GKE での ML / AI 推論向けのデータ読み込みに関するベスト プラクティス
Brian Kaufman
Senior Product Manager, Google
Akshay Ram
Group Product Manager, GKE
※この投稿は米国時間 2024 年 11 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
AI モデルが高度化するなかで、サービス提供には大規模なモデル データがますます必要となってきています。推論のために必要なフレームワークとともにモデルと重みを読み込むと、数秒、場合によっては数分のスケーリングの遅延が発生し、費用とエンドユーザーのエクスペリエンスの両方に影響を与えます。
たとえば、Triton、Text Generation Inference(TGI)、vLLM などの推論サーバーはコンテナとしてパッケージ化されており、多くの場合、そのサイズは 10GB を超えています。そのため、ダウンロードに時間がかかり、Kubernetes の Pod の起動時間が長くなる可能性があります。その後、推論 Pod が起動すると、モデルの重みを読み込む必要があり、そのサイズは数百 GB にもなり、データ読み込みの問題がさらに大きくなります。
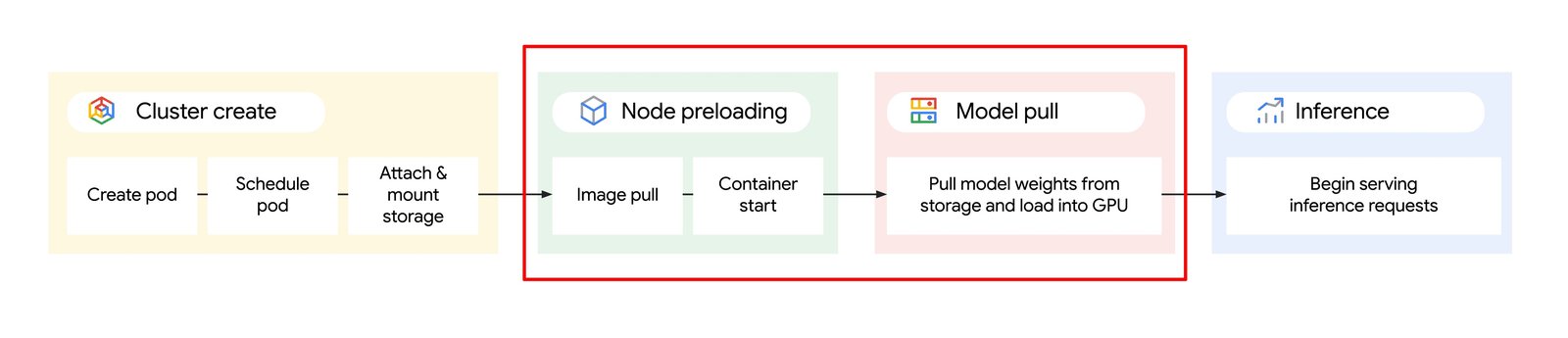
このブログでは、推論サービング コンテナおよびモデルと重みのダウンロードの両方でデータ読み込みを高速化する手法をご紹介します。これにより、Google Kubernetes Engine(GKE)での AI / ML 推論ワークロードの読み込み時間を全体的に短縮できるようになります。
