Spanner on a modern columnar storage engine
Yuanyuan Zhao
Software Engineer
Google was born in the cloud. At Google, we have been running massive infrastructure that powers critical internal and external facing services for more than two decades. Our investment in this infrastructure is constant, ranging from user visible features to invisible internals that makes the infrastructure more efficient, reliable and secure. Constant updates and improvements are made into the infrastructure. With billions of users served around the globe, availability and reliability is at the core of how we operate and update our infrastructure.
Spanner is Google’s massively scalable, replicated and strongly consistent database management service. With hundreds of thousands of databases running in our production instance, Spanner processes over 2 billion requests per second at peak and has over 6 exabytes of data under management that is the “source of the truth” for many mission critical services, including AdWords, Search, and Cloud Spanner customers. The customer workloads are diverse, and would stretch a system in various ways. Although there have been constant binary releases to Spanner, fundamental changes such as swapping out the underlying storage engine is a challenging undertaking.
In this post, we talk about our journey migrating Spanner to a new columnar storage engine. We discuss the challenges a massive scale migration faced and how we accomplished this effort in ~2-3 years with all the critical services running on top uninterrupted.
The Storage Engine
The storage engine is where a database turns their data into actual bytes and stores them in underlying file systems. In a Spanner deployment, a database is hosted in one or more instance configurations, which are physical collections of resources. The instance configurations and databases comprise one or more zones or replicas that are served by a number of spanner servers. The storage engine in the server encodes the data and stores them in the underlying large scale distributed file system - Colossus.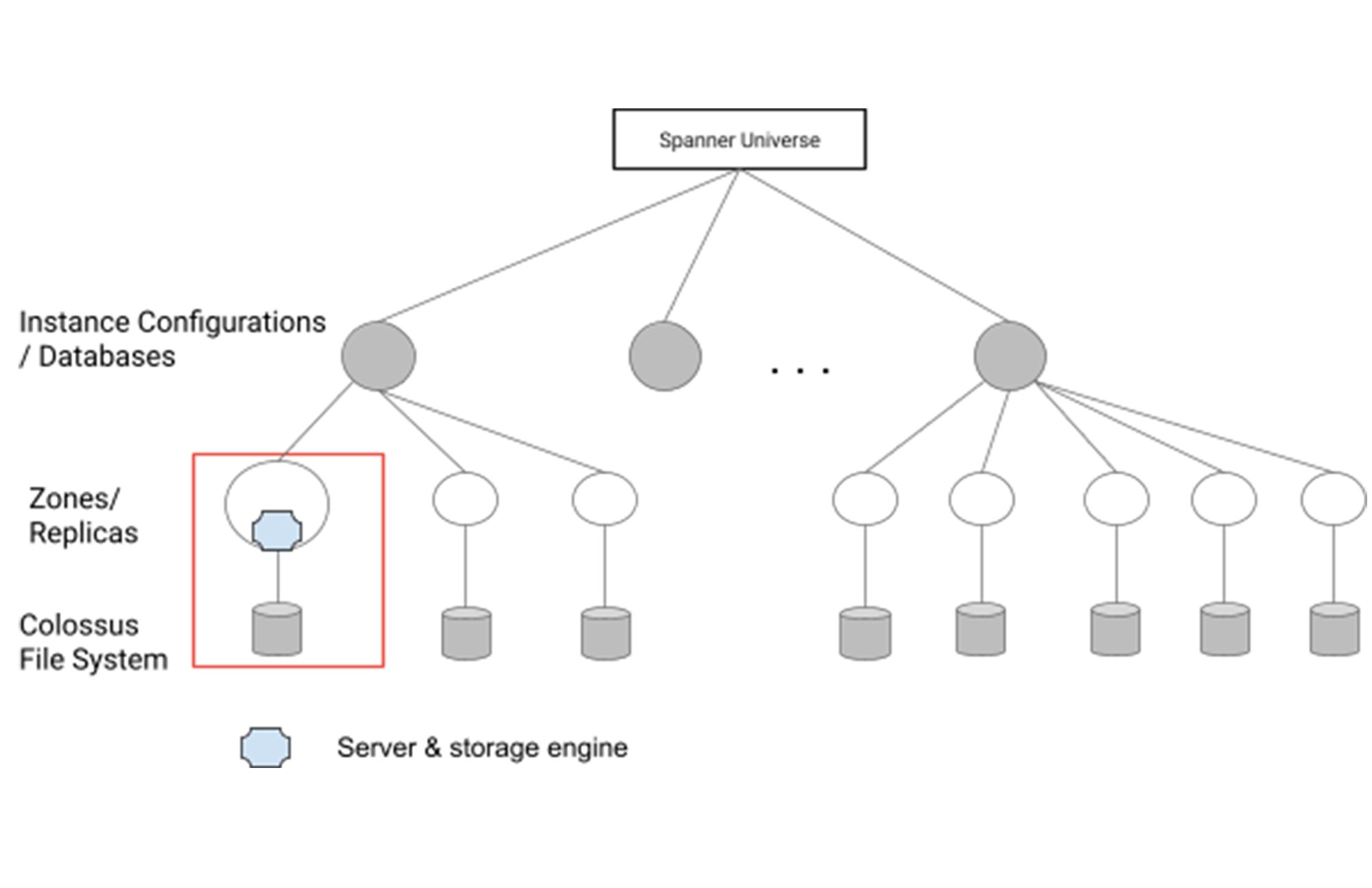
Spanner originally used a Bigtable-like storage engine based on SSTable (Sorted String Table) format stacks. This format has proven to be incredibly robust through years of large scale deployment such as in Bigtable and Spanner itself. The SSTable format is optimized for schemaless NoSQL data consisting of primarily large strings. While it is a perfect match for Bigtable, it is not the best fit for Spanner. In particular, traversing individual columns is inefficient.
Ressi is the new low-level, column-oriented storage format for Spanner. It is designed from the ground up for handling SQL queries over large-scale, distributed databases with both OLTP and OLAP workloads, including maintaining and improving performance of read and write queries with key-value data in the database. Ressi includes optimizations ranging from block-level data layout, file-level organization of active and inactive data, and existence filters for storage I/O savings etc. The data organization improves storage usage and helps in large scan queries. Deployment of Ressi with very large scale services such as GMail on Spanner have shown performance improvements over multiple dimensions, such as CPU and storage I/O.
