最新のカラム型ストレージ エンジン上の Spanner
Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
Google は「クラウド生まれ」です。20 年以上もの間、社内外向けの重要なサービスを支える大規模なインフラストラクチャを運用してきました。ユーザーの目に見える機能から、インフラストラクチャの効率性、信頼性、安全性を高める目に見えない内部構造に至るまで、このインフラストラクチャに対する投資を継続してきました。このインフラストラクチャは、常にアップデートされ改良されています。世界中の何十億人ものユーザーにサービスを提供しているため、このインフラストラクチャの運用や更新の中核となっているのは可用性と信頼性です。
Spanner は、複製される強整合性を備えた高度にスケーラブルな Google のデータベース管理サービスです。Google の本番環境インスタンスで動作している数十万のデータベースを使用して、ピーク時には毎秒 20 億件以上のリクエストを処理し、6 エクサバイトを超えるデータを管理しています。AdWords、Google 検索、Cloud Spanner などのミッション クリティカルなサービスを利用するお客様にとって Spanner が「信頼できる情報源」となっています。お客様のワークロードは多様であり、おそらくさまざまな方法で単一のシステムを無理矢理使用しているでしょう。これまでにも Spanner では定期的にバイナリのリリースが行われてきましたが、基盤となるストレージ エンジンの交換などといった根本的な変更を行うのは、難易度の高い取り組みです。
この投稿では、Spanner をカラム型ストレージ エンジンへと移行するための長い道のりについて取り上げます。大規模な移行の前に立ちはだかった課題や、2~3 年もの間、すべての重要なサービスの動作に支障をきたすことなくこの取り組みを成し遂げた方法について説明します。
ストレージ エンジン
ストレージ エンジンとは、データベース内のデータを実際のバイトに変換して基盤となるファイル システムに保存する場所です。Spanner のデプロイでは、データベースが 1 つ以上のインスタンス構成(リソースの実質的な集合体)でホストされています。このインスタンス構成とデータベースが、複数の Spanner サーバーによってホストされる 1 つ以上のゾーンまたはレプリカを形成します。ストレージ エンジンは、サーバー内でデータをエンコードして、基盤となる大規模な分散ファイル システムである Colossus に保存します。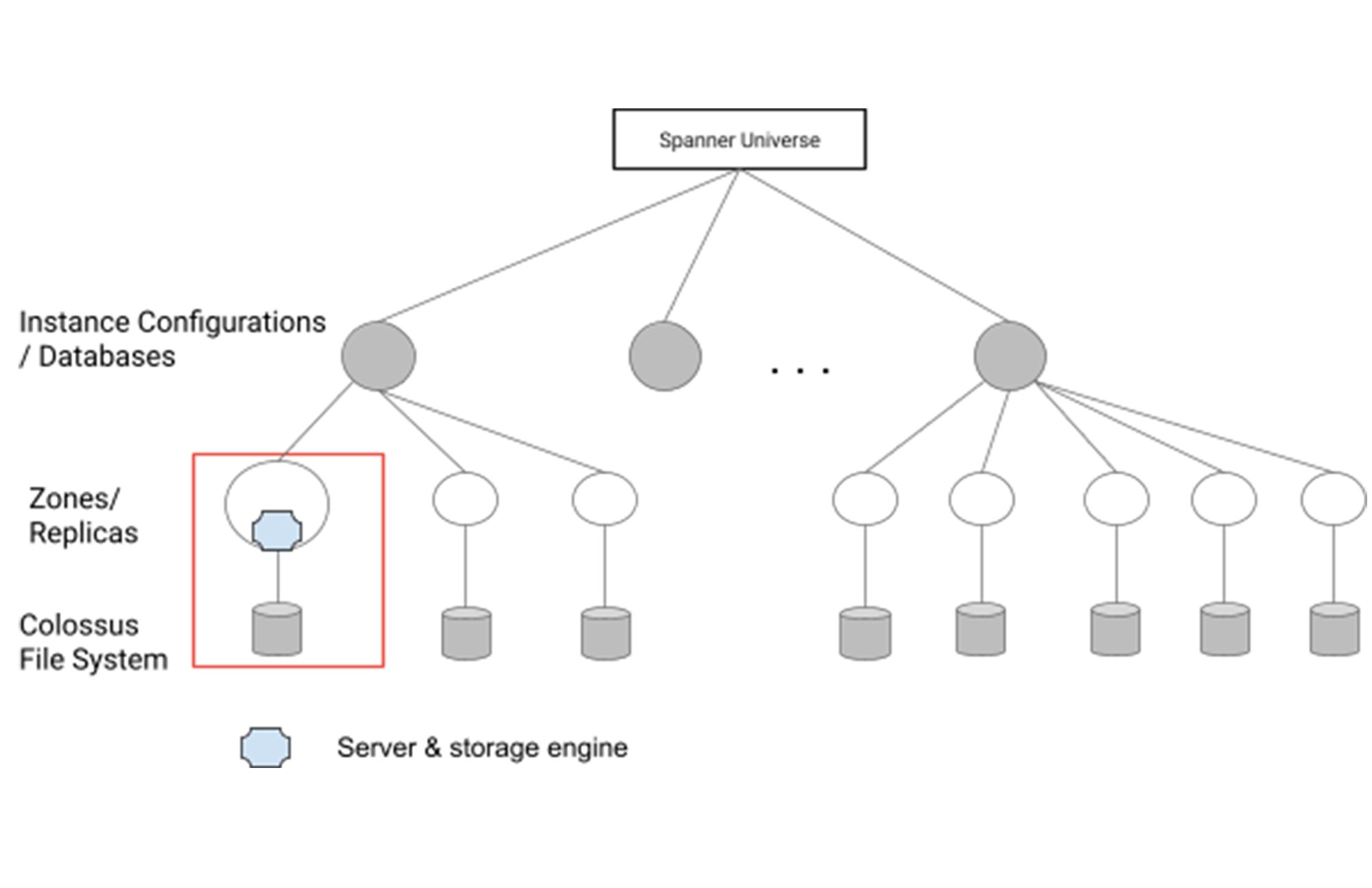
Spanner は当初、SSTable(ソートされた文字列テーブル)形式のスタックに基づく Bigtable のようなストレージ エンジンを使用していました。Bigtable や Spanner そのものに長年にわたり大規模にデプロイされてきたなかで、この形式は非常に堅牢であることが証明されています。SSTable 形式は、大規模な文字列を中心に構成されるスキーマレスな NoSQL データ向けに最適化されています。この形式は Bigtable には最適ですが、Spanner にとって最適とは言えません。特に、個々の列を走査するには非効率です。
Ressi は、ローレベルで列指向の、新しい Spanner 向けストレージ形式です。このストレージ形式はゼロから設計されました。OLTP と OLAP の両方のワークロードが存在する大規模な分散データベースで SQL クエリを処理するため、さらにデータベース内の Key-Value データを使用した読み取りクエリと書き込みクエリのパフォーマンスを維持および改善するためのものです。Ressi では、ブロックレベルのデータ レイアウト、アクティブなデータと非アクティブなデータのファイルレベルでの編成、ストレージ I/O を節約するための存在フィルタなど、さまざまな最適化が可能です。データ編成によりストレージ使用量が改善され、大規模なクエリのスキャンに役立ちます。Spanner 上の Gmail などの非常に大規模なサービスを使用した Ressi のデプロイでは、CPU やストレージ I/O などの複数の項目でパフォーマンスが向上しています。
ストレージ エンジンの移行における課題
Google Cloud は、Spenner の改善と更新を絶えず行っており、動的な環境での安全なシステム運用や高性能化を得意としています。しかし、ストレージ エンジンを移行することでデータベース システムの基盤が変わり、特に大規模なデプロイ規模では、顕著な課題が表面化します。
一般的に、本番環境の OLTP データベース システムでのストレージ エンジンの移行は、ホストされているデータベースを中断することなく、レイテンシやスループットの低下を発生させずに、データの整合性を損なうことなく実行する必要があります。過去には、ライブ データベースのストレージ エンジンを移行する試みと成功事例がありました。しかし、数エクサバイトのデータを含んだ Spanner のような規模での試みが成功したケースはまれです。サービスのミッション クリティカルな性質と、大規模なスケールから、移行の方法には非常に高い要件が課せられます。
信頼性、可用性、データの整合性
移行での最大の要件は、移行の全過程を通じてサービスの信頼性、可用性、およびデータの整合性を維持することです。課題は極めて重要であり、Spanner の大規模なデプロイに特有のものでした。
Spanner データベースのワークロードは多様で、基盤となる Spanner システムとさまざまな法でやり取りします。あるデータベースが問題なく移行できても、別のデータベースの移行が成功するとは限りません。
大規模なデータ移行は、基盤となるシステムに異常な変動をきたす危険性をはらんでいます。これにより、予期せぬ潜在的な動作が引き起こされ、本番環境が停止する可能性があります。
Google Cloud はお客様による新しい環境の変更や Spanner の新機能の開発が絶えず行われている動的な環境で運用しています。移行は、単調に減少していかないリスクに直面しました。
パフォーマンスとコスト
新たなストレージ エンジンへの移行でのもう一つの課題は、優れたパフォーマンスを実現し、コストを削減することです。基盤となるチャーンからの移行中や移行後に、新しいストレージ エンジンとやり取りするワークロードの特定の側面が原因でパフォーマンスの低下が発生する可能性があります。これが、レイテンシの増加やリクエストの拒否などの問題につながる場合があります。
パフォーマンスの低下は、データベースの圧縮率にばらつきが生じることで発生する、一部のデータベースでのストレージ使用量の増加として表面化することもあります。これにより、内部リソースの消費とコストが増加します。さらに、追加のストレージが利用できない場合、本番環境の停止につながる可能性があります。
新しいカラム型ストレージ エンジンは、一般的にパフォーマンスとデータ圧縮の両方を向上させますが、Spanner のデプロイは大規模であるため、異常値に注意する必要があります。
複雑度とサポート性
2 種類の形式(デュアル フォーマット)が存在することによって、サポートのためにより多くのエンジニアリング作業が必要になるだけでなく、システムが複雑になりゾーンごとのパフォーマンスに格差が生じます。ここでのリスクを軽減するための明白なアプローチは、移行速度を向上させることです。特に、同じデータベース内でデュアル フォーマットが共存する期間を短縮することです。
しかし、Spanner 上のデータベースのサイズはさまざまで、数桁にもおよびます。その結果、それぞれのデータベースの移行に必要な時間は大きく異なります。移行のためのデータベースのスケジュール設定は、画一的に行うことはできません。移行作業では、安全かつ確実に最速での達成を目指す一方で、デュアル フォーマットが存在する移行期間を考慮する必要があります。
移行の信頼性を確立するための体系的な原則に基づくアプローチ
Google Cloud では、独自に定義した一連の信頼性の原則に基づく体系的なアプローチを導入しました。この信頼性の原則を使用して、Google の自動化フレームワークは移行候補(インスタンス構成やデータベースなど)を自動的に評価し、移行に適合する候補を選択しました。また、違反するものにはフラグを付けて報告しました。違反として報告された移行候補は特別に検査され、違反内容が解決してから移行の対象として認められました。これにより、本番環境の安全性を犠牲にすることなく、トイルを軽減しながら俊敏性を高めることができました。
信頼性の原則と自動化アーキテクチャ
信頼性の原則が移行を実施する方法の基礎となるものでした。移行候補の健全性と適合性の評価、本番環境の変更に関するお客様への公開管理、パフォーマンスの低下とデータの整合性の処理から、Spanner の内外での新しいリリースや機能の追加などの絶え間ない変化を伴う動的な環境でのリスク軽減まで、信頼性の原則は多くの側面をカバーしました。
信頼性の原則に基づき、自動化フレームワークを構築しました。さまざまなデータや指標を収集し、組み合わせることで、Spanner 全体の状態をモデル化したビューを形成しました。このビューは、Spanner の現状を正確に反映するために繰り返しアップデートされました。
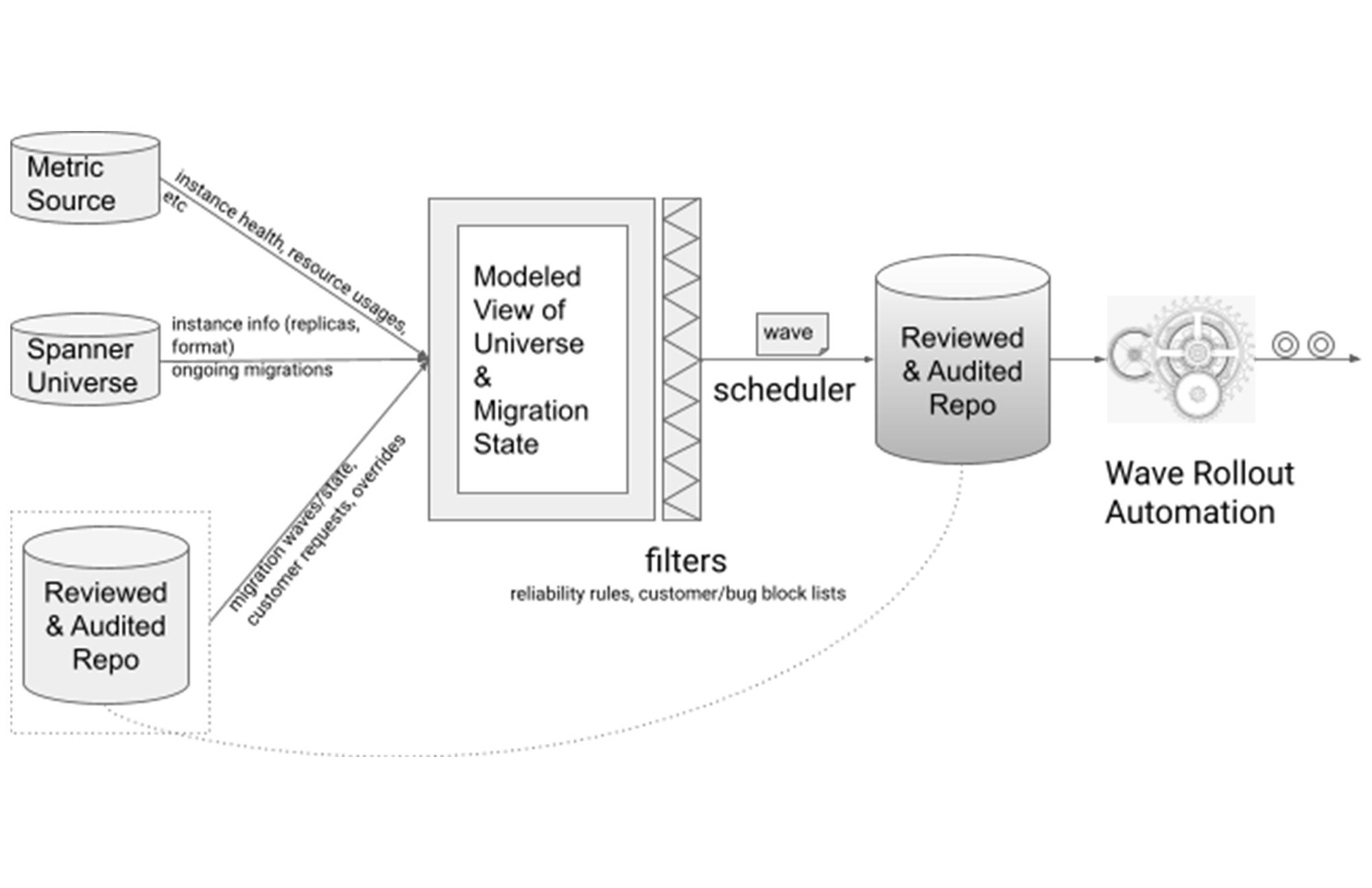
このアーキテクチャ設計では、信頼性の原則がフィルタの役割を果たしました。移行候補は要件を満たした場合にのみこのフィルタを通過し、移行スケジューラがそれを選択しました。段階的な展開が可能になるように、移行のスケジューリングは 1 週間ごとのウェーブで行われていました。
前述のとおり、信頼性の原則に適合しない移行候補が無視されることはなく、そのような候補にはわかりやすいようにフラグが付けられ、次の 2 つのうちどちらかの方法で解決されました。その方法とは、オーバーライドして慎重に移行するか、根本で邪魔をしている問題を解決してから移行するかです。
移行スケジュールの設定と 1 週間ごとロールアウト
移行スケジュールの設定は、移行のリスクを管理し、パフォーマンスの低下を防ぎ、データの整合性を確保するための中心的な要素でした。
お客様のワークロードは多様であり、デプロイのサイズが広範囲に及ぶため、きめ細かな移行スケジュールが採用されました。スケジュール設定アルゴリズムは、お客様のデプロイを障害発生ドメインとして監視し、お客様のインスタンス構成の移行を適切にステージングしてスペースを確保しました。ロールアウトの自動化と併せて、リスクをコントロールしながら効率的な移行プロセスを実現しました。
このフレームワークの下で、移行は次の項目で段階的に進行しました。
- 同じお客様のデプロイの複数のインスタンス構成間
- 同じインスタンス構成の複数のゾーン間
- 毎週のロールアウト ウェーブ内の移行候補間
お客様のデプロイを考慮したスケジュール設定
お客様のデプロイ内での段階的なロールアウトでは、お客様のデプロイを障害発生ドメインとして認識する必要がありました。そこで、デプロイメントのオーナー権限と使用状況を示すヒューリスティックを使用しました。Spanner の場合、複数のインスタンスは通常、同じサービスのリージョン インスタンスであるため、これはワークロードの分類の近似値でもあります。次の簡略化されたグラフに示すように、分類により、各クラスが同じお客様からの同じワークロードのインスタンス構成のコレクションであるデプロイメント インスタンスの同等のクラスが生成されました。
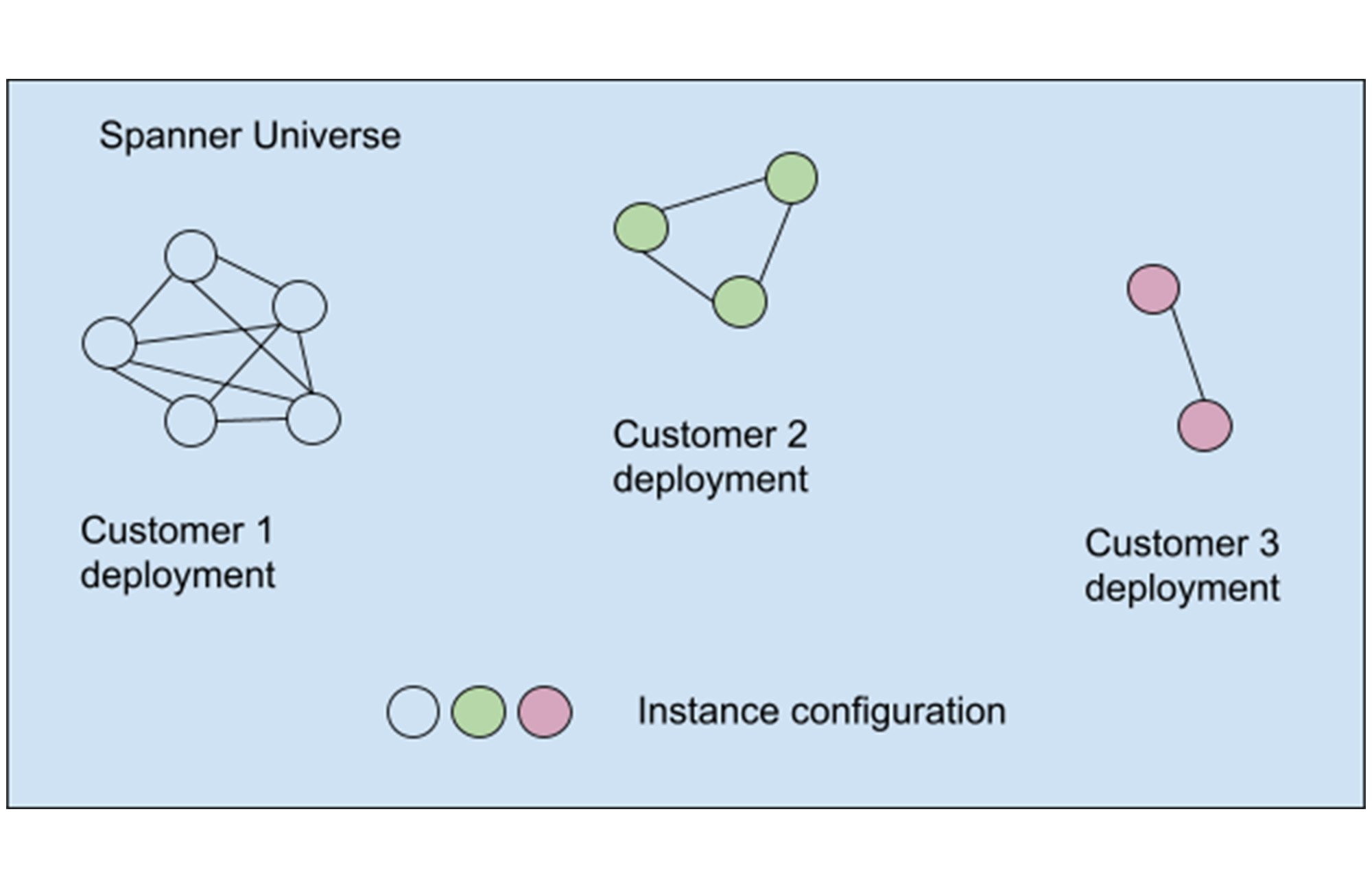
毎週のウェーブ スケジューラにより、同等の各クラスから移行候補(インスタンス構成のレプリカやゾーンなど)が選択されました。ワークロードが分離されていたため、複数の同等クラスからの候補を個別に選択できました。ある同等クラスで問題をブロックしても、他のクラスでの進行が妨げられることはありませんでした。
毎週のウェーブの段階的なロールアウト
新しいリリースによる新しい問題と、お客様と Spanner の両方からの変更を軽減するために、毎週のウェーブも段階的にロールアウトされました。これにより、広範囲に影響を与えることなく問題が表面化し、移行速度が加速されました。
信頼性、可用性、パフォーマンスの管理
前述のメカニズムのもと、パフォーマンスの低下や可用性とデータの整合性の損失を防ぎつつ、お客様のデプロイは一連の状態変化を通じて慎重に移行されました。
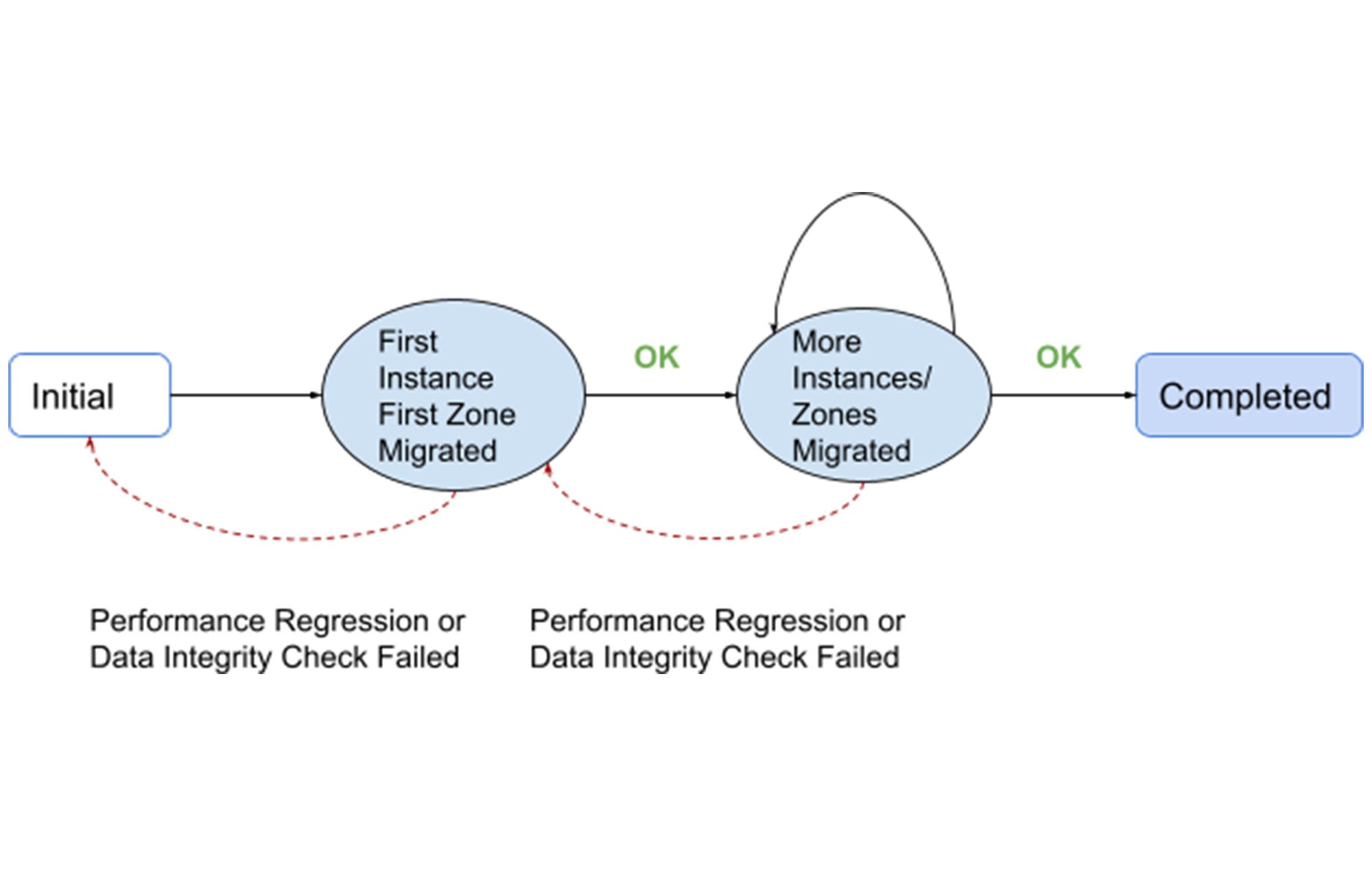
最初に、お客様のインスタンス構成が選択され、最初のゾーンやレプリカ(以下「最初のゾーン」)が移行されました。これにより、ワークロードと新しいストレージ エンジンとのやり取りが不十分な場合に問題が明らかになる一方で、お客様のグローバルな本番環境に対する潜在的な影響が回避されました。
最初のゾーン移行に続いて、Spanner の組み込みの整合性チェックを使用して、移行されたゾーンを他のゾーンと比較することにより、データの整合性がチェックされました。このチェックが失敗した場合、または移行後にパフォーマンスの低下が発生した場合、インスタンスは以前の状態に復元されました。
移行後のストレージ サイズを前もって見積もっておくことで、ストレージが過剰に増加したインスタンスの移行は信頼性の原則によりブロックされました。その結果、移行後にストレージ圧縮が予想外に元に戻ることは多くありませんでした。それとは関係なく、リソースの使用状況とシステムの状態は、モニタリング インフラストラクチャによって綿密にモニタリングされました。予期しない回帰が発生した場合は、ゾーンを SSTable 形式に戻して移行することで、インスタンスが望ましい状態に復元されました。
すべてが順調に進んだ場合にのみ、より多くのインスタンスやゾーンを移行することで、お客様のデプロイの移行は段階的に進行し、リスクが軽減されるにつれて加速しました。
プロジェクト管理と指標の推進
大規模な移行作業には、効果的なプロジェクト管理と、進捗を促進するための主要な指標が必要です。そこで、以下を含む(ただしこれ以外にもあります)いくつかの重要な指標を導き出しました。
「coverage(対象範囲)」指標。この指標により、新しいストレージ エンジンを実行している Spanner インスタンスの数と割合が追跡されました。これは最も優先度の高い指標でした。名前が示すとおり、この指標は、さまざまなワークロードと新しいストレージ エンジンとのやりとりを対象としており、根本的な問題を早期に発見できました。
「majority(大多数)」指標。この指標により、大部分のゾーンで新しいストレージ エンジンを実行している Spanner インスタンスの数と割合が追跡されました。これにより、Spanner のようなクォーラムに基づくシステムの転換点における異常を検出できます。
「completion(完了)」指標。この指標は、新しいストレージ エンジンを完全に実行している Spanner インスタンスの数と割合を追跡しました。この指標で 100% を達成することが最終的な目標でした。
指標は時系列で維持されていたため、傾向を調査して取組みの後半に近づくにつれてギアを切り替えることができました。
まとめ
大規模な移行を実行することは、戦略的な設計、自動化の構築、プロセスの設計、取組みの進行に伴う実行ギアの転換などを伴う事業です。体系的かつ原則に基づいたアプローチにより、サービスの可用性、信頼性、完全性について妥協することなく、6 エクサバイトを超える管理データと、ピーク時には 20 億件を超える QPS を含む大規模な Spanner の移行を短時間で達成しました。
Google の重要なサービスの多くは Spanner に依存しており、この移行によってすでに大幅な改善が見られます。さらに、この新しいストレージ エンジンにより、将来の数多くのイノベーションのためのプラットフォームが提供されます。最高の瞬間が訪れるのは、まだこれからです。
- ソフトウェア エンジニア Yuanyuan Zhao

