Bigtable のトランザクションと分析のハイブリッド処理(HTAP)により、1 つのデータベースですべてに対応
Billy Jacobson
Developer Advocate: Bigtable
※この投稿は米国時間 2024 年 7 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
一般的に、データベースはオンライン トランザクション処理(OLTP)とオンライン分析処理(OLAP)という 2 種類のワークロードを処理します。たとえば、低レイテンシで大規模かつリアルタイムにモデルやベクトルを提供する必要がある AI システムを利用しているとします。これが OLTP ワークロードです。同時に、新たにトレーニングしたモデルから得た新しいデータセットや結果を定期的に一括アップロードする必要があるとします。これが OLAP です。ただし、これらのワークロードには相反する要件があります。OLTP では、少量のデータに対し多数の同時実行クエリを低レイテンシで実行する必要がありますが、OLAP ワークロードでは、少数の同時実行クエリで大量のデータにアクセスする必要があります。その際、レイテンシを気にする必要はそれほどありません。
Google Bigtable は、フルマネージドの NoSQL データベース サービスです。金融、医療、小売業界で大量のデータの保存とアクセスに利用されています。Google は最近、分散カウンタ、リクエストの優先度、書き込みフロー制御、Data Boost といった機能を Bigtable に追加し、1 つのデータベースで OLAP と OLTP の両方をより簡単に処理できるようにしました。この処理は、トランザクションと分析のハイブリッド処理(HTAP)とも呼ばれています。この新機能を活用すると、より高い信頼性とより負担の少ない運用管理でバッチジョブをさまざまな時間に分散させ、使用するリソースを減らして、サービス提供ワークロードに影響が及ばないようにすることができます。
実際に HTAP では、1 つのデータソースを処理することで、信頼できるデータソースが 1 つとなり、さまざまなユースケースに合わせてデータを移動させるパイプラインを実行する必要がなくなる、バッチジョブでリアルタイムのデータにアクセスできるなどの利点を得ることができます。これまで、分析クエリは OLTP タイプのサービス提供ワークロードに影響を与えていたため、サービス提供システムを大幅にオーバープロビジョニングするか、データを別のデータベースに複製する必要がありました。このようなソリューションでは、費用、管理オーバーヘッド、データ不整合などの問題が発生します。
このブログ投稿では、ハイブリッド サービスを改善して Bigtable の総所有コスト(TCO)を削減するベスト プラクティスや、これらの新機能の使い方とその仕組みについてご説明します。
ハイブリッド サービスのベスト プラクティス
Bigtable はユニークなデータベースで、高 QPS 低レイテンシのポイント読み取り、高いスキャン スループット、高い書き込みスループットをすべて 1 つの便利なパッケージで提供することができます。Bigtable を単一のアクセス パターンで使用するシステムもありますが、クラスタで混在ワークロードに対応することが一般的です。
ここでは、高パフォーマンスなハイブリッド設定におすすめの戦略をいくつかご紹介します。最高のパフォーマンスを実現するには、これらの戦略を組み合わせて使用することが必要となる場合があります。最近リリースされたリクエストの優先度設定、フロー制御、Data Boost といった機能は、既存の戦略を補完するものです。
Data Boost
