How 20th Century Fox uses ML to predict a movie audience

Miguel Campo-Rembado
SVP of Data Science, 20th Century Fox
Sona Oakley
Solutions Architect, Google Cloud
Success in the movie industry relies on a studio’s ability to attract moviegoers—but that’s sometimes easier said than done. Moviegoers are a diverse group, with a wide variety of interests and preferences. Historically, movie studios have relied heavily on experience when deciding to invest in a particular script—but this can lead to huge risks, particularly when investing in new, original stories. The iterative and complex process of matching stories and audiences is something that Julie Rieger, President, Chief Data Strategist and Head of Media, and Miguel Campo-Rembado, SVP of Data Science, together with their team of data scientists at 20th Century Fox, decided to clarify with data.
A data challenge suited to Machine Learning
Understanding the market segmentation of the movie-going public is a core function of movie studios. Over the years, studios have invested in high-level data processes to try to map out customer segments, and to make predictions for future films. However, to date, granular predictions at the segment level, not to mention at the customer level, have remained elusive because of technological and institutional barriers.
Miguel and his team have been able to lift some of those barriers by working with partners like Google Cloud. Together, we’ve built privacy-robust data partnerships to better understand moviegoers, and have developed in-house deep learning models that train on granular customer data and movie scripts to identify the basic patterns in audiences’ preferences for different types of films. In the span of 18 months, these models have become routine considerations for important business decisions, and provide one of their most objective, data-driven, and effective barometers to evaluate the tone of a movie, its affinity with core and stretch audiences, and its potential financial performance.
Let’s talk about these methods in greater detail. When it comes to movies, analyzing text taken from a script is limiting because it only provides a skeleton of the story, without any of the additional dynamism that can entice an audience to see a movie. The team wondered if there was some way to use modern, advanced computer vision to study movie trailers, which remain the single most central element of a movie’s entire marketing campaign. The trailer release for a new movie is a highly anticipated event that can help predict future success, so it behooves the business to ensure the trailer is hitting the right notes with moviegoers. To achieve this goal, the 20th Century Fox data science team partnered with Google’s Advanced Solutions Lab to create Merlin Video, a computer vision tool that learns dense representations of movie trailers to help predict a specific trailer’s future moviegoing audience.
Designing a data pipeline
The first step the team took was to identify which technology should power this tool. The obvious choice was Cloud Machine Learning Engine (Cloud ML Engine), in conjunction with the TensorFlow deep learning framework. Because it’s a managed service, Cloud ML Engine automates all resource provisioning and monitoring, so the team could focus on building the deep learning model for Merlin, rather than configuring infrastructure. Its integration with Cloud Dataflow also enables seamless report generation in Data Studio, which gave the team a deeper understanding of how the process works. The day-to-day maintenance of the system (data ingest, mostly) is both simple and easy, and can be handled entirely by data scientists, instead of requiring intervention from other business units’ engineers.
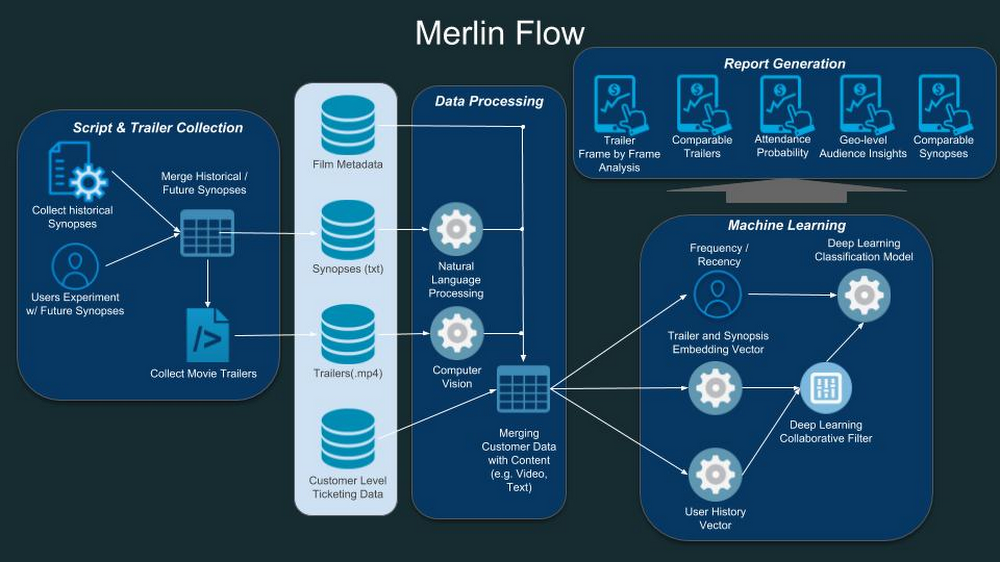
With the right infrastructure in place, the team began its analysis on YouTube 8M, a publicly available dataset of YouTube videos. This dataset includes a pre-trained model from Google that is able to analyze specific video features like color, illumination, many types of faces, thousands of objects, and several landscapes. As seen in the figure above, the first step in Merlin’s architecture is to parse out these predefined characteristics, as a precursor to determining which elements of the trailer are most predictive of moviegoers’ preferences.
