Vertex AI を利用して強化学習レコメンデーション アプリケーションをビルドする
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
強化学習(RL)は機械学習の形態の 1 つであり、エージェントが環境に対する行動を選択しながら、その一連の選択を通じて得られる目標(報酬)を最大化する方法を学習していくというものです。RL のアプリケーションの例として、学習ベースのロボット工学、自律走行車、コンテンツ配信などがあります。基本的な RL システムには、多くの状態、対応する行動、それらの行動に対する報酬が含まれています。これを映画のレコメンデーション システムで考えてみましょう。「状態」はユーザー、「行動」はユーザーにおすすめする映画、「報酬」は映画に対するユーザー評価に当てはめることができます。Applied ML Summit 2021 の基調講演 で Spotify が述べていたように、RL は ML モデル最適化に適したフレームワークです。
この記事では、Vertex AI で実行され、TF-Agents(TensorFlow の RL 用ライブラリ)でビルドされる RL ベースの映画レコメンデーション システムのデモを行います。このデモは、2 つの部分で構成されています。1 つ目は Vertex Training サービス、ハイパーパラメータ調整サービス、予測サービスを活用する手順ガイドで、2 つ目は Vertex Pipelines などの Vertex サービスを使用してエンドツーエンドのパイプラインをビルドするための MLOps ガイドです。
TF-Agents と Vertex AI との融合
強化学習では、特定の環境において、エージェントが一定のポリシーに基づいて一連の行動を選択します。その際の目標は、この一連の行動を通じて得られる報酬を最大化することにあります。TF-Agents は、RL アプリケーションの設計、実装、テストを容易に行うための強力かつ柔軟なライブラリであり、簡単なカスタマイズを実現する包括的な論理モジュール セットを提供します。
ポリシー: 環境の観測から 1 つの行動または複数の分散行動へのマッピング。これは、トレーニングから生成されるアーティファクトであり、教師あり学習環境における「モデル」に相当します。
行動: あるポリシーから出力され、エージェントによって選択および実施される動作または行動。
エージェント: 1 つ以上のポリシーを使用して行動を選択および実施するアルゴリズムをカプセル化するとともに、ポリシーをトレーニングするエンティティ。
観測: 環境状態の特性評価。
環境: 解決する RL 問題の定義。環境は、各タイムステップで、観測データを生成し、エージェントによる行動の効果を取り込んだ後、その行動と観測データに基づいて、フィードバックとして報酬を返します。
典型的な RL トレーニング ループの様子:

RL アプリケーションをビルド、評価、デプロイする一般的なプロセスは、次のようになります。
問題をフレーム化する: このブログ記事では映画のレコメンデーション システムを紹介していますが、RL は、さまざまな問題の解決に使用できます。たとえば、典型的な分類の問題を RL で容易に解決できます。この場合には、予測クラスを行動としてフレーム化できます。一例として数字の分類が挙げられます。観測は数字の画像、行動は 0~9 の予測です。報酬は、予測がグラウンド トゥルースの数字に合致しているかどうかを示します。
RL シミュレーション テストを設計して実装する: シミュレーションしたトレーニング データと予測リクエストについては、エンドツーエンド パイプライン デモで詳しく説明します。
オフライン テストのパフォーマンスを評価する。
シミュレーション構成要素を実際のインタラクションに置き換えてエンドツーエンドの本番環境パイプラインを立ち上げる。
RL による映画レコメンデーション システムのビルド方法が分かったところで、次に Vertex AI を使用して RL アプリケーションをクラウドで実行する方法を見ていきましょう。次の Vertex AI サービスを使用します。
Vertex AI トレーニング。RL ポリシー(教師あり学習のモデルに相当)を大規模にトレーニングします。
Vertex AI ハイパーパラメータ調整。最適なハイパーパラメータを見つけます。
Vertex AI 予測。エンドポイントでトレーニングされたポリシーを提供します。
Vertex Pipelines。ワークフローをサーバーレスな方法でオーケストレーションし、Vertex ML Metadata を使用してワークフローのアーティファクトを格納することで、RL システムの自動化、モニタリング、管理を行います。
RL の手順デモ
この手順デモでは、TF-Agents と Vertex AI サービス(主に、カスタム トレーニングとハイパーパラメータ調整、カスタム予測、エンドポイント デプロイメント)を使用して MovieLens レコメンデーション システムをビルドする方法を紹介します。このデモは GitHub で入手できます。手順を説明するノートブックと Python モジュールが含まれています。
デモでは最初に、RL システムの TF-Agents オンポリシー(詳細はデモ内で説明)トレーニング コードを、ノートブック環境でローカルに実施します。その後、TF-Agents の実装を Vertex AI サービスと統合する方法を紹介します。この方法ではトレーニング(およびハイパーパラメータ調整)のロジックをカスタムのトレーニング / ハイパーパラメータ調整コンテナにパッケージングし、そのコンテナを Cloud Build でビルドします。このコンテナと Vertex AI を使用して、リモートのトレーニング ジョブとハイパーパラメータ調整ジョブを実施します。また、最適化の手段として、トレーニング中にハイパーパラメータ調整ジョブから学習した最適なハイパーパラメータを使用する方法も示します。
デモでは予測ロジックも定義します。このロジックは、予測リクエストから観測データ(ユーザー ベクトル)を取り込んで、予測行動(おすすめする映画アイテム)をカスタムの予測コンテナに出力し、そのコンテナを Cloud Build でビルドします。また、トレーニング済みのポリシーを Vertex AI エンドポイントにデプロイし、Vertex AI エンドポイントで予測コンテナをポリシー向けのサービス提供コンテナとして使用します。
クローズドなフィードバック ループを伴うエンドツーエンドのワークフロー: パイプラインのデモ
パイプライン アーキテクチャ
RL のデモに基づき、このワークフローを Vertex Pipelines を使用してスケーリングする方法を説明します。このパイプラインのデモでは、Kubeflow Pipelines(KFP)をオーサリングに使用し、Vertex Pipelines をオーケストレーションに使用して、MovieLens レコメンデーション システム向けのエンドツーエンド MLOps パイプラインをビルドする方法を紹介します。
このエンドツーエンド デモの注目点:
モデルではなく RL モジュール、トレーニング ロジック、トレーニング済みポリシーを扱う、RL 固有の実装
シミュレーションしたトレーニング データ、予測のためにシミュレーションした環境、再トレーニング
予測結果とトレーニングのフィードバック ループを閉じる
カスタマイズ可能で再現性の高い KFP コンポーネント
パイプラインの構造を下図に示します。
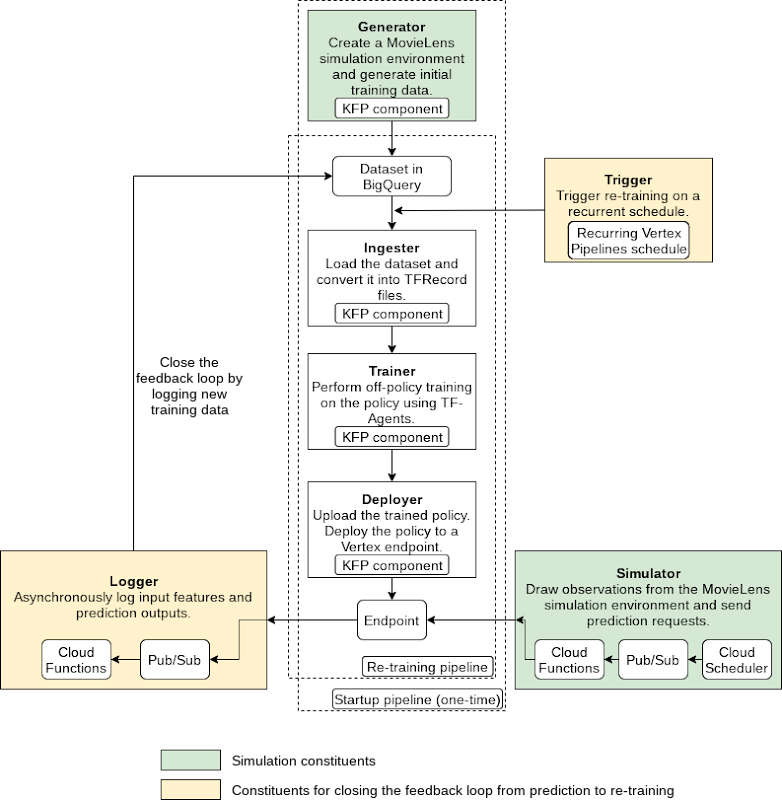
このパイプラインは以下のコンポーネントで構成されます。
Generator(生成ツール): ランダムデータ収集ポリシーを使用して MovieLens シミュレーション データを初期トレーニング データセットとして生成し、BigQuery に格納します(1 度のみ実行)
Ingester(取り込みツール): トレーニング データを BigQuery に取り込み、TFRecord ファイルを出力します
Trainer(トレーニング ツール): トレーニング データセットを使用してオフポリシー(詳細はデモ内で説明)トレーニングを実施し、トレーニング済みの RL ポリシーを出力します
Deployer(デプロイツール): トレーニング済みのポリシーをアップロードし、Vertex AI エンドポイントを作成して、トレーニング済みのポリシーをエンドポイントにデプロイします
上述のパイプラインのほか、他の GCP サービス(Cloud Functions、Cloud Scheduler、Pub/Sub)を利用するコンポーネントが 3 つあります。
Simulator(シミュレーション ツール): 繰り返しシミュレーションされた MovieLens 予測のリクエストをエンドポイントに送信します
Logger(ログツール): 予測リクエストごとに、非同期的に予測の入力と結果をログに記録し、新しいトレーニング データとして BigQuery に返します
Trigger(トリガー): 新しいトレーニング データに対して再トレーニングを繰り返し実施します
Kubeflow Pipelines(KFP)によるパイプライン作成
上記の個々のコンポーネントを使用してパイプラインを作成できます。
パイプラインの実行グラフは次のようになります。
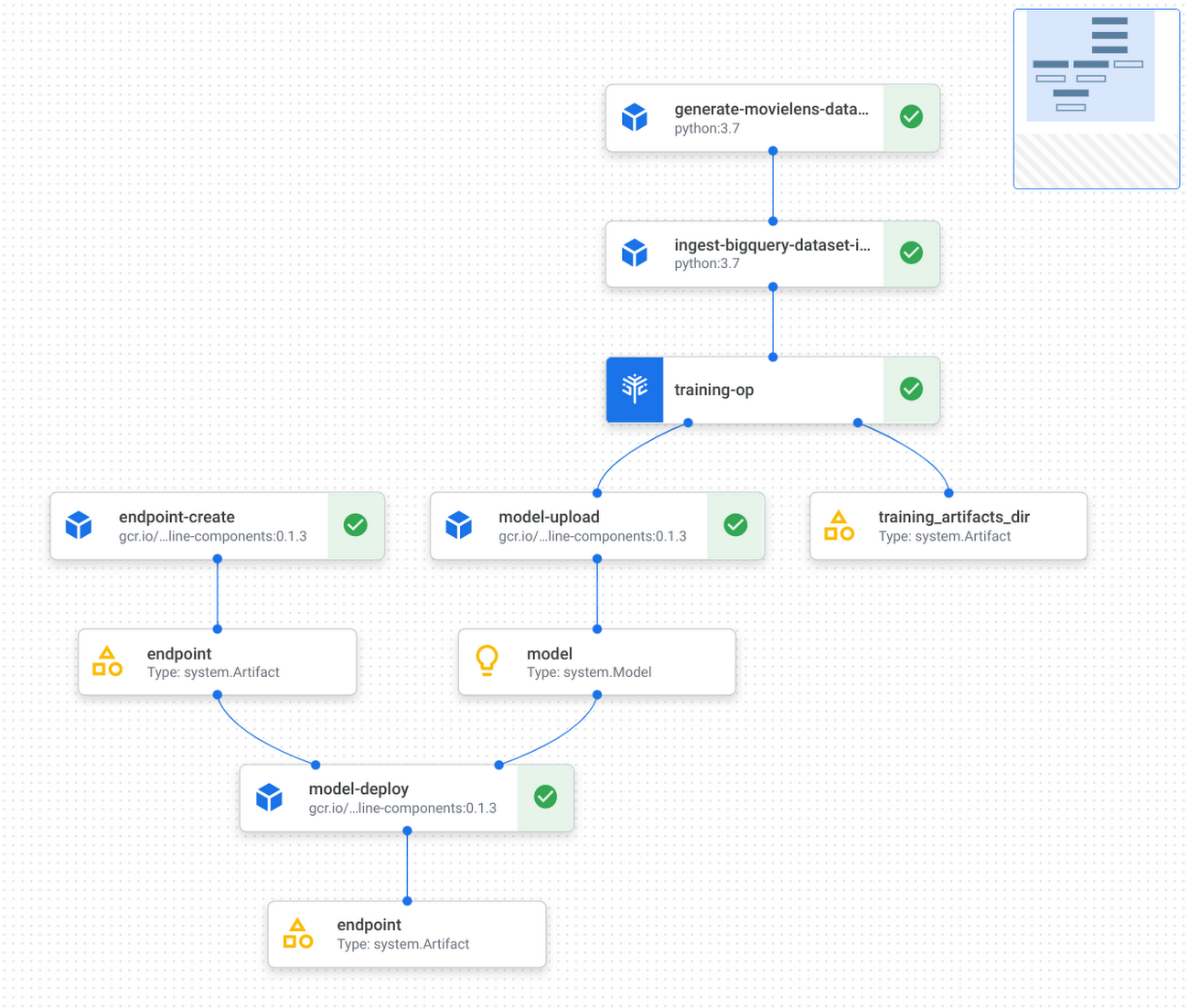
