Colossus の仕組み: Google のスケーラブルなストレージ システムの舞台裏
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
お客様は Google Cloud を信頼して重要なデータを預けていますが、Google もまた、それと基盤を同じとするストレージ インフラストラクチャを利用して他のビジネスを行なっていることをご存じでしょうか。つまり、Google Cloud に使用されているのと同じストレージ システムが、Google の人気の高いプロダクトを支え、YouTube、Google ドライブ、Gmail のような世界中で利用できるサービスをサポートしているのです。
その基盤となるストレージ システムが Colossus です。これは Cloud Storage や Firestore などの Google のストレージ サービスの広範なエコシステムで利用されており、トランザクション処理、データの配信、分析、アーカイブ、ブートディスク、ホーム ディレクトリなどの幅広いワークロードをサポートしています。
この投稿では、VM の背後にあるストレージ インフラストラクチャ、特に Colossus ファイル システムについて、そしてそれが Google サービスとお客様のアプリケーションのスケーラビリティ向上とデータの耐久性の実現にどのように役立っているかを詳しく見ていきます。
Google がスケールすれば Google Cloud もスケールする
ストレージ サービスの動作の仕組みについて詳しく見ていく前に、Google Cloud と Google プロダクトの両方をサポートする単一のインフラストラクチャについて理解しておく必要があります。適切に設計されたソフトウェア システムがそうであるように、Google のサービスはすべて、共通した一連のスケーラブルなサービスで階層化されています。各ストレージ サービスでは次の 3 つの主要な構成要素が使用されています。
Colossus は、クラスタレベルのファイル システムで、Google File System(GFS)の後継です。
Spanner は、グローバルな整合性を備えたスケーラブルなリレーショナル データベースです。
Borg は、コンピューティングからストレージ サービスまでのすべてを起動させるスケーラブルなジョブ スケジューラです。これは Kubernetes の設計と開発に大きな影響を与え続けてきました。
これらの 3 つの主要な構成要素を使用して、Firestore から Cloud SQL、Filestore、そして Cloud Storage まで、あらゆる Google Cloud ストレージ サービスの基盤となるインフラストラクチャが提供されています。お気に入りのストレージ サービスにアクセスしたときにはいつでも、同じ 3 つの構成要素が連携して必要なすべてを提供しているのです。Borg が必要なリソースをプロビジョニングし、Spanner がアクセス許可とデータの場所に関するすべてのメタデータを保存して、Colossus がすべてのデータへのアクセスを管理、保存、提供します。
