SRE の原則を使用し、Cloud Monitoring ダッシュボードでパイプラインをモニタリングする
Google Cloud Japan Team
※この投稿は米国時間 2020 年 3 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
データ パイプラインはリアルタイム データのストリームを操作し、大量のデータを処理する機能を提供します。重要な指標の多くは独特であるため、データ パイプラインのモニタリングが課題になる可能性があります。たとえばデータ パイプラインでは、パイプラインのスループット、データがパイプラインを通過する時間、リソース制約の有無を把握する必要があります。このような考察はクラウド インフラストラクチャの稼働を維持し、ひいてはビジネスニーズを先取りするために欠かせません。
リアルタイム データを含む複雑なシステムのモニタリングは、運用管理を円滑にするための重要な要素です。システムを測定して潜在的な問題を見つけるために使えるヒントとコツがいくつかあります。Google の書籍の第 6 章 Monitoring Distributed Systems には、Google のサイト信頼性エンジニアリング(SRE)チームからの優れたガイダンスが提供されており、システムでモニタリングする方法や対象を計画する際に推奨される、4 つのゴールデン シグナルについて詳細を確認できます。
4 つのゴールデン シグナルとは以下を指します。
レイテンシ - サービスがリクエストの処理にかける時間
トラフィック - サービスに対する要求の量
エラー - サービスが失敗する割合
飽和度 - サービスのリソースがフル使用にどれだけ近いかを示す尺度
これらのモニタリング カテゴリは、システムや特定のデータ処理パイプラインでモニタリングする対象を検討する際に利用できます。