The Challenges of Storage Engine Migration
Improvements and updates to Spanner are constant and we are adept at safely operating and evolving our system in a dynamic environment. However, a storage engine migration changes the foundation of a database system and presents distinct challenges, especially at a massive deployment scale.
In general, in a production OLTP database system, storage engine migration needs to be done without interruption to the hosted databases, without degradation to latency and throughput, and without compromising data integrity. There had been past attempts and success stories of live database storage engine migration. However, successful attempts at the scale of Spanner with multiple exabytes of data are rare. The mission critical nature of the services and the massive scale place a very high requirement on how the migration should be handled.
Reliability, Availability & Data Integrity
The topmost requirement of the migration is maintaining service reliability, availability and data integrity throughout the migration. The challenges were paramount and unique with the massive deployment scale of Spanner:
Spanner database workloads are diverse and interact with the underlying Spanner system in different ways. Successful migration of one database does not guarantee successful migration of another.
Massive data migration inherently creates unusual churns in the underlying system. This may trigger latent and unanticipated behavior, causing production outages.
We operate in a dynamic environment with constant new ambient changes from the customers and Spanner new feature development. Migration faced non-monotonically decreasing risk.
Performance & Cost
Another challenge of migrating to a new storage engine is to achieve good performance and reduce cost. Performance regression can arise during the migration from underlying churns, and/or after the migration due to certain aspects of the workloads interacting with the new storage engine. This can cause issues such as increased latency and rejected requests.
Performance regression may also manifest as increased storage usage in some databases due to variances in database compressibility. This increases internal resource consumption and cost. What’s more, if additional storage is not available, it may lead to production outages.
Although the new columnar storage engine improves both performance and data compression in general, due to Spanner’s massive deployment, we must watch out for the outliers.
Complexity and Supportability
Existence of dual formats not only requires more engineering effort to support, but also increases system complexity and performance variances in different zones. An obvious approach to mitigate the risk here is to achieve high migration velocity and in particular, shorten the co-existence of dual formats in the same databases.
However, databases on Spanner have different sizes, spanning several orders of magnitude. As a result, the time required to migrate each database can vary by a large degree. Scheduling databases for migration can not be done one-size-fit-all. The migration effort must take into account the transitioning period where dual formats exist while trying to achieve highest velocity safely and reliably.