For example, if someone has previously seen mostly movies with a male action lead, are they more likely to see another movie with a male action lead? Let’s look in depth at Logan, an action movie released by 20th Century Fox featuring Hugh Jackman as Wolverine. Below you can see a snapshot 12 seconds into the official trailer.

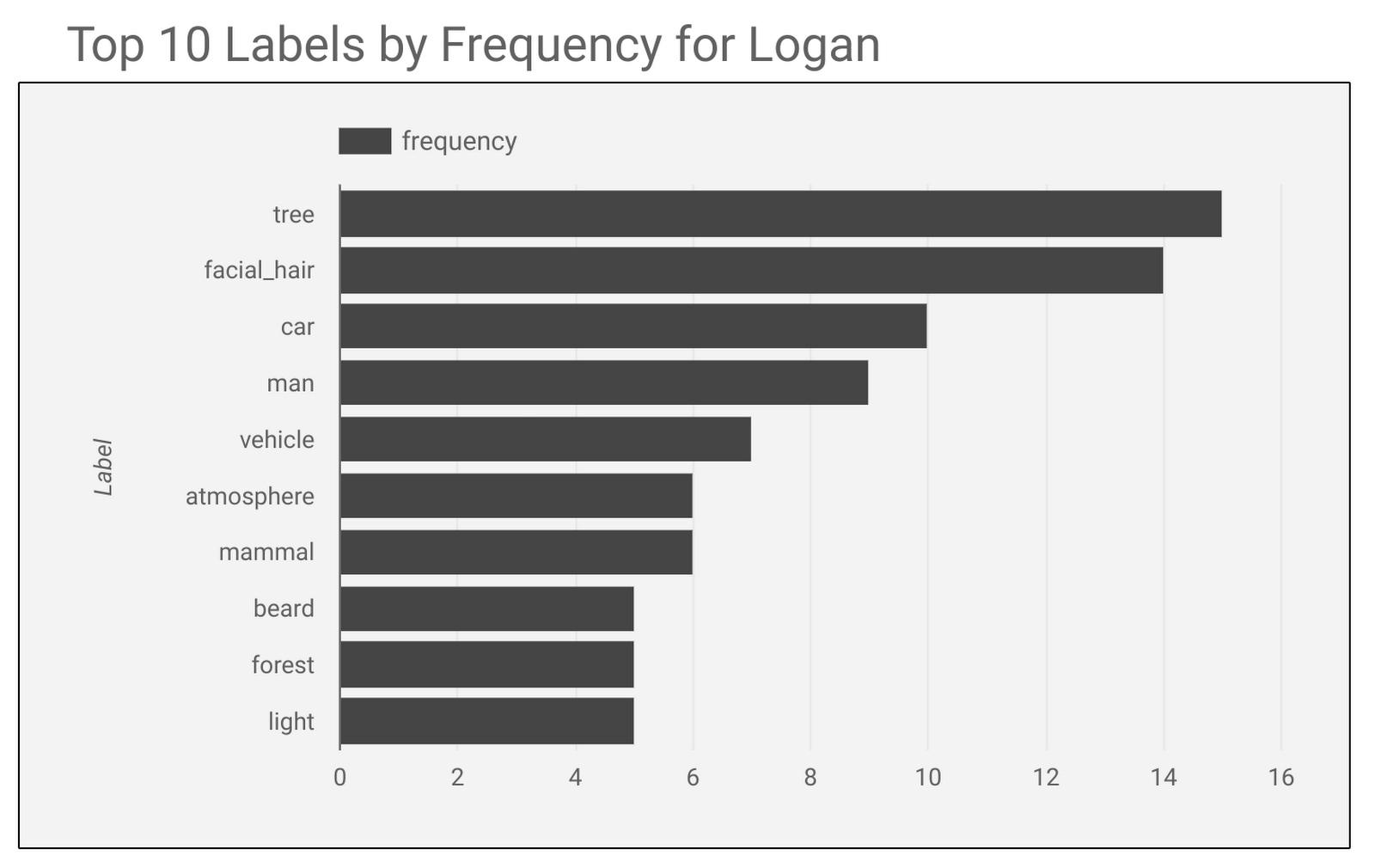
For this snapshot, Merlin returns the following labels: facial_hair, beard, screenshot, chin, human, film. After analyzing the full trailer, second by second, Merlin reveals that the top labels for Logan are as follows:
Once the label analysis of Logan had been assigned, the team at 20th Century Fox wanted to compare that new analysis with the labels previously generated from other film trailers to identify similar movies. Presumably, there is some overlap between the audiences for Logan and other action movies, but the challenge here is twofold. The first challenge is the temporal position of the labels in the trailer: it matters when the labels occur in the trailer. The second challenge is the high dimensionality of this data. For any given movie, there can be numerous elements in the