1. コンテナ読み込み時間を短縮するために、セカンダリ ブートディスク を使用してコンテナ イメージをお使いの推論エンジンと適用可能なライブラリを使用して直接 GKE ノードでキャッシュに保存する。
2. Google Cloud Storage からのモデルと重みの読み込み時間を短縮するために、 Cloud Storage FUSE または Hyperdisk ML を使用する。
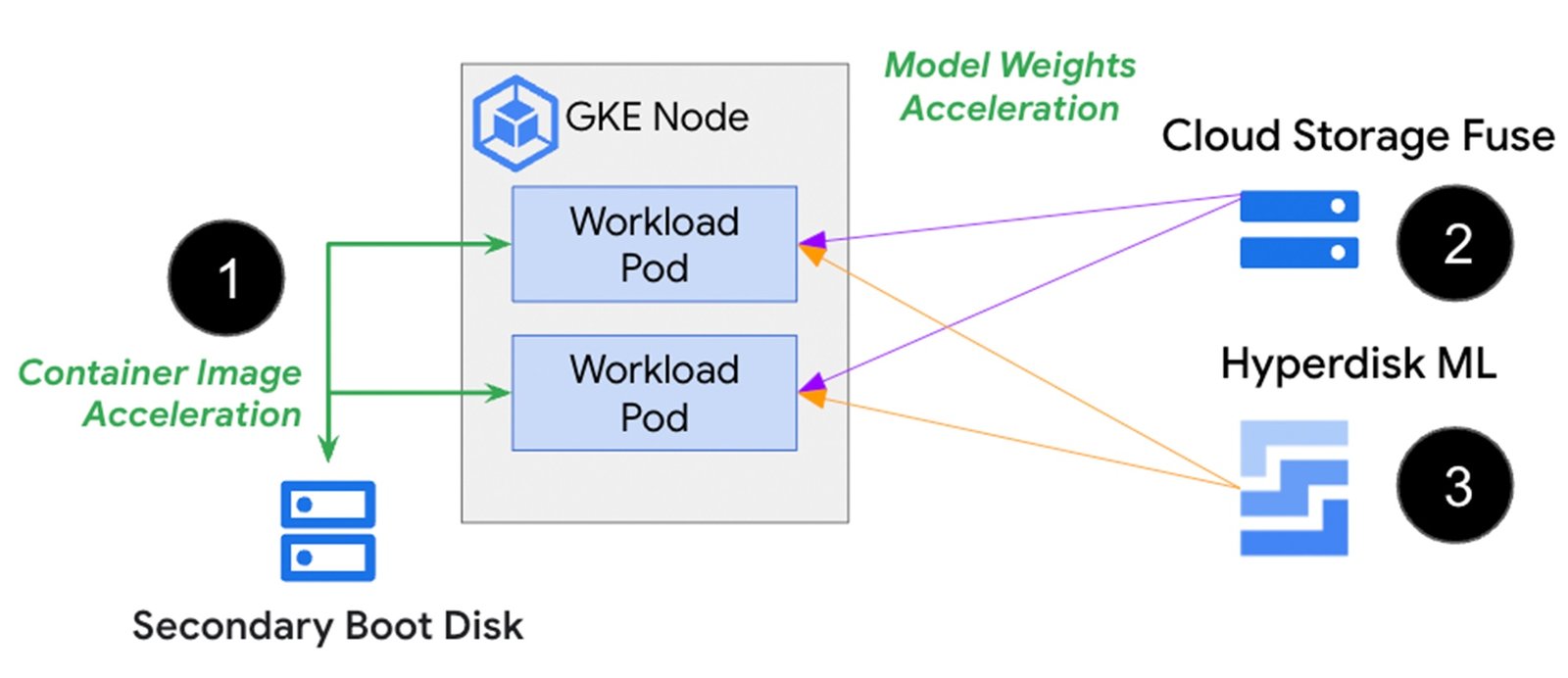
上の画像は、セカンダリ ブートディスク(1)がコンテナ イメージを事前に保存することで、Pod やコンテナの起動中にイメージをダウンロードするプロセスを回避できることを示しています。スピードとスケールが要求される AI / ML 推論ワークロードでは、Cloud Storage またはネットワーク接続されたディスクに保存されたモデルと重みのデータに Pod を接続するオプションとして、Cloud Storage Fuse(2)と Hyperdisk ML(3)があります。以下でそれぞれのアプローチをより詳しく見ていきましょう。
セカンダリ ブートディスクでコンテナ読み込み時間を短縮する
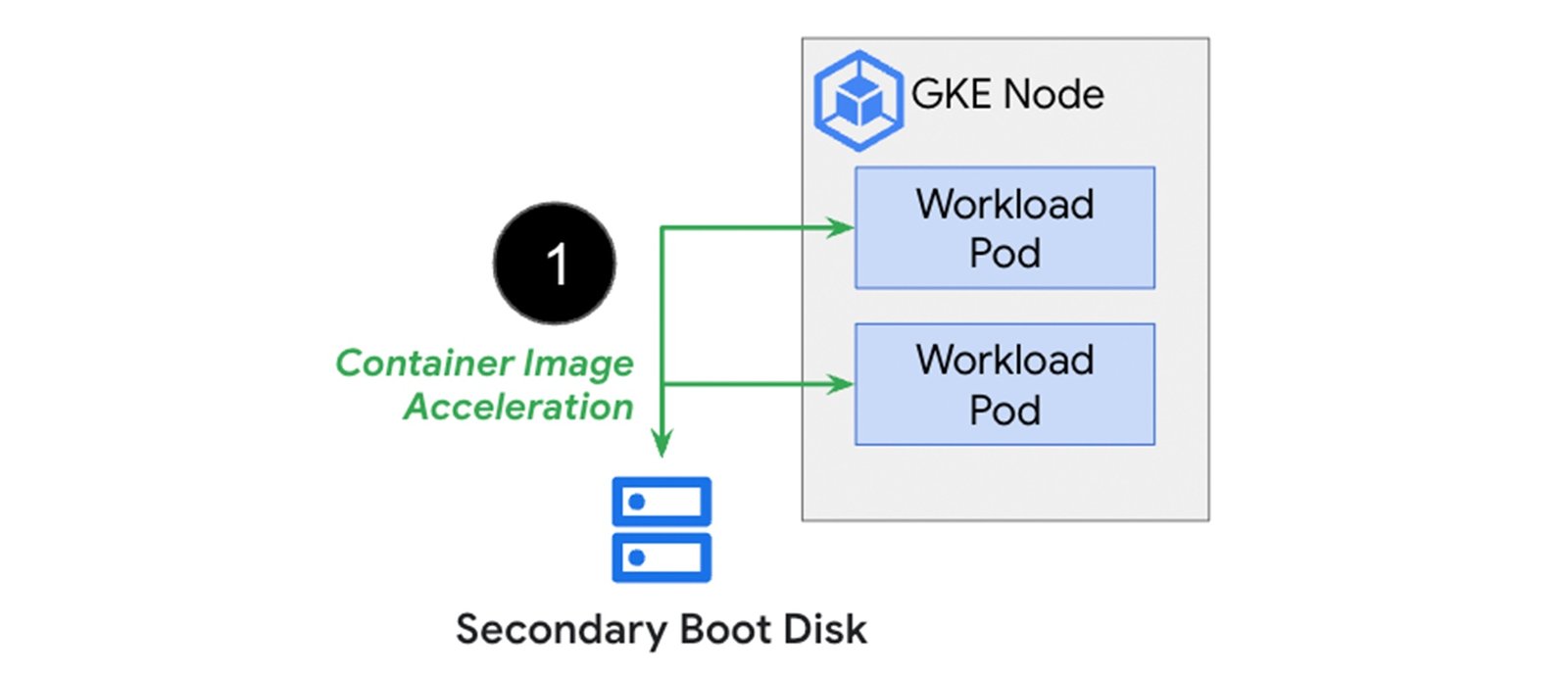