Google Cloud は、これらと同じ構成要素を使用してすべてを階層化し、ストレージ サービスに求められるレベルの可用性、パフォーマンス、耐久性を実現しています。つまり、お客様独自のアプリケーションは、Google プロダクトと同じくこれら 3 つのサービスを基盤とした同じコア インフラストラクチャを利用して、ニーズに合わせてスケールされます。
Colossus の概要
では、Colossus の仕組みについて詳しく見てみましょう。
まずは、Colossus のバックグラウンドについて簡単にご紹介します。
GFS の後継です。
その設計により、ストレージのスケーラビリティを高め、増え続けるアプリケーションのデータ量の大幅な増加に対応できるように改善されています。
Colossus では分散メタデータ モデルが導入され、よりスケーラブルで可用性の高いメタデータ サブシステムを提供しています。
では、これはどのような仕組みなのでしょうか。また、どのようにして 1 つのファイル システムでこのような幅広いワークロードを支えることができるのでしょうか。次の図は、Colossus コントロール プレーンの主要なコンポーネントを示しています。
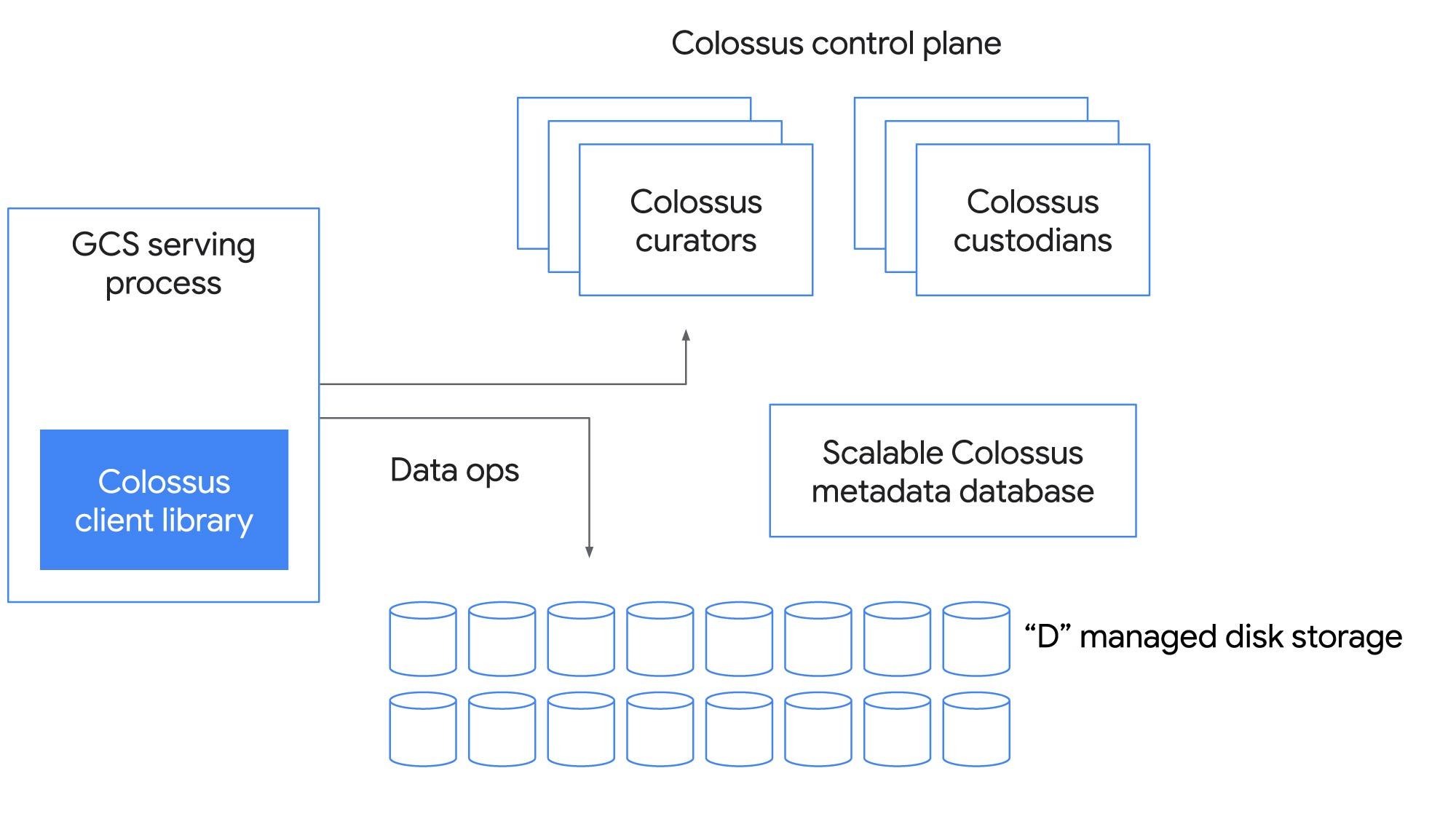
クライアント ライブラリ
クライアント ライブラリは、アプリケーションやサービスが Colossus とやり取りする方法です。クライアントは、ファイル システム全体の中で最も複雑な部分と言えます。ソフトウェア RAID など、アプリケーションの要件に基づいてクライアントに組み込まれる機能が多数あります。Colossus 上に構築されたアプリケーションは、多様なエンコーディングを使用して、さまざまなワークロードに合わせてパフォーマンスと費用のバランスを微調整します。
Colossus コントロール プレーン
Colossus の基盤はそのスケーラブルなメタデータ サービスであり、多数のキュレーターで構成されています。クライアントは、ファイル作成などの制御操作のためにキュレーターと直接対話し、水平方向にスケールできます。
メタデータ データベース
キュレーターは、ファイル システムのメタデータを Google の高性能な NoSQL データベースである Bigtable に保存します。Colossus の構築の当初の動機は、Google File System(GFS)で検索に関連するメタデータを格納しようとしたときに経験したスケーリングの制限を解決することでした。ファイル メタデータを Bigtable に保存することで、Colossus では GFS の最大クラスタの 100 倍以上のスケールアップを実現できました。
D ファイル サーバー
Colossus は、ネットワーク上のデータのホップ数も最小限に抑えます。データは、クライアントと「D」ファイル サーバー(Google のネットワーク接続ディスク)の間を直接流れます。
Custodians
Colossus には Custodians と呼ばれるバックグラウンドでのストレージ管理ツールも含まれています。これらは、データの耐久性や可用性および全体的な効率性を維持し、ディスク スペースのバランス操作や RAID の再構築などのタスクを処理するうえで重要な役割を果たしています。
Colossus で信頼性の高いスケーラブルなストレージを提供する方法