A Systematic Principled Approach toward Migration Reliability
We introduced a systematic approach based on a set of reliability principles we defined. Using the reliability principles, our automation framework automatically evaluated migration candidates (i.e., instance configurations and/or databases), selecting conforming candidates for migration and flagging violations. The flagged migration candidates were specially examined and violations resolved before the candidates became eligible for migration. This effectively reduced toil and increased velocity without sacrificing production safety.
The Reliability Principles & Automation Architecture
The reliability principles were the cornerstones of how we conducted the migration. They covered multiple aspects: from evaluating the healthiness and suitability of migration candidates, managing customer exposure to production changes, handling performance regression and data integrity, to mitigating risks in a dynamic environment with constant changes, such as new releases and feature launches within and outside of Spanner.
Based on the reliability principles, we built an automation framework. Various stats and metrics were collected. Together they formed a modeled view of the state of the Spanner universe. This view was continuously updated to accurately reflect the current state of the universe.
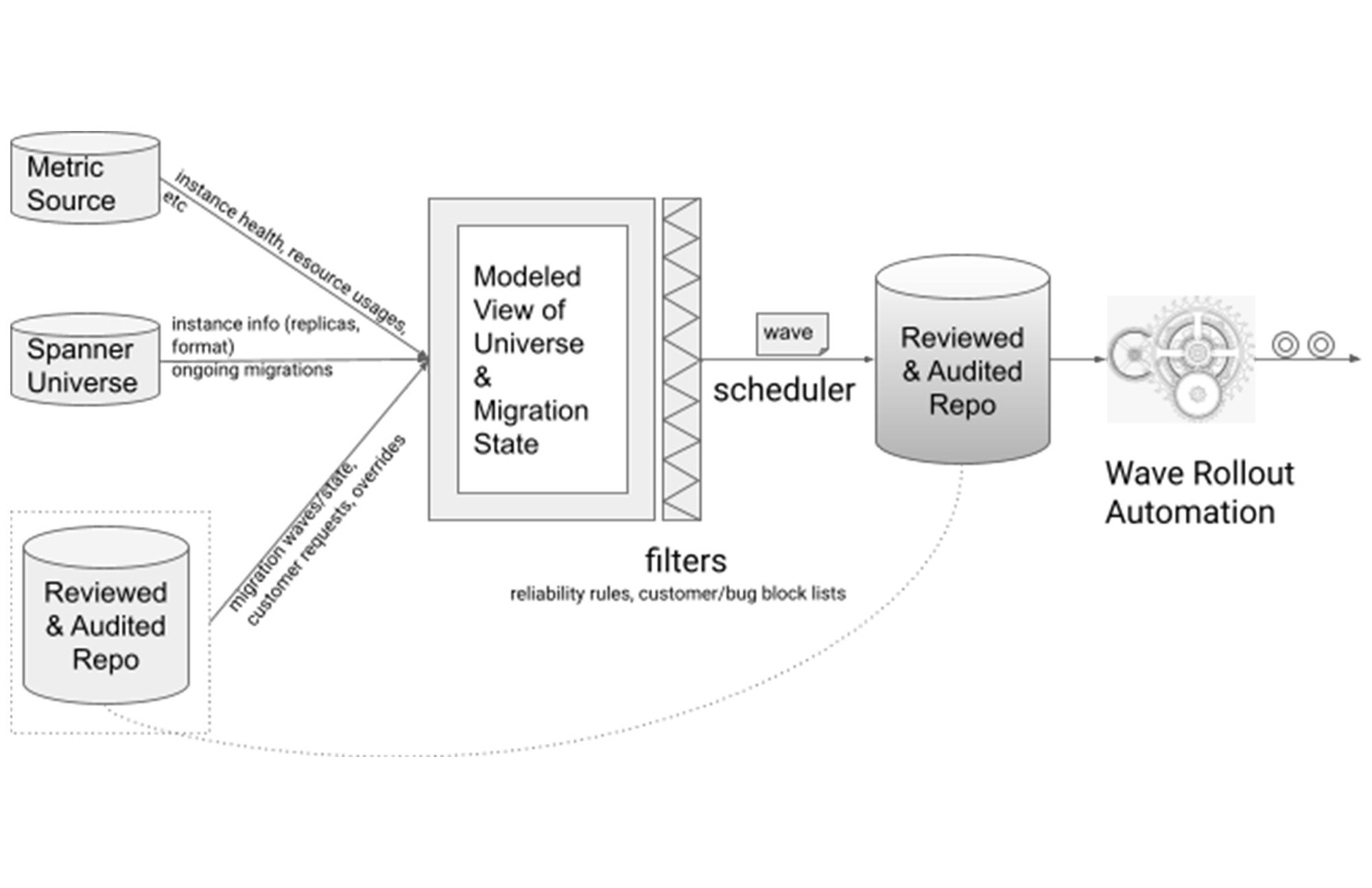
In this architectural design, the reliability principles became filters, where a migration candidate could only pass through and be selected by the migration scheduler if it satisfied the requirements. Migration scheduling was done in weekly waves to enable gradual rollout.
