株式会社セブン-イレブン・ジャパン:これからの IT 戦略を支えるデジタルデータ基盤「セブンセントラル」を Google Cloud 上に構築

Google Cloud Japan Team
日本全国に多数の店舗を展開する大手コンビニエンスストア チェーン、セブン-イレブン・ジャパン。その躍進の背景には他社に先駆けて投資、展開してきた積極的な IT 活用があると言われています。しかし、2000 年代以降のいわゆる IT ジャイアントの台頭や、スマートフォンの普及に伴う社会全体の急速なデジタル化に比して、自社の複雑化したシステムの構造がレガシー化し、抜本的な改革が求められるように。ここでは、そんな同社が将来に向けたデジタル トランスフォーメーション(DX)をはじめとする IT 戦略を支えるため、2020 年 9 月から稼働開始したデジタルデータ活用基盤「セブンセントラル」について、その開発を担当した IT 部門の責任者とエンジニアの皆さんに語っていただきました。
利用している Google Cloud ソリューション:Streaming Analytics 、 Data Lake Modernization 、Data Warehouse Modernization 、Database Modernization
利用している Google Cloud サービス:BigQuery、Cloud Spanner、Dataflow、Cloud Pub/Sub など
ビッグデータの取り扱い、そして将来に向けた拡張性に期待して Google Cloud を選択
「セブンセントラルは、セブン-イレブン・ジャパンが今後、中長期的に IT 戦略を加速させて行く中で、それを支えるデータ活用デジタル基盤。現在、各店舗や本部、社外の既存システム内に散在している各種データを、クラウドに集約し、リアルタイムに活用できるようにするためのものです。その究極の目的は、店頭の最新状況をデータでリアルタイムに把握できるようにすること。たとえば、現在、COVID-19 の影響でセブン-イレブン店舗における売上トレンドも一変しましたが、こうした不確実性の高い状況ではデータを活用した迅速な判断が欠かせません。全社各部署が最新のデータをもとにいち早く状況を把握し、対応する。こうした目的のためにセブンセントラルを構築しました。」
こう説明してくれたのは、今回、セブンセントラルの開発を企画段階から主導したシステム本部 副本部長の西村さん。セブン-イレブン・ジャパンは、創業早期から積極的に情報システムを取り入れ、固定の大手国内ベンダーによる情報システムを長期にわたって利用していたのですが、システムが大きくなるにつれ、自社ドリブンのコントロールが行えず、ビジネス要件の達成をベンダー依存が高い構造で解決する一方で、データとビジネス ロジックがシステム内で一体化し、さらに、レガシーな環境上で構築されデータのサイロ化が徐々に進行。その結果、複数システムにデータが分散して必要なデータが効率的に取り出せなくなる場面や、店舗で収集したデータの参照に時間がかかり、リアルタイム性が必要な業務で適切なタイミングでの施策ができにくくなっているなど、多くの課題が発生していたそうです。さらに、システム間の連携においては時間やコストもかかり、新しいサービスの企画から開発、ローンチまでのスパンがビジネス現場の期待に反して長くなっていました。変化の激しい現在のビジネス環境において、IT 対応がボトルネックとなるリスクが顕在化してきたと西村さんは言います。