これらすべてが実際にどのように機能するかを確認するために、Cloud Storage が Colossus をどのように使用しているかを考えてみましょう。アーカイブ ストレージから高スループット解析まで、Cloud Storage がどのようにして幅広いユースケースをサポートしているかについてはこれまでも度々お話ししてきましたが、その基盤となるシステムについて話すことはあまりありません。
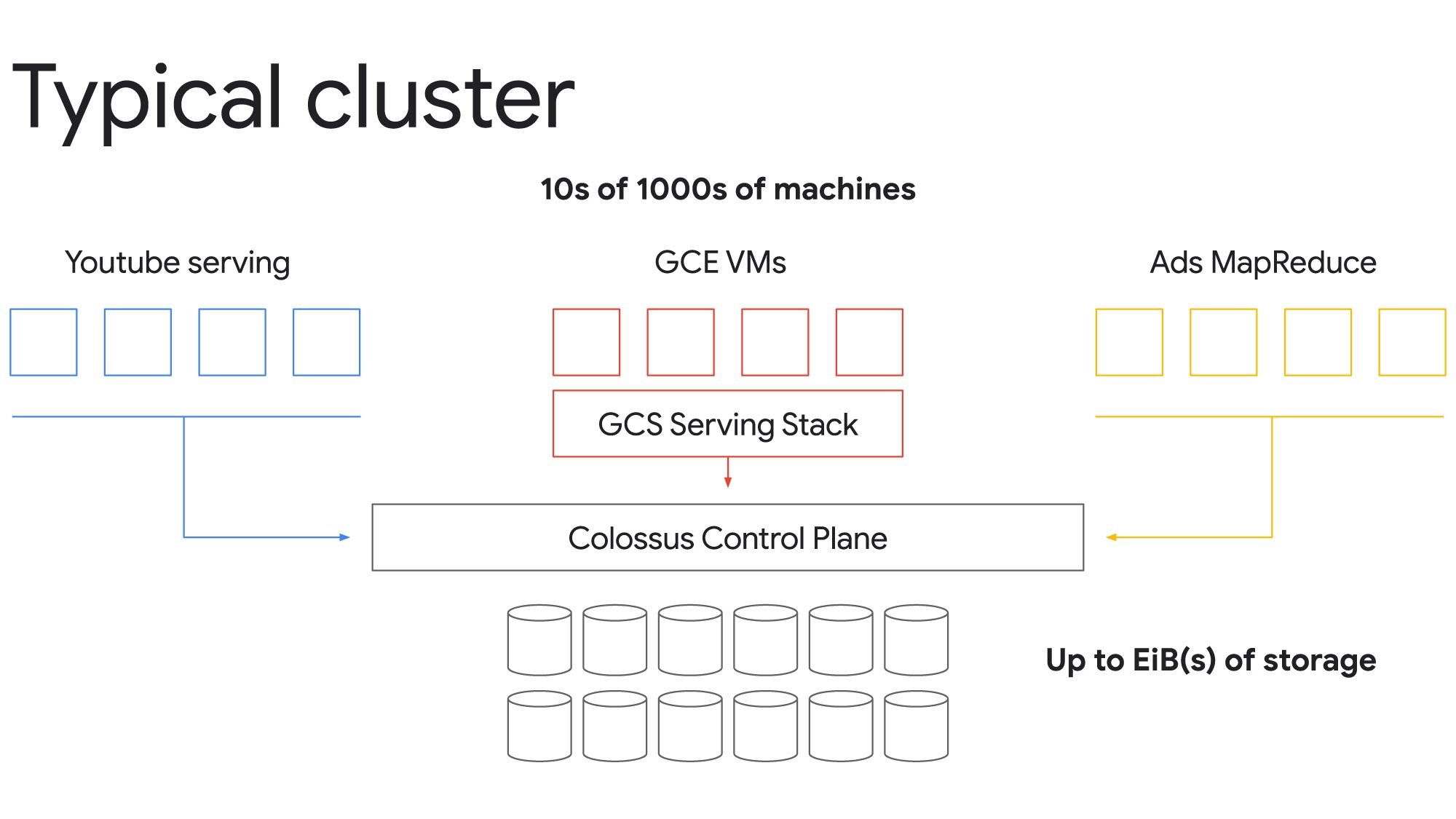
Colossus により、単一のクラスタをエクサバイト規模のストレージと数万台ものマシンにスケールできます。たとえば、前述の例では、Compute Engine VM、YouTube サービス提供ノード、Ads MapReduce ノードから Cloud Storage にアクセスするインスタンスがあり、これらすべてが同じ基盤となるファイル システムを共有してリクエストを完了できます。重要なのは、共有のストレージ プールを Colossus コントロール プレーンで管理することにより、各自がそれぞれ個別のファイル システムを利用しているかのように思わせることです。
リソースを分割することで、貴重なリソースをより効率的に使用し、すべてのワークロード全体でコストを削減できます。たとえば、YouTube 動画のような低レイテンシのワークロードのピーク需要に対応できるようにリソースをプロビジョニングしておき、そうでないアイドル時間のギャップを埋めることで、バッチ分析ワークロードをより低コストで実行できます。
Colossus がもたらすその他の利点もいくつか見ていきましょう。
ハードウェアの複雑さの軽減
ご想像のとおり、Google サービスをサポートするファイル システムのスループットとスケーリングの要件はきわめて厳しく、マルチ テラバイト規模のファイルと膨大なデータセットを処理する必要があります。Colossus は多数の物理的なハードウェアの混在による複雑さを解消し、ストレージを大量に使用するアプリケーションでも利用できるようにします。
Google データセンターには膨大な種類の基盤となるストレージ ハードウェアがあり、サイズとタイプが異なるさまざまな回転ディスクやフラッシュ ストレージを組み合わせてサービスを提供しています。それに加えて、アプリケーションには、耐久性、可用性、レイテンシに関する多種多様な要件があります。各アプリケーションに必要なストレージを確保できるように、Colossus ではさまざまなサービスティアを提供しています。アプリケーションは I/O、可用性、耐久性の要件を指定してこれらのさまざまなティアを使用し、リソース(バイトおよび I/O)を抽象的な区別されていない単位としてプロビジョニングします。
さらに、Google 規模では、ハードウェアは実質的にひっきりなしに故障しています。これは信頼性が低いためではなく、ハードウェアが多数あるからです。このような大規模な運用では障害は自然なことであり、そのファイル システムでフォールト トレランスと透過的なリカバリを提供することが不可欠です。Colossus はこのような障害を回避するように IO を操作し、迅速なバックグラウンド リカバリを行なって、耐久性と可用性に優れたストレージを提供します。