KFP コンポーネントの実装およびテスト方法と Vertex Pipelines によるパイプライン実行方法に関する詳細な手順については、GitHub リポジトリを参照してください。
独自の RL プロジェクトと本番環境にこのデモを適用する
MovieLens シミュレーション環境を現実の環境(観測、行動、報酬などの RL 数値が当該の現実環境における関連アスペクトを反映している環境)に置き換えることができます。現実とのインタラクションをリアルタイムで実施できるかどうかによって、オンポリシー(手順デモで説明)またはオフポリシー(パイプラインのデモで説明)のいずれかのトレーニングおよび評価を選択できます。
実際のレコメンデーション システムを実装する際には以下のことを行います。
ユーザーをいくつかのユーザー ベクトルで表します。ユーザー ベクトルの個々のエントリには現実的な意味(年齢など)を反映させることができます。あるいは、ニューラル ネットワークを介してユーザー エンベディングとして生成できます。同様に、行動の内容および可能な行動(おそらく、プラットフォームで利用可能なすべてのアイテム)を定義します。また、報酬の内容(たとえば、ユーザーがアイテムを試したかどうか、ユーザーがアイテムに費やした時間 / 程度、アイテムに対するユーザーの評価など)も定義します。この場合も、パフォーマンスを最大化するには問題をフレーム化する表現をどのようにしたらよいか、柔軟に決定できます。トレーニング中またはデータの事前収集が行われる間に、実世界からユーザーをランダムにサンプリング(および対応するユーザー ベクトルをビルド)し、アイテムのおすすめに関するポリシーをクエリするための観測データとしてそれらのベクトルを使用します。その後、そのおすすめをユーザーに適用してフィードバックを報酬として取得できます。
この RL デモは、レコメンデーション システム以外の ML アプリケーションにも拡大できます。たとえば、画像分類システムをビルドするユースケースの場合、観測を画像ピクセルまたはエンベディングとし、行動を予測クラス、報酬を予測精度に関するフィードバックとする環境をフレーム化できます。
結論
以上、本記事では、モジュール化され再現性のあるフルマネージド型の方法で、強化学習ソリューションを Vertex AI を使ってビルドする方法を学びました。RL で実現可能なプロジェクトは多岐にわたります。皆さんはこれで、生産システム、調査、個人プロジェクトなどの RL の取り組みをサポートする数多くの Vertex AI サービスや Google Cloud サービスをツールとして利用できるようになりました。
参考情報
[まとめ] 手順デモのリンク: GitHub のリンク
[まとめ] エンドツーエンド パイプライン デモ: GitHub のリンク
バンディットに関する TF-Agents のチュートリアル: 多腕バンディット入門
Vertex Pipelines のチュートリアル: Vertex Pipelines の概要
-SWE インターン Kathy Yu
-ソフトウェア エンジニア Amy Wu