「こうした問題を解決すべく、セブンセントラルでは、セブン-イレブン・ジャパン店舗の POS データをはじめとした、汎用性、即時性のあるデータをクラウド基盤上で一元管理。データとロジックを切り離し API を経由したデータ提供をおこなうシンプルなデータマートとすることで、各部の要望に迅速に対応できるようにしています。なお、セブンセントラルで管理・収集するデータは、ビジネスニーズに応じて徐々に拡充する戦略としています。まず、第 1 フェーズでは全 2 万店舗の POS データを収集し、これをリアルタイムに分析できるようにすることを目指しました。今後は、現在は外部に保存されているマスターデータをはじめ、画像・動画などの非構造化データなどニーズの高い情報をセブンセントラルに集約していくことも検討しています。その過程でセンシティブなデータも取り扱う可能性も想定し、セキュリティ対策を十分に講じていかねばならないと考えています。」(西村さん)
セブンセントラルの開発が本格的にスタートしたのは 2019 年初頭。そこに Google Cloud を採用した理由について西村さんは次のように説明します。
「今回、Google Cloud 以外のさまざまなパブリック クラウドを複数の観点で比較・検討しましたが、このプロジェクトでは、今後、デジタル トランスフォーメーションを強化していくという文脈でさまざまな展開を検討しているため『サービスの拡張性』、自社にとって生命線となるデータを取り扱うという点で『セキュリティ』、それに加えて『オープン性』について、特に重視しました。中でもオープン性は、ネガティブな側面としてのベンダー全体依存の体制から脱却し、マルチベンダーでアジャイル開発の体制を構築していくうえで非常に重要だと考えています。この点、 Google Cloud にはオープンなマインドを感じており、我々の思いを理解しながら進めてもらえるのではとも思いました。」(西村さん)
個別のプロダクトでは BigQuery と Apigee を高く評価しているとのこと。事実、この 2 つのプロダクトがセブンセントラルで極めて大きな役割を果たしているそうです。
「BigQuery はペタバイト級の大規模データの高速処理を可能にしながら、マネージド サービスで処理量に応じた課金のため、初期コストを大きく抑えることができます。開発や検証時は最小限のコストで、分析が本格的に始まったら利用した分のコストで、というのはとてもありがたいですね。データを気軽に組織を越えて共有可能なストレージが、スケーラビリティの観点でも、データのサイロ化を解決してくれています。また、機械学習を BigQuery 上で実施できる BigQuery ML など、将来的に活用できそうな面白い機能が揃っていることも気に入っています。」(西村さん)
もう 1 つの Apigee は、セブンセントラルのこだわりの 1 つであるデータとビジネス ロジックの分離に貢献。API を活用したインターフェースの標準化は昨今の流行ですが、現実的には統一的な API を導入しきれず多様な API が乱立しがちです。
「Apigee を導入することで、データ基盤に対する統一的な API を少ない労力で提供可能になります。あわせて、Apigee の認証・認可機能や API 利用の状況の可視化によって、どのデータがどのように利用されているかを API の利用数を通じて把握できるようになることも大きいと考えています。現在は約 2 万店舗分のデータを収集していますが、今後の業務拡大を見越して、3 万店舗、1 店舗あたり 1 日 1,000 人の来店、1 人あたり 5 点の商品を購入しても問題なくスケールして動作するようなシステムとして設計しています。」(西村さん)
BigQuery、Cloud Spanner などを駆使してデータのリアルタイム活用を実現
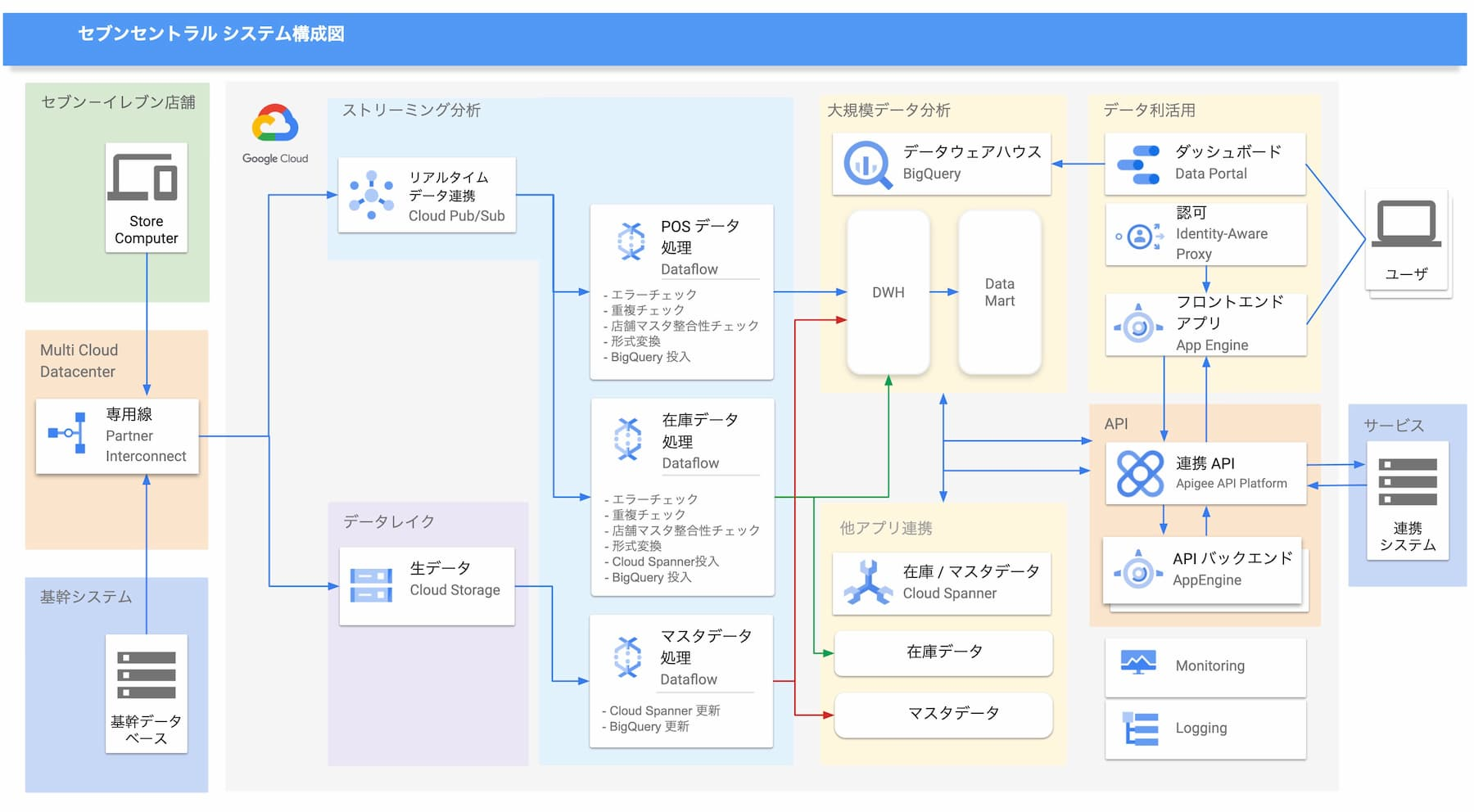
その後、2019 年 3 月には、プラットフォーム検討、アーキテクチャー検討と並行して、Google Cloud 活用に多くの実績があるパートナー、クラウドエースが参加。全国約 2 万 1,000 店から集まってくるデータの分析に BigQuery をフル活用しつつ、求められる即時性を実現させるため、クラウドエースの勧めによって Cloud Spanner も利用することにしました。
