リリース パイプラインに割り当ての回帰検出を組み込む
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud では、組織が消費できるリソースの量を公平に保つ方法の一つとして、割り当てを使用しています。サービスのリソース消費量を制限することによって、企業はクラウド費用をより適切に管理できます。多くの場合、割り当てを API に関連付けてリソースにアクセスします。エンドポイントが処理可能な秒間クエリ数(QPS)は大量ですが、割り当てを使用することにより、1 人のユーザーやお客様が使用可能な容量を超えてリソースを独占することがないようにします。ここで重要になるのが公平性です。ユーザーやお客様ごとに設定できるスコープの上限を設け、その上限を増減できます。
リソース プロバイダ(今回の場合は Google Cloud)の視点からすると、割り当ての上限によって、公平性の問題に対処できているといえますが、リソースを使用するお客様には、その上限が守られていることを確認する方法が必要です。また同様に、不注意でこの上限を超えてしまわないようにすることも重要です。これは、自動化が進んでいる継続的インテグレーションと継続的デリバリー(CI / CD)環境では、特に重要なことです。CI / CD はプロダクト リリースの自動化に大きく依存していて、リリースされたプロダクトが常に安定していることを確認する必要があります。ここで、割り当て回帰の問題が発生します。
割り当て回帰とは何か、どのように発生するのか?
割り当て回帰とは、指定された割り当てが予定外に変更されることです。これにより、多くの場合リソースの消費容量が低下します。
会計事務所を例にとってみましょう。私はこの業界には友人がたくさんいますが、1 月から 4 月の繁忙期になると、彼らが私に付き合ってくれることは決してありません。一応は、それが口実です。繁忙期になると、桁外れに大量の取扱い件数を抱えますが、それ以外の時期は少なくなります。この取扱い件数が、実際に Google Cloud のリソース費用に即座に影響すると仮定してみましょう。取扱い件数の急増は、年間を通じて特定の時期にしか発生しないため、常に高い割り当てを維持する必要はないかもしれません。リソースは「従量制」モデルで支払われるため、費用的には賢明とは言えません。
会計事務所が社内にエンジニアリング チームを持ち、システムが目的どおりに機能しているかを確認する負荷テストを構築していれば、繁忙期前に負荷容量が増加することが予想できます。負荷テストがサービス環境とは別の環境で行われている場合(セキュリティやデータへの不要なアクセス許可を避けるためにそうすべきです)、割り当て回帰が発生するかもしれません。この例として、非本番環境の Google Cloud プロジェクト(例: your-project-name-nonprod)で負荷テストを行い、イメージをサービス プロジェクト(例: your-project-name-prod)にプロモートすることが挙げられます。
負荷テストに合格するためには、負荷テスト環境に十分対応できる割り当て量が必要です。しかし、サービス環境でその割り当てが付与されていないこともあり得ます。これは、管理者がサービス環境で、追加の割り当てをリクエストする必要があるプロセスを単に見落としたか、繁忙期の後にその割り当てが元に戻ったことに気づかなかったのが原因かもしれません。どちらにしても、環境間で割り当てに整合性を保つには人間の介入が必要になります。これを見過ごしてしまうと、この会計事務所は、負荷テストに合格して繁忙期を迎えることができても、サービス環境の割り当て不足によるシステム停止に陥る可能性があります。
従来のモニタリングではなぜ不十分なのか?
ここで思い浮かべるのが、「セキュリティのモニタリングとセキュリティ ガード」の議論です。このような矛盾を検出するモニタリングを行っても、アラートが無視されることや、アラートが遅れる場合があります。アラートは、この動作に関連する自動化がされていない場合に役立ちます。上記の例では、アラートだけで十分かもしれません。しかし、CI / CD の場合は、下位環境に十分な割り当てがあれば負荷テストに合格するため、依存関係に高い QPS を導入するデプロイメントが、下位環境からサービス環境にプロモートされる可能性があります。ここで問題なのは、現在、そのデプロイメントが自動的に本番環境に push され、アラートが発生し、サービスが停止される可能性が高いということです。
このようなシナリオに対処する最善の方法は、モニタリングしてアラートを出すだけでなく、そのような回帰的動作をサービス環境にプロモートしないための自動化された方法を取り入れることです。最も心配なのは、付与されたリソース量よりも多いリソース割り当てを必要とする新しいロジックが、自動的に本番環境にプロモートされることです。
なぜテストで既存の確認を行わないのでしょうか?ソフトウェア エンジニアリングの分野では、いくつかの種類のテスト(単体テスト、統合テスト、パフォーマンス テスト、負荷テスト、スモークテストなど)が行われていますが、環境間の整合性を確保するような複雑な問題に対応できるテストはありません。テストの多くは、ユーザーと想定される動作に焦点を当てています。インフラストラクチャに特化した唯一のテストは負荷テストですが、割り当て回帰は必ずしも負荷テストの一部とは限りません。負荷テストは独自の環境で行われ、実際に実行されている環境には依存しないため、検出されないのです。
つまり、割り当て回帰テストは環境を意識する必要があります。負荷テストが行われる想定されるベースライン環境と、プロダクトがデプロイされる実際のサービス環境が必要になります。私は、その他多くの一連のテストに含まれる、環境を意識したテストを提案しています。
Google Cloud での割り当て回帰テスト
Google Cloud では、この機能を簡単に組み込むために利用できるサービスをすでに提供しています。これはむしろ、実行できるシステム アーキテクチャの実践といえます。
Service Consumer Management API では、独自の割り当て回帰テストを作成するために必要なツールを提供しています。例として、リスト API を介して返される ConsumerQuotaLimit リソースについて考えてみます。ここからは、以下のような環境設定を想定して説明します。
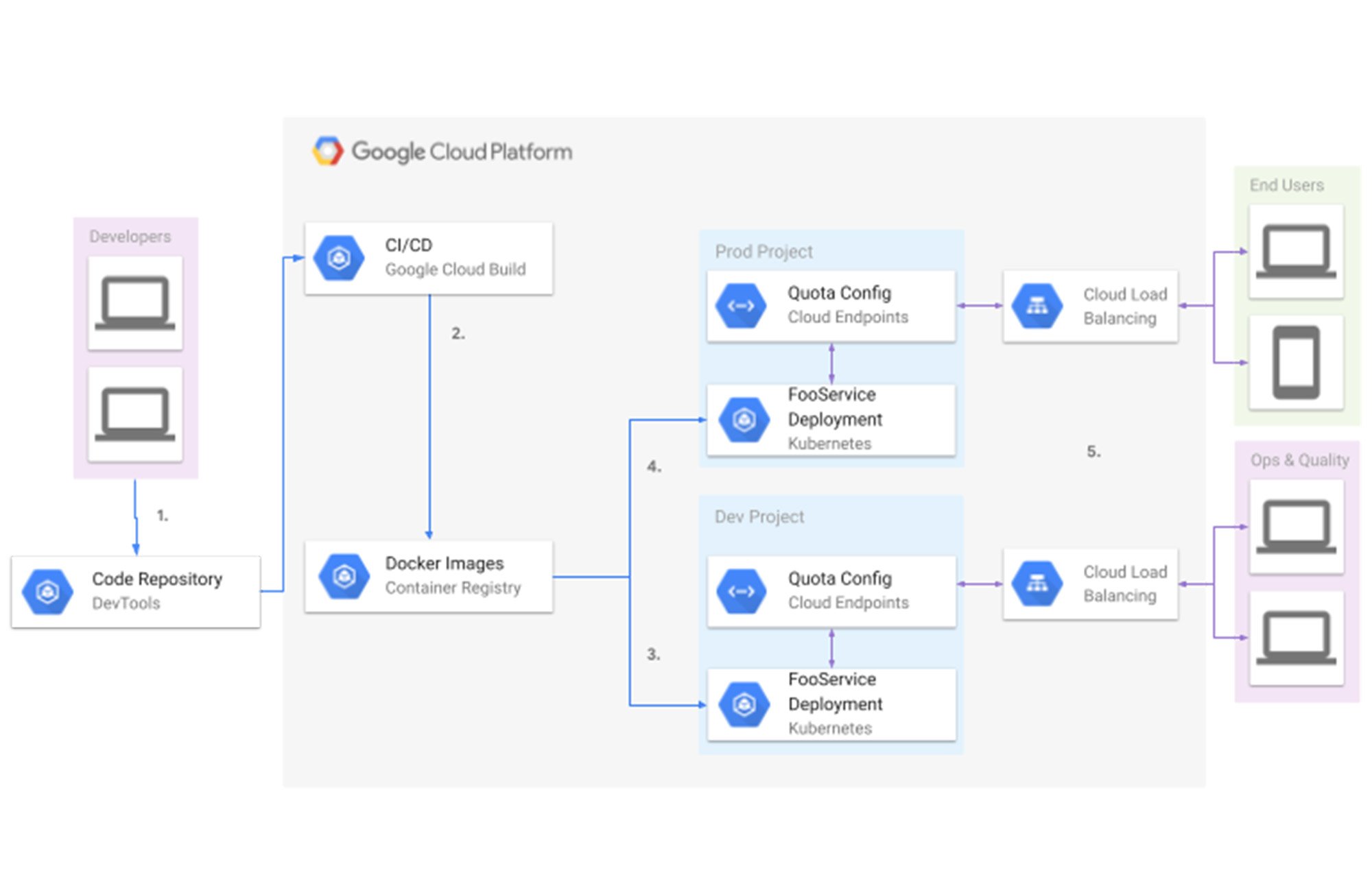
上の図は、デプロイ パイプラインを簡略化したものです。
デベロッパーがリポジトリにコードを送信する
Cloud Build のビルドとデプロイのトリガーが起動する
テストを実行する
前提条件の手順を完了すると、デプロイメントのイメージが push される
イメージは各環境に push される(今回のケースでは、ビルドは開発環境に、以前の開発環境は本番環境に)
割り当ては、デプロイ時にエンドポイントに定義される
Cloud ロードバランサによってエンドユーザーがエンドポイントを利用可能になる
割り当て上限
このメンタルモデルを使用して、全体像の中で割り当てが果たす役割について詳しく見ていきましょう。たとえば、「FooService」というエンドポイントに対して以下のようなサービス定義があるとします。この例で重要なのは、サービス名、指標ラベルの値、割り当ての上限値です。
gRPC Cloud Endpoint Yaml のサンプル
今回の定義では、以下のことを確立しています。
サービス名:
fooservice.endpoints.my-project-id.cloud.goog指標ラベル:
library.googleapis.com/read_calls割り当て上限:
1
これらの要素を定義することで、サービスの読み取り呼び出しをちょうど 1 分につき 1 回に制限できるようになります。プロジェクト番号(例: 123456789)を指定し、コンシューマー割り当て指標サービスに呼び出しを発行して、サービス割り当てを表示できます。
コマンドと出力の例
レスポンス例(省略あり)
上記のレスポンスにおいて、注意すべき最も重要なことは、特定のサービス指標に対する実質的な上限です。前述したように、この実質的な上限とは、顧客間の公平性を確立する際にリソースを消費するお客様に適用される上限のことです。
プロジェクトごとのリソースに対して割り当て定義の effectiveLimit を取得する方法を確立したので、割り当ての整合性に関するアサーションを次のように定義できます。
負荷テスト環境での割り当ての実質的な上限 <= サービス環境での割り当ての実質的な上限
このようなテストを行えば、Cloud Build などと統合し、テストに合格しなかった場合は、下位環境からサービス環境へのイメージのプロモートを阻止できます。これにより、新しいイメージからサービス環境に回帰的な動作が発生することによって起こるサービスの停止を防ぐことができます。
早期検出の重要性
割り当て回帰を検出したときにアラートを出し、本番環境へのイメージのプロモートを阻止するだけでは十分とはいえません。可能な限り早く検出を知らせることがベターです。もし、本番環境にプロモートさせるときにリソースが不足していた場合、今度は十分なリソースを時間内にラングリングするという問題に直面します。これは、常に希望するスケジュールで行えるとは限りません。なぜなら、リソース プロバイダが割り当ての増加を処理するために、リソースのスケールアップが必要な場合もあるからです。この作業は、必ずしも 1 日でできることではありません。たとえば、該当するサービスは Google Kubernetes Engine(GKE)でホストされているのか、自動スケーリングを使用したとしても、IP プールが不足した場合はどうするのか、などが影響します。クラウド インフラストラクチャの変更は、弾力性はありますが、少し時間がかかります。実稼働計画の一部は、スケーリングにかかる時間を考慮する必要があります。
要約すると、割り当て回帰テストは、Google Cloud に限らず、あらゆるクラウドサービスにおいて過負荷を処理し、ロード バランシングに対応するという全体のコンセプトにとって、追加するべき重要なコンポーネントです。需要の落ち込みや急増に伴うプロダクトの安定性を確保するうえで重要であり、これは多くの分野で必ず発生する問題です。もし、構成全体で割り当ての整合性を確保するために人間の介入に依存し続けるなら、整合性に欠けた場合、最終的にはサービスの停止を招くことになります。割り当ての操作について詳細は、こちらのドキュメントをご覧ください。
-シニア ソフトウェア エンジニア Nethaneel Edwards


