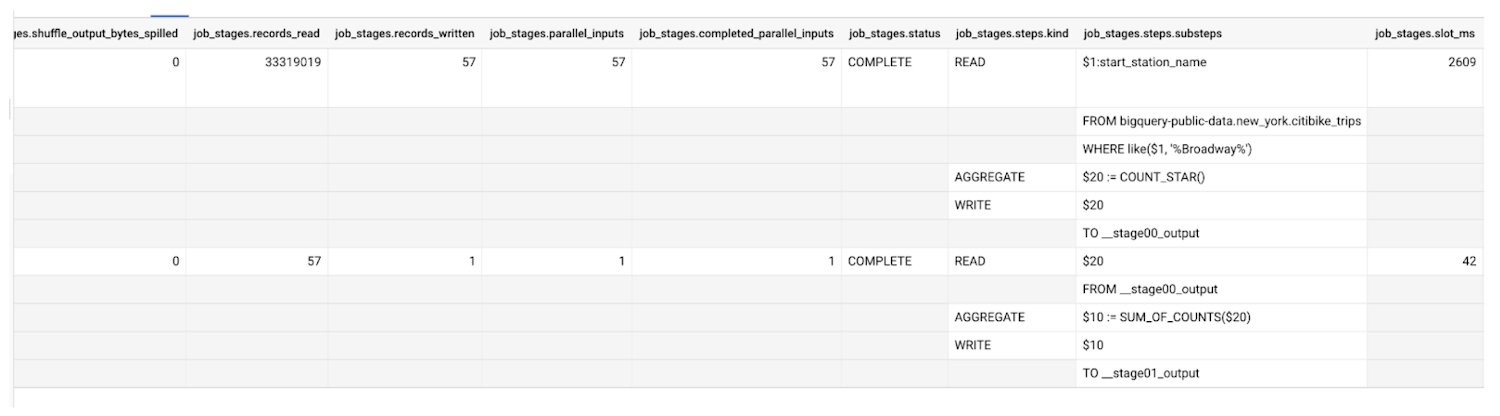
クエリ統計情報には、1 つのステージに存在する作業ユニットの数や、完了した作業ユニットの数に関する情報が含まれています。たとえば、先のセクションで使用した情報スキーマのクエリを調べると、以下の情報を入手できます。
入力と出力
parallel_inputs フィールドを使用すると、入力がどの程度細かく分割されたかがわかります。このフィールドは、テーブル読み込みの場合には、入力にファイル ブロックが何個あるかを示すものとなります。シャッフルから読み込むステージでは、個別のデータバケットがいくつ存在するかが入力の数から確認できます。入力一つ一つが、別々にスケジュールを設定することが可能な個別の作業ユニットを表しています。例では、テーブルに 57 個の異なるカラム型ファイル ブロックがあります。
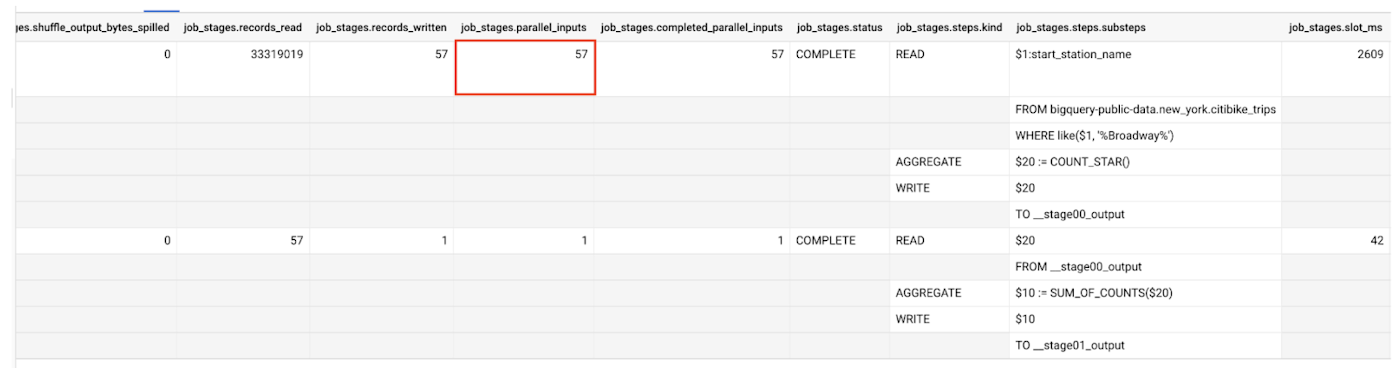
この例からは、テーブルの処理中に 3,300 万行以上がクエリによってスキャンされたこともわかります。シャッフル システムでは、第 1 ステージで入力ごとに 1 行を読み込んだように、第 2 ステージでは 57 行を読み込みます。
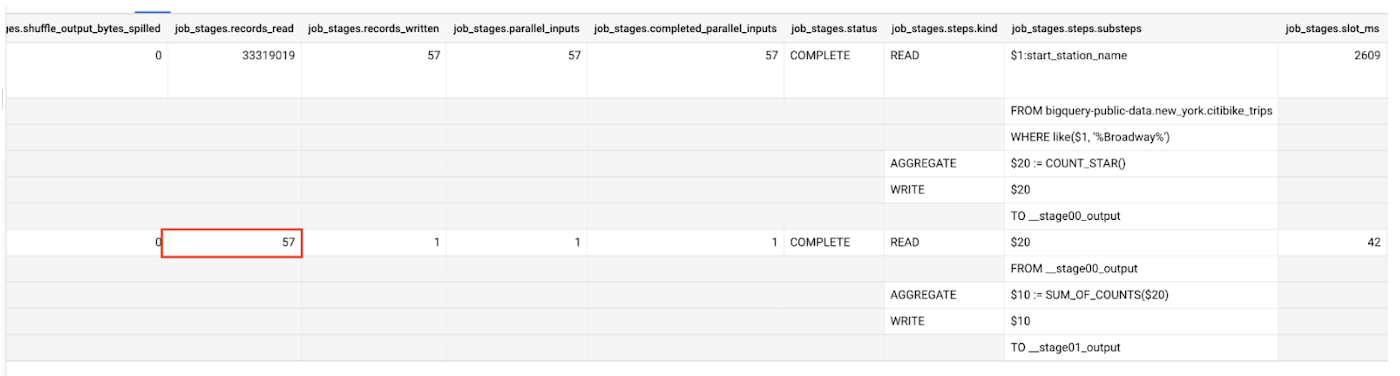
また、ステージは入力のサブセットだけを処理して終了してもまったく問題ありません。これは実行ステージで起きやすく、すべての入力を処理しなくても、必要な出力を確保する条件を満たせる場合があります。入力の一部を使用し、LIMIT 句を使って出力の行数を少なく制限するクエリステージは、その典型例です。
そのため、並列処理の概念の研究も重要です。1 つのステージに 57 個の入力があるということは、57 個のワーカー(スロット)が利用可能になるまでこのステージが開始されないということではなく、対処すべき要素を 57 個持っている作業キューが存在するということです。1 つのワーカーでそのキューを処理することは可能で、その場合は基本的にシリアル実行を行います。ワーカーが複数あれば、各ワーカーが独立して動作してユニットを処理するため、より早く処理できます。ただし、57 個を超えるスロットは無駄になります。これは、作業をそれ以上細かく分散させることができないためです。
BigQuery は、ネイティブの分散ストレージやシャッフルからの読み込みだけでなく、Cloud Storage などの外部ソースからデータの読み込みと書き込みを行うこともできます(以前の投稿でご説明したとおりです)。その場合もやはり並列アクセスの概念が適用されますが、一般にパフォーマンスは低下します。
スロット使用率
BigQuery では、スロットと呼ばれるコンピューティング ユニットを使ってリソースの使用状況を伝達します。最も単純な説明として、スロットは仮想 CPU と似たものであると言えます。スロットは、使用可能または使用中のワーカーの数を測定するものなので、全体的なコンピューティングのスループットや、変動率を考える際に、スロットに目を向けます。たとえば、1 個のスロットは、1 スロット秒のコンピューティングを毎秒処理する能力を提供します。このように、ワーカー数、またはスロット数が少ないからといって、ジョブが実行されないわけではありません。単に実行が遅くなるというだけです。