「API 経由でのデータ提供のバックエンド ストレージとして Cloud Spanner を推したのは、将来的にどんどんとデータとアクセスが増加していくことが想定される中、高いスケーラビリティがあり、かつリレーショナルなデータベースとして取り扱える Cloud Spanner が好適と考えたから。もちろん、それ以外の部分では、それぞれのストレージをその特徴とサービスからの要求に応じて使い分けています。」(クラウドエース株式会社 技術本部 コンサルティング部 部長 菊地さん)
なお、これだけ大規模なデータをリアルタイムで集計を行い、データをさまざまな活用用途で提供するという技術的なチャレンジに対しては、Google Cloud での開発を数多く手掛けてきたクラウドエースでも多くの苦労があったとのこと。
「2 万を超える店舗から 1 分ごとに集まってくる在庫情報、売上データのトラフィックを、Cloud Spanner と Cloud Dataflow を組み合わせてリアルタイムに集計処理を行おうとしたのですが、リアルタイム処理では計算が複雑なゆえに、単純にワーカー数、ノード数を増やした分だけ処理量が増えるというわけではなく、チューニングには悩まされました。その際、Dataflow や Spanner の挙動などで調査と検証で詰まった際に問い合わせができるサポートがあることは助かりました。事象解決のために推奨の SDK のバージョンを共有いただいたことで、事象が解決したこともありました。また、Dataflow pipeline で期待通りの性能が出なかった際、スケーリング制御機構の概要について情報提供をいただくことで、最終的に目標としていた性能が実現できました。」(菊地さん)
ちなみに POS のデータはメッセージング サービスである Google Cloud のストリーム分析ソリューション を活用して取り込み。リアルタイムにデータを加工し、Cloud Spanner や BigQuery からデータをリアルタイムに活用できるようにしています。
さらにセブンセントラルではシステム構成自体のモダン化に加え、開発手法もウォーターフォール型からアジャイル型に変更。ビジネス検討からアプリケーション実現までのスピード向上と、環境変化への俊敏かつ高頻度な対応に挑戦しました。
「POS データの連携など既存システムの変更にまつわる部分は従来通りウォーターフォール開発となっていたのですが、セブンセントラル自体は完全にアジャイルで開発しています。ウォーターフォール側との工程が合わずちょっとした戻りなどはあったのですが、そうした変更についても柔軟に対応できたのはアジャイルならでは。今後、セブンセントラルはさらなるデータ連携・活用を目指したフェーズ 2 の開発へと進んでいくのですが、今後もこの体制でやっていこうと考えています。なお、今回は開発中に COVID-19 の流行が発生し、各 IT パートナーとリリースまで一切の顔合わせなく開発を進めましたが、ウェブ ミーティングなどを駆使することで円滑なコミュニケーションを実現。スケジュールの変更なくここまでこぎ着けました。」(システム本部システム企画部 佐藤さん)
また、セブン-イレブン・ジャパンとクラウドエースの間のやり取りについては(クラウドエースから)ブリッジ SE を立てるかたちで、プロジェクト マネジメントを効率化。当初まだ Google Cloud に慣れていなかったセブン-イレブン・ジャパン社内エンジニア陣へのサポートを提供しました。
「私の役割は、クラウドエースが設計したシステムの詳細をかみ砕いて、セブン-イレブン・ジャパンのチームにお伝えし、ご相談にも対応させていただくというものでした。朝会でも気軽に相談していただけるチーム醸成を行い、コロナ禍によるリモート中心の業務にもかかわらず、コミュニケーションは円滑だったと思います。弊社の目指す、発注サイドと開発ベンダーがタッグを組んでプロジェクトを遂行するという SI 2.0 の理想的な形を実現できたのではないでしょうか。」(クラウドエース株式会社 技術本部 山内さん)
