Spanner への近似最近傍(ANN)検索の導入
Zhiyan Liu
Software Engineer
※この投稿は米国時間 2024 年 8 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
ベクトル検索は、大規模なデータセットの中から、指定されたクエリアイテムに似たアイテムを見つけるために使用する手法です。従来の(完全一致に基づく)検索手法があまり効果的ではない、画像、テキスト、音声などの非構造化データを扱う場合に特に有用です。また、大規模言語モデル(LLM)のプロンプトの強化、関連性の向上、ハルシネーションの削減にも使用できるため、生成 AI アプリケーションにおけるベクトル検索の役割は重要です。この機能が汎用データベースに組み込まれているということは、スケーラブルなベクトル検索機能がオペレーショナル データベースに直接統合され、別のデータベースや ETL パイプラインを管理する必要がないということです。
現在プレビュー版で提供している Spanner の厳密 K 最近傍(KNN)ベクトル検索は、個人の写真を検索するなど、個々のクエリに関連するエンティティの数が比較的少ない、高度にパーティショニング可能なワークロードに適しています。今年初めに KNN ベクトル検索をリリースして以来、Spanner のお客様による導入が増加しています。そしてこのたび、パーティション分割されていない大規模なワークロードでも、Spanner で近似最近傍(ANN)検索を利用して、以下を実現できるようになりました。
-
スケールとスピード: 10 億以上のベクトルに対応する高速、高再現率の検索
-
運用の簡素化: 専用のベクトル DB へのデータのコピーが不要
-
整合性: 最新のアップデートが反映された、常に最新の結果を表示
ANN 検索機能の追加により、Spanner はベクトル検索ニーズに対して、スケーラビリティに優れた効率的なサポートを提供できるようになりました。とはいえ、Google の言葉を鵜呑みにしないでください。お客様の声をご紹介しましょう。
「Spanner のベクトル検索がもたらすセマンティックな理解の力を活用することで、関連性の高いコンテンツとエクスペリエンスをお客様に提供し、エンゲージメントとコンバージョン率の向上を実現できると考えています。」 - Optimizely、最高技術責任者 Aniel Sud 氏
ANN を使用する
大規模なベクトル検索を実現する Spanner のイノベーションについて、詳しく見ていきましょう。
Spanner は、Google Research の高効率なベクトル類似検索アルゴリズムである ScaNN(スケーラブルな最近傍)を活用しています。これは、Google および Google Cloud アプリケーションに不可欠な要素です。現在 Spanner には、以下のような主要な ScaNN ベースの最適化が組み込まれています。
-
ツリー状構造へのクラスタ エンベディングにより、スコア空間を枝刈りしてクエリ時間を短縮し、精度と引き換えにパフォーマンスを大幅に向上
-
生のベクトル エンベディングを量子化し、スコアリングの高速化とストレージの削減を実現
-
ベクトルの最も関連性の高い部分に焦点を当てて距離計算を最適化し、パーティショニングとランキングを改善して再現率を向上
Spanner で ANN を実行するには、標準 SQL DDL を使用し、検索ツリーの形状と距離の種類を指定して、ベクトル エンベディングのベクトル インデックスを作成する必要があります。
ツリーの形状
データセットのサイズにより、ツリーは 2 レベルまたは 3 レベルになります。3 レベルのツリーでは、ルートとリーフの間にブランチノードのレイヤが追加され、10 億以上のベクトル データセットまでスケーリングできる階層的なパーティショニングが可能になります。セントロイドと呼ばれるリーフ パーティションの代表は、それ自体がエンベディングでもあり、計算され、ルートノードとブランチノードに格納されます。
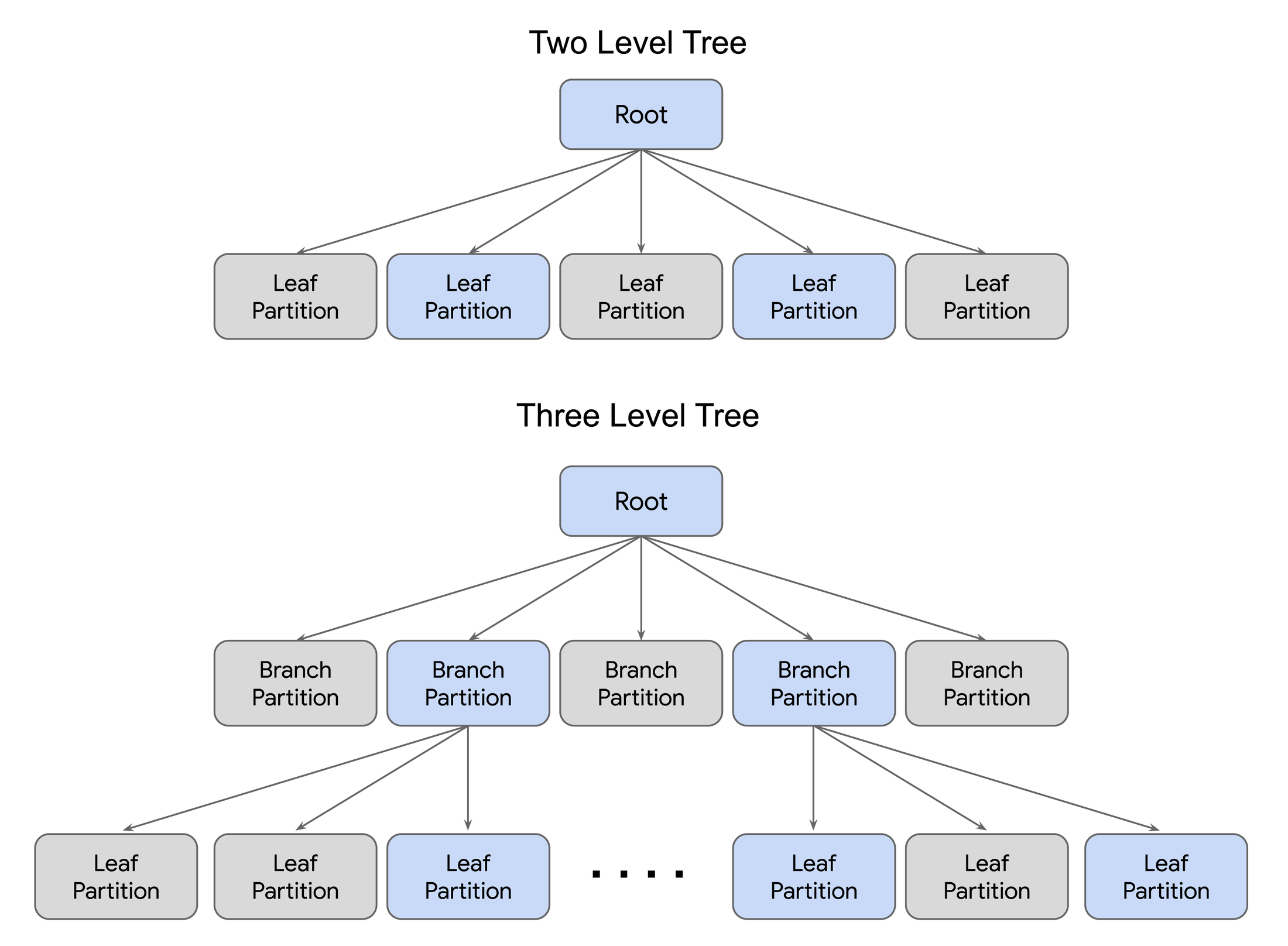
クエリ時には、受信したクエリ エンベディングは、まずルートに格納されているすべてのセントロイドと比較されます。最も近いセントロイドと、それに対応するリーフ(2 レベルのツリーの場合)またはブランチ(3 レベルのツリーの場合)のみが、さらなる評価のために選択されます。上の図では、青いブロックがスコアリングのために読み込まれる検索ツリー部分を表し、灰色のブロックが枝刈りされる部分(ツリー全体の大部分)を表しています。
ツリーのブランチとリーフの数はインデックス作成時に設定できます。一方、検索するリーフの数はクエリ時に調整できます。クエリオプションと同様にインデックス作成ノブを調整することで、求めているパフォーマンスと精度のトレードオフを実現できます。
距離関数
距離関数は、ベクトル エンベディング間の類似度を測定する手段です。Spanner はすでに KNN 検索のための厳密な距離関数をサポートしています。ANN については、ベクトル インデックスとともに使用する ANN 検索用に以下の近似距離関数が導入されています。
-
APPROX_COSINE_DISTANCE() -
APPROX_EUCLIDEAN_DISTANCE() -
APPROX_DOT_PRODUCT()
ベクトル インデックスの作成時には、求めている距離の種類をインデックス オプションとして指定する必要があります。指定可能な値は COSINE、EUCLIDEAN、DOT_PRODUCT です。
ベクトル インデックスに対するクエリでは、対応する距離関数を使用する必要があります。
例: 投資信託の検索
ANN のデモで紹介された例を見ていきましょう。あるお客様が投資に適した投資信託を探しています。MutualFunds テーブルの各行は 1 つの投資信託を表しています。
-
FundIdは、投資信託の固有識別子です。他のテーブルで相互参照される場合があります。 -
FundNameは、投資信託の正式な名称です。 -
InvestmentStrategyは、ファンドの戦略を記述した構造化されていないテキスト文字列です。 -
Attributesは、運用益など、ファンドに関する構造化データを格納するプロトコル バッファです。 InvestmentStrategyEmbeddingは、投資戦略のベクトル表現です。ML.PREDICT関数を使用して生成できます。
次のステートメントを使用して、MutualFunds のベクトル インデックスを作成します。
投資信託の数が多い場合は、3 レベルのツリーの方が適切かもしれません。
インデックスが作成されたら、以下のようにクエリを実行します。query_embedding は、InvestmentStrategyEmbedding 列を生成したものと同じエンベディング モデルを使用し、ユーザー入力のテキストに基づいて ML.PREDICT により生成された、求めている投資戦略のベクトル表現です。
このクエリでは、50 件のリーフを検索し、クエリの投資戦略に最も近い上位 10 件の投資信託を見つけます。num_leaves_to_search の値を調整して、レイテンシと再現率をトレードオフします。
現時点では、以下に注意してください。
-
使用するベクトル インデックスは、クエリヒントとして明示的に指定する必要があります。
-
クエリでは、ベクトル インデックスと同じ NULL フィルタリング(
IS NOT NULL)句を使用する必要があります。 -
近似距離関数は、ベクトル インデックスの
distance_typeと一致している必要があります。 -
距離関数を唯一の ORDER BY キーにして、LIMIT を指定する必要があります。
高度なユースケース
ポスト フィルタリング
ANN の検索結果は、クエリの WHERE 句に属性を追加することでフィルタできます。次のクエリは、クエリ戦略が一致し、10 年間の利益率が 8% を超えるファンドを返します。
マルチモデル クエリ
FundName フィールドに全文検索インデックスも作成する場合は、以下のようになります。
以下のクエリを実行すると、クエリ戦略(「balanced low risk socially responsible fund(バランスの取れた低リスクの社会的責任ファンド)」のようなフレーズのベクトル表現など)が似た、名前に「emerging markets(新興市場)」が含まれているファンドを探すことができます。
また、求めている戦略に似たファンドか、ファンド名に「emerging markets(新興市場)」が含まれているファンドを探すことで、必ずしもこれらの言葉がすべて含まれているとは限らないテキスト一致や意味的一致を見つけることができます。
このようにすると、従来のテキスト検索結果を、意味的に関連性のある検索結果でフィルタしたり増やしたりすることができます。
使ってみる
Spanner の詳細情報を確認し、今すぐお試しください。その他の情報については、以下をご覧ください。
-
Spanner ベクトル検索のデモ
-
Spanner ANN ユーザーガイド
-
Spanner の ML.PREDICT SQL 関数を使用したデータベース内ベクトル エンベディング生成(チュートリアル)、LLM クエリ(チュートリアル)、Vertex AI が提供するカスタムモデルによるオンライン推論(チュートリアル)
-
LangChain と、オープンソースの spanner-analytics パッケージ(Python での一般的なデータ分析オペレーションを容易にし、Jupyter Notebooks とのインテグレーションが含まれます)を含む Spanner の AI エコシステムのインテグレーション
-ソフトウェア エンジニア Zhiyan Liu