映画の観客動員を機械学習で予測する 20th Century Fox

Google Cloud Japan Team
※この投稿は米国時間 2018 年 10 月 30 日に Google Cloud blog に投稿されたものの抄訳です。
映画産業での成功は映画製作会社が観客を魅了できるかどうかにかかっていますが、それは口で言うほど簡単ではありません。観客は多様な集団であり、その興味や嗜好は多岐にわたります。従来、製作会社は脚本に投資するかどうかを経験を頼りに判断してきましたが、そのやり方は特に新しい独創的な作品を世に問う場合に高いリスクを伴います。
20th Century Fox の社長でチーフ データ ストラテジスト兼メディア責任者でもある Julie Rieger 氏と、データ サイエンス担当 SVP の Miguel Campo-Rembado 氏は、社内のデータ サイエンティスト チームと協力し、ストーリーと観客のマッチングという反復的で複雑なプロセスの精度をデータの力で高めようと考えました。
機械学習に適した問題
観客のマーケット セグメンテーションを把握することは映画製作会社の重要な仕事の 1 つです。製作会社は、観客セグメントを詳細に調べて映画の成否を予測することに役立てるため、長年にわたって高度なデータ処理に投資してきました。しかし、これまでは技術的および制度的な障壁が理由で、観客個人のレベルだけでなくセグメント レベルでも、細かい粒度での予測には対応できていませんでした。Miguel 氏と彼のチームは、Google Cloud のようなパートナーと協力して、こうした障壁のいくつかを取り除いてきました。