Cloud Monitoring(旧称 Stackdriver)は、Google Cloud サービス向けに自動的に収集される一連の統合指標を提供します。Cloud Monitoring を使用すると、ダッシュボードを構築してデータ パイプラインの指標を可視化できます。また、Dataflow、Kubernetes Engine、Compute Engine などの一部のサービスには、それぞれの UI や Monitoring UI に直接表示される指標があります。この記事では、サンプルのデータ パイプラインの Cloud Monitoring ダッシュボードを構築するために必要な指標について説明します。
データ処理パイプラインをモニタリングする指標を選択する
Pub/Sub イベント、Dataflow パイプライン、BigQuery に基づくイベント ドリブン型データ パイプライン(データの最終的な送信先は BigQuery)について次の例で説明します。
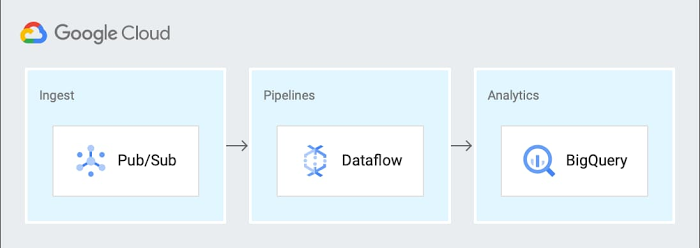
このパイプラインは次の手順に一般化できます。
指標データを Pub/Sub トピックに送信する
Dataflow ストリーミング ジョブで Pub/Sub サブスクリプションからデータを受信する
結果を分析用に BigQuery に書き込み、アーカイブ用に Cloud Storage に書き込む
Cloud Monitoring は、Dataflow の [ジョブの詳細] ページと Cloud Monitoring UI 自体の 2 か所で、Dataflow ジョブの強力なロギングと診断機能を提供します。
Cloud Monitoring と Dataflow の統合により、Dataflow の [ジョブの詳細] ページで、ジョブ ステータス、要素数、システムラグ(ストリーミング ジョブの場合)、ユーザー カウンタなどの Dataflow ジョブ指標に直接アクセスできます(この統合をコンテキストのオブザーバビリティと呼びます。指標は、それらを生成するジョブのコンテキストで表示、監視されるためです)。
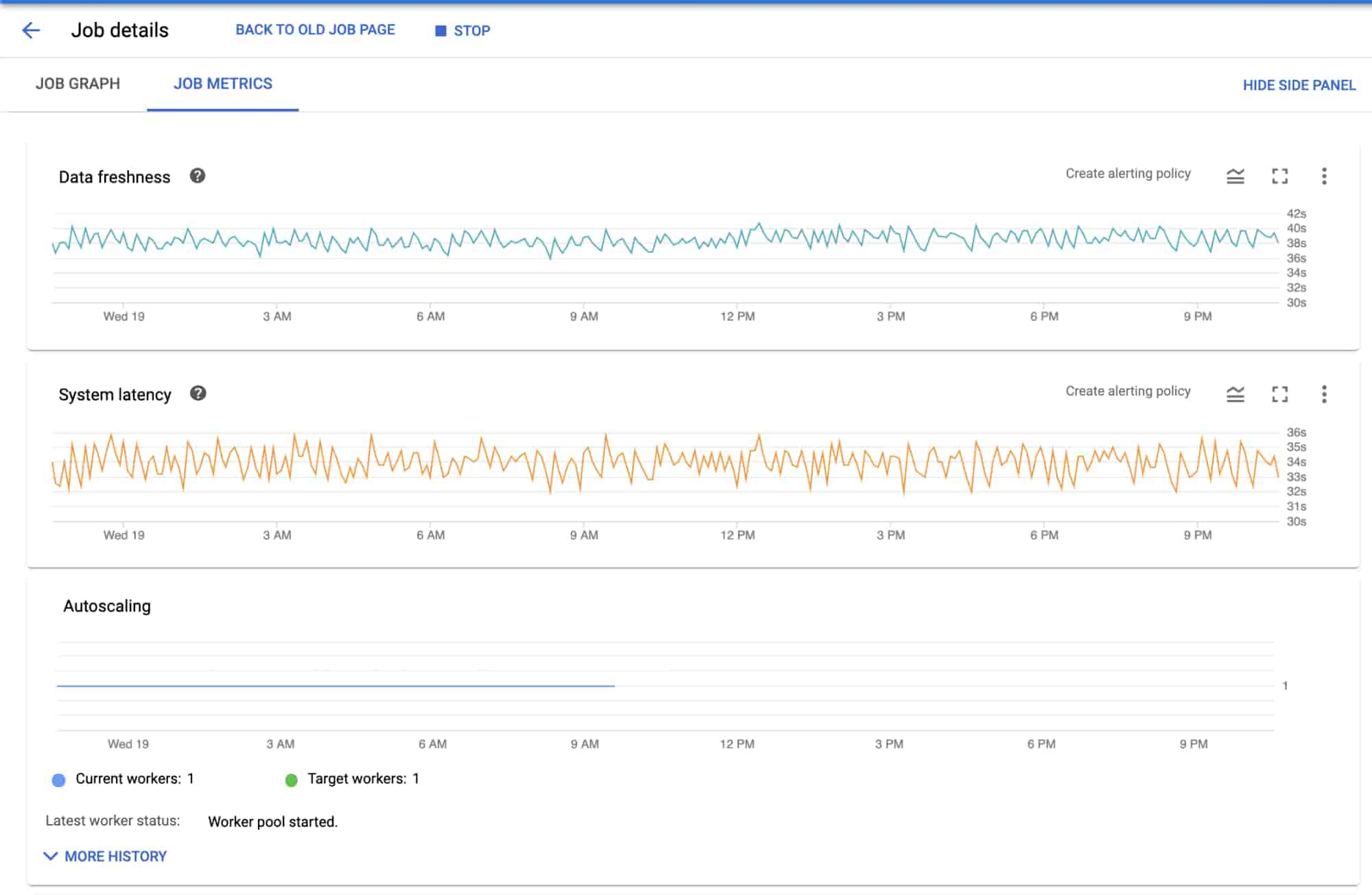