trailer that can predict of audience interest, and Merlin aims to analyze all of these simultaneously. The elasticity of Cloud ML Engine allowed the data science team to iterate and test quickly, without compromising the integrity of the deep learning model. This helped Merlin become a production-ready tool in a matter of days, instead of months or years.
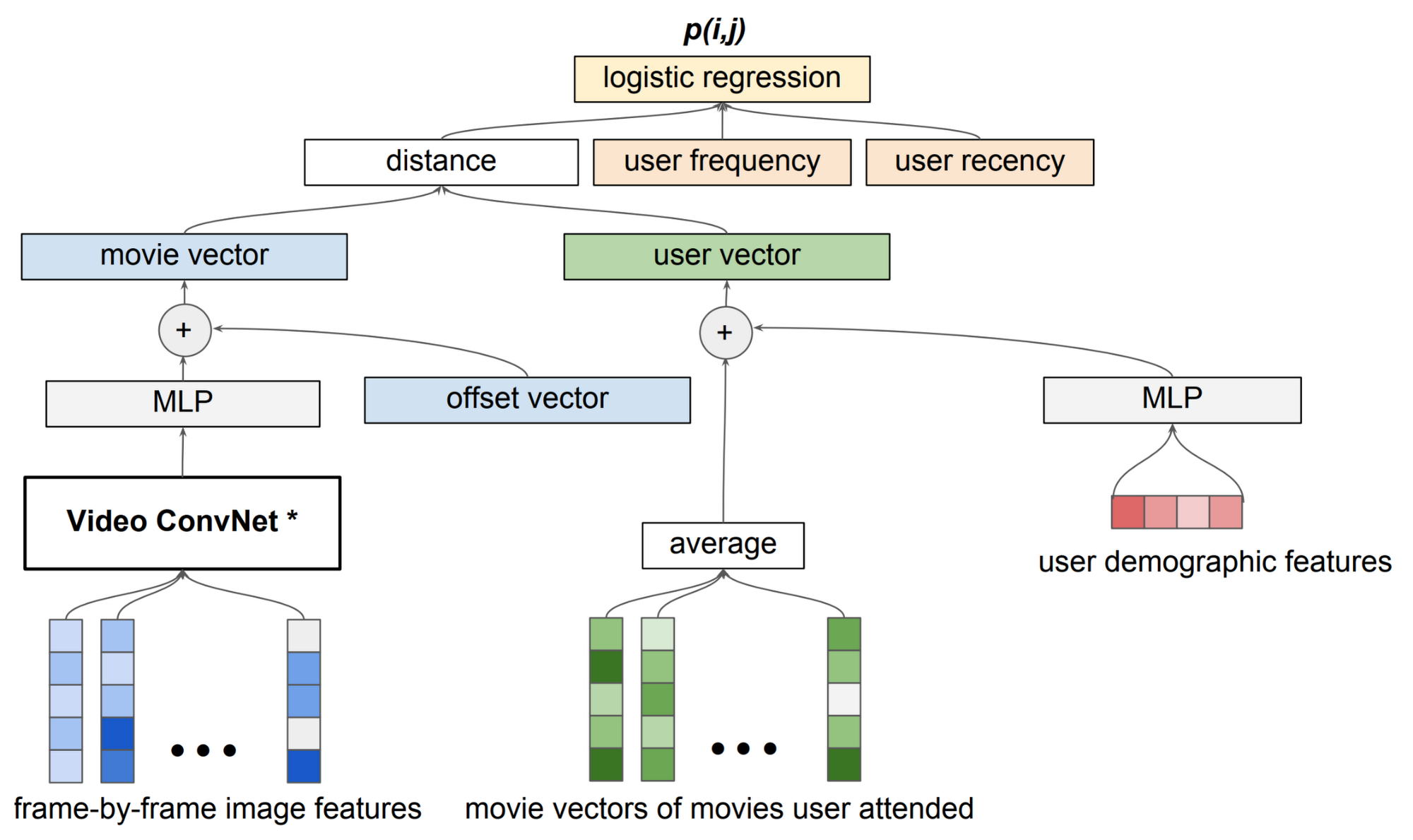
Specifically, the analysis pipeline feeds these individual components (labels) into a custom neural network that the data science team developed. This custom model learns the temporal sequencing of labels in the movie trailer. Temporal sequencing (for example, a long shot of an object versus intermittent short shots) can convey information about the movie type, the movie plot, the roles of the main characters, and the filmmakers’ cinematographic choices. When combined with historical customer data, sequencing analysis can be used to create predictions of customer behavior. The pipeline also includes a distance-based “collaborative filtering” (CF) model and a logistic regression layer that combines all the model outputs together to produce the movie attendance