分析や ML トレーニングなど、レイテンシ要件が厳しくない読み取り専用ワークロードには、Data Boost を使用します。Data Boost では、低レイテンシのオペレーションに最適化されたコンピューティング リソースを使わずに、基盤となる Bigtable データに直接アクセスできます。
ワークロードで Data Boost を有効にするには、Data Boost 対応のアプリケーション プロファイルを使用します。プロファイルの新規作成や既存プロファイルの更新が可能なので、多くの場合、コードを修正したりパイプラインを停止したりする必要はありません。
分散カウンタ
Bigtable の集計タイプを使用すると、ストリーミング データのカウント、設定操作、統計に最適化された、高速で効率的な増分更新が可能となり、複雑な Lambda アーキテクチャを通常は必要とするユースケースを簡素化できます。集計はマルチクラスタ ルーティングに対応しています。最高のパフォーマンスを得るには、集計の優先度をできる限り ReadModifyWrite より高くする必要があります。他の列タイプと一緒に任意のテーブルで使用できるため、1 つのデータベースでコンテンツ提供とリアルタイム分析を組み合わせて行うことができます。
リクエストの優先度設定
アプリケーション プロファイルでリクエストの優先度を設定し、Bigtable インスタンスに受信リクエストの処理方法を伝えます。Bigtable が対応しており、アプリ プロファイルで設定できる優先度は以下の 3 種類です。
-
PRIORITY_HIGH
-
PRIORITY_MEDIUM
-
PRIORITY_LOW
優先度の高いリクエストは優先度の低いリクエストより先に実行されるため、Bigtable インスタンス上の異種ワークロードは、優先度の高いワークロードほど優れたパフォーマンスを発揮します。
リクエストの優先度では、Data Boost のような完全な分離は行われませんが、読み取りと書き込みの両方に対応しています。また、Data Boost が追加のコンピューティング リソースを使用するのに対し、リクエストの優先度機能は、プロビジョニング済みのノードを追加費用なしで使用します。プロビジョニング済みのノードで処理できないほど多くのトラフィックが発生した場合、優先度の低いリクエストのスロットリングが始まります。スロットリングを許容できる優先度の低いワークロードもありますが、一貫して高いスループットが必要な場合は、スロットリングが発生する前に Bigtable の自動スケーリングを使ってより多くのノードをプロビジョニングします。
フロー制御を使用した自動スケーリング
Bigtable クラスタは、CPU 使用率に基づく自動スケーリングを使用して構成できます。Bigtable サービスは、CPU 使用率の目標しきい値を上回らないよう、設定された上限内でノードを追加または削除します。ほとんどのジョブは Bigtable の自動スケーリングでうまく動作しますが、ノードを最小限に増やして高スループットの書き込みを行う一括書き込みジョブは、問題を引き起こす可能性があります。スケーリングを使って最適なパフォーマンスを得るには、10000/10/1 ルール(10,000 QPS から始めて、1 分ごとにトラフィックを 10% ずつ増やす)に従うことをおすすめします。フロー制御は、スケーリング中の書き込みをレート制限することでこの問題を解決する追加機能です。
フロー制御と自動スケーリングを組み合わせることで、クラスタを過負荷にすることなく、書き込みトラフィックを徐々に増やし、Bigtable の自動スケーリングをトリガーできます。これにより、ジョブの成功率が高まり、パフォーマンスが向上し、トラフィック処理への影響が軽減されます。ノードが追加されると、スロットリングは減少します。