GKE を使用すると、作成時にノードに接続されるコンテナ イメージを事前にセカンダリ ブートディスクにキャッシュ保存できます。この方法でコンテナを読み込むメリットは、イメージのダウンロード ステップを省略し、コンテナの起動をすぐに開始できるため、起動時間が大幅に短縮されることです。以下の図は、コンテナ イメージのダウンロード時間がコンテナ イメージのサイズに比例して長くなることを示しています。そしてこれらの時間を、ノードで事前に読み込まれキャッシュに保存されたバージョンのコンテナ イメージを使用した場合と比較しています。
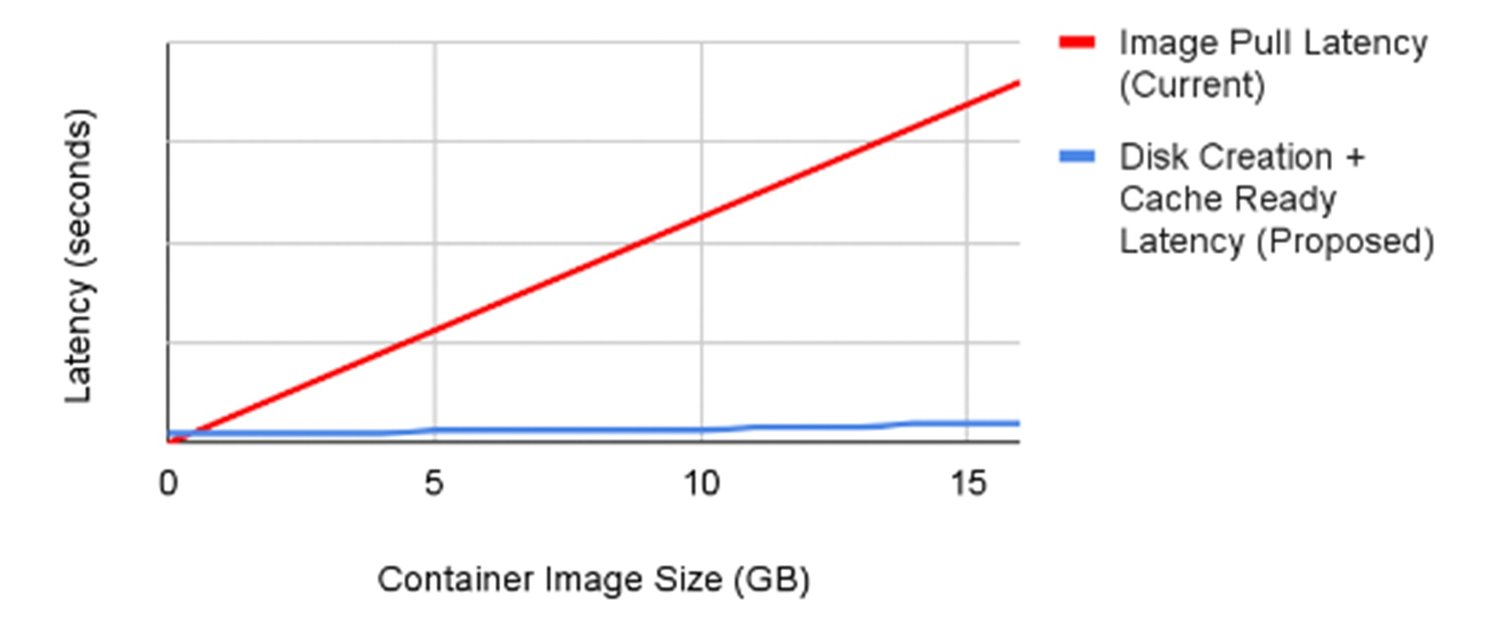
セカンダリ ブートディスクに 16GB のコンテナ イメージを事前にキャッシュ保存することで、Container Registry からコンテナ イメージをダウンロードする場合と比較して、読み込み時間が最大 29 倍短縮されたのがわかります。さらに、このアプローチでは、コンテナサイズに依存しないアクセラレーションのメリットを享受できるため、大規模なコンテナ イメージを想定どおりの速さで読み込むことができます。
セカンダリ ブートディスクを使用するには、まずすべてのイメージを含むディスクを作成し、そのディスクからイメージを作成して、GKE ノードプールを作成する際にディスク イメージをセカンダリ ブートディスクとして指定します。詳しくは、ドキュメントをご覧ください。
モデルの重みの読み込み時間の短縮
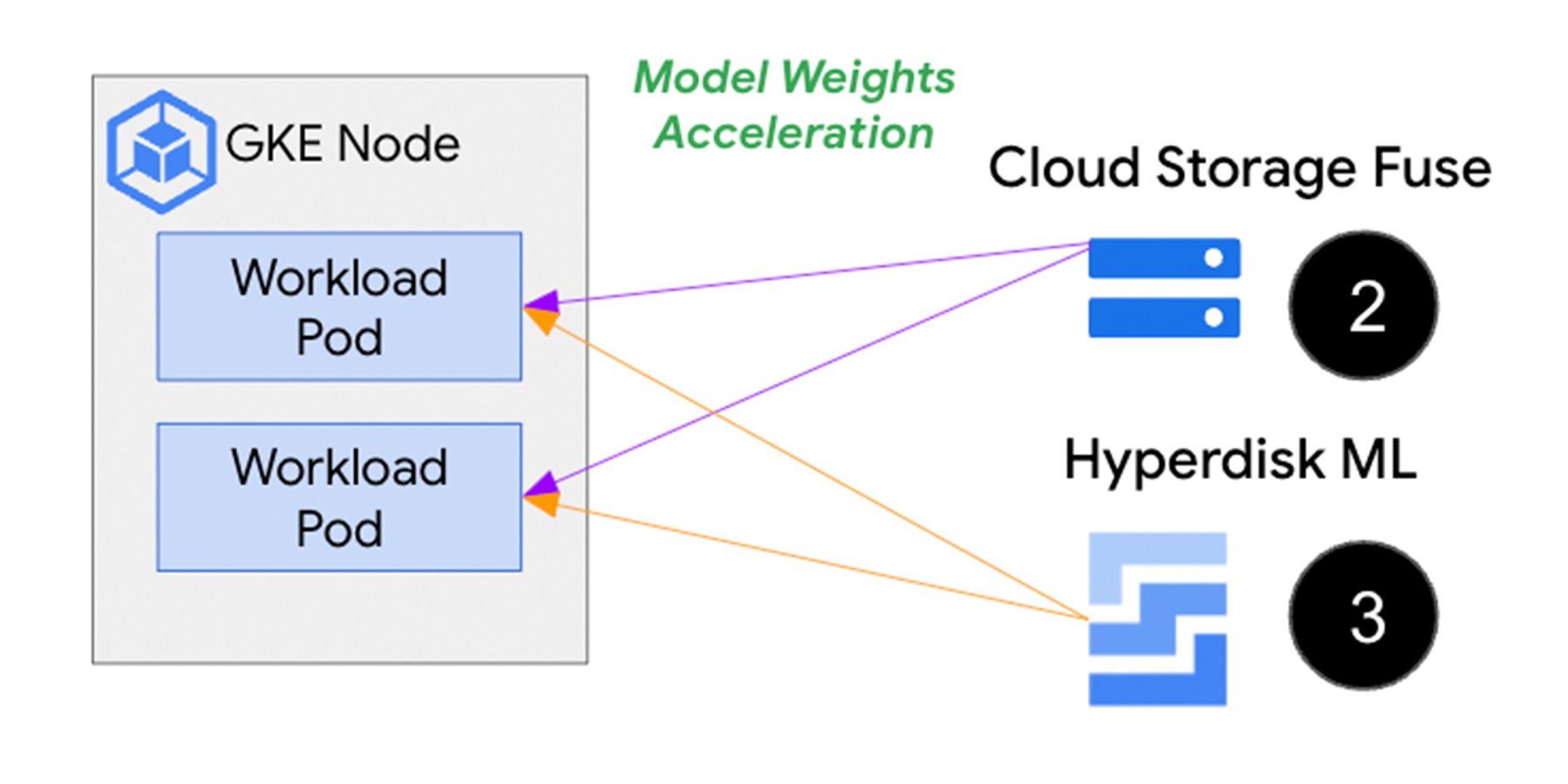