クエリ統計情報で、slot_ms(スロットミリ秒)の使用量がわかります。この数字をクエリステージの実行時間(ミリ秒)で割れば、そのステージで完全飽和したスロットの数を計算できます。
この情報によって、さまざまなワークロードやプロジェクトで使用されるスロットの平均数がわかります。その平均数がわかると、予約のサイズ設定にも役に立ちます(それについてはこの後詳しく説明します)。完全飽和したスロットと比較して並行入力の数が多い領域を調べれば、アクセスできるスロットの数が増えればより高速で実行されるクエリを突き止められるかもしれません。
各フェーズに費やす時間
また、クエリ実行の各ステージで、待機、読み込み、コンピューティング、書き込みの各フェーズにワーカーが費やした平均時間と最大時間もわかります。
待機フェーズ: エンジンが、ワーカーが利用可能になるか、利用可能な結果の書き出しが前のステージで始まるのを待っている状態です。待機フェーズに費やされる時間が多い場合は、スロット数を増やすことで処理時間を短縮できる可能性があります。
読み込みフェーズ: スロットが分散ストレージまたはシャッフルからデータを読み込んでいる状態です。ここに費やされる時間が多い場合は、(結果セットを制限するか、データをフィルターすることで)クエリで使用されるデータ量を制限したほうがよいかもしれません。
コンピューティング フェーズ: SQL の関数や式の値を求めるといった実際の処理が行われるフェーズです。一般に、適切に調整されたクエリは、コンピューティング フェーズに時間の大半を費やします。コンピューティング フェーズに費やす時間の削減を試みる方法としては、近似関数の利用や、複雑な正規表現のようなコストのかかる文字列操作の調査が挙げられます。
書き込みフェーズ: データが、次のステージ、シャッフル、ユーザーに返される最終出力のいずれかに書き込まれるフェーズです。ここに費やす時間が多い場合は、(結果セットを制限するか、データをフィルターすることで)このステージの結果を限定したほうがよいかもしれません。
各フェーズに費やされる時間の最大値が平均を大きく上回る場合は、直前のステージから出力されたデータが不均等に分布している可能性があります。一つの方法として、クエリのはじめにフィルタリングを行うことで、データの偏りが少なくなることがあります。
大規模なシャッフル
多くのクエリパターンでは使用するシャッフルの量が妥当であっても、大規模なクエリでは利用可能なシャッフルのリソースを使い尽くしている場合があります。特に、クエリステージ全体の時間の大半がシャッフルへの書き出しに費やされている場合は、シャッフルの統計情報に目を通してください。shuffleOutputBytesSpilled を見ると、メモリ内リソースを超えるディスク リソースをシャッフルに利用せざるを得なかったかどうかがわかります。