私たちは、映画の観客に対する理解を深めるため、プライバシー保護を強化したデータ パートナーシップを構築しました。そして、さまざまなタイプの映画に対する観客の嗜好の基本的なパターンを特定することを目的に、粒度の細かい観客データや脚本を基に社内専用のディープ ラーニング モデルを開発したのです。このモデルは、ビジネス上の重要な決定の際の判断材料として 18 か月前から日常的に利用され、映画のトーン、コアな観客層とその延長線上の観客層への親和性、興行成績の可能性に関する最も客観的で効果的、かつデータドリブンなバロメーターの 1 つになっています。
それでは、実際の方法を詳しく説明しましょう。映画の場合、脚本に書かれたテキストを分析しても、それはストーリーの骨組みにすぎず、観客の足を映画館に向けさせるような付加的なダイナミズムに欠けています。そこでチームは、映画の集客キャンペーンを展開するうえで重要な材料となる予告編を、最新の高度なコンピュータ ビジョンを使って学習する方法はないかと考えました。新作映画にとって予告編を公開することは一大イベントであり、映画の成功を予測することにも役立つからです。
20th Century Fox のデータ サイエンス チームは、狙いどおりの関心を観客から集めるような予告編を作ることを目標に、Google の Advanced Solutions Lab(ASL)と協力して Merlin Video を作りました。Merlin Video は、映画の観客動員を予告編から予測することに役立つ、予告編のベクトル表現を学習するコンピュータ ビジョン ツールです。
データ パイプラインの設計
