BigQuery 管理者リファレンス ガイド: データ ガバナンス
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery 管理者シリーズをご覧になって、BigQuery に対する理解を順調に深められているかと思います。ここで、基礎知識を身に着けていただいたところで、すべてのデータ プロフェッショナルに該当するトピック、つまりデータ ガバナンスについてお話ししましょう。
データ ガバナンスとは
データ ガバナンスとは、BigQuery 内でのデータの安全性、機密性、正確性、利用可能性を保証するために行うすべてのことを指します。ガバナンスが優れていれば、組織内の全員が効果的な意思決定を行うために必要なデータを簡単に見つけ、活用できるうえ、データの漏洩または不正使用の全体的リスクを最小限に抑えながら、法令遵守を徹底することができます。
BigQuery のセキュリティ機能
BigQuery はフルマネージド サービスのため、Google がお客様の代わりに多くの厄介な作業を引き受けます。BigQuery のストレージの仕組みの記事で述べたとおり、BigQuery のデータは、信頼性と可用性を保証するため、データセンター間で複製されます。さらに、データは、保存時に必ず暗号化されます。基本的には、Google がお客様に代わって暗号鍵を管理します。ただし、Cloud KMS を使用して暗号鍵を自動的にローテーションしたり、破棄したりすることで、お客様が管理している暗号鍵を活用することもできます。
また、Google の Virtual Private Cloud(VPC)Service Controls を使用して、BigQuery へのトラフィックを制限することもできます。この Service Controls を正しく適用すると、不正なネットワークが BigQuery のデータにアクセスできなくなり、データを不正な Google Cloud プロジェクトにコピーできなくなります。境界内では引き続き自由な通信が可能ですが、境界を越えた通信は制限されます。
BigQuery の既製のセキュリティ機能を活用する以外にも、プロセスの観点からガバナンスを向上させることもできます。この記事では、お客様の組織でデータ ガバナンスを確保するためのさまざまな方策を紹介します。
データセットのオンボーディング: データの理解と分類
データ ガバナンスは、データセットのオンボーディングから始まります。例えば、e コマースチームの誰かから、顧客のトランザクションを含む新しいデータセットを追加したいという要望を受けたとします。この場合にまず必要なのは、そのデータを理解することです。そのためには、次のような質問を問いかけることから始めてみましょう。
このデータにはどのような情報が含まれていますか?
ビジネス上の意思決定にこのデータがどのように使用されますか?
このデータには誰がアクセスしますか?
データはどこから取得され、アナリストは BigQuery 内でどのようにデータにアクセスしますか?
データを理解することで、新しいテーブルを BigQuery のどこに置くべきか、誰がこのデータにアクセスするか、BigQuery 内でどのようにデータにアクセスできるようにするか(たとえば外部テーブルを活用する、ネイティブ ストレージにデータを一括で読み込むなど)を判断しやすくなります。
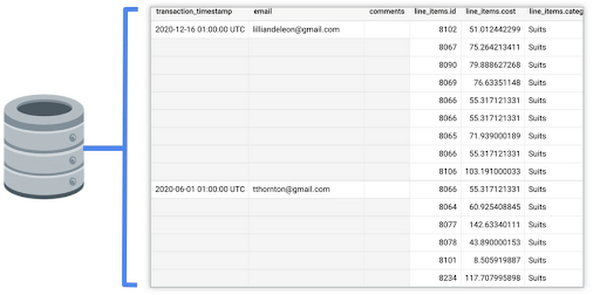
この例では、トランザクションが OLTP データベースに置かれています。Google のデータベースの既存テーブルにどのような情報が格納されているかを見てみましょう。以下に示すとおり、このテーブルには、注文に関する情報(注文日時、購入者情報、注文に関する追加コメント)と、購入された商品の詳細(商品 ID、費用、カテゴリなど)が格納されていることがわかります。
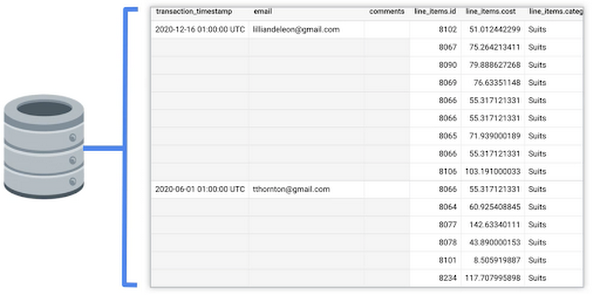
この時点でデータ参照元にどのようなデータが存在し、どのような情報がビジネスにとって重要かがわかるため、BigQuery テーブルにどのフィールドが必要か、またデータを本番環境にプッシュするためにどのような変換が必要かを判断できます。
情報の分類
データの分類とは、データに含まれる情報の種類を把握し、これを検索可能なメタデータとして保存することをいいます。データを適切に分類することで、データが適切に処理、共有され、組織全体でデータを検索できるようになります。
本番環境用のテーブルがどうあるべきかがわかっているため、あえて適切なスキーマを設定した空の BigQuery テーブルを作成し、そこにトランザクションを格納できます。
この新しいテーブルに関するメタデータの保存には、2 種類の方法があります。
ラベルの使用
1 つの方法として、ラベルの使用が挙げられます。ラベルはプロジェクト、データセット、テーブルなど、BigQuery の多くのリソースで使用できます。ラベルは Key-Value ペアで、Cloud Monitoring でデータをフィルタリングしたり、情報スキーマに対するクエリで特定のユースケースに関連するデータを検索したりするために使用できます。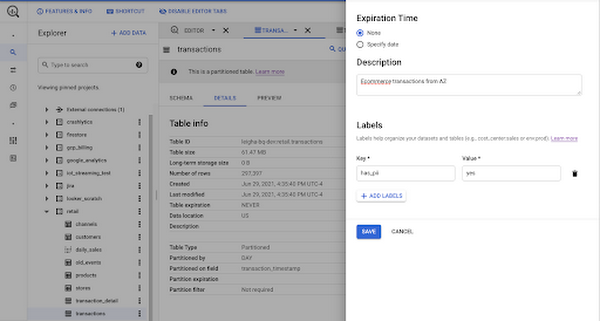
ラベルは、Google Cloud のエコシステムにおいて異なるビジネス目的を論理的に分離、管理するためのものですが、データ ガバナンスの観点から使用するものではありません。ラベルはスキーマを指定できず、テーブルの特定フィールドに適用することもできません。また、アクセス ポリシーの設定にもリソース階層の追跡にも使用できません。
お察しのとおり、トランザクション テーブルには個人を特定できる情報(PII)が含まれている可能性があります。そこで、メールアドレス列を「Has_PII」: True に設定することをおすすめします。新しいテーブルにラベルを使用する代わりに、Data Catalog を活用して、BigQuery リソースと個々のフィールドにメタデータタグを組み込み、強固なデータ ガバナンス ポリシーを確立します。
Data Catalog タグの使用
Data Catalog は、Google Cloud のデータ検出とメタデータ管理のサービスです。BigQuery で新しいテーブルを作成すると、直ちに Data Catalog でこのテーブルが自動的に検出できるようになります。Data Catalog は、名前、説明、作成日時、列名、データタイプなど、テーブルに関連するすべてのテクニカル メタデータを追跡します。
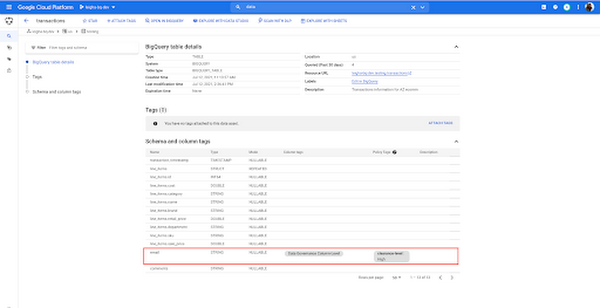
BigQuery のインテグレーションによって取得されるメタデータ以外に、スキーマ化されたタグを作成して、追加のビジネス情報を追跡することもできます。たとえば、データの提供元に関する情報、データに関連する分析ユースケース、セキュリティと共有に関連する列レベルの情報を追跡するタグを作成することをおすすめします。先ほど述べたメールアドレスの列に戻ると、単に列レベルのガバナンスタグをフィールドに添付し、email_address が暗号化されていない旨、PII を含んでいる旨、より具体的にはメールアドレスを含んでいる旨を指定して情報を記入できます。
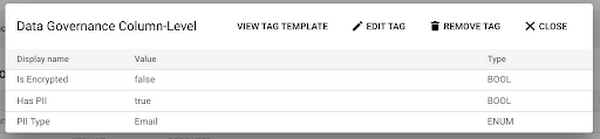
これはほぼ手作業でのプロセスになりそうだと思われるかもしれませんが、Data Catalog には API が完備されており、プログラム化した形でタグの作成、添付、更新を行えます。タグとテクニカル メタデータが 1 か所に集められているため、データ利用者は Data Catalog にアクセスして、必要なデータを検索できます。
データの取り込みとステージング
本番環境用テーブルのメタデータが所定の場所に格納されたところで、この新しいテーブルにデータをプッシュする方法に注目しましょう。ご存じかと思いますが、データを前処理して BigQuery に取り込む方法はさまざまです。Google Cloud サービスにデータをステージングして、変換、分類、または匿名化のワークフローを開始するお客様も多くいらっしゃいます。バッチ読み込みのためにデータをステージングする方法として、以下の 2 つの方法が広く用いられています。
Google Cloud ストレージ バケットにデータをステージングする: BigQuery にデータを直接取り込む前に Google Cloud ストレージ バケットにデータをプッシュすることで、データ構造の柔軟性が確保され、大量の情報を保存するための費用を抑えることができます。また、PubSub を使用して変換ジョブをトリガーすることで、新しいデータがバケットに入ったときにワークフローを簡単に開始することもできます。ただし、変換は BigQuery サービスの外で行われるため、データ エンジニアは他のツールまたは言語に精通しておく必要があります。また、blob ストレージでは、列レベルのメタデータを追跡することも困難です。
BigQuery のステージング コンテナにデータをステージングする: データを BigQuery にプッシュすると、BigQuery と Data Catalog のインテグレーションにより、目標達成プロセスの早い段階で特定のフィールドのメタデータを追跡できます。データ損失防止(DLP)機能(次のセクションで説明します)を使用してスキャンジョブを実行するときに、特定の列を除外し、実行結果を Data Catalog 内のステージング テーブルのメタデータに直接保存できます。さらに、本番環境用のデータを準備するための変換は、SQL ステートメントを使用して行えるため、より簡単に開発や管理を行えます。
機密情報の特定(および匿名化)
データ ガバナンスに関する最も困難な問題の 1 つとして、新しいデータに含まれる機密情報の特定が挙げられます。先ほど、Data Catalog で既知のメタデータを追跡する方法を説明しましたが、データに機密情報が含まれているかどうかわからない場合はどうなるでしょうか。機密情報特定機能は、トランザクションのコメント フィールドのような自由形式のテキスト フィールドに特に役立つと考えられます。Google Cloud にデータがステージングされている場合、データ損失防止(DLP)機能を使用して、プログラムにより PII を特定したり、データから機密情報を削除したりできます。
DLP は、名前、メールアドレス、場所、クレジット カード番号など、さまざまなタイプの機密情報のデータをスキャンするために使用できます。スキャンジョブは、BigQuery、データカタログ、または DLP サービス、DLP API から直接開始できます。DLP は、BigQuery または Google Cloud にステージングされているデータのスキャンに使用できます。また、BigQuery に格納されたデータについては、DLP にスキャンの結果を Data Catalog に直接プッシュさせることもできます。
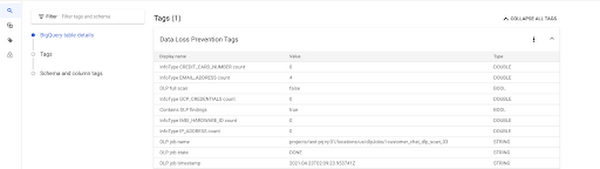
DLP API を使用して、データを匿名化することもできます。たとえば、名前、メールアドレス、場所などのインスタンスをアスタリスク(「*」)に置き換えることが推奨されています。今回のケースでは、DLP を活用して、BigQuery のステージング テーブルのコメント列をスキャンし、その結果を Data Catalog に保存し、機密データのインスタンスがある場合は、サニタイズされたデータを本番環境用テーブルにプッシュする前に、匿名化ワークフローを実行できます。なお、ここで紹介しているようなパイプラインを構築するには、他のツールをいくつか使用する必要があります。

Cloud Function を使用して API 呼び出しを行ったり、Cloud Composer のようなオーケストレーション ツールを使用してワークフローの各ステップを実行したりできます(適切なオーケストレーション ツールについては、こちらの記事をご覧ください)。今回の記事では、DLP と Composer を使用して匿名化ワークフローを実行する例を紹介しています。
