Slurm で GCP 上に HPC クラスタを構築
Google Cloud Japan Team
ハイパフォーマンスのテクニカル コンピューティングはスケーラビリティとスピードがすべてです。創薬とゲノミクス、金融サービス、画像処理などの分野のアプリケーションは、その多くが大量かつ多様な計算リソースへのオンデマンド アクセスを必要とします。計算能力が大きく高速になれば、アイデアを発見に変え、仮説を治療法に生かし、ひらめきを製品に反映させることができます。
Google Cloud は、大量のハイパフォーマンス リソースへのオンデマンド アクセスを、Compute Engine を通じて HPC(High Performance Computing)コミュニティに提供しています。しかし、これらの強力なリソースを活用して HPC ジョブをすばやく実行し、既存の HPC クラスタを Compute Engine でシームレスに拡張する方法については、まだ課題が残っています。
この問題の解決を支援するため、Google は SchedMD の協力を得て、Compute Engine での Slurm Workload Manager の起動を容易にするツールのプレビュー版をリリースしました。追加リソースが必要なときに既存クラスタを拡張することも可能です。
このツールは、SchedMD のエキスパートが Slurm のベスト プラクティスに従って構築したものです。Slurm は、TOP500 にランキングされているスーパーコンピュータの多くで使われている最先端かつオープンソースの HPC ワークロード マネージャです。

今回のインテグレーションにより、Compute Engine 上では、自動スケーリングされた Slurm クラスタを簡単に起動できるようになりました。Slurm クラスタはジョブの要件やキューの深さに応じて自動的にスケーリングします。
Slurm クラウド クラスタをセットアップすると、オンプレミス クラスタのジョブは、フェデレーションによって Compute Engine 上の Slurm クラスタを利用できるようになります。HPC クラスタをクラウド環境に用意しておけば、個々の研究者、チーム、またはジョブは、適切に調整されて弾力性もある専用のリソースを確保して、キューの順番待ちに煩わされず問題解決に集中できます。
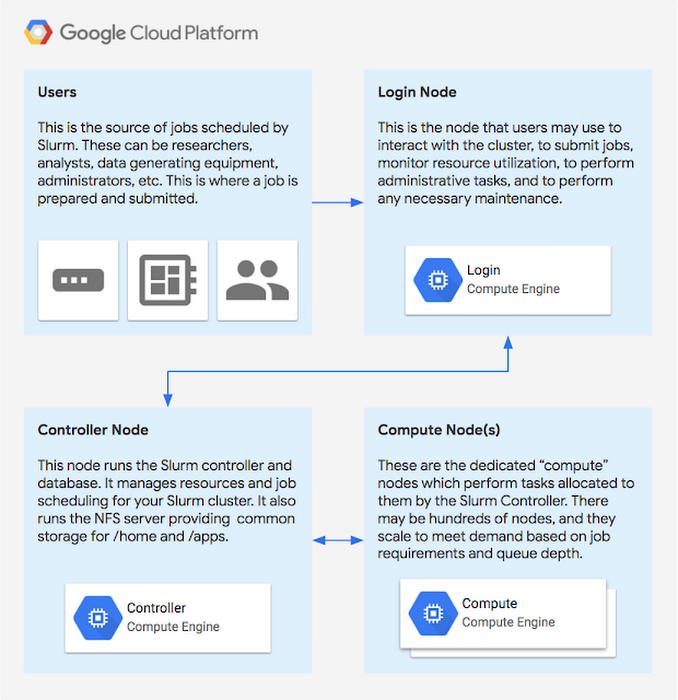
ユーザー
Slurm でスケジューリングされるジョブのソースです。研究者、アナリスト、データ生成機器、管理者などが該当します。ここではジョブが準備され、サブミットされます。
ログイン ノード
クラスタの操作、ジョブのサブミット、リソースの利用状況の監視、管理タスクの実行、そのほか必要なメンテナンス作業のためにユーザーが使用するノードです。
コントローラ ノード
Slurm コントローラとデータベースを実行するノードです。Slurm クラスタのリソースとジョブ スケジューリングを管理します。また、/home と /apps の共通ストレージを提供する NFS サーバーを実行します。
計算ノード(複数可)
Slurm コントローラによって割り当てられたタスクを実行する専用の “計算” ノードです。ノードの数が数百に上ることもあります。需要に応えるため、ジョブの要件とキューの深さに基づいてスケーリングされます。
ここからは、Compute Engine 上で Slurm クラスタを起動する手順をたどってみましょう。
ステップ 1 : SchedMD の GitHub リポジトリから Cloud Deployment Manager スクリプトを入手します。詳細は同梱の README.md を参照してください。必要に応じて Deployment Manager スクリプトをカスタマイズすることがあります。クラスタ パラメータの多くは同梱の slurm-cluster.yaml ファイルで設定できます。
slurm-cluster.yaml では、少なくとも munge_key の内容をペーストし、GCP ユーザー名を default_users に指定し、使いたい Slurm のバージョン(たとえば 17.11.5)を指定するといったカスタマイズが必要になります。
ステップ 2 : Cloud Shell か、gcloud コマンドがインストールされたローカル端末で以下のコマンドを実行します。
次に、Developers Console の Deployment Manager セクションに移動し、デプロイが成功していることを確かめます。
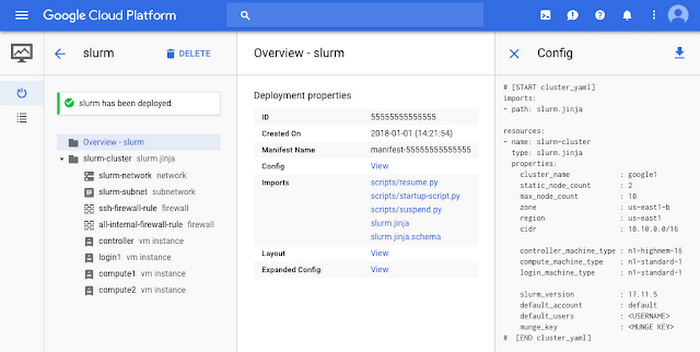
ステップ 3 : Developers Console の Compute Engine セクションに移動すると、Deployment Manager がいくつかの VM インスタンスを作成しており、その中に Slurm ログイン ノードが含まれていることがわかります。VM がプロビジョニングされ、VM 上に Slurm がインストールされて設定が行われたら、Console の SSH ボタンをクリックするか、gcloud compute ssh login1 --zone=us-west1-a を実行すれば、SSH でログイン ノードに入れます(slurm-cluster.yaml ファイルでゾーンを書き換えた場合は、ゾーンを変更しなければならないことがあります)。
ログインすると、いつもと同じように sbatch を使って Slurm とやり取りを行い、ジョブをサブミットできます。たとえば、slurm-sample1.sh という新しいファイルに以下のサンプル スクリプトをコピーします。
そして、以下のようにサブミットします。
次に sinfo と squeue コマンドを使用すれば、ジョブが計算ノードで分散処理されていることを確認できます。
サブミットされたジョブにおいて、最初にデプロイされたときよりも多くのリソースが必要になった場合は、slurm-cluster.yaml で指定された上限に達するまで新しいインスタンスが自動的に作成されることに注意してください。これは、#SBATCH --nodes=4 を指定してジョブを再度サブミットすれば試せます。一時的な計算インスタンスは、指定された時間アイドル状態が続くと、デプロビジョニングされます。
なお、Deployment Manager スクリプトは、デプロイの一環として NFS をセットアップすることに注意してください。
詳細は同梱の README をご覧ください。また、Slurm の導入にあたって支援が必要な場合は、クイックスタート ガイドを参照するか、SchedMD にお問い合わせください。
* この投稿は米国時間 3 月 23 日、Product Manager の Michael Basilyan、HPC Specialists の Wyatt Gorman と Keith Binder、Partner Manager の Annie Ma-Weaver によって投稿されたもの(投稿はこちら)の抄訳です。
- By Michael Basilyan, Product Manager; Wyatt Gorman and Keith Binder, HPC Specialists; and Annie Ma-Weaver, Partner Manager