多くの ML フレームワークは、長期の保存によく使用される Google Cloud Storage などのオブジェクト ストレージにチェックポイント(モデルの重みのスナップショット)を出力します。Cloud Storage を信頼できる情報源として使用して、GKE-Pod レベルでデータを取得するには、Cloud Storage Fuse と Hyperdisk ML(HdML)の 2 つのプロダクトがあります。
どちらか一つのプロダクトを選ぶ際に考慮すべき主な点は次の 2 つです。
-
パフォーマンス - GKE ノードがどれだけ迅速にデータを読み込めるか
-
運用のシンプルさ - いかに簡単にデータを更新できるか
Cloud Storage Fuse は、オブジェクト格納バケットに存在するモデルの重みについて、Cloud Storage への直接リンクを提供します。さらに、ソースバケットからの追加ダウンロード(レイテンシが発生する)を防ぐために、読み取りが複数回必要なファイル向けにキャッシング メカニズムを備えています。なぜ Cloud Storage Fuse が魅力的かというと、特定のバケットで新しいファイルをダウンロードするために Pod が事前にハイドレーションの運用アクティビティを行う必要がないからです。ここで注意すべき重要な点は、Pod が接続しているバケットを切り替える場合は、更新された Cloud Storage FUSE の構成を使用して Pod を再起動する必要があることです。パフォーマンスをさらに向上させるには、並列ダウンロードを有効化できます。並列ダウンロードは、モデルをダウンロードするために複数のワーカーを生成し、モデルの pull パフォーマンスを大幅に向上させます。