チームの最初の仕事は、このツールを支えるテクノロジーを選択することでしたが、ディープ ラーニング フレームワークである TensorFlow と、Cloud Machine Learning Engine(Cloud ML Engine)を組み合わせることに疑問の余地はありませんでした。Cloud ML Engine はマネージド サービスであり、リソースのプロビジョニングやモニタリングは自動化されるため、チームはインフラストラクチャの調整ではなく、Merlin のディープ ラーニング モデル構築に力を注ぐことができたのです。また、Cloud Dataflow との統合によって Data Studio でのシームレスなレポート作成が可能になり、チームはプロセスの動きを深く理解できるようになりました。システムの日々のメンテナンス(主としてデータの取り込み)は単純かつ簡単で、他部門のエンジニアの助けを借りることなく、データ サイエンティスト自身で処理することができます。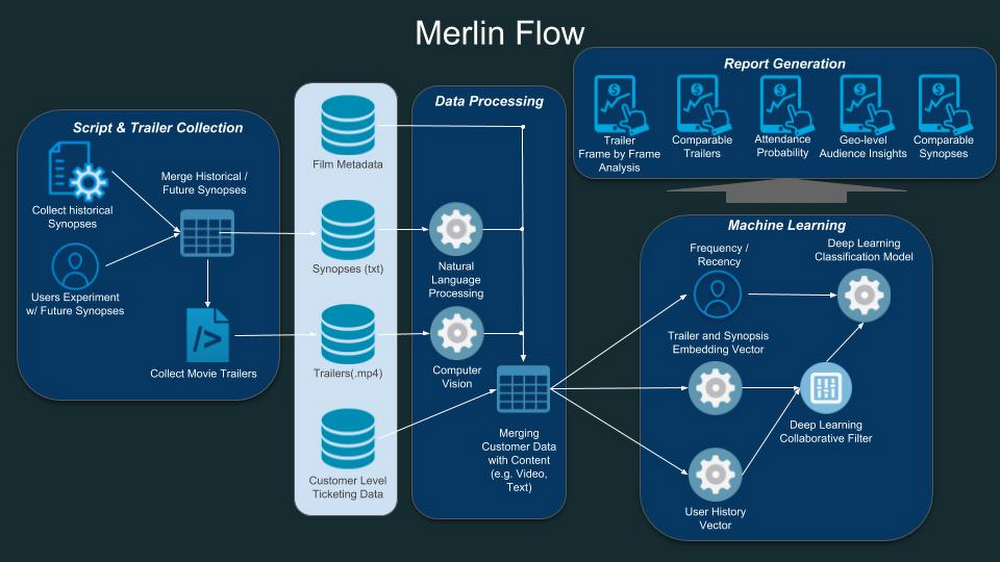
適切なインフラストラクチャの準備を終えたチームは、YouTube 動画の公開データセットである YouTube-8M の分析に取りかかりました。このデータセットには、色、照明、さまざまなタイプの顔、数千ものオブジェクト、複数の風景を分析できる Google 製作の事前訓練モデルが含まれています。上図からもわかるように、Merlin のアーキテクチャにおける最初のステップは、予告編のどの要素が観客の嗜好の予測に最も役立つかを知るための前段として、これらの事前に学習された特性を読み取ることです。