タスクが Dataflow ジョブのモニタリングの場合、Dataflow 自体の [ジョブの詳細] ページに表示される指標で優れたカバレッジが提供されます。アーキテクチャ内の他のコンポーネントをモニタリングする必要がある場合、Cloud Monitoring 内のダッシュボードで、Dataflow 指標を BigQuery や Pub/Sub などの他のサービスの指標と組み合わせることができます。
Monitoring も Cloud Monitoring UI で同じ Dataflow 指標が表示されるため、「4 つのゴールデン シグナル」モニタリング フレームワークを適用することにより、指標を利用してデータ パイプラインのダッシュボードを構築できます。Monitoring においてはパイプライン全体をモニタリング対象の「サービス」として扱えます。それでは、各ゴールデン シグナルについて見ていきましょう。
レイテンシ
レイテンシは一定期間でリクエストを処理するのにかかる時間を表します。レイテンシを測定する方法としては、リクエストの処理に必要な秒単位の時間が一般的です。使用しているサンプル アーキテクチャでは、レイテンシの理解に役立つ指標は、データが Dataflow や、Dataflow パイプラインの個々のステップを通過するのにかかる時間になります。
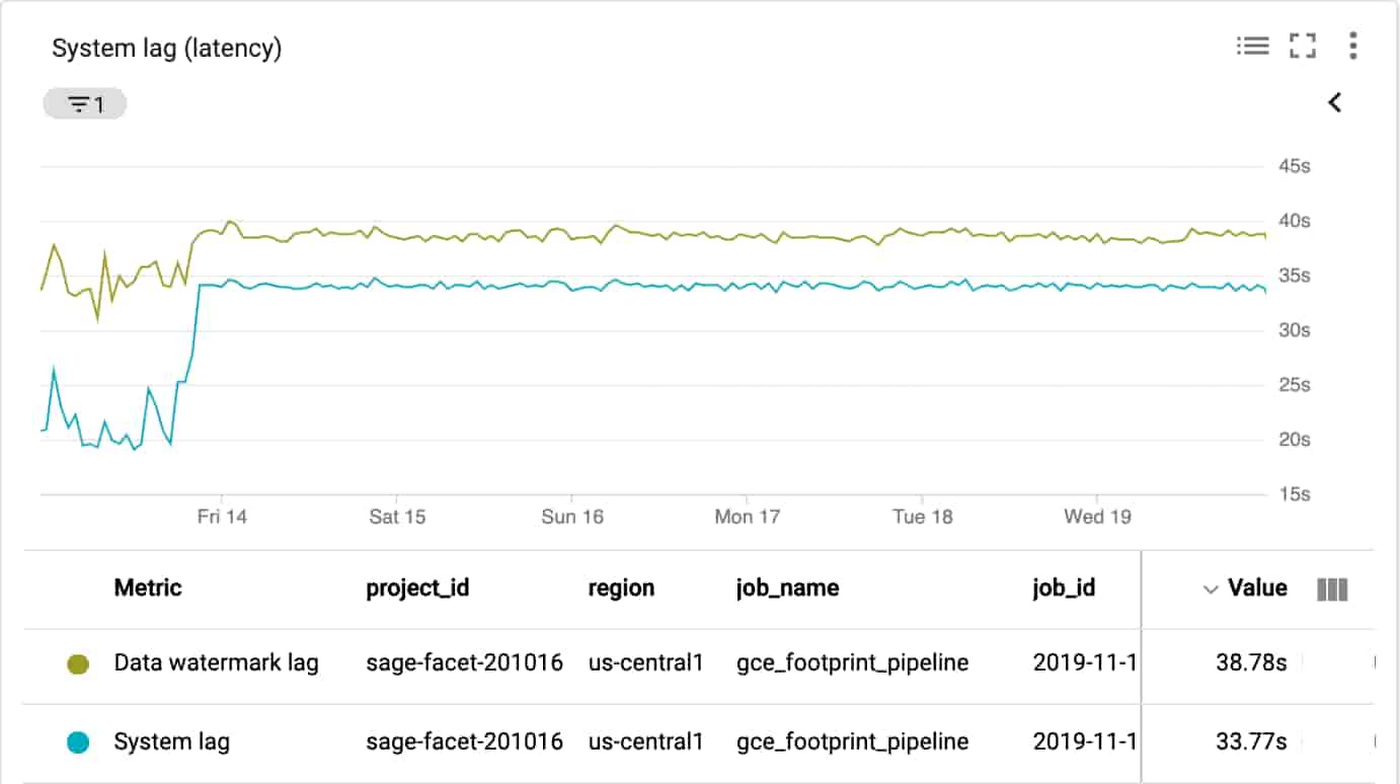
システムラグ チャート
処理時間と遅延領域に関連する指標はリクエストの処理にかかる時間を表すため、その使用は合理的な選択です。job/data_watermark_age はパイプラインで完全に処理された最新のデータアイテムの経過時間(イベントのタイムスタンプからの時間)を表します。job/system_lag はデータアイテムが処理を待っている現在の最大経過時間(秒単位)を表します。この 2 つは次に示すように Dataflow パイプラインを使用した処理にかかる時間の測定と整合します。
トラフィック
一般にトラフィックは、一定期間に受信されたユーザー リクエストの数を表します。トラフィックを測定する方法としては、1 秒あたりのリクエスト処理数が一般的です。サンプルのデータ パイプラインには、受信されるトラフィックに関する分析情報を提供できる主要なサービスが 3 つあります。この例では、データ処理パイプライン アーキテクチャの 3 つのテクノロジー(Pub/Sub、Dataflow、BigQuery)について 3 種類のチャートを作成して読みやすくしました。各指標で Y 軸のスケールの桁が異なるためです。チャートを 1 つにまとめて単純にすることもできます。
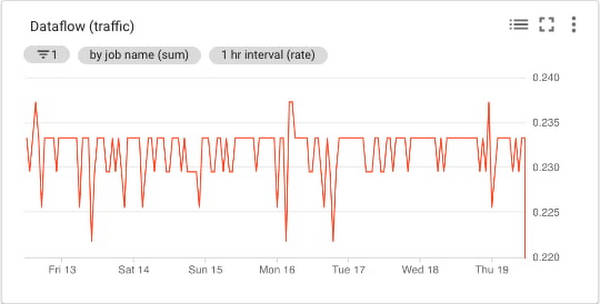
Dataflow トラフィック チャート
Cloud Monitoring は Cloud Dataflow のさまざまな指標を提供します。各指標については、指標のドキュメントをご覧ください。指標は job/status や job/total_vcpu_time などの Dataflow ジョブ全体の指標と、job/element_count や job/estimated_byte_count などの処理指標に分類されます。
Dataflow を介してトラフィックをモニタリングするためには、job/element_count がこれまでに PCollection に追加された要素数を表しており、トラフィック量の測定と整合します。重要なのは、トラフィック量の増加につれてこの指標の値が増えることです。そのため、パイプラインに生じるトラフィックの把握に使用できる合理的な指標になります。
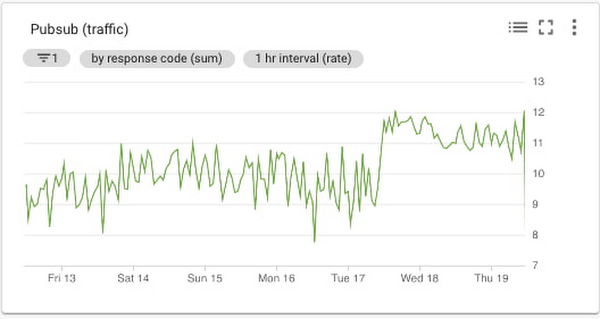
Pub/Sub トラフィック チャート
Pub/Sub 向けの Cloud Monitoring 指標はトピック、サブスクリプション、スナップショットの各指標に分類されます。この指標は受信トラフィックの量を表すため、データを受信するインバウンド トピックに使用するのは合理的な選択です。topic/send_request_count は結果別にグループ化したパブリッシュ リクエストの累積数を表し、次に示すようにトラフィック量の測定と整合します。
