Google Cloud
Kaggle Kernels ノートブックで BigQuery データを分析
2019年7月5日

Google Cloud Japan Team
Google Cloud のエンタープライズ向けクラウド データ ウェアハウスである BigQueryに Kaggle が統合されました。BigQuery をご利用のお客様は、超高速の SQL クエリを実行し、SQL で機械学習モデルをトレーニングし、Kernels でそのモデルを分析できるようになります。Kernels とは、無料で使える Kaggle のホステッド Jupyter ノートブック環境です。
BigQuery と Kaggle Kernels を一緒に使うことで、直感的に扱える開発環境を使用して BigQuery データにクエリを実行し、データの移動やダウンロードなしで機械学習を行えます。Kernels ノートブックまたはスクリプトに Google Cloud アカウントをリンクすると、BigQuery API Client ライブラリを使ってノートブックで直接クエリを組み立て、BigQuery で実行するという形で、ほぼあらゆるタイプのデータ分析が可能になります。たとえば、Matplotlib、scikit-learn、XGBoost など最新のデータ サイエンス ライブラリをインポートすれば、結果を可視化したり、最先端の機械学習モデルをトレーニングしたりすることができます。さらに、Kernels の無料使用枠は、GPU と最大 16 GB の RAM を使って 9 時間実行できるという贅沢な内容です。Kernels が提供する機能の詳細は Kaggle のドキュメントをご覧ください。
300 万人以上のユーザーを抱える Kaggle は、データ サイエンティストたちがデータの探索や分析、その成果のシェアのために集まる世界的なオンライン コミュニティです。Python か R の Kernels ノートブックを起動すればすぐにコーディングを開始でき、ほかの人々が書いた 20 万以上の公開 Kernels からヒントを得ることができます。
BigQuery のお客様にとって何よりも大きいのは、クエリや分析を 1 か所にまとめられる IDE(統合開発環境)、すなわち Kaggle Kernels を使えることでしょう。データ サイエンティストの仕事は細切れになりがちで、従来はクエリ エディタでクエリを実行し、そのデータを別の場所にエクスポートして分析を終えていましたが、Kernels はそれらをシームレスにつないで 1 つにまとめます。
しかも、Kaggle は Kernels を簡単に公開できるシェアのためのプラットフォームです。オープンソースの仕事を広めたり、世界最高レベルのデータ サイエンティストたちと議論したりすることができます。
Kernels で BigQuery データセットを分析するには、まず Kaggle アカウントにサインアップします。サインインの後に、上のバーの “Kernels” をクリックし、さらに “New Kernel” をクリックすると、新しい IDE セッションがスタートします。Kernels にはスクリプトとノートブックの 2 つのタイプがあります。次に示すのはノートブック オプションの例です。
BigQuery と Kaggle Kernels を一緒に使うことで、直感的に扱える開発環境を使用して BigQuery データにクエリを実行し、データの移動やダウンロードなしで機械学習を行えます。Kernels ノートブックまたはスクリプトに Google Cloud アカウントをリンクすると、BigQuery API Client ライブラリを使ってノートブックで直接クエリを組み立て、BigQuery で実行するという形で、ほぼあらゆるタイプのデータ分析が可能になります。たとえば、Matplotlib、scikit-learn、XGBoost など最新のデータ サイエンス ライブラリをインポートすれば、結果を可視化したり、最先端の機械学習モデルをトレーニングしたりすることができます。さらに、Kernels の無料使用枠は、GPU と最大 16 GB の RAM を使って 9 時間実行できるという贅沢な内容です。Kernels が提供する機能の詳細は Kaggle のドキュメントをご覧ください。
300 万人以上のユーザーを抱える Kaggle は、データ サイエンティストたちがデータの探索や分析、その成果のシェアのために集まる世界的なオンライン コミュニティです。Python か R の Kernels ノートブックを起動すればすぐにコーディングを開始でき、ほかの人々が書いた 20 万以上の公開 Kernels からヒントを得ることができます。
BigQuery のお客様にとって何よりも大きいのは、クエリや分析を 1 か所にまとめられる IDE(統合開発環境)、すなわち Kaggle Kernels を使えることでしょう。データ サイエンティストの仕事は細切れになりがちで、従来はクエリ エディタでクエリを実行し、そのデータを別の場所にエクスポートして分析を終えていましたが、Kernels はそれらをシームレスにつないで 1 つにまとめます。
しかも、Kaggle は Kernels を簡単に公開できるシェアのためのプラットフォームです。オープンソースの仕事を広めたり、世界最高レベルのデータ サイエンティストたちと議論したりすることができます。
Kaggle と BigQuery の始め方
BigQuery を初めてお使いになる方は、BigQuery サンドボックスでアカウントを有効にしてください。これにより、最大で 10 GB のストレージ、1 か月あたり 1 TB のクエリ処理、10 GB の BigQuery ML モデル作成クエリを無料で使用できます(料金体系の詳細は BigQuery のドキュメントをご覧ください)。Kernels で BigQuery データセットを分析するには、まず Kaggle アカウントにサインアップします。サインインの後に、上のバーの “Kernels” をクリックし、さらに “New Kernel” をクリックすると、新しい IDE セッションがスタートします。Kernels にはスクリプトとノートブックの 2 つのタイプがあります。次に示すのはノートブック オプションの例です。
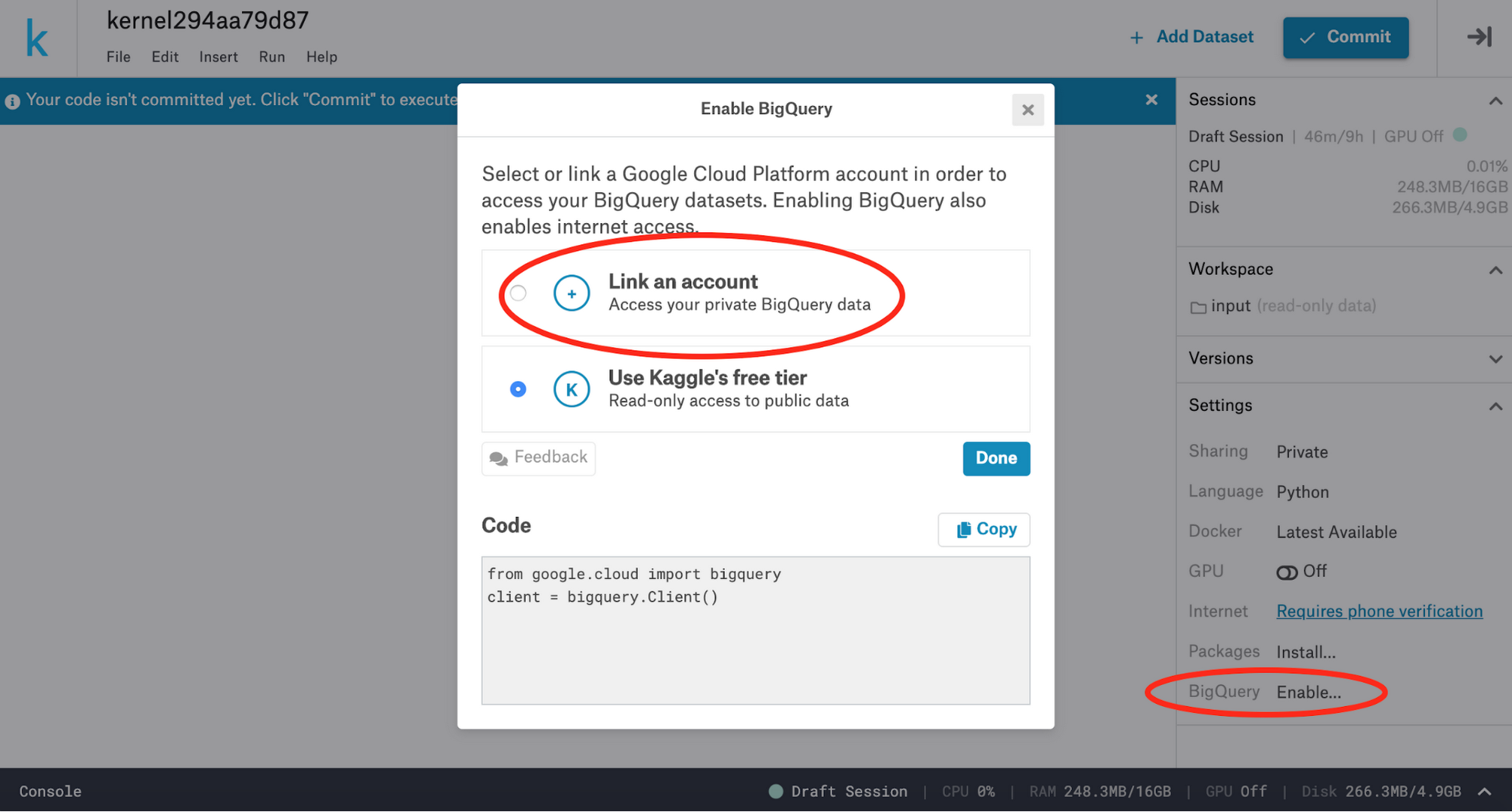
次に、Kernels のエディタ環境で、右側にあるサイドバーの “BigQuery” をクリックし、続いて “Link an account” をクリックして、Kaggle アカウントに BigQuery アカウントを紐づけます。アカウントがリンクされたら、BigQuery API Client ライブラリを使ってご自分の BigQuery データセットにアクセスできます。
Kaggle で公開されている Ames Housing データセットを使用して、これを試してみましょう。このデータセットは米国アイオワ州エイムズに建つ住宅の(ほとんど)すべての側面を記述する 79 種の説明変数から成り、その最終販売価格も含まれています。このデータから情報を得るためにクエリを作ってみましょう。このデータセットにはどのような家のタイプが含まれているのでしょうか。また、セントラル空調を設置している家、設置していない家はどれくらいあるのでしょうか。クエリは次のとおりです。
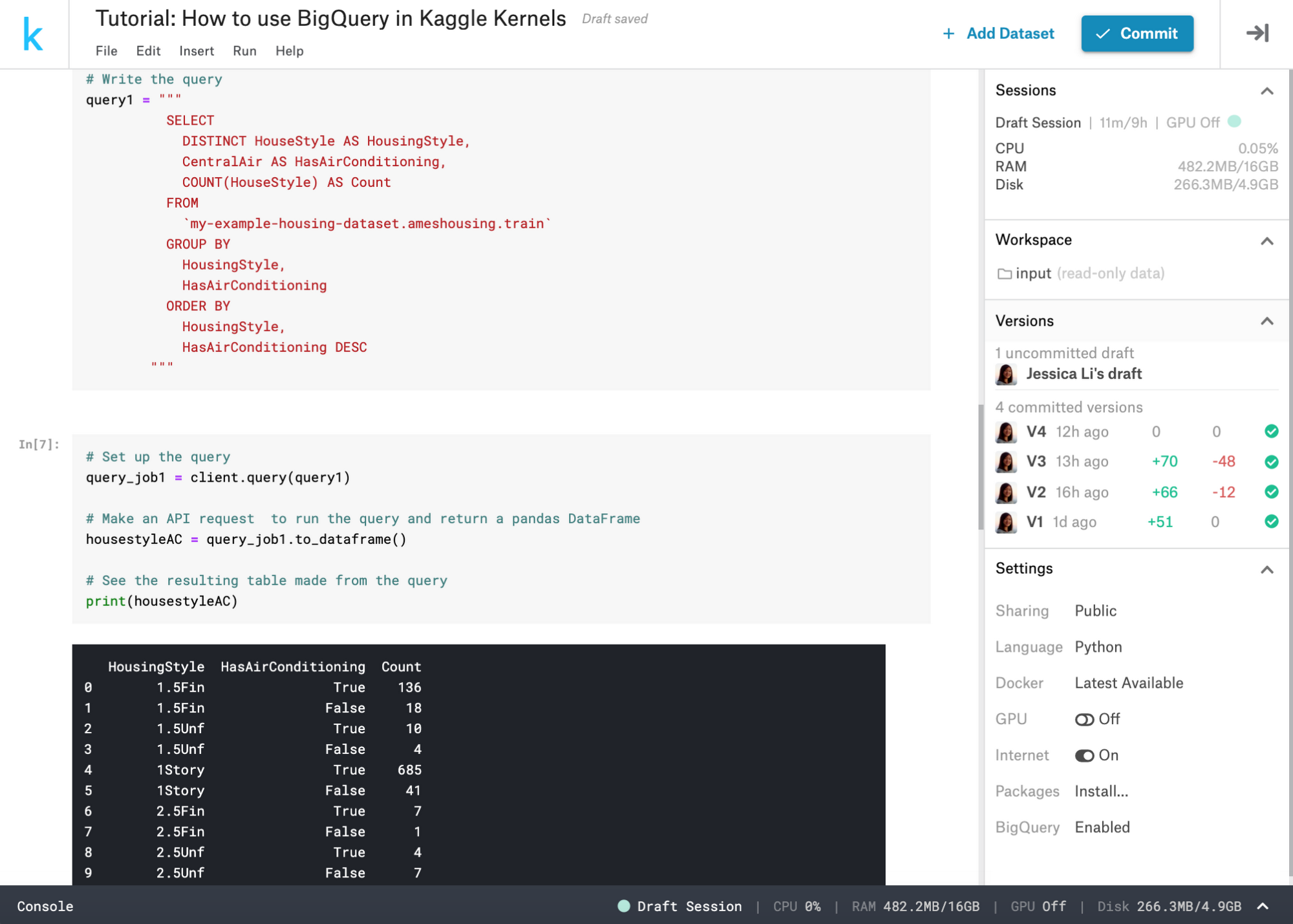
エイムズで最も一般的な家のタイプは平屋建てで、タイプに関係なく、ほとんどの家にセントラル空調が設置されていることがすぐにわかります。Kaggle には、このような形で探索できる公開データセットがほかにもたくさんあります。
SQL クエリを使った機械学習モデルの構築
データ分析のほか、BigQuery ML では SQL クエリを使って機械学習モデルを作成、評価できます。機械学習フレームワークやプログラミング言語に関する詳細な知識がなくても、データ サイエンティストであれば、わずかなクエリだけで回帰モデルの構築や評価を行えるのです。ここでは、エイムズにある不動産の最終販売価格を予想する線形モデルを作ってみましょう。このモデルでは、居住スペースの広さ、築年数、条件全般、品質全般を入力としてトレーニングを行います。モデルのコードは次のようになります。読み込んでいます...
このように、1 つのクエリだけで、Kernels の中に SQL ベースの機械学習モデルを作りました。Kernels を使用すれば、分析のためにもっと高度なクエリを作成したり、モデルを最適化して性能を高めたりすることができます。分析が完了したら、Kaggle コミュニティや、より広範なインターネット ユーザーに向けて Kernels ノートブックを公開することも可能です。
トレーニング統計情報の取得やモデルの評価に関するワークフローの続きの部分については、『Tutorial : How to use BigQuery in Kaggle Kernels』をご覧ください。このチュートリアルは Kernels ノートブックとして公開されています。モデルのトレーニングや評価を深く掘り下げる『Getting started with BigQuery ML』もあります。
BigQuery と Kaggle Kernels の統合の詳細は Kaggle のドキュメントをご覧ください。BigQuery を使って SQL 言語の基本を学べる Kaggle の SQL micro-course も内容を一新しており、サインアップすることをお勧めします。この統合機能をぜひお試しください。
トレーニング統計情報の取得やモデルの評価に関するワークフローの続きの部分については、『Tutorial : How to use BigQuery in Kaggle Kernels』をご覧ください。このチュートリアルは Kernels ノートブックとして公開されています。モデルのトレーニングや評価を深く掘り下げる『Getting started with BigQuery ML』もあります。
BigQuery と Kaggle Kernels の統合の詳細は Kaggle のドキュメントをご覧ください。BigQuery を使って SQL 言語の基本を学べる Kaggle の SQL micro-course も内容を一新しており、サインアップすることをお勧めします。この統合機能をぜひお試しください。
- By Jessica Li, Product Manager, Kaggle and Jordan Tigani, Director, BigQuery, Google Cloud