実際の予告編を例に説明しましょう。男性のアクション俳優が主役を務める映画を見たことがある人は、男性のアクション俳優が主役の別の映画を見に行く可能性が高いと言えるのでしょうか。Wolverine 役として Hugh Jackman を起用した 20th Century Fox の映画『Logan』(邦題 : ローガン)を詳しく見てみます。次の画面は公式予告編の 12 秒目のスナップショットです。

Merlin はこのスナップショットに対して、facial_hair(顔ひげ)、beard(顎ひげ)、screenshot、chin(顎)、human、film というラベルを返します。そして、予告編全体を秒刻みで分析し、『Logan』における上位頻出ラベルとして次の結果を出力します。
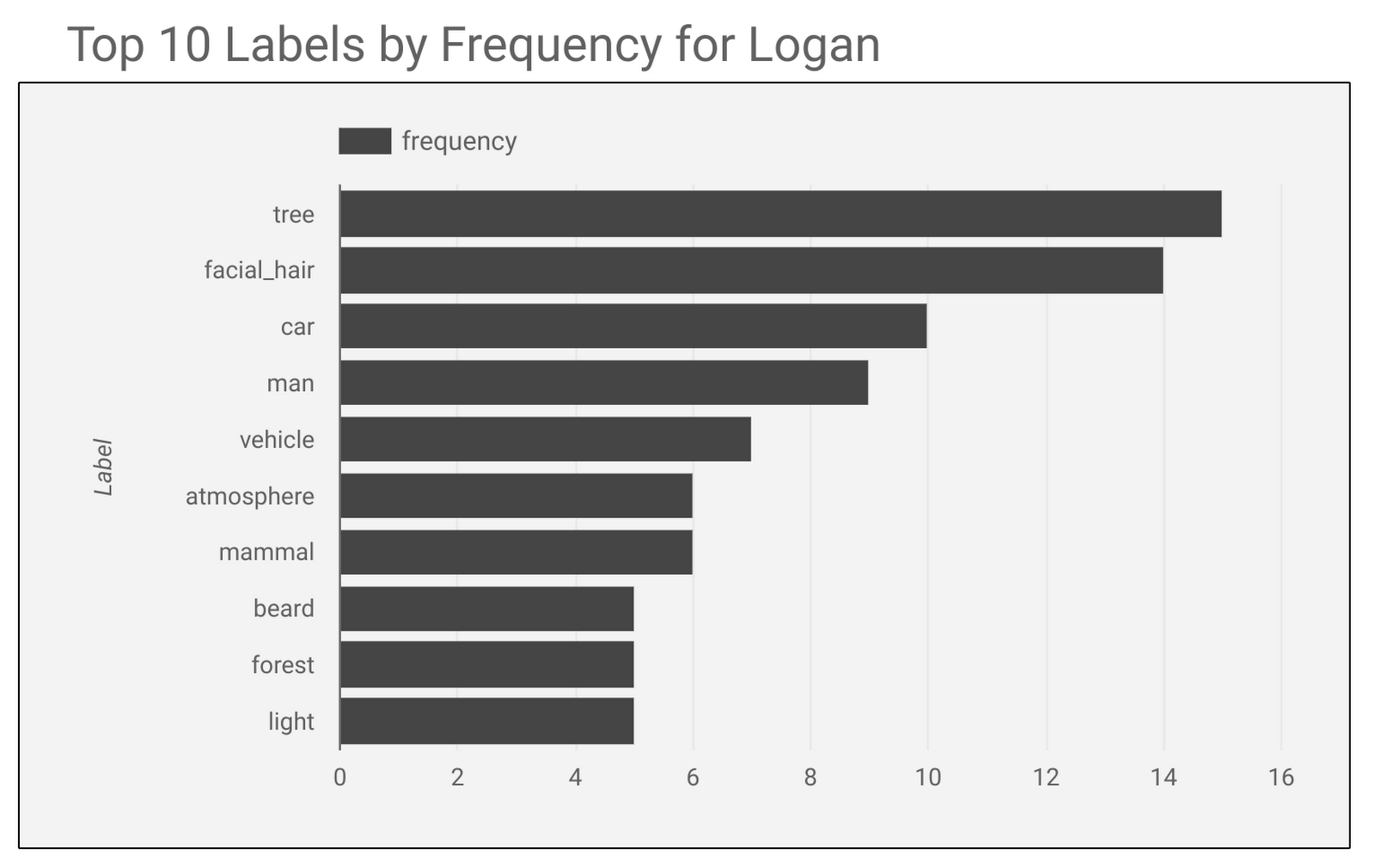
『Logan』のラベル分析を行った 20th Century Fox チームは、この新しいラベル分析と、過去の映画の予告編から得られたラベルを比較し、類似の映画を割り出すことにしました。『Logan』の観客とほかのアクション映画の観客には重なりがあると考えたからです。しかし、このような比較には二重の難しさがあります。
1 つは、予告編におけるラベルの時間的な位置です。ラベルが予告編のどこで出現するかは重要です。そしてもう 1 つは、このデータの次元の高さです。どの映画の予告編にも観客の興味を予測できる要素が無数にありますが、Merlin はこれらをすべて同時に分析しようとします。データ サイエンス チームは、Cloud ML Engine の柔軟性のおかげで、ディープ ラーニング モデルの能力を損なうことなくイテレーションとテストをすばやく行うことができました。Merlin は、数か月や数年ではなく数日で、本番の作業に対応できるツールへと進化したのです。
