Dataplex の自動検出機能により、Cloud Storage データを分析とガバナンスで利用可能に
Parth Desai
Product Manager, Google
※この投稿は米国時間 2024 年 11 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
データと AI の活用が一段と進む昨今の世界において、組織は増え続ける構造化データと非構造化データへの対応に苦慮しています。このデータ量の増加により、適切なタイミングで適切なデータを見つけることがますます難しくなっており、企業データのかなりの部分が未検出、または十分に活用されていないままとなっています。多くの場合、こうしたデータは「ダークデータ」と呼ばれます。実際、66% もの組織が、データの半分以上はこの状態にあると報告しています。
この課題に対処するため、Google はこのたび、Dataplex による Google Cloud Storage データの自動検出とカタログ化の機能をリリースしました。Dataplex は、インテリジェント データから AI ガバナンスを実現する、BigQuery の統合プラットフォームの一部です。この強力な機能により、組織は以下のことが可能になります。
-
自動検出: ドキュメント、ファイル、PDF、画像などの構造化データと非構造化データを含む、Cloud Storage 内に存在する貴重なデータアセットを自動的に検出します。
-
収集とカタログ化: データの変化に合わせて組み込みの互換性チェックとパーティション検出を行い、スキーマ定義を最新に保つことで、検出されたアセットのメタデータを収集、カタログ化します。
分析の有効化: 自動作成された BigLake テーブル、外部テーブル、オブジェクト テーブルにより、データ サイエンスや AI のユースケースを大規模に分析できるようになり、データの重複やテーブル定義の手動作成が不要になります。
仕組み
Dataplex の自動検出およびカタログ化プロセスは、統合された効率的な設計となっており、以下の手順に沿って操作します。
-
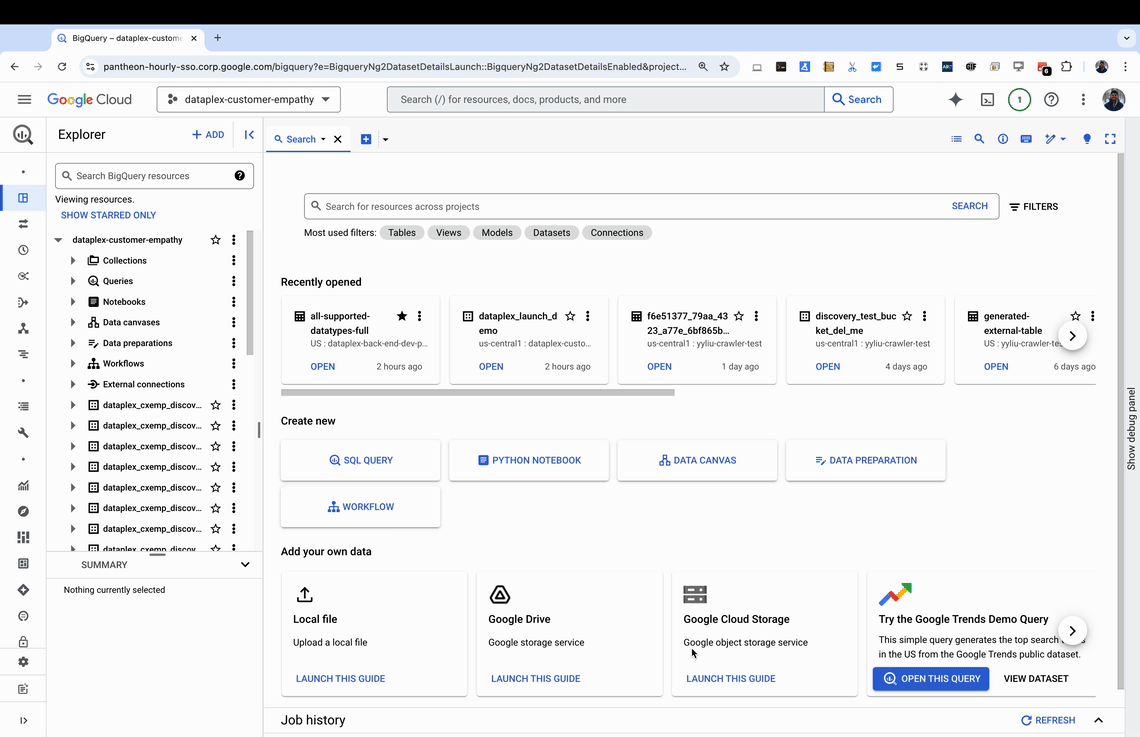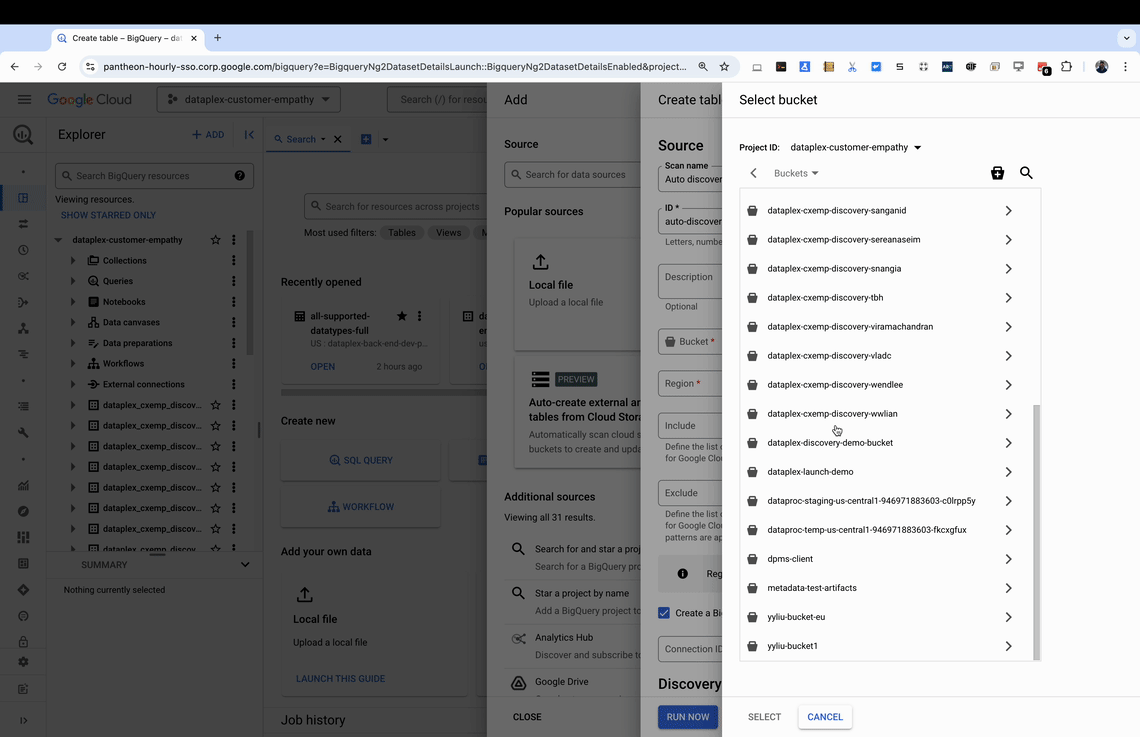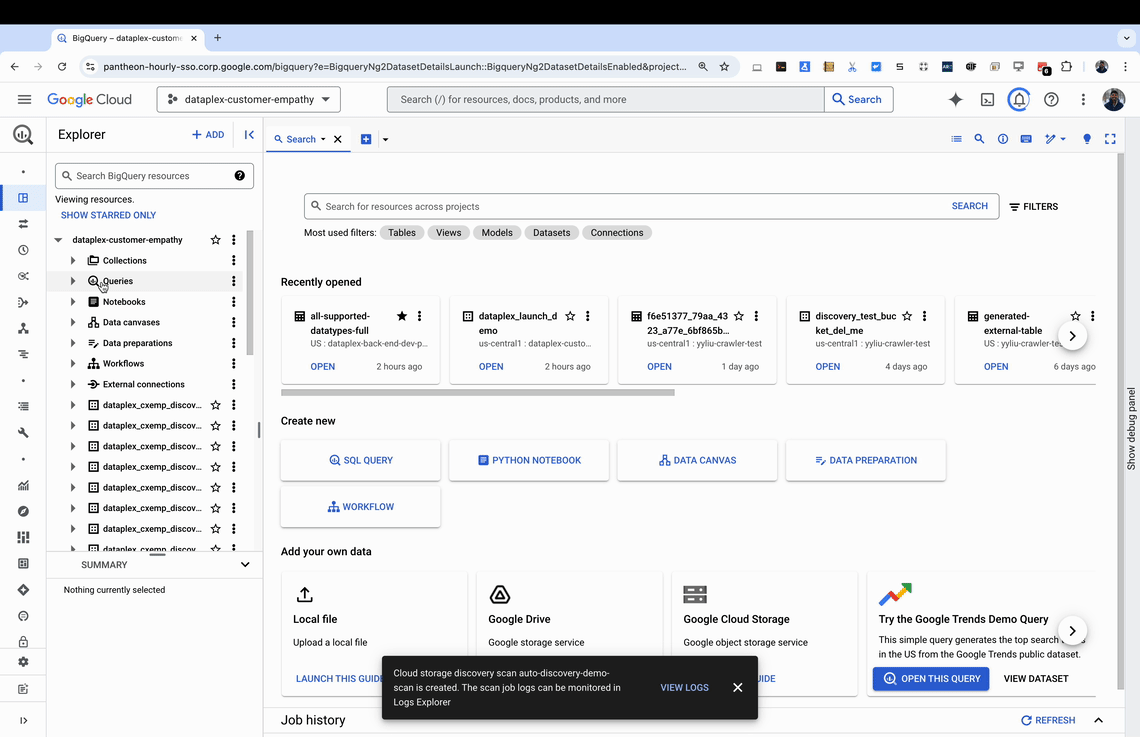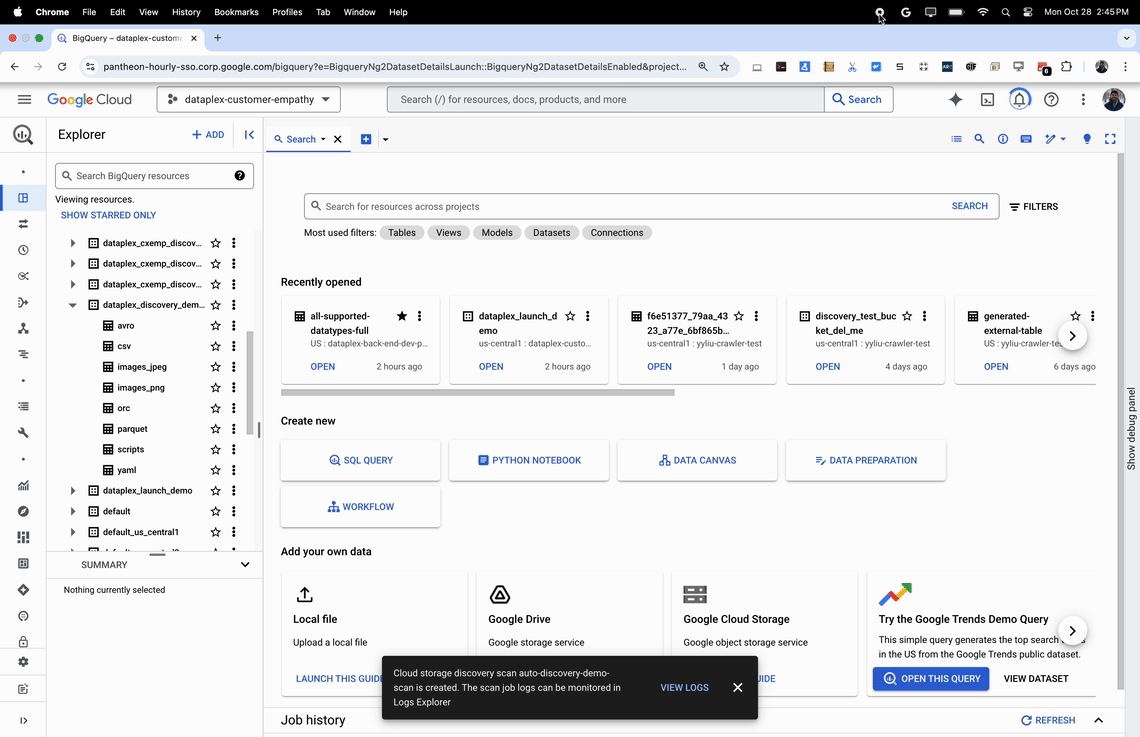
検出スキャン: 検出スキャンは、ユーザーが BigQuery Studio の UI、CLI、gcloud を使って構成し、最大数百万のファイルがある Cloud Storage バケットをスキャンし、データアセットを識別して分類します。
-
メタデータの抽出: 検出されたアセットから、スキーマ定義やパーティション情報などの関連メタデータを抽出します。
-
BigQuery でのデータセットとテーブルの作成: 多数の BigLake テーブル、外部テーブル、オブジェクト テーブル(非構造化データ用)の新しいデータセットが、正確かつ最新のテーブル定義を使って BigQuery に自動的に作成されます。スケジュール設定されたスキャンでは、Cloud Storage バケット内のデータが変化すると、これらのテーブルも更新されます。
-
分析と AI の準備: 公開されたデータセットとテーブルは、BigQuery だけでなく、Spark、Hive、Pig などのオープンソース エンジンでの分析、処理、データ サイエンス、AI のユースケースに利用できます。
- カタログ統合: BigLake テーブルはすべて Dataplex カタログに統合されているため、検索やアクセスが簡単に行えます。

主な利点
Dataplex の自動検出およびカタログ化機能は、組織に多くの利点をもたらします。
-
データの可視性の向上: Google Cloud 全体のデータと AI アセットを明確に把握できるため、当て推量をなくし、関連情報の検索にかかる時間を短縮します。
-
手作業の削減: Dataplex によってバケットをスキャンし、Cloud Storage 内のデータに対応する多数の BigLake テーブルを作成することで、手作業でテーブル定義を作成するトイルと労力を削減します。
-
分析と AI の加速: 検出されたデータを分析および AI ワークフローに組み込むことで、価値の高い分析情報を引き出し、情報に基づいた意思決定を促進します。
-
データアクセスの簡素化: 適切なセキュリティ基準と管理基準を維持しながら、承認されたユーザーが必要なデータに簡単にアクセスできるようにします。
Cloud Storage の管理と、ストレージ資産全体に対する分析情報の取得に関心のあるストレージ管理者の方は、AI を活用したクエリと分析情報で Cloud Storage のフットプリントを把握する方法についてのブログ投稿をご覧ください。
データの可能性を引き出す
Dataplex の自動検出とカタログ化は、組織がデータの可能性を最大限に引き出すための重要な一歩です。ダークデータに関連する課題を解消し、Cloud Storage アセットの包括的で検索可能なカタログを提供することで、Dataplex はデータに基づく意思決定を、自信を持って行えるようにします。
この強力な新機能をぜひお試しいただき、その利点を実際にお確かめください。詳細を確認して、使用を開始するには、Dataplex のドキュメントをご覧いただくか、Google の担当チームにサポートをご依頼ください。
-Google、プロダクト マネージャー Parth Desai