probability. The model is trained end-to-end, and the loss of the logistic regression is back-propagated to all the trainable components (weights). Merlin’s data pipeline is refreshed weekly to account for new trailer releases. The pipeline’s structure is shown in the diagram below:
For a final step, the team uses BigQuery and BigQueryML to merge Merlin’s millions of customer predictions with other data sources to create useful reports and to quickly prototype media plans for marketing campaigns.
Validating the model
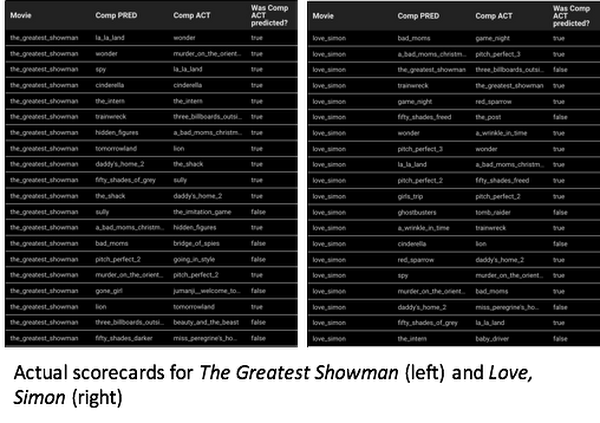
Let’s revisit our Logan example to see if the data corroborates our intuition that moviegoers who have previously seen an action movie with a “rugged” male lead will likely see Logan as well. After a movie’s release, we are able to process the data on which movies were previously seen by that audience. The table below shows the top 20 actual moviegoer audiences (Comp ACT) compared to the top 20 predicted audiences (Comp PRED). Let’s focus on the top 5 actual movies (shown in green below) and see if they also showed up in our prediction column: of the top 5, all of them are represented by the predictions.
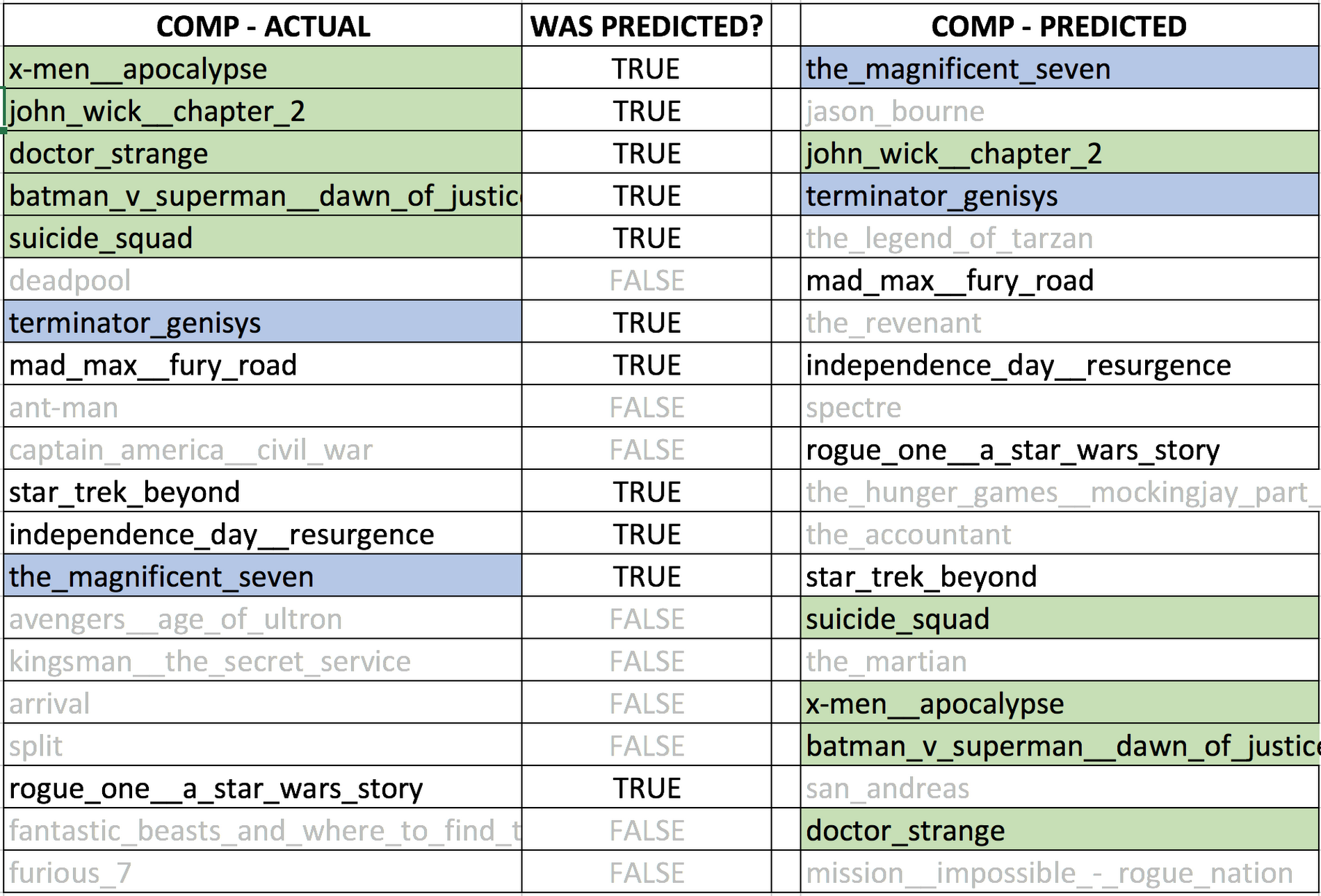
On the surface, our intuition was correct. The top audiences for Logan were actually a combination of superhero (which we already knew) and “rugged male action lead” (which we didn’t know with certainty). This can be better seen by noting that key “rugged male action lead” predictions like The Magnificent Seven (in blue above), John Wick (in green above) and Terminator Genisys (in blue above) were also present in the top 20 list of actual audiences. This result is a win-win because the new audience “adds” to the core superhero audience, and can potentially be used to extend the reach of the movie beyond that core audience.
The impact of these tools on 20th Century Fox’s marketing and data teams is significant. Instead of depending solely on high level audience survey results, the team can now deploy more precise instruments to determine customer intent. The insights are at least two orders of magnitude more detailed than the previous sets of analytics the studio had been relying on. 20th Century Fox has been using this tool since the release of The Greatest Showman in 2017, and continues to use it to inform their latest releases. They’re also now incorporating purchase and rental data from home entertainment sources to identify stronger correlations between an audience member and the titles they’ve watched.
Finally, because the data is more granular, the team can review actual box office performance versus their internal predictions, to see which segment level predictions came true. Miguel’s data science team now creates scorecards every Monday morning, which then get emailed to the rest of the organization.
If you’re interested in learning more about the research underlying Merlin, you can find the original research paper here.