事前スケーリング
ワークロード トラフィックの大幅な変動が予測されることはよくあることです。たとえば、日次のバッチジョブが午前 0 時をすぎて実行されたり、ビジネス イベントのためにプラットフォームの使用量が急増したりすることがあります。
10000/10/1 ルール
より速いペースでトラフィックを増やしたい場合、あらかじめクラスタをスケーリングして、Bigtable インスタンスをトラフィックの増加に備えさせると効果的です。必要と思われるノード数を判断するには、Bigtable のパフォーマンス ガイドラインを参考にしてください。自動スケーリングを使用する場合、これは最小ノード構成の拡大を意味します。Bigtable の自動スケーリングは引き続き、ワークロードのニーズに合わせてクラスタのサイズを自動的に調整し続けます。
ワークロードの事前スケーリングはリクエストの優先度やフロー制御とともにシームレスに動作し、求めるレベルのパフォーマンスを実現します。
技術アーキテクチャ: フロー制御とリクエストの優先度
フロー制御機能は、Bigtable への書き込みリクエストをレート制限し、ジョブが成功するよう支援します。
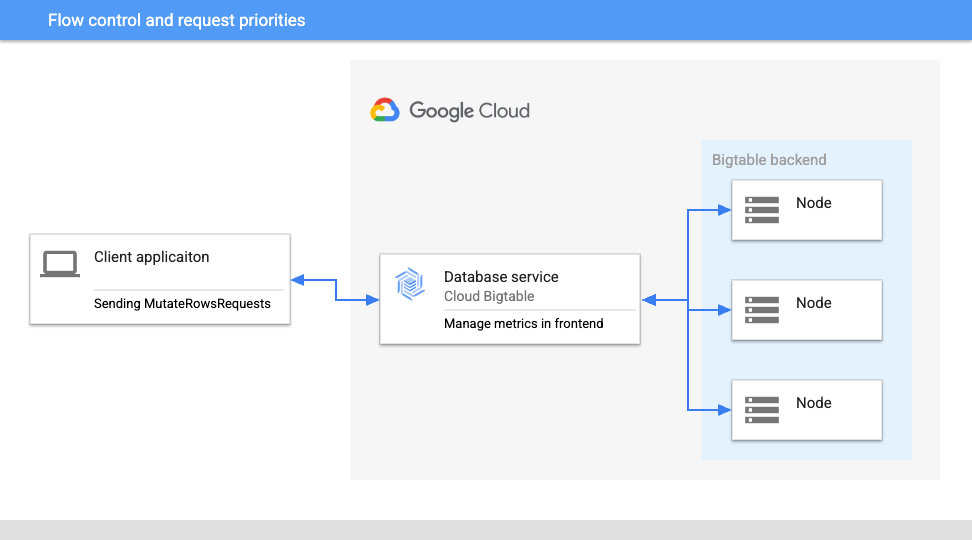
Bigtable サービスのフロントエンド サーバーは、システム容量をモニタリングし、推奨されるトラフィック調整をクライアントに送信します。クライアントはその情報に基づき、送信リクエストを増やしたりスロットリングしたりすることができます。データを Bigtable にインポートする Dataflow ジョブでは、リクエストのスロットリングが必要になると、Dataflow は新しい要素のフェッチを停止するため、ワーカーのメモリに大量のデータキューがたまることはありません。
実施時におすすめの方法
リクエストの優先度と書き込みフロー制御を使用すると、必要なコード変更は最小限になります。低いリクエスト優先度でアプリ プロファイルを作成し、そのアプリ プロファイルをバッチ書き込みジョブに使用します。
以下は、Dataflow ジョブが Bigtable に書き込むためのアプリ プロファイルの設定例です。
1 個のクラスタで複数のバッチジョブを実行する際にすべてのジョブで優先度の低いアプリ プロファイルのルーティングを使用しない場合、注意が必要です。フロー制御はクラスタのリソースによって決まるため、他のジョブよりも前に 1 つのジョブがすべてのリソースを占有し、要求してしまうと、他のジョブを「飢えさせる」可能性があります。
ワークロードは多様なので、Dataflow の適切な構成を探るには、試験運用を少し行います。一般的には、Dataflow ワーカーを増やして Bigtable の自動スケーリングの最大値を大きくすると、ジョブをより速く実行できます。小規模なデータセットかテスト用のテーブルを使って試験運用を行うことをおすすめします。Dataflow クラスタの使用率をモニタリングし、その状況に応じて Dataflow ワーカーの最大数と Bigtable の自動スケーリング構成を調整します。
次のステップ
これで、Bigtable のハイブリッド サービスの新機能の詳細と、これらの機能を使って最高のパフォーマンスを実現する方法について理解を深めていただけたかと思います。次のステップとして、これらの手法と機能を活用し、アプリケーションに実装する方法をいくつかご紹介します。
-
アプリケーション プロファイルでリクエストの優先度を構成する方法を学ぶ
- Bigtable を使用した分散カウンタの構築について学ぶ
ー Bigtable 担当デベロッパー アドボケイト Billy Jacobson