データ共有
BigQuery Identity Access Management
Google Cloud 全体では、Identity Access Management(IAM)を活用して、クラウド リソース全体でアクセス権限を管理しています。IAM では、誰(ID)がどのリソースに対してどのようなアクセス権(ロール)を持つかを定義することにより、アクセス制御を管理します。BigQuery には、他の Google Cloud リソースと同様に、複数の事前定義ロールがあります。また、より細かいアクセス権限に基づいてカスタムロールを作成することもできます。

BigQuery データへのアクセスを許可する場合、多くの管理者は、会社のさまざまな部門を代表する Google グループに特定のデータセットまたはプロジェクトへのアクセスを許可することを選択しているため、ポリシーは簡単に管理できます。さまざまなビジネス シナリオと推奨されるアクセス ポリシーの例をこちらでご覧いただけます。
この記事の小売業のユースケースでは、各チームに対し 1 つのプロジェクトが指定されています。各チームの Google グループには、チームのプロジェクトに保存されている情報にアクセスするための BigQuery データ閲覧者ロールが付与されます。しかしながら、e コマースチームの誰かが、製品開発チームのプロジェクトなど、別のプロジェクトのデータを必要とする場合もあります。データへの限定的なアクセスを許可する 1 つの方法として、承認済みビューを使用する方法が挙げられます。
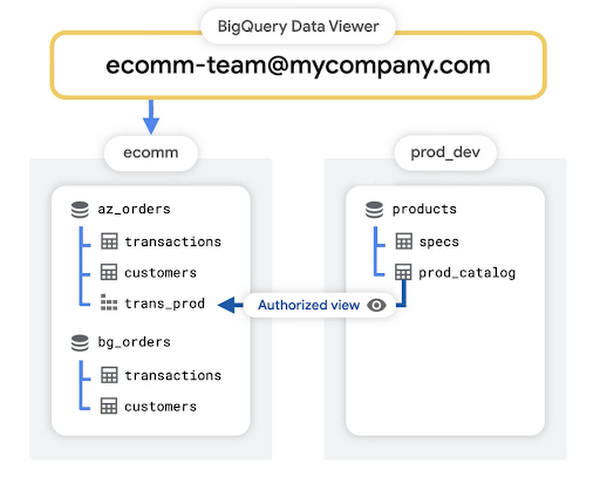
承認済みビューを使用したデータの保護
データセットに表示アクセス権を設定する場合、BigQuery では承認済みビューを作成します。承認済みビューを使用すると、元のソースデータへのアクセスを許可することなくクエリの結果を特定のユーザーやグループと共有することができます。この記事のケースでは、e コマースチームがデータを効果的に分析するために必要な情報を取得し、同チームがすでにアクセス権を持つ既存の e コマース プロジェクトにそのビューを保存するためのクエリを簡単に記述できます。

列レベルのアクセス ポリシー
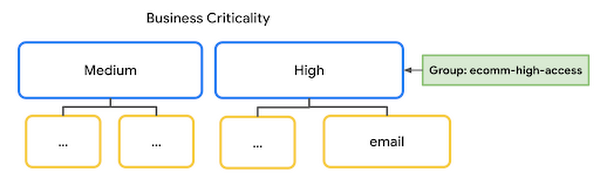
標準的な IAM ロールを使用してデータへのアクセスを制御したり、承認済みビューを通じてクエリ結果へのアクセスを許可するだけでなく、BigQuery の列レベルのアクセス ポリシーを活用することもできます。たとえば、この記事で PII を含むものとして指定したメールアドレスの列を覚えているでしょうか。これらの列をクエリするためのアクセス権は、セキュリティ レベルの高い機密情報の使用が許可されているメンバーのみに付与することをおすすめします。これは、以下の方法で行えます。
最初にデータカタログで分類を定義し、機密性が高いフィールドに対し「高」ポリシータグを添付します。
次に、機密性の高いデータへのアクセスが必要なユーザー グループを、高粒度アクセス読者(Fine Grained Access Readers)として「高」リソースに追加します。
列レベルのアクセス ポリシーを作成するためのアドバイスは、ベスト プラクティスに関するドキュメントに記載されています。
行レベルのアクセス ポリシー
新しいテーブルの特定フィールドへのアクセスを制限するだけでなく、ユーザーに関連のある行へのアクセスのみを許可することも推奨されています。たとえば、異なる事業部門のアナリストが、その事業部門のトランザクションを表す行にのみアクセスできるようにする例が挙げられます。この場合、スポーツウェア チームを表す Google グループは、「Active」に分類された商品に対する注文にのみアクセスさせる必要があります。BigQuery では、トランザクション テーブルに行レベルのアクセス ポリシーを作成することで、これを実現できます。
行レベルのアクセス ポリシーを作成するためのアドバイスは、ベスト プラクティスに関するドキュメントに記載されています。
データ共有のために何をどのタイミングで使用するか
最終的には、先に考察したコンセプトのうち 1 つ以上を採用してデータを保護するという目的を達成することができます。承認済みビューでは、特定ユーザーに基盤となるデータセットに直接アクセスさせることなく必要情報を提供することで、データ共有に抽象化レイヤーが追加されます。変換(共有前の事前集計など)を行いたい場合には、承認済みビューが最適です。承認済みビューを使用して列レベルのアクセスを管理できますが、Data Catalog なら単一テーブルのメタデータにアクセス情報を簡単に集約し、階層的な分類によってアクセスを制御できるため、こちらのサービスを活用することをおすすめします。同様に、異なる場所の複数の承認済みビューを管理するよりも、複数のアクセス ポリシーが設定された単一のテーブルを管理する方がより容易な場合には、行をフィルタリングするための承認済みビューではなく、行レベルのアクセス ポリシーを活用する方が望ましいといえます。
データ品質のモニタリング
データ ガバナンスの最後の要素として、ここではデータ品質のモニタリングについて説明します。BigQuery データの品質は、データソースに問題があったり、変換パイプラインにエラーがあったりと、さまざまな理由で低下することがあります。いずれにしても、何か問題がないかを把握し、問題がある場合は自社内のデータ利用者に通知する手段を確保しておくことをおすすめします。先ほど説明したように、Cloud Composer のようなオーケストレーション ツールを活用して、さまざまな SQL 検証テストを実施するためのパイプラインを作成できます。
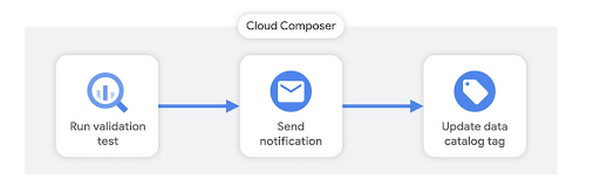
検証テストは、以下の複数の方法で作成できます。
まず、Google のプロフェッショナル サービス チームが作成したこちらのようなオープンソースのフレームワークを利用する方法が挙げられます。このようなフレームワークを使用することで、検証テストがどういうときに合格または不合格になるかのルールを宣言できます。
同様に、検証ルールを宣言するために YAML ファイルを活用する機能を備えた Dataform のようなツールを使用することもできます。Dataform は最近、Google Cloud の傘下に入り、まもなく新規のお客様の受付を開始する予定です。こちらから順番待ちリストに登録できます。
また、ASSERT のような BigQuery の組み込み機能を使用してプログラム形式でクエリを実行することで、いつでも独自のソリューションを構築できます。アサーションが有効ではない場合、BigQuery がエラーを返します。このエラーを読むと、パイプラインの次のステップがわかります。
検証テストの結果に基づき、Slack などの組み込み通知ツールを使用して、Composer に通知を送信させることができます。最後に、Data Catalog の API を使用して、所定のテーブルのデータ品質を追跡するタグを更新することもできます。サンプルコードについてはこちらをご覧ください。この情報が Data Catalog に追加されると、組織内のデータ利用者が検索できるようになり、データ利用者が分析に使用する情報の品質について常に情報を得ることができます。
今後の予定
この記事では触れませんでしたが、確実にデータ ガバナンスに関連するものとして、使用状況の監査とアクセス ポリシーに関する継続的なモニタリングが挙げられます。これついては、数週間のうちに、BigQuery のモニタリング全体を取り上げる際により詳しく説明します。このシリーズの最新情報を見逃さないように、ぜひ LinkedIn と Twitter で私をフォローしてください。
-デベロッパー アドボケイト Leigha Jarett
-戦略クラウド エンジニア Suhita Goswami





{kind=link}
{kind=link}