SRE fundamentals: SLIs, SLAs and SLOs
Jay Judkowitz
Senior Product Manager
Mark Carter
Group Product Manager
Editor's note: We've written an expanded and updated version of this post. Find it here: SRE fundamentals 2021: SLIs vs SLAs vs SLOs.
Next week at Google Cloud Next ‘18, you’ll be hearing about new ways to think about and ensure the availability of your applications. A big part of that is establishing and monitoring service-level metrics—something that our Site Reliability Engineering (SRE) team does day in and day out here at Google. Our SRE principles have as their end goal to improve services and in turn the user experience, and next week we’ll be discussing some new ways you can incorporate SRE principles into your operations.
To learn more about applying SRE in your business, we invite you to join Ben Treynor, head of Google SRE, who will be sharing some exciting announcements and walking through real-life SRE scenarios at his Next ‘18 Spotlight session. Register now as seats are limited.
The concept of SRE starts with the idea that metrics should be closely tied to business objectives. We use several essential tools—SLO, SLA and SLI—in SRE planning and practice.
Defining the terms of site reliability engineering
These tools aren’t just useful abstractions. Without them, you cannot know if your system is reliable, available or even useful. If they don’t tie explicitly back to your business objectives, then you don’t have data on whether the choices you make are helping or hurting your business.As a refresher, here’s a look at SLOs, SLAs, and SLIS, as discussed by AJ Ross, Adrian Hilton and Dave Rensin of our Customer Reliability Engineering team, in the January 2017 blog post, SLOs, SLIs, SLAs, oh my - CRE life lessons.
1. Service-Level Objective (SLO)
SRE begins with the idea that a prerequisite to success is availability. A system that is unavailable cannot perform its function and will fail by default. Availability, in SRE terms, defines whether a system is able to fulfill its intended function at a point in time. In addition to being used as a reporting tool, the historical availability measurement can also describe the probability that your system will perform as expected in the future.
When we set out to define the terms of SRE, we wanted to set a precise numerical target for system availability. We term this target the availability Service-Level Objective (SLO) of our system. Any discussion we have in the future about whether the system is running sufficiently reliably and what design or architectural changes we should make to it must be framed in terms of our system continuing to meet this SLO.
Keep in mind that the more reliable the service, the more it costs to operate. Define the lowest level of reliability that you can get away with for each service, and state that as your SLO. Every service should have an availability SLO—without it, your team and your stakeholders cannot make principled judgments about whether your service needs to be made more reliable (increasing cost and slowing development) or less reliable (allowing greater velocity of development). Excessive availability can become a problem because now it’s the expectation. Don’t make your system overly reliable if you don’t intend to commit to it to being that reliable.
Within Google, we implement periodic downtime in some services to prevent a service from being overly available. You might also try experimenting with planned-downtime exercises with front-end servers occasionally, as we did with one of our internal systems. We found that these exercises can uncover services that are using those servers inappropriately. With that information, you can then move workloads to somewhere more suitable and keep servers at the right availability level.
2. Service-Level Agreement (SLA)
At Google, we distinguish between an SLO and a Service-Level Agreement (SLA). An SLA normally involves a promise to someone using your service that its availability SLO should meet a certain level over a certain period, and if it fails to do so then some kind of penalty will be paid. This might be a partial refund of the service subscription fee paid by customers for that period, or additional subscription time added for free. The concept is that going out of SLO is going to hurt the service team, so they will push hard to stay within SLO. If you’re charging your customers money, you will probably need an SLA.
Because of this, and because of the principle that availability shouldn’t be much better than the SLO, the availability SLO in the SLA is normally a looser objective than the internal availability SLO. This might be expressed in availability numbers: for instance, an availability SLO of 99.9% over one month, with an internal availability SLO of 99.95%. Alternatively, the SLA might only specify a subset of the metrics that make up the internal SLO.
If you have an SLO in your SLA that is different from your internal SLO, as it almost always is, it’s important for your monitoring to measure SLO compliance explicitly. You want to be able to view your system’s availability over the SLA calendar period, and easily see if it appears to be in danger of going out of SLO. You will also need a precise measurement of compliance, usually from logs analysis. Since we have an extra set of obligations (described in the SLA) to paying customers, we need to measure queries received from them separately from other queries. That’s another benefit of establishing an SLA—it’s an unambiguous way to prioritize traffic.
When you define your SLA’s availability SLO, you need to be extra-careful about which queries you count as legitimate. For example, if a customer goes over quota because they released a buggy version of their mobile client, you may consider excluding all “out of quota” response codes from your SLA accounting.
3. Service-Level Indicator (SLI)
We also have a direct measurement of a service’s behavior: the frequency of successful probes of our system. This is a Service-Level Indicator (SLI). When we evaluate whether our system has been running within SLO for the past week, we look at the SLI to get the service availability percentage. If it goes below the specified SLO, we have a problem and may need to make the system more available in some way, such as running a second instance of the service in a different city and load-balancing between the two. If you want to know how reliable your service is, you must be able to measure the rates of successful and unsuccessful queries as your SLIs.
Since the original post was published, we’ve made some updates to Stackdriver that let you incorporate SLIs even more easily into your Google Cloud Platform (GCP) workflows. You can now combine your in-house SLIs with the SLIs of the GCP services that you use, all in the same Stackdriver monitoring dashboard. At Next ‘18, the Spotlight session with Ben Treynor and Snapchat will illustrate how Snap uses its dashboard to get insight into what matters to its customers and map it directly to what information it gets from GCP, for an in-depth view of customer experience.
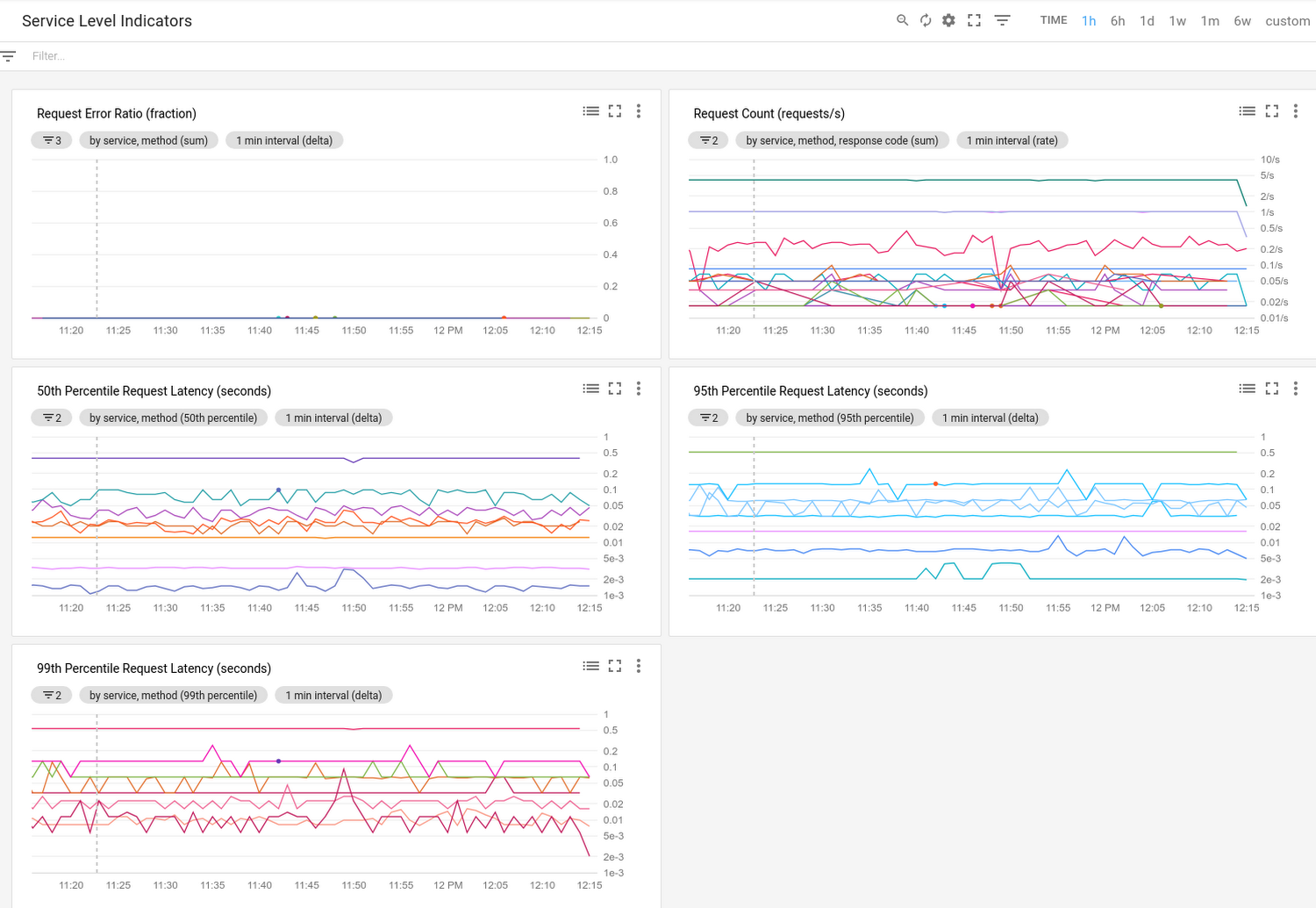
If you’re building a system from scratch, make sure that SLIs and SLOs are part of your system requirements. If you already have a production system but don’t have them clearly defined, then that’s your highest priority work. If you’re coming to Next ‘18, we look forward to seeing you there.
See related content
- We wrote the book on SRE—check it out.
- Read about SLOs for services with dependencies.
- Learn about CRE best practices.