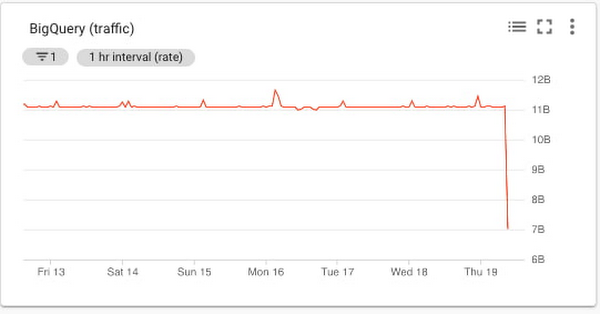
BigQuery トラフィック チャート
BigQuery 向けの Cloud Monitoring 指標は bigquery_project、bigquery_dataset、クエリの各指標に分類されます。アップロードされたデータに関連する指標は受信トラフィックの量を表すため、合理的な選択です。storage/uploaded_bytes は、次のように BigQuery への受信トラフィックの測定と整合します。
エラー
エラーはアプリケーション エラー、インフラストラクチャ エラー、障害発生率を表します。エラー率の増加をモニタリングすることで、パイプラインのログに記録されたエラーが飽和などのエラー状態に関連しているかどうかを把握できます。
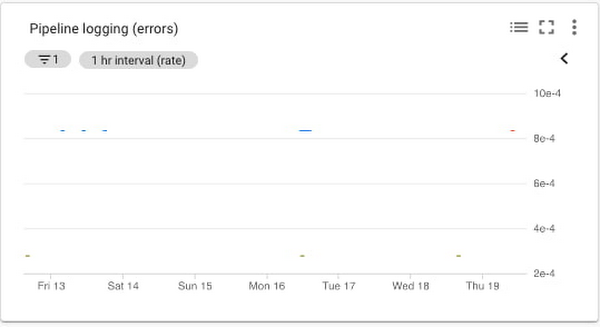
データ処理パイプラインのエラーチャート
Cloud Monitoring は、サービスのログに記録されるエラーを報告する指標を提供します。指標をフィルタリングし、使用している特定のサービスに限定できます。具体的にはエラーの数とエラー率をモニタリングします。log_entry_count は 3 つのサービスごとのログエントリ数を表し、次のチャートで示すようにエラー数の増加の測定と整合します。
飽和度
飽和度はサービスを実行するリソースの使用率を表します。飽和度をモニタリングし、システムがリソースの制約を受ける可能性がある時期を確認する必要があります。このサンプル パイプラインでは、飽和度の把握に役立つ指標は最も古い確認応答されていないメッセージです(処理が遅くなると、メッセージは Pub/Sub により長く残ります)。Dataflow では、データのウォーターマークの経過時間です(処理が遅くなると、メッセージがパイプラインを通過するのに時間がかかります)。
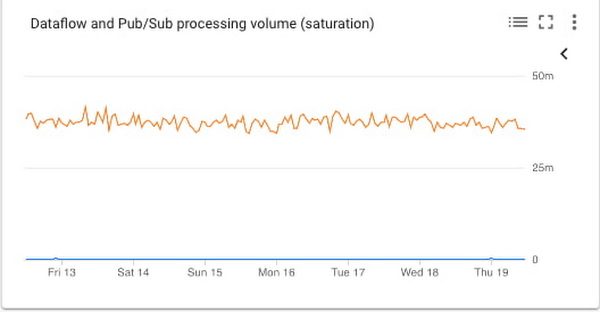
飽和度チャート
システムが飽和状態になるとリソースのフル使用に近づくので、1 件のメッセージを処理する時間は減少します。指標 job/data_watermark_age は上で説明したとおりです。topic/oldest_unacked_message_age_by_region はトピック内で最も古い確認応答されていないメッセージの経過時間(秒単位)を表します。この 2 つは次のように、Dataflow 処理時間の増加や、パイプラインが Pub/Sub からの入力メッセージを受信および確認応答する時間の増加についての測定と整合します。
ダッシュボードを構築する
各種チャートを 1 つのダッシュボードにすべてまとめると、次のようにデータ処理パイプライン指標の単一ビューが得られます。
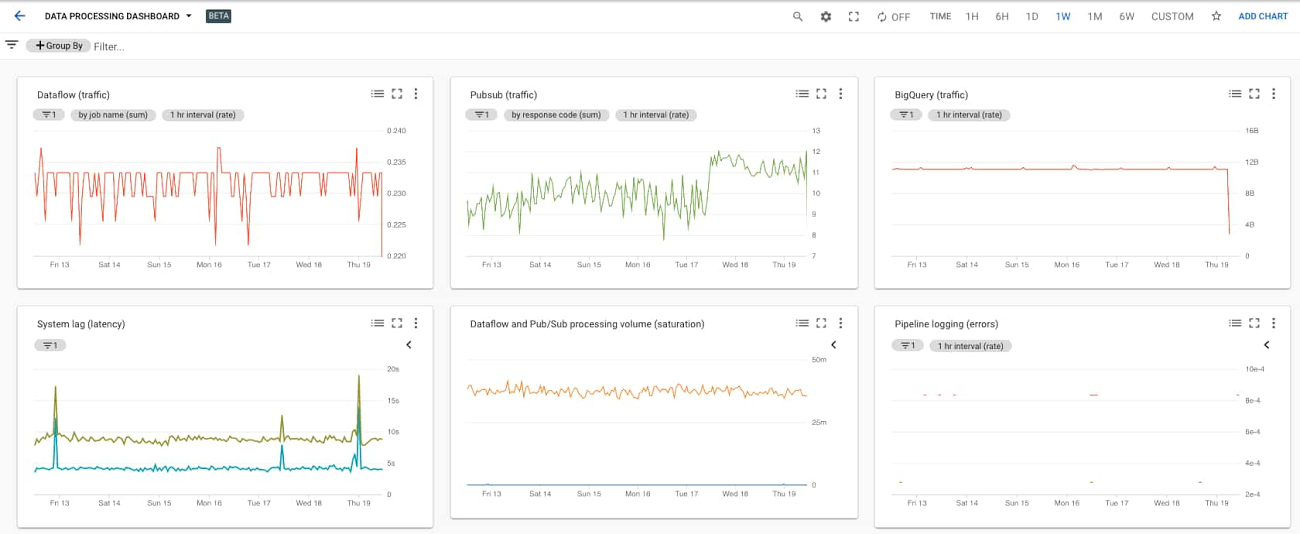
このダッシュボードは、Cloud Monitoring コンソールの [ダッシュボード] セクションで上記の指標を利用すれば、こうした 6 つのチャートを使って簡単に手動で構築できますが、DEV、QA、PROD など複数のワークスペースにダッシュボードを構築することは、さまざまな手作業を繰り返すことになります。これを SRE チームでは「トイル」と呼んでいます。より優れたアプローチとしては、1 つのダッシュボード テンプレートを使用してプログラムでダッシュボードを作成することが挙げられます。また、Stackdriver Cloud Monitoring Dashboards API を使ってサンプル ダッシュボードをテンプレートからデプロイすることもできます。
SRE と CRE の詳細
SRE について詳しくは、SRE の基礎が学べるこちらの記事、または SRE の書籍をご覧ください。CRE ライフレッスン ブログシリーズで、顧客信頼性エンジニアリング(CRE)の実践経験についてお読みください。
- By Google Cloud ソリューション アーキテクト Charles Baer