目標を大きく上回る高速レスポンスが新たな価値を生み出す
2020 年 9 月に本格リリースを迎えたセブンセントラル。西村さんに現時点での手応えを聞いてみました。
「お客さまが商品を購入後、セブンセントラルがそのデータを活用できるようになるまで、当初はその目標時間を 1 時間と設定していました。ところが、できあがったシステムで実際に試してみたところ、わずか 1 分という驚異的な結果に。今後、実際に全店で稼働させた場合でも 5 分程度、悪くても 10 分以内にはサービス側から最新の在庫情報などが確認できると見込んでいます。これは本当に革新的なことで、正直、少し驚きました。今ある課題が解決できるのはもちろんのこと、これまで発想もしなかったような新しい改善やサービスにも繋がっていくのではないかと期待しています。」(西村さん)
本格リリースにあたり、すでに多くの部署から注目を集め、既に多くのリクエストが上がってきているというセブンセントラル。「ビジネス ロジックは持たない」「即時性、汎用性がある」「セブン-イレブン・ジャパンとして独自性がある」という原理・原則に則りながら、今後も収集データや機能を拡充させていき、セブンセントラルを育てていきたいと、西村さんらは言います。
「最近は軽々に AI という言葉を使わないようにしていますが、このようにデータが揃ってくると、AI や機械学習を活用して、新しい領域にチャレンジしていけるのではと考えています。Google Cloud 上でもさまざまな機械学習の技術が提供されているので、例えば、BigQuery ML を利用した各店舗のクラスタリングなど、追加での設備投資なくトライできる範囲から挑戦していきたいですね。また、セブン-イレブン・ジャパンに閉じずに、セブン&アイ・ホールディングス関連会社全体でのデータ活用にもセブンセントラルが活用できるのではないかと考えています。その時には、BigQuery の導入コストの低さや、データがサイロ化しないことによるプロジェクトをまたいだデータセットの共有が簡単である点が有用になるのではないかと考えています。」(西村さん)


(写真左から)
株式会社セブン-イレブン・ジャパン
・システム本部システム企画部 佐藤 毅 氏
・システム本部副本部長 兼 システム企画部総括マネジャー 西村 出 氏
クラウドエース株式会社
・技術本部コンサルティング部 部長 菊地 正太 氏
・技術本部システム開発部 山内 沙織 氏
セブン&アイグループの事業会社として、日本全国に 20,980 店(2020 年 8 月末時点)を展開する国内最大手コンビニエンスストア チェーン。国内コンビニ業界のオピニオンリーダーとして、POS レジの早期導入や、業界初の 24 時間営業、プライベートブランド(セブンプレミアム)の積極展開などを行ってきた。従業員数は 8,959 名(2020 年 2 月末時点)。
(Google Cloud パートナー)
イベントのご案内
本事例について、2020 年 9 月 16 日 (水) 開催のオンラインイベント Data Platform Day #3 にてセブン-イレブン・ジャパン 西村様、佐藤様による講演を予定しています。事例詳細については、ぜひそちらもあわせてご覧ください。→ お申し込みはこちらから
日時:9 月 16 日 (水)
テーマ:「エンタープライズ企業における DX 促進のためデータ分析・基盤とは」
対象者:データベースエンジニア、データ分析エンジニア、データベース管理者
セブン-イレブン・ジャパン事例についての講演
・11:00 - 11:20 Data Platform Day #3 基調講演 ①
・11:50 - 12:30 お客様事例セッション:GCP を活用したセブンイレブンのデータ活用基盤「セブンセントラル」構築