その仕組みを具体的に説明しましょう。分析パイプラインは、データ サイエンス チームが開発したカスタム ニューラル ネットワークに個々のコンポーネント(ラベル)を送ります。このカスタム モデルは、予告編内でのラベルの時間的シーケンスを学習します。時間的シーケンス(たとえば、ロングショットか、断続的な短いショットか)は、映画のタイプ、プロット、主人公の役柄、製作者の映画的な選択といった情報を反映しています。シーケンス分析に観客の履歴データを組み合わせれば、観客の行動予測を作成できます。
分析パイプラインには、距離に基づいた協調フィルタリング(Collaborative Filtering)モデルや、すべてのモデルの出力を 1 つにまとめて観客動員率を計算するロジスティック回帰レイヤも含まれています。このモデルは エンドツーエンドで訓練され、ロジスティック回帰の損失はすべての訓練可能なコンポーネント(重み)に逆伝播されます。Merlin のデータ パイプラインは、新しい予告編のリリースのために毎週リフレッシュされます。パイプラインの構造は次の図のとおりです。
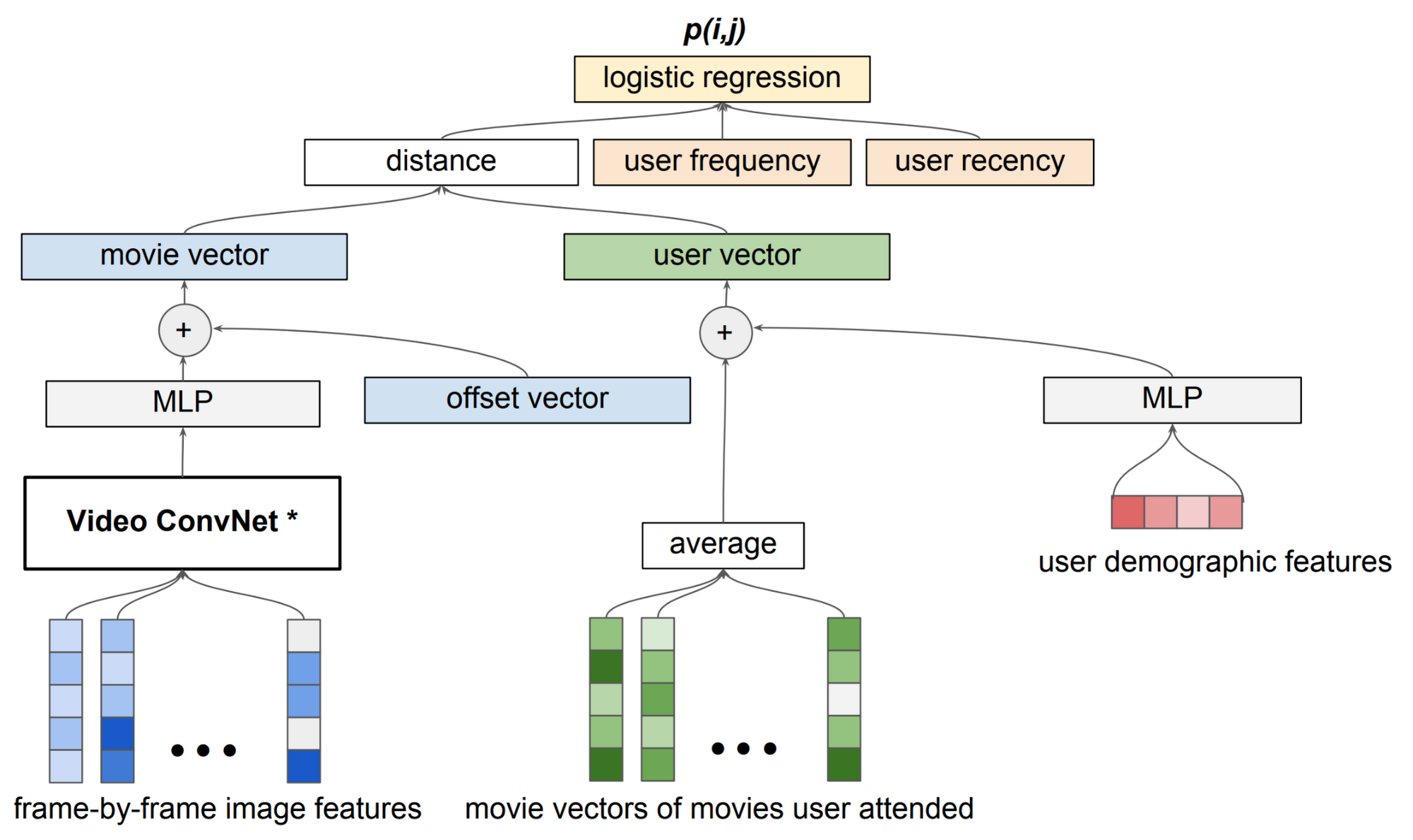
最後のステップでは BigQuery と BigQuery ML を使用します。Merlin による数百万もの観客予測とその他のデータ ソースを組み合わせ、有用なレポートや、宣伝キャンペーンに向けたメディア プランのプロトタイプを作ります。
モデルの妥当性確認
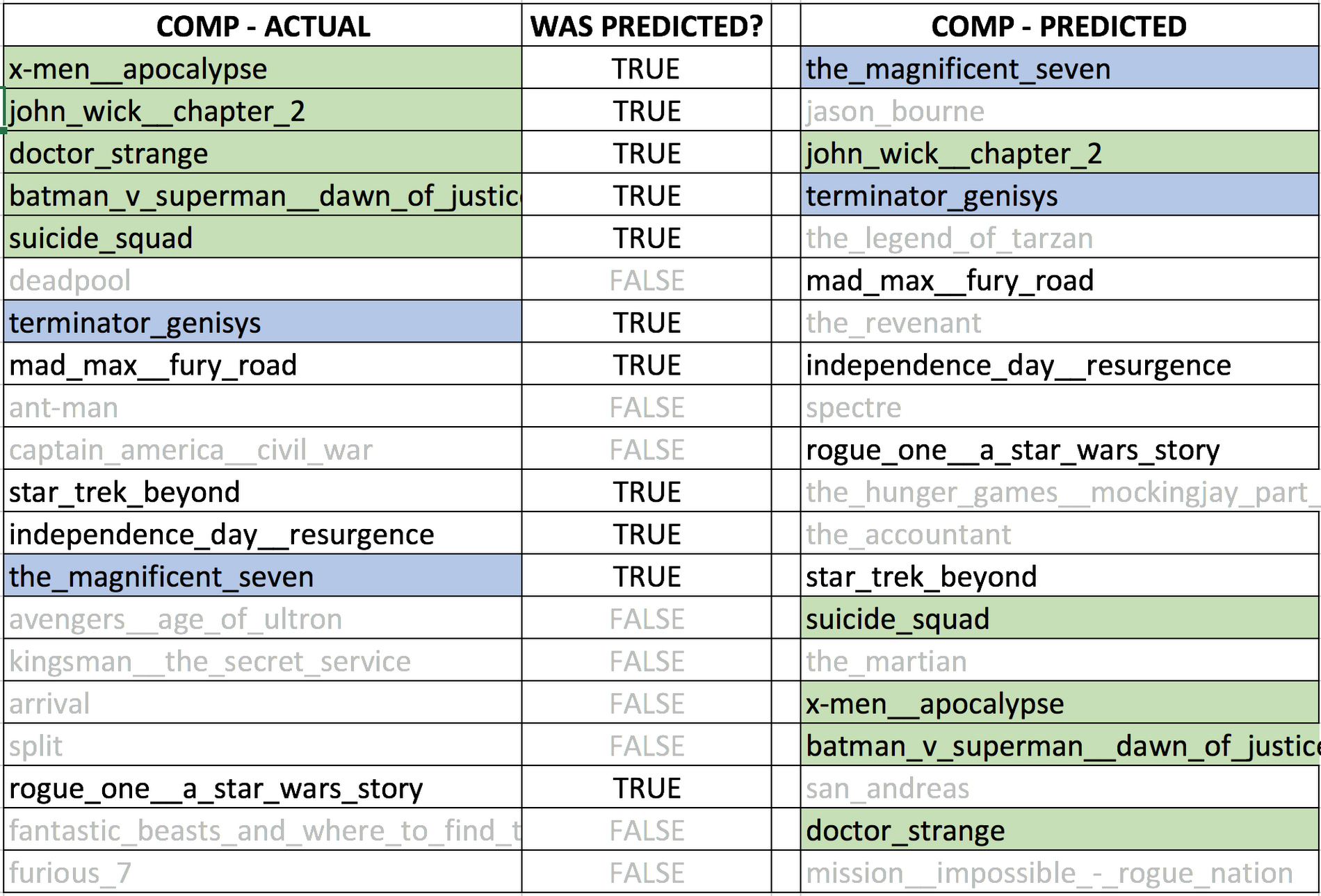