その結果、ハードウェア リソースの処理に関連する複雑な問題が大幅に軽減され、アプリケーションは必要なストレージを簡単に取得して使用できるようになります。
ストレージ効率を最大化
さて、ご想像のとおり、過剰にプロビジョニングせずに、アプリケーションが必要に応じてストレージ リソースを使用できるようにするには魔法のような管理術が必要です。Colossus は、データにはさまざまなアクセスのパターンと頻度(頻繁にアクセスされるホットデータなど)があるという事実を利用して、フラッシュ ストレージとディスク ストレージを組み合わせてあらゆるニーズに対応しています。
最もホットなデータは、より効率的に低レイテンシで提供できるようにフラッシュ ストレージに配置されます。ギガバイトあたりの I/O 密度をディスクが通常提供できる高さに押し上げるのに十分なだけのフラッシュ ストレージを購入し、十分な容量を確保するのに十分なだけのディスクを購入します。これらを適切に組み合わせることで、ストレージ効率を最大化し、無駄な過剰プロビジョニングを回避できます。
ディスクベースのストレージについては、過剰な在庫や無駄なディスク IOPS を回避するために、ディスクをいっぱいにしてビジー状態に保ちたいと考えます。このために、Colossus はインテリジェントなディスク管理を使用して、実現可能なディスク IOPS から可能な限り多くの価値を引き出しています。新しく書き込まれたデータ(つまり、よりホットなデータ)は、クラスタ内のすべてのドライブに均等に分散されます。その後、データが古くなってコールドデータになると、リバランスされて容量の大きいドライブに移動されます。これは、たとえば、データが古くなると一般的にアクセス頻度が少なくなる分析ワークロードに最適です。
大規模な配信のために十分にテスト済み
以上で、Colossus が Google のストレージ インフラストラクチャの背後に隠されたスケーリングの超能力であることがおわかりいただけたかと思います。Colossus は、Google Cloud サービスのストレージ ニーズを処理するだけでなく、Google 内部のストレージ ニーズに対応するストレージ機能も提供し、検索、マップ、YouTube などを毎日使用する何十億もの人々にコンテンツを配信するのに役立っています。Google Cloud でビジネスを構築すると、Google が稼働し続ける、十分にメンテナンスされた同じインフラストラクチャにアクセスできることになります。Google は絶えずインフラストラクチャの改善を図っているため、お客様は何もする必要はありません。
Google Cloud のストレージ アーキテクチャの詳細については、この投稿の原案となった Next ‘20 のセッション「A peek at the Google Storage infrastructure behind the VM」(VM の背後にある Google Storage を覗き見る)をご覧ください。また、すべてのストレージ サービスの詳細については、クラウド ストレージのウェブサイトをご確認ください。
- Office of the CTO テクニカル ディレクター Dean Hildebrand
- Google Cloud Storage テクニカル リーダー Denis Serenyi