As previously mentioned, migration candidates not satisfying the reliability principles were not ignored - they were flagged for attention and were resolved in one of two ways: override and migrate with caution, or resolve the underlying blocking issue then migrate.
Migration Scheduling & Weekly Rollout
Migration scheduling was the core component in managing migration risk, preventing performance regressions and ensuring data integrity.
Due to the diverse customer workload and wide spectrum of deployment sizes, we adopted fine-grained migration scheduling. The scheduling algorithm observed the customer deployment as failure domains and properly staged and spaced the migration of customer instance configurations. Together with the rollout automation, they enabled an efficient migration journey while keeping risk under control.
Under this framework, the migration proceeded progressively in the following dimensions:
among multiple instance configurations of the same customer deployment;
among the multiple zones of the same instance configuration; and
among the migration candidates in the weekly rollout wave.
Customer Deployment-aware Scheduling
Progressive rollout within a customer’s deployment required us to recognize the customer deployment as failure domains. We used an heuristic that indicates deployment ownership and usage. In Spanner’s case, this is also a close approximation of workload categorization as the multiple instances are typically regional instances of the same service. The categorization produced equivalent classes of deployment instances where each class is a collection of instance configurations from the same customer and with the same workload, as shown in a simplified graph:
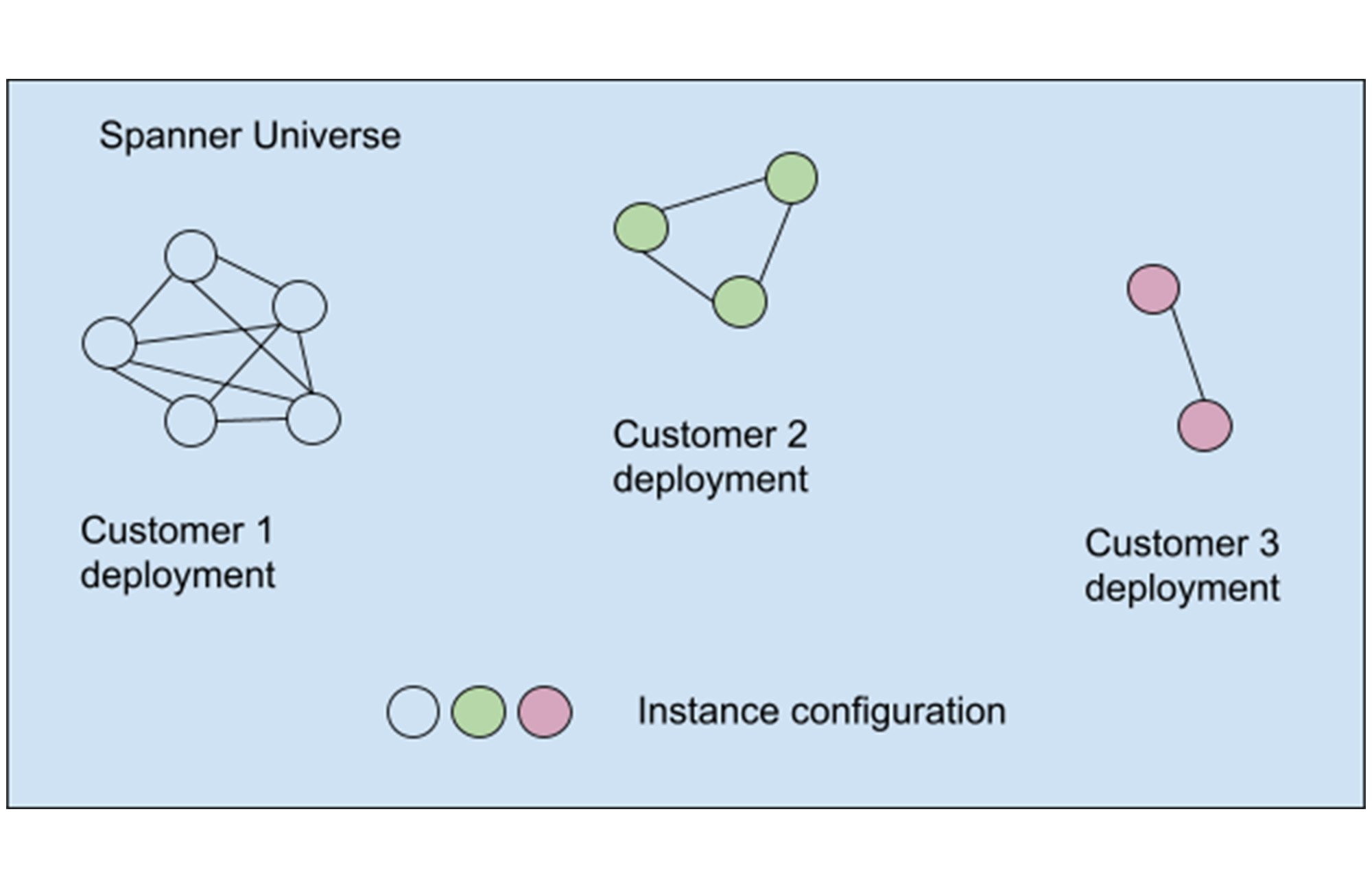