それでは『Logan』の例に戻って、「“ごつい” 男性が主役のアクション映画を過去に見たことがある観客は『Logan』も見るだろう」という私たちの直観にデータの裏付けが得られたかどうかを確認してみましょう。映画公開後には、実際の観客が過去に見た映画についてのデータを処理できるので、それを使用します。下表は、実際の観客が見た映画の上位 20 作品(COMP-ACTUAL)と、予測した観客が見た上位 20 作品(COMP-PREDICTED)を比較したものです。COMP-ACTUAL の上位 5 作品(緑)が COMP-PREDICTED に含まれているかどうかに注目してみると、上位 5 作品はすべて含まれていることがわかります。
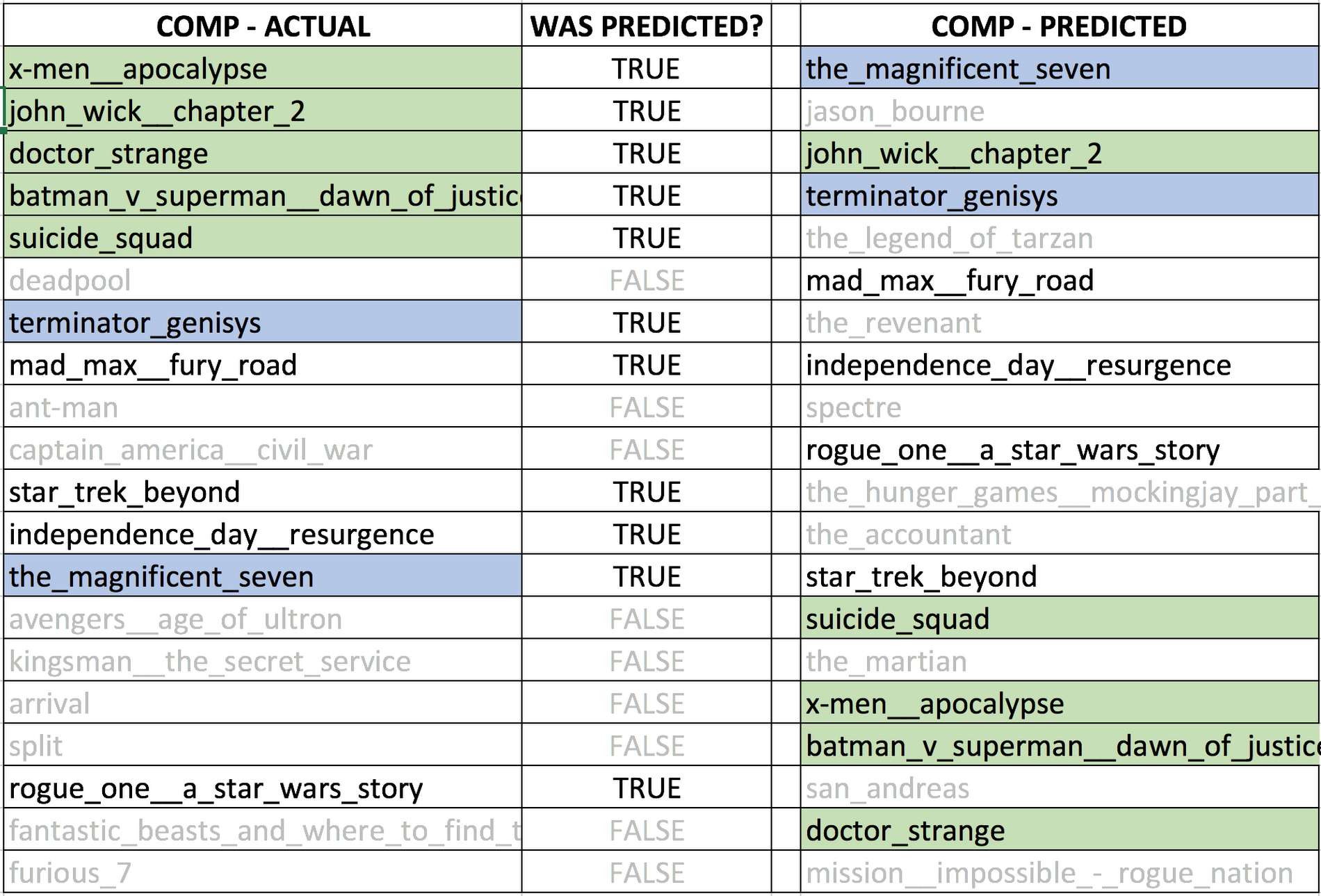
この表を見る限り、私たちの直観は正しかったと言えます。『Logan』を見た観客の主流は、スーパーヒーローを求める人(事前にわかっていたこと)と、「ごつい男性アクション俳優」の映画を求める人(はっきりとわかっていなかったこと)の組み合わせでした。このことは、「ごつい男性アクション俳優」が鍵となって COMP-PREDICTED の上位にランクインした『The Magnificent Seven』(邦題 : マグニフィセント・セブン、上表では青)、『John Wick: Chapter 2』(邦題 : ジョン・ウィック: チャプター 2、同緑)、『Terminator Genisys』(邦題 : ターミネーター: 新起動/ジェニシス、同青)といった作品が COMP-ACTUAL に含まれていることからもよくわかります。この結果は、スーパーヒーローを求めるコアな観客に新しい観客が加わり、コアな観客を超えて映画のリーチを広げるために使用される可能性が開けてきたことを示しています。
これらのツールが 20th Century Fox のマーケティングやデータ チームに与えた影響は絶大です。観客の調査結果だけに頼るのではなく、より精度の高い方法で観客の意向を探れるようになったからです。得られるインサイトは、従来のアナリティクスに比べて少なくとも 2 桁分は詳細な分析を可能とします。同社は、2017 年に公開された『The Greatest Showman』(邦題 : グレイテスト・ショーマン)からこのツールを使用しており、今も最新映画の情報提供に活用しています。また、観客のセグメントと彼らが見る作品との間に強い相関関係があるかどうかを把握するため、DVD などの購入データやレンタル データについても組み込もうとしているところです。
さらに、データの粒度がより細かくなったことから、チケット売り場での実際の販売実績を基に社内予測を評価し、どのセグメント レベルの予測が正しかったかを判定することも可能になりました。Miguel 氏のデータ サイエンス チームは、今では毎週月曜の朝にスコアカードを作り、社内の他部門にメールで提供しています。
Merlin の基礎に関する研究についてもっと知りたい方は、こちらからオリジナルの論文をダウンロードしてください。

- By Miguel Campo-Rembado, SVP of Data Science, 20th Century Fox and Sona Oakley, Solutions Architect, Google Cloud