Hyperdisk ML は、Cloud Storage やその他のオンラインの場所から Pod に直接ファイルをダウンロードするよりも優れたパフォーマンスとスケーラビリティを提供します。さらに、1 つの Hyperdisk ML インスタンスに最大 2,500 ノードを接続でき、総帯域幅は最大1.2 TiB/秒となります。これは、多くのノードにまたがる推論ワークロードや、同じデータを読み取り専用で繰り返しダウンロードするような場合に特におすすめです。Hyperdisk ML を使用するには、データを使用する前に Hyperdisk ML ディスクに読み込み、更新するたびに再度読み込みます。ただし、データが頻繁に変更される場合、業務にかかるオーバーヘッドが増えます。
モデルと重みの読み込みにどのプロダクトを使用するかは、ユースケースによって異なります。次の表で、各プロダクトの詳細な比較を確認できます。
ご覧のとおり、パフォーマンスの高いモデル読み込み戦略を構築する際は、スループット以外にも考慮事項があります。
まとめ
大規模な AI モデル、重み、コンテナ イメージを GKE ベースの AI モデルに読み込むと、ワークロードの起動時間の遅延が発生します。上で説明した 3 つの方法の組み合わせ(コンテナ イメージのセカンダリ ブートディスク、Hyperdisk ML またはモデルと重み向け Cloud Storage Fuse)を使用することで、AI / ML 推論アプリケーションのデータ読み込み時間を短縮しましょう。
次のステップ:
