TensorFlow Probability と Vertex AI による異常検出
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
時系列の異常検出は、目下話題のトピックです。統計学者は、消費者行動の劇的な変化を受け、小売の需要予測などのモデルの再調整に追われています。私はインターンとして、Vertex AI で機械学習を活用した異常検出ソリューションを開発し、骨の折れる時系列モデルの構築プロセスを自動化するというタスクを与えられました。この記事では、Google のインターンが取り組む手強い課題がどのようなものか、その一端をお見せするとともに、TensorFlow Probability の 構造時系列 API と Vertex Pipelines でジョブを実行する方法についてもご紹介します。
Vertex Pipelines
Vertex Pipelines は Google Cloud の MLOps ソリューションで、「ML ワークフローのオーケストレーションによる ML システムの自動化、モニタリング、管理」を可能にします。具体的には、今回のデモはオープンソースの Kubeflow パイプライン SDK 上で実行できるため、Vertex Pipelines、Amazon EKS、Microsoft Azure AKS などのサービス上でも実行可能です。この記事では、新しい時系列データの分析、異常の報告、結果の分析の一連のプロセスを Vertex Pipelines を使用して自動化する方法をご紹介します。Vertex Pipelines について詳しくは、こちらの記事をご一読ください。

Google Cloud パイプライン コンポーネント
Google Cloud パイプライン コンポーネントは、さまざまなソリューションをコンポーネントとして提供する Kubeflow パイプラインの新しい取り組みです。Google Cloud の時系列の異常検出コンポーネントは、この SDK が提供する初の応用 ML コンポーネントです。SDK の GitHub リポジトリで、Kubeflow のオープンソース コンポーネントをご覧いただけます。また、URL からコンポーネントを読み込んで使用することも可能です。
なお、このコンポーネントは現在試験運用段階であり、正式版はリリースされていません。
TensorFlow Probability 異常検出 API
TensorFlow Probability には、構造時系列(STS)用の API ライブラリが含まれています。これは、時系列をわかりやすい季節およびトレンド コンポーネントに分解するベイズ統計モデルクラスです。
以前は、モデルの季節およびトレンド コンポーネントを手動で定義する必要がありました。例えば、このデモでは地域の線形傾向と月ごとの影響を使用するモデルを用いて CO2 濃度を予測しています。TensorFlow Probability チームは、このインターン プロジェクトと同時進行で、こうしたコンポーネントを入力時系列に基づいて推論する新しい異常検出 API を構築しました。この新しいコンポーネントにより、以下の 1 行のコードで異常検出を行えるようになりました。
この End to End API は、入力時系列の正則化、季節モデルの推論、モデルの適合、許容値の予想範囲に基づいた異常の報告を行います。次回の正式リリースにも含まれる予定ですが、現在は TensorFlow Probability の GitHub リポジトリからご利用いただけます。Google Cloud パイプライン コンポーネントは、この API を Vertex Pipelines エコシステムにまとめ、この異常検出アルゴリズムを使用したワークフローの例を示しています。
デモ ノートブック
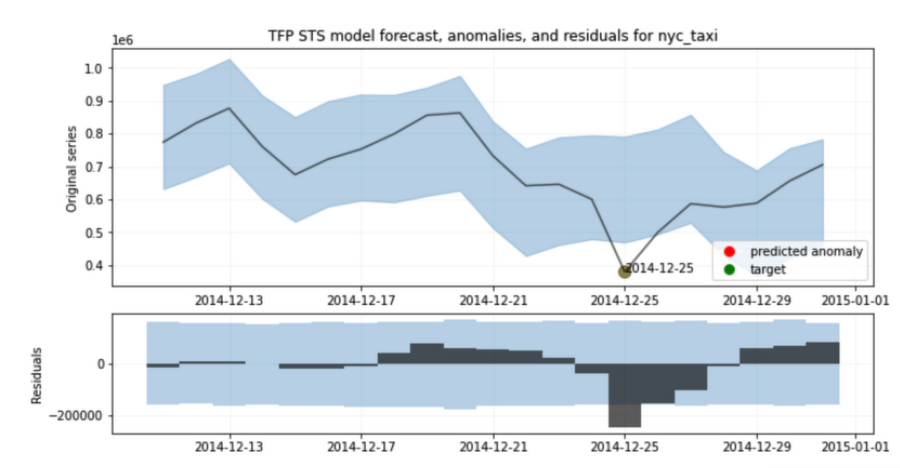
デモでは、Numenta Anomaly Benchmark のニューヨーク市のタクシーに関するタスクを使用して、TensorFlow Probability の異常検出アルゴリズムのパフォーマンスを評価します。このデータセットは、2014 年 7 月~2015 年 1 月の間にニューヨーク市のタクシーを利用した客の合計人数を 30 分単位で記録したものです。クリスマスやニューヨーク シティ マラソンなどのイベント期間中には、最大 1 万のデータポイントと 5 つの異常が発生しています。

こちらは、パイプラインの結果を可視化したものです。上のグラフの黒線は、タクシーの乗客数の元の時系列です。青い帯の部分は、アルゴリズムが過去の時点を踏まえて判断した予測分布です。ポイントが予測の範囲を外れると異常が報告されます。下のグラフでは、黒い四角形は残差を表します。この場合は、実際の乗客数と予測した乗客数との差となります。グラフからは、12 月 25 日に残差が大きく、アルゴリズムがその日を異常であると適切に報告していることが見て取れます。
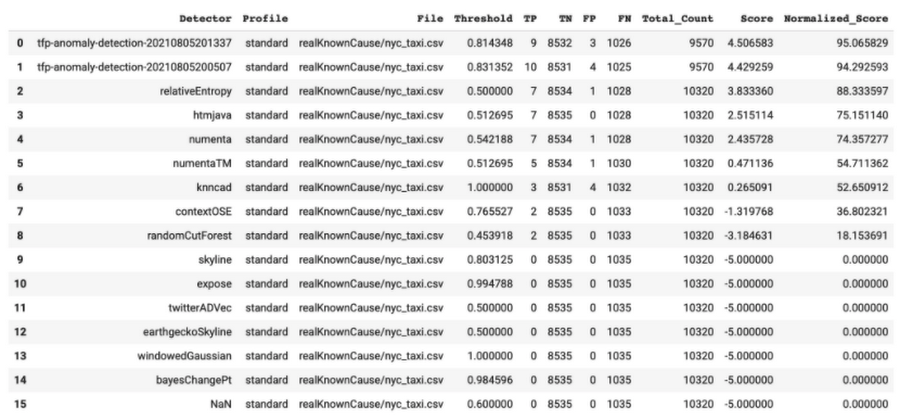
また、予測結果に対して Numenta Anomaly Benchmark のカスタム スコアリング スクリプトを実行し、アルゴリズムを他と比較しました。その結果、Google のアルゴリズムは誤検出を最小限に抑えつつ異常を数多く検出しており、このニューヨーク市のタクシーに関するタスクに関しては最も優れたパフォーマンスをあげていることがわかりました。
結論
Vertex AI 上で時系列モデルを構築してみたいとお考えの場合は、以下のリソースをご活用ください。
時系列の異常検出に関する Colab ノートブック
初めての KFP コンポーネントの構築に関するドキュメント
構造時系列モデリングに関する TensorFlow Probability のブログ記事
構造時系列モデリングのケーススタディに関する TensorFlow Probability のデモ
-SWE インターン、Grace Luo