The weekly wave scheduler selected migration candidates (i.e., replicas/zones in instance configuration) from each equivalent class. Candidates from multiple equivalent classes can be chosen independently as their workloads were isolated. Blocking issues in one equivalent class would not prevent progress in other classes.
Progressive Rollout of Weekly Waves
To mitigate new issues from new releases and changes from both customers and Spanner, the weekly waves were also rolled out in a progressive manner, allowing issues to surface without causing widespread impact while accelerating to increase migration velocity.
Managing Reliability, Availability & Performance
Under the mechanisms described above, customer deployments were carefully moved through a series of state changes, preventing performance degradation and loss of availability and data integrity.
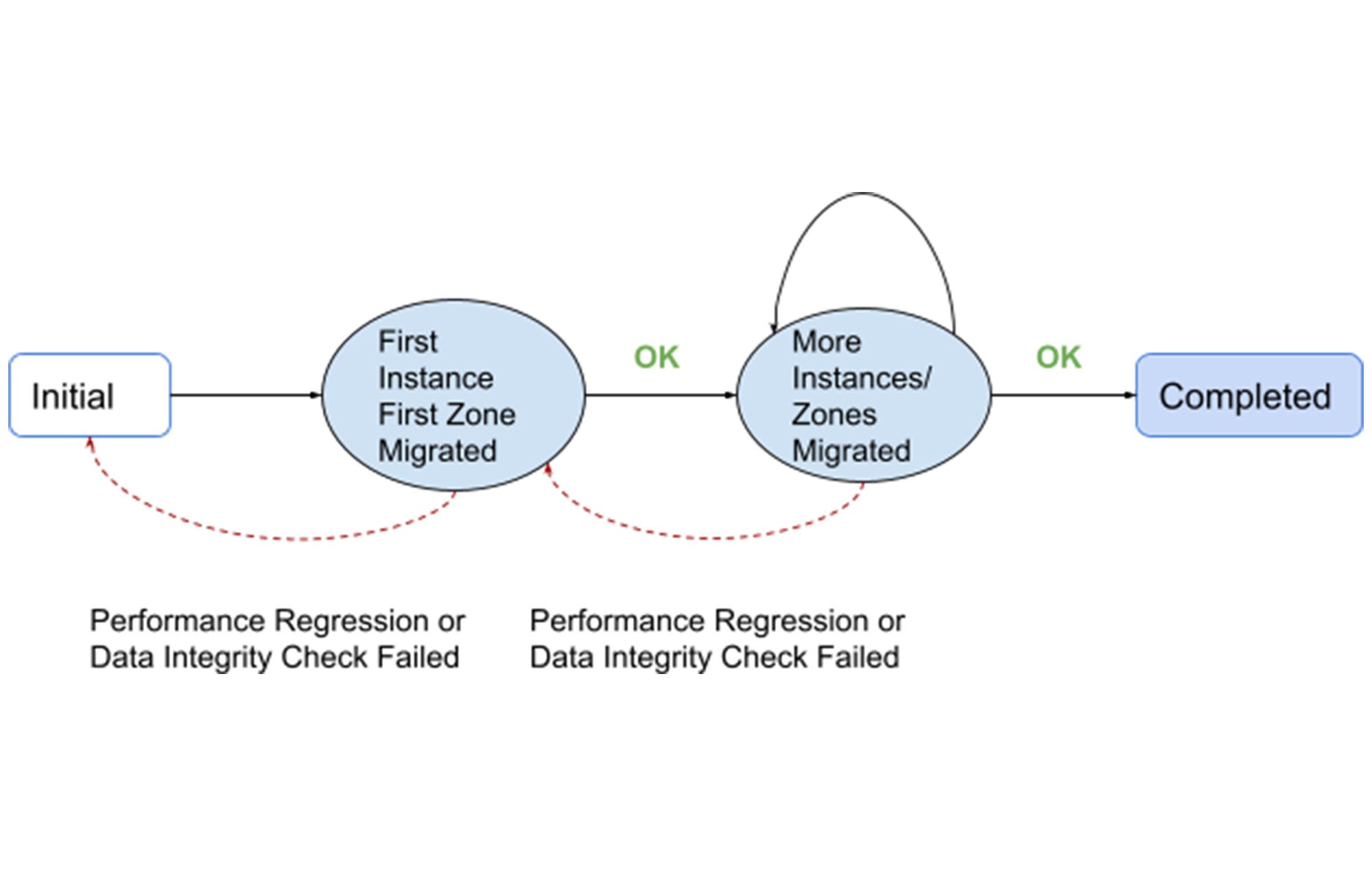
At the start, an instance configuration of a customer was chosen and an initial zone/replica ( henceforth referred to as “first zone”) was migrated. This avoided potential global production impact to the customer while revealing issues should the workload interact poorly with the new storage engine.
Following the first zone migration, data integrity was checked by comparing the migrated zone with other zones using Spanner’s built-in integrity check. If this check failed or performance regression occurred following the migration, the instance was restored to the previous state.
We pre-estimated the post migration storage size and the reliability principle blocks instances with excessive storage increase from migrating. As a result, we did not have many unexpected storage compression regression following a migration. Regardless, the resource usage and system health was closely monitored by our monitoring infrastructure. If unexpected regression occurred, the instance was restored back to the desired state by migrating the zone back to SSTable format.
Only when everything was OK would the migration of the customer deployment proceed forward, progressively by migrating more instances and/or zones, and accelerating as risk was further reduced.
Project Management & Driving Metrics
A massive migration effort requires effective project management and the identification of key metrics to drive progress. We drove a few key metrics, including (but not limited to):
The coverage metric. This metric tracked the number and percentage of Spanner instances running the new storage engine. This was the highest priority metric. As the name indicated, this metric covered the interaction of different workloads with the new storage engine, allowing early discovery of underlying issues.
The majority metric. This metric tracked the number and percentage of Spanner instances with the majority of the zones running the new storage engine. This allows catching anomalies at tipping points in a quorum based system like Spanner.
The completion metric. This metric tracked the number and percentage of Spanner instances that were completely running the new storage engine. Achieving 100% on this metric was our ultimate goal.
The metrics were maintained as time series, allowing examination of the trend and shifting gears as we approached the later stages of the effort.
Summary
Performing massive scale migration is an effort that encompasses strategic design, building automation, designing processes, and shifting execution gears as effort progresses. With a systematic and principled approach, we achieved a massive scale migration involving over 6 exabytes of data under management and 2 billion QPS at peak in Spanner within a short amount of time with service availability, reliability and integrity uncompromised.
Many of Google’s critical services depend on Spanner and have already seen significant improvements with this migration. Furthermore, the new storage engine provides a platform for many future innovations. The best is